
Heim >Technologie-Peripheriegeräte >KI >Die 10 besten Python-Bibliotheken für den Umgang mit unausgeglichenen Daten
Die 10 besten Python-Bibliotheken für den Umgang mit unausgeglichenen Daten

- 王林nach vorne
- 2023-09-30 19:53:031271Durchsuche
Datenungleichgewicht ist eine häufige Herausforderung beim maschinellen Lernen, bei dem eine Klasse deutlich zahlreicher ist als andere Klassen, was zu verzerrten Modellen und schlechter Verallgemeinerung führen kann. Es gibt verschiedene Python-Bibliotheken, die dabei helfen, unausgeglichene Daten effizient zu verarbeiten. In diesem Artikel stellen wir die zehn besten Python-Bibliotheken für den Umgang mit unausgeglichenen Daten beim maschinellen Lernen vor und stellen Codeausschnitte und Erklärungen für jede Bibliothek bereit.
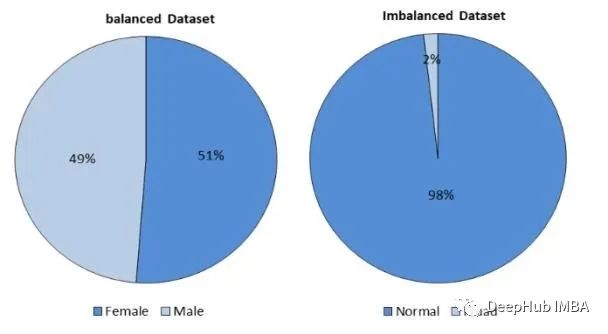
1. imbalanced-learn
imbalanced-learn ist eine Erweiterungsbibliothek von scikit-learn, die eine Vielzahl von Techniken zur Neuausrichtung von Datensätzen bereitstellen soll. Die Bibliothek bietet mehrere Optionen wie Oversampling, Undersampling und kombinierte Methoden
from imblearn.over_sampling import RandomOverSampler ros = RandomOverSampler() X_resampled, y_resampled = ros.fit_resample(X, y)
2, SMOTE
SMOTE generiert synthetische Stichproben, um den Datensatz auszugleichen.
from imblearn.over_sampling import SMOTE smote = SMOTE() X_resampled, y_resampled = smote.fit_resample(X, y)
3. ADASYN
ADASYN generiert adaptiv synthetische Proben basierend auf der Dichte einiger Proben.
from imblearn.over_sampling import ADASYN adasyn = ADASYN() X_resampled, y_resampled = adasyn.fit_resample(X, y)
4. RandomUnderSampler
RandomUnderSampler entfernt zufällig Stichproben aus der Mehrheitsklasse.
from imblearn.under_sampling import RandomUnderSampler rus = RandomUnderSampler() X_resampled, y_resampled = rus.fit_resample(X, y)
5. Tomek Links
Tomek Links können Paare von nächsten Nachbarn verschiedener Kategorien entfernen und die Anzahl mehrerer Stichproben reduzieren
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X, y)
6. SMOTEENN (SMOTE + Edited Nearest Neighbors)
SMOTEENN kombiniert SMOTE und Edited Nearest Neighbors.
from imblearn.combine import SMOTEENN smoteenn = SMOTEENN() X_resampled, y_resampled = smoteenn.fit_resample(X, y)
7. SMOTETomek (SMOTE + Tomek Links)
SMOTEENN kombiniert SMOTE und Tomek Links für Oversampling und Undersampling.
from imblearn.combine import SMOTETomek smotetomek = SMOTETomek() X_resampled, y_resampled = smotetomek.fit_resample(X, y)
8. EasyEnsemble
EasyEnsemble ist eine Ensemble-Methode, mit der ausgewogene Teilmengen der meisten Klassen erstellt werden können.
from imblearn.ensemble import EasyEnsembleClassifier ee = EasyEnsembleClassifier() ee.fit(X, y)
9. BalancedRandomForestClassifier
BalancedRandomForestClassifier ist eine Ensemble-Methode, die zufällige Wälder mit ausgeglichenen Teilstichproben kombiniert.
from imblearn.ensemble import BalancedRandomForestClassifier brf = BalancedRandomForestClassifier() brf.fit(X, y)
10. RUSBoostClassifier
RUSBoostClassifier ist eine Ensemble-Methode, die zufällige Unterabtastung und Verbesserung kombiniert.
from imblearn.ensemble import RUSBoostClassifier rusboost = RUSBoostClassifier() rusboost.fit(X, y)
Zusammenfassung
Der Umgang mit unausgeglichenen Daten ist entscheidend für die Erstellung genauer Modelle für maschinelles Lernen. Diese Python-Bibliotheken bieten verschiedene Techniken zur Lösung dieses Problems. Abhängig von Ihrem Datensatz und Ihrem Problem können Sie die am besten geeignete Methode zum effektiven Ausgleich Ihrer Daten auswählen.
Das obige ist der detaillierte Inhalt vonDie 10 besten Python-Bibliotheken für den Umgang mit unausgeglichenen Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!