
Heim >Technologie-Peripheriegeräte >KI >Wenn Sie Ihre Arbeit bei Nature einreichen, fragen Sie zuerst nach GPT-4! Stanford hat tatsächlich 5.000 Artikel getestet und die Hälfte der Meinungen stimmten mit denen menschlicher Rezensenten überein
Wenn Sie Ihre Arbeit bei Nature einreichen, fragen Sie zuerst nach GPT-4! Stanford hat tatsächlich 5.000 Artikel getestet und die Hälfte der Meinungen stimmten mit denen menschlicher Rezensenten überein

- PHPznach vorne
- 2023-10-06 14:37:061742Durchsuche
Ist GPT-4 in der Lage, eine Papierüberprüfung durchzuführen?
Forscher aus Stanford und anderen Universitäten haben es tatsächlich getestet.
Sie gaben GPT-4 Tausende von Artikeln von Top-Konferenzen wie Nature und ICLR, ließen es Rezensionsmeinungen generieren (einschließlich Änderungsvorschlägen usw.) und verglichen sie dann mit den Meinungen von Menschen.
Nach der Untersuchung haben wir Folgendes festgestellt:
Mehr als 50 % der von GPT-4 vorgeschlagenen Meinungen stimmen mit mindestens einem menschlichen Rezensenten überein;
Und mehr als 82,4 % der Autoren haben dies festgestellt die von GPT-4 bereitgestellten Meinungen Sehr hilfreich
Welche Erkenntnisse kann uns diese Forschung bringen?
Die Schlussfolgerung lautet:
Es gibt immer noch keinen Ersatz für hochwertiges menschliches Feedback, aber GPT-4 kann Autoren dabei helfen, ihre ersten Entwürfe vor der formellen Begutachtung durch Fachkollegen zu verbessern.

automatische Pipeline unter Verwendung von GPT-4.
Es kann die gesamte Arbeit im PDF-Format analysieren, Titel, Zusammenfassungen, Abbildungen, Tabellentitel und andere Inhalte extrahieren, um Eingabeaufforderungen zu erstellenund dann GPT-4 Rezensionskommentare bereitstellen lassen. Darunter entsprechen die Meinungen den Standards jeder Top-Konferenz und umfassen vier Teile: Die Bedeutung und Neuheit der Forschung sowie die Gründe für eine mögliche Annahme oder Ablehnung und Verbesserungsvorschläge 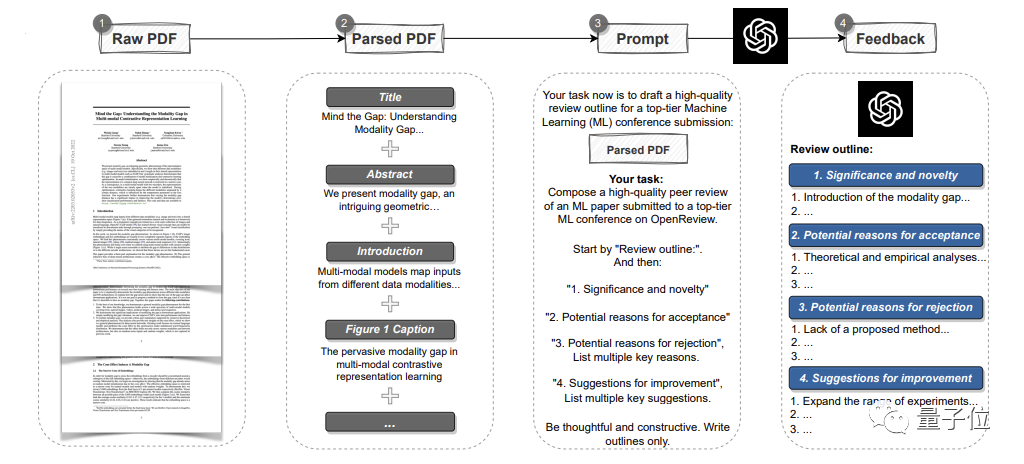
Zwei Aspekten entfalten.
Das erste ist das quantitative Experiment:
Lesen Sie vorhandene Artikel, generieren Sie Feedback und vergleichen Sie sie systematisch mit echten menschlichen Meinungen, um die Überschneidungen herauszufindenHier sammelte das Team Daten aus der Hauptzeitschrift „Nature“ und der Hauptunterschrift -Zeitschriften 3096 Artikel wurden ausgewählt, 1709 Artikel wurden von der ICLR Machine Learning Conference(einschließlich letztes und dieses Jahr) ausgewählt, also insgesamt 4805 Artikel.
Davon umfassten Nature-Artikel insgesamt 8.745 Kommentare von Menschen; ICLR-Konferenzen umfassten 6.506 Kommentare.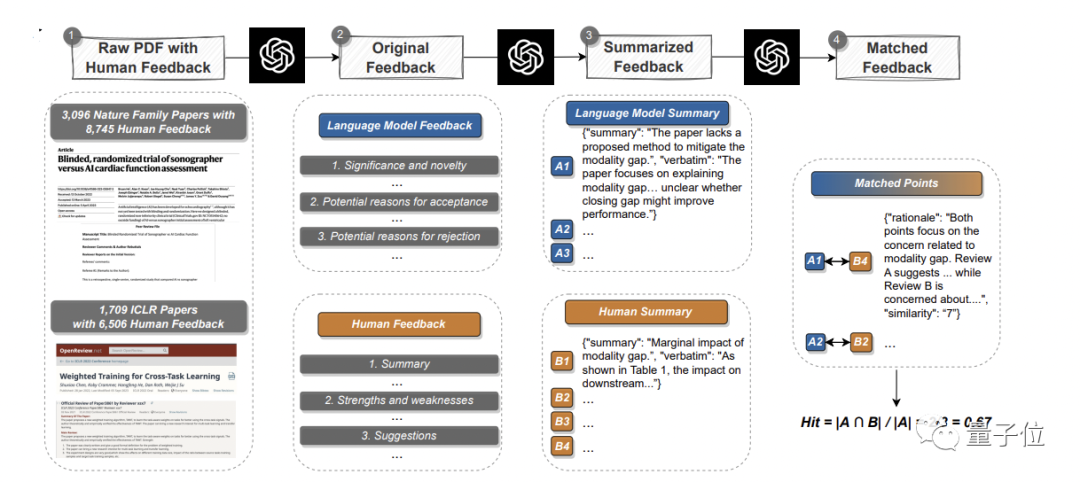
1. GPT-4-Meinungen überschneiden sich erheblich mit den tatsächlichen Meinungen menschlicher Gutachter.
Insgesamt stimmen 57,55 % der GPT-4-Meinungen mit mindestens einem menschlichen Gutachter überein Laut ICLR liegt diese Zahl sogar bei 77,18 %.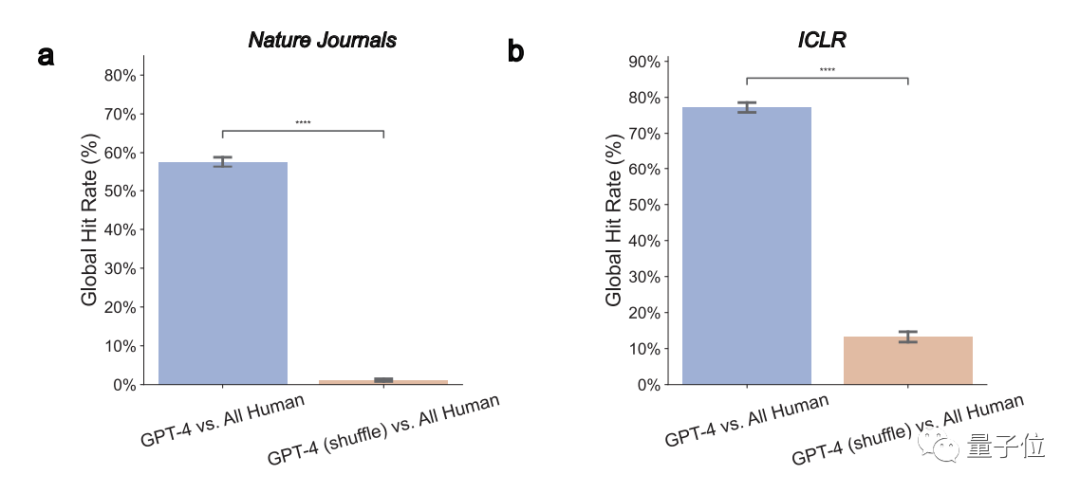
 Dies zeigt, dass GPT-4 eine hohe Unterscheidungsfähigkeit hat und Papiere von schlechter Qualität identifizieren kann
Dies zeigt, dass GPT-4 eine hohe Unterscheidungsfähigkeit hat und Papiere von schlechter Qualität identifizieren kann
Der Autor gab auch an, dass diejenigen, die umfangreichere Änderungen erfordern, dies können Zum Glück für angenommene Arbeiten kann jeder die von GPT-4 bereitgestellten Überarbeitungsvorschläge ausprobieren, bevor er sie offiziell einreicht.
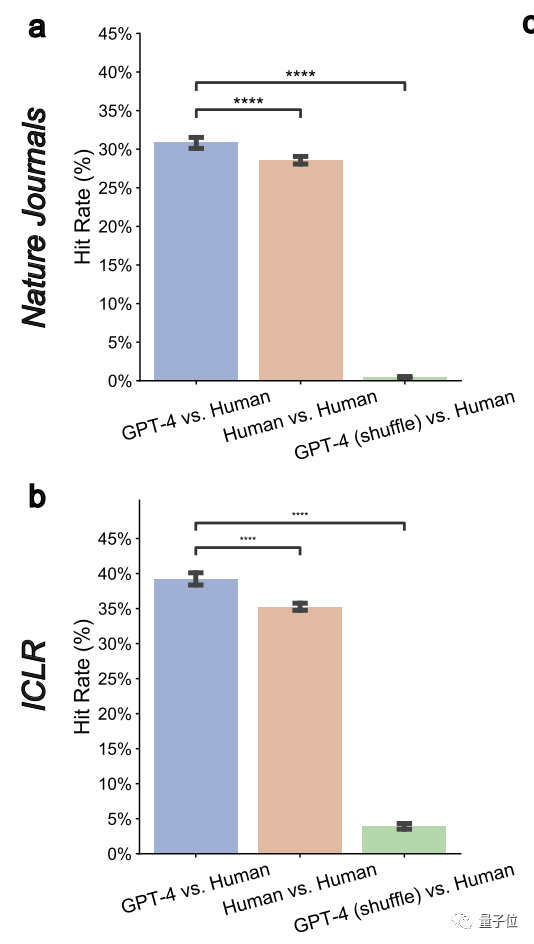
2. GPT-4 kann nicht-universelles Feedback gebenDas sogenannte nicht-universelle Feedback bedeutet, dass GPT-4 keine universelle Bewertungsmeinung abgibt, die für mehrere Arbeiten gilt.
Hier haben die Autoren eine Metrik der „paarweisen Überlappungsrate“ gemessen und festgestellt, dass diese sowohl bei Nature als auch bei ICLR deutlich auf 0,43 % und 3,91 % reduziert wurde.
Dies zeigt, dass GPT-4 spezifische Ziele verfolgt
3 Es kann eine Übereinstimmung mit menschlichen Meinungen zu wichtigen und universellen Themen erzielenIm Allgemeinen stellen die Kommentare, die am frühesten erscheinen und von mehreren Gutachtern erwähnt werden, häufig wichtige und häufige Probleme dar. Das Team stellte außerdem fest, dass LLM eher häufige Probleme identifiziert, die von mehreren Gutachtern einhellig als Probleme oder Mängel erkannt werden
GPT-4 schneidet insgesamt gut ab4 Die von GPT-4 abgegebenen Meinungen betonen einige Aspekte, die sich von denen des Menschen unterscheiden. Die Studie ergab, dass die Häufigkeit, mit der GPT-4 die Bedeutung der Forschung selbst kommentiert, menschlich ist 7,27-mal höhere Wahrscheinlichkeit als Menschen, sich zu Forschungsneuheiten zu äußern.
Sowohl GPT-4 als auch Menschen empfehlen oft zusätzliche Experimente, aber Menschen konzentrieren sich mehr auf Ablationsexperimente und GPT-4 empfiehlt, es an mehr Datensätzen zu versuchen. Die Autoren gaben an, dass diese Ergebnisse darauf hindeuten, dass GPT-4 und menschliche Gutachter verschiedene Aspekte unterschiedlich betonen und dass die Zusammenarbeit zwischen beiden potenzielle Vorteile bringen könnte.
Über quantitative Experimente hinaus geht es um
Nutzerforschung
.
An dieser Studie nahmen insgesamt 308 Forscher aus den Bereichen KI und Computerbiologie aus verschiedenen Institutionen teil. Sie luden ihre Arbeiten zur Begutachtung auf GPT-4 hoch. Das Forschungsteam sammelte ihr echtes Feedback zu den GPT-4-Begutachtungskommentaren.
Insgesamt glaubtenmehr als die Hälfte
(57,4 %)
der Teilnehmer, dass das von GPT-4 generierte Feedback sehr hilfreich war, einschließlich der Angabe einiger Punkte, an die Menschen nicht denken würden.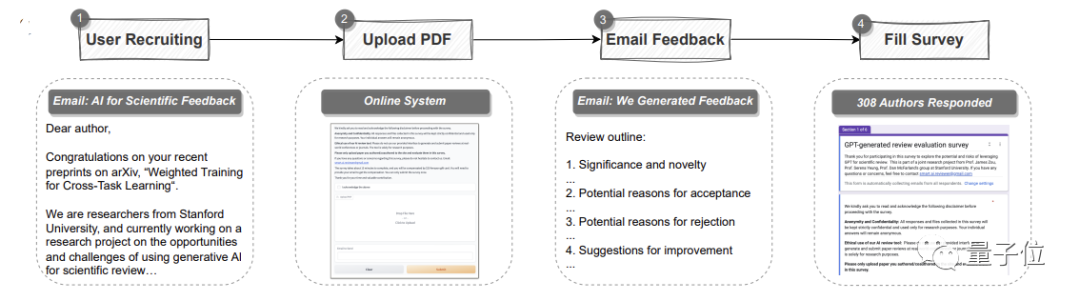 Und 82,4 % der Befragten fanden es vorteilhafter als zumindest das Feedback einiger menschlicher Rezensenten.
Und 82,4 % der Befragten fanden es vorteilhafter als zumindest das Feedback einiger menschlicher Rezensenten.
Darüber hinaus äußerte mehr als die Hälfte (50,5 %) ihre Bereitschaft, weiterhin große Modelle wie GPT-4 zur Verbesserung des Papiers zu nutzen. Einer von ihnen sagte, dass GPT-4 nur 5 Minuten braucht, um die Ergebnisse zu liefern. Dieses Feedback erfolgt sehr schnell und ist für Forscher sehr hilfreich, ihre Arbeiten zu verbessern. Natürlich betont der Autor:
Die Fähigkeiten von GPT-4 weisen auch einige Einschränkungen aufDas offensichtlichste ist, dass es sich mehr auf das „Gesamtlayout“ konzentriert und es an
tiefgehenden Vorschlägen in bestimmten technischen Bereichen mangelt ( wie Modellarchitektur). In der abschließenden Schlussfolgerung des Autors heißt es also:
Hochwertiges Feedback von menschlichen Prüfern ist vor der formellen Prüfung sehr wichtig, aber wir können zunächst die Gewässer testen, um Details wie Experimente und Konstruktionen auszugleichen, die möglicherweise erforderlich sind AuslassungNatürlich erinnern sie auch daran:An der formellen Begutachtung sollten Gutachter weiterhin unabhängig teilnehmen und sich nicht auf LLM verlassen.
Alle Autoren sind Chinesen
Diese Studie
Es gibt drei Autoren, die alle Chinesen sind und alle von der School of Computer Science der Stanford University kommen.
Sie sind:Liang Weixin, ein Doktorand an der Schule und Mitglied des Stanford AI Laboratory
(SAIL) 
- Cao Hancheng ist Doktorand im fünften Jahr an der Schule mit den Schwerpunkten Managementwissenschaften und Ingenieurwesen. Er hat sich auch den NLP- und HCI-Gruppen an der Stanford University angeschlossen. Zuvor schloss er sein Bachelor-Studium an der Fakultät für Elektrotechnik der Tsinghua-Universität ab. Papierlink: https://arxiv.org/abs/2310.01783
Das obige ist der detaillierte Inhalt vonWenn Sie Ihre Arbeit bei Nature einreichen, fragen Sie zuerst nach GPT-4! Stanford hat tatsächlich 5.000 Artikel getestet und die Hälfte der Meinungen stimmten mit denen menschlicher Rezensenten überein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So konvertieren Sie ai in ps
- Gründe, warum KI nicht in Echtzeit färben kann
- Wo befindet sich die Hauptfunktion im C-Quellprogramm?
- NUS und Byte arbeiteten branchenübergreifend zusammen, um durch Modelloptimierung ein 72-mal schnelleres Training zu erreichen, und gewannen den AAAI2023 Outstanding Paper.
- Die EMNLP-Konferenz 2022 ist offiziell abgeschlossen, der beste Langbeitrag, der beste Kurzbeitrag und weitere Auszeichnungen wurden bekannt gegeben