
Heim >Technologie-Peripheriegeräte >KI >ICCV 2023 bekannt gegeben: Beliebte Veröffentlichungen wie ControlNet und SAM wurden ausgezeichnet
ICCV 2023 bekannt gegeben: Beliebte Veröffentlichungen wie ControlNet und SAM wurden ausgezeichnet

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-04 21:37:011377Durchsuche
Die International Conference on Computer Vision (ICCV) wurde diese Woche in Paris, Frankreich, eröffnet.
Als weltweit führende akademische Konferenz im Bereich Computer Vision findet die ICCV alle zwei Jahre statt.
Die Beliebtheit von ICCV lag schon immer auf Augenhöhe mit CVPR und erreichte immer wieder neue Höchstwerte
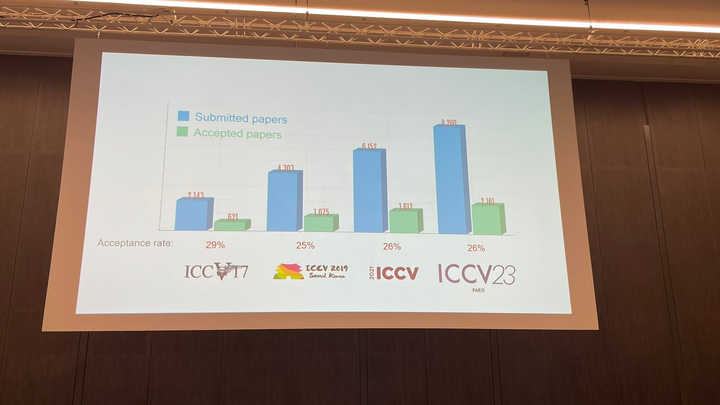
Bei der heutigen Eröffnungszeremonie gab ICCV offiziell die diesjährigen Papierdaten bekannt: Insgesamt wurden in diesem Jahr 8068 Einreichungen beim ICCV eingereicht, von denen 2160 angenommen wurden Die Akzeptanzrate liegt bei 26,8 %, was etwas höher ist als die Akzeptanzrate des vorherigen ICCV 2021 von 25,9 % beliebt
Der wichtigste Teil der heutigen Eröffnungsfeier ist zweifellos die Preisverleihung. Als nächstes werden wir nacheinander die Gewinner der besten Arbeit, der Nominierung für die beste Arbeit und der besten Studentenarbeit bekannt geben Die erste Studie wurde von Forschern der University of Toronto durchgeführt Wei, Sotiris Nousias, Rahul Gulve, David B. Lindell, Kiriakos N. Kutulakos
Beliebte Veröffentlichungen wie ControlNet und SAM wurden ausgezeichnet und die ICCV 2023 Paper Awards wurden bekannt gegeben. Dieser Artikel demonstriert experimentell das Potenzial dieses asynchronen Bildgebungsmechanismus: (1) um Szenen abzubilden, die gleichzeitig von Lichtquellen (Glühlampen, Projektoren, mehrfach gepulste Laser) beleuchtet werden, die mit deutlich unterschiedlichen Geschwindigkeiten arbeiten, ohne Synchronisierung, (2) Passives Non-Line-of -Sight-Videoerfassung; (3) Nehmen Sie Ultra-Breitbandvideos auf, die später mit 30 Hz abgespielt werden können, um alltägliche Bewegungen zu zeigen, aber auch eine Milliarde Mal langsamer, um die Ausbreitung des Lichts selbst zu zeigen
Der Inhalt, der es braucht neu geschrieben werden soll: Der zweite Artikel ist das, was wir als ControNet kennen Institution: Stanford University

Die Kernidee von ControlNet besteht darin, der Textbeschreibung einige zusätzliche Bedingungen hinzuzufügen, um das Diffusionsmodell zu steuern (z. B. stabile Diffusion), wodurch die Pose, Tiefe, Bildstruktur und andere Informationen des generierten Bilds besser gesteuert werden können.
Umgeschrieben als: Wir können zusätzliche Bedingungen in Form von Bildern eingeben, damit das Modell Canny-Kantenerkennung, Tiefenerkennung, semantische Segmentierung, Hough-Transformationslinienerkennung, Gesamtverschachtelte Kantenerkennung (HED), Erkennung menschlicher Körperhaltung usw. durchführen kann. Operationen und behalten diese Informationen im resultierenden Bild bei. Mit diesem Modell können wir Strichzeichnungen oder Graffiti direkt in Vollfarbbilder umwandeln und Bilder mit der gleichen Tiefenstruktur erzeugen. Gleichzeitig können wir auch die Generierung von Charakterhänden durch Handschlüsselpunkte optimieren Weitere Informationen finden Sie im ausführlichen Einführungsbericht auf dieser Website:
Die Reduzierung der KI-Dimensionalität trifft menschliche Maler, vinzentinische Diagramme werden in ControlNet eingeführt und Tiefen- und Kanteninformationen sind vollständig wiederverwendbar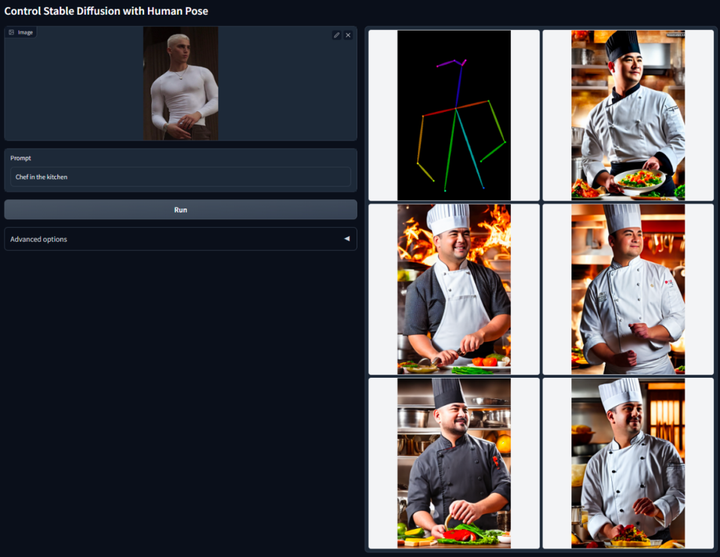
Nominierung für die beste Arbeit: SAM
Im April dieses Jahres Meta veröffentlichte einen Artikel mit dem Titel „Separate Everything (SAM)’s AI model, das Masken für Objekte in jedem Bild oder Video generieren kann.“ Diese Technologie schockierte Forscher auf dem Gebiet der Computer Vision und einige nannten sie sogar „Lebenslauf existiert nicht mehr“Jetzt wurde dieser hochkarätige Artikel für den besten Artikel nominiert.
Papieradresse:
https://arxiv.org/abs/2304.02643
CV existiert nicht mehr? Meta veröffentlicht das KI-Modell „Split Everything“, CV könnte den GPT-3-Moment einläuten
Beste studentische Arbeit
Papieradresse:
https://arxiv.org/abs/2306.05422
 Projekthomepage:
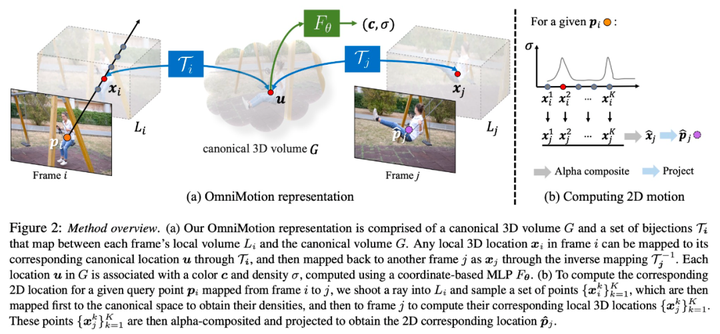
Projekthomepage:- Im Bereich Computer Vision gibt es Es gibt zwei Arten von häufig verwendeten Methoden zur Bewegungsschätzung: Verfolgung spärlicher Merkmale und dichter optischer Fluss. Allerdings haben beide Methoden einige Nachteile. Sparse-Feature-Tracking kann nicht die Bewegung aller Pixel modellieren, während ein dichter optischer Fluss keine Bewegungstrajektorien über lange Zeiträume hinweg erfassen kann
OmniMotion ist eine neue, von der Forschung vorgeschlagene Technologie, die kanonische Quasi-3D-Volumina zur Charakterisierung von Videos verwendet. OmniMotion ist in der Lage, jedes Pixel durch eine Bijektion zwischen lokalem Raum und kanonischem Raum zu verfolgen. Diese Darstellungsmethode gewährleistet nicht nur globale Konsistenz und Bewegungsverfolgung auch bei verdeckten Objekten, sondern ist auch in der Lage, beliebige Kombinationen von Kamera- und Objektbewegungen zu modellieren. Experimente haben gezeigt, dass die OmniMotion-Methode hinsichtlich der Leistung deutlich besser ist als die bestehende SOTA-Methode. „Alles verfolgen“-Videoalgorithmus Hier kommen wir
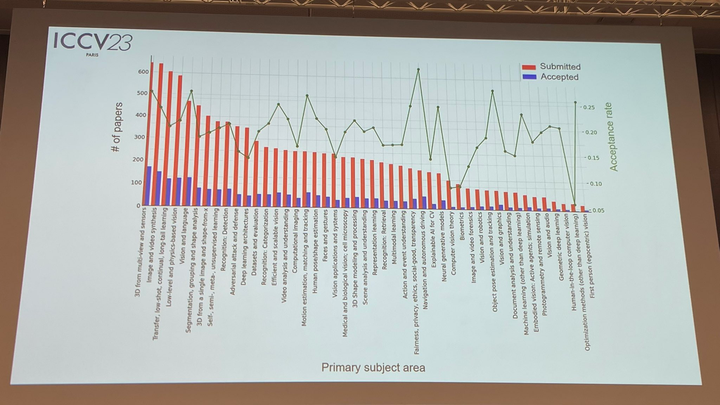
 Natürlich gibt es dieses Jahr neben diesen preisgekrönten Arbeiten im ICCV noch viele herausragende Arbeiten, die Ihre Aufmerksamkeit verdienen. Abschließend finden Sie hier eine erste Liste der 17 preisgekrönten Arbeiten.
Natürlich gibt es dieses Jahr neben diesen preisgekrönten Arbeiten im ICCV noch viele herausragende Arbeiten, die Ihre Aufmerksamkeit verdienen. Abschließend finden Sie hier eine erste Liste der 17 preisgekrönten Arbeiten. Das obige ist der detaillierte Inhalt vonICCV 2023 bekannt gegeben: Beliebte Veröffentlichungen wie ControlNet und SAM wurden ausgezeichnet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Neue Regeln für Oktober sind da! Einbeziehung neuer Verkehrszeichen, Industrie der künstlichen Intelligenz usw.
- Ministerium für Wissenschaft und Technologie: Künstliche Intelligenz als strategische aufstrebende Industrie nachdrücklich unterstützen
- Ronglian Cloud wurde in die Global Generative AI Industry Map 2023 aufgenommen
- Gehirn-Computer-Schnittstelle erstrahlt in der Realität! Das Ministerium für Industrie und Informationstechnologie wird sich in Zukunft darauf konzentrieren, sie zu fördern. Wie weit ist der Weg zur Industrialisierung?