
Heim >Technologie-Peripheriegeräte >KI >SupFusion: Erforschen Sie, wie Lidar-Kamera-fusionierte 3D-Erkennungsnetzwerke effektiv überwacht werden können?
SupFusion: Erforschen Sie, wie Lidar-Kamera-fusionierte 3D-Erkennungsnetzwerke effektiv überwacht werden können?

- 王林nach vorne
- 2023-09-28 21:41:071361Durchsuche
Die 3D-Erkennung auf Basis der Lidar-Kamerafusion ist eine Schlüsselaufgabe für das autonome Fahren. In den letzten Jahren sind viele LiDAR-Kamera-Fusionsmethoden entstanden und haben eine gute Leistung erzielt, diesen Methoden fehlt jedoch immer ein gut konzipierter und effektiv überwachter Fusionsprozess.
In diesem Artikel wird eine neue Trainingsstrategie namens SupFusion vorgestellt, die eine Laser-Radar-Kamera-Fusion bereitstellt zusätzliche Überwachung auf Funktionsebene und verbessert die Erkennungsleistung erheblich. Die Methode umfasst die Datenerweiterungsmethode Polar Sampling zur Verschlüsselung spärlicher Ziele und zum Training von Hilfsmodellen, um hochwertige Merkmale für die Überwachung zu generieren. Diese Funktionen werden verwendet, um das Lidar-Kamera-Fusionsmodell zu trainieren und die fusionierten Features zu optimieren, um die Generierung hochwertiger Features zu simulieren. Darüber hinaus wird ein einfaches, aber effektives Deep-Fusion-Modul vorgeschlagen, das im Vergleich zu bisherigen Fusionsmethoden mit der SupFusion-Strategie kontinuierlich eine überlegene Leistung erzielt. Die Methode in diesem Artikel hat die folgenden Vorteile: Erstens führt SupFusion eine zusätzliche Überwachung auf Funktionsebene ein, die die Erkennungsleistung von Lidar-Kameras verbessern kann, ohne zusätzliche Inferenzkosten zu erhöhen. Zweitens kann die vorgeschlagene Tiefenfusion die Fähigkeiten des Detektors kontinuierlich verbessern. Die vorgeschlagenen SupFusion- und Deep-Fusion-Module sind Plug-and-Play-Module und dieser Artikel demonstriert ihre Wirksamkeit durch umfangreiche Experimente. Im KITTI-Benchmark für die 3D-Erkennung auf Basis mehrerer Lidar-Kameras wurde eine 3D-mAP-Verbesserung von ca. 2 % erreicht!
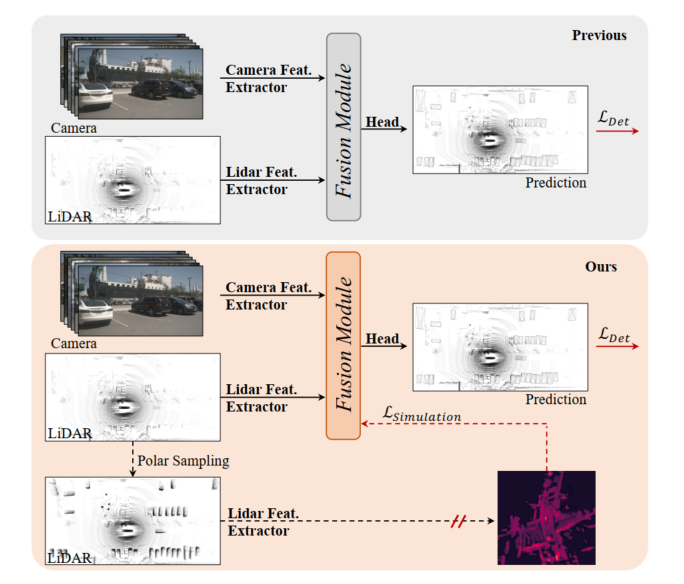
Abbildung 1: Oben, vorheriges 3D-Erkennungsmodell der Lidar-Kamera, das Fusionsmodul ist durch Erkennungsverlust optimiert. Unten: Das in diesem Artikel vorgeschlagene SupFusion führt eine Hilfsüberwachung durch hochwertige Funktionen ein, die von Hilfsmodellen bereitgestellt werden.
Die auf Lidar-Kamerafusion basierende 3D-Erkennung ist eine kritische und herausfordernde Aufgabe beim autonomen Fahren und in der Robotik. Bisherige Methoden projizieren die Kameraeingabe immer über intrinsische und extrinsische Parameter auf das Lidar-BEV oder den Voxelraum, um Lidar- und Kamerafunktionen auszurichten. Anschließend wird eine einfache Verkettung oder Summierung eingesetzt, um die zusammengeführten Merkmale für die endgültige Erkennung zu erhalten. Darüber hinaus haben einige auf Deep Learning basierende Fusionsmethoden vielversprechende Leistungen erbracht. Bisherige Fusionsmethoden optimieren jedoch immer direkt die 3D/2D-Merkmalsextraktions- und Fusionsmodule durch Erkennungsverluste, denen es an sorgfältigem Design und effektiver Überwachung auf Merkmalsebene mangelt, was ihre Leistung einschränkt.
In den letzten Jahren haben Destillationsmethoden große Verbesserungen bei der Überwachung auf Funktionsebene für die 3D-Erkennung gezeigt. Einige Methoden bieten LIDAR-Funktionen, um das 2D-Backbone bei der Schätzung von Tiefeninformationen basierend auf der Kameraeingabe zu unterstützen. Darüber hinaus bieten einige Methoden Lidar-Kamerafusionsfunktionen zur Überwachung des Lidar-Backbones, um globale und kontextbezogene Darstellungen aus Lidar-Eingaben zu lernen. Durch die Einführung einer Hilfsüberwachung auf Merkmalsebene durch die Simulation robusterer und qualitativ hochwertigerer Merkmale kann der Detektor geringfügige Verbesserungen bewirken. Davon inspiriert besteht die natürliche Lösung für die Funktionsfusion von Lidar-Kameras darin, stärkere, qualitativ hochwertige Funktionen bereitzustellen und eine zusätzliche Überwachung für die 3D-Erkennung von Lidar-Kameras einzuführen!
Um die Leistung der fusionierten 3D-Erkennung auf Basis von Lidar-Kameras zu verbessern, wird in diesem Artikel eine überwachte Lidar-Kamera-Fusion-Methode namens SupFusion vorgeschlagen. Diese Methode erreicht dies durch die Generierung hochwertiger Merkmale und eine effektive Überwachung der Fusions- und Merkmalsextraktionsprozesse. Zunächst trainieren wir ein Hilfsmodell, um hochwertige Funktionen bereitzustellen. Im Gegensatz zu früheren Methoden, die größere Modelle oder zusätzliche Daten nutzen, schlagen wir eine neue Methode zur Datenerweiterung namens Polar Sampling vor. Polar Sampling erhöht dynamisch die Dichte von Zielen aus spärlichen LIDAR-Daten, wodurch sie leichter zu erkennen sind und die Merkmalsqualität, wie z. B. genaue Erkennungsergebnisse, verbessert wird. Anschließend trainieren wir einfach einen Detektor auf Basis der Lidar-Kamerafusion und führen eine zusätzliche Überwachung auf Funktionsebene ein. In diesem Schritt speisen wir die rohen Lidar- und Kameraeingaben in das 3D/2D-Backbone- und Fusionsmodul ein, um fusionierte Features zu erhalten. Die fusionierten Merkmale werden zur endgültigen Vorhersage in den Erkennungskopf eingespeist, während die Hilfsüberwachung die fusionierten Merkmale in qualitativ hochwertige Merkmale modelliert. Diese Funktionen werden durch vorab trainierte Hilfsmodelle und erweiterte LIDAR-Daten erhalten. Auf diese Weise kann die vorgeschlagene Überwachung auf Merkmalsebene es dem Fusionsmodul ermöglichen, robustere Merkmale zu generieren und die Erkennungsleistung weiter zu verbessern. Um die Funktionen von Lidar und Kamera besser zu verschmelzen, schlagen wir ein einfaches und effektives Deep-Fusion-Modul vor, das aus gestapelten MLP-Blöcken und dynamischen Fusionsblöcken besteht. SupFusion kann die Fähigkeiten des Deep-Fusion-Moduls voll ausschöpfen und die Erkennungsgenauigkeit kontinuierlich verbessern!
Hauptbeiträge dieses Artikels:
- Schlägt eine neue überwachte Fusionstrainingsstrategie SupFusion vor, die hauptsächlich aus einem Prozess zur Generierung hochwertiger Merkmale besteht, und schlägt erstmals einen zusätzlichen überwachten Verlust auf Merkmalsebene für eine robuste Extraktion von Fusionsmerkmalen und eine genaue 3D-Erkennung vor.
- Um qualitativ hochwertige Funktionen in SupFusion zu erhalten, wird eine Datenerweiterungsmethode namens „Polar Sampling“ vorgeschlagen, um spärliche Ziele zu verschlüsseln. Darüber hinaus wird ein effektives Tiefenfusionsmodul vorgeschlagen, um die Erkennungsgenauigkeit kontinuierlich zu verbessern.
- Führte umfangreiche Experimente auf der Grundlage mehrerer Detektoren mit unterschiedlichen Fusionsstrategien durch und erzielte eine mAP-Verbesserung von etwa 2 % gegenüber dem KITTI-Benchmark.
Die vorgeschlagene Methode
Der Prozess zur Generierung hochwertiger Merkmale ist in der folgenden Abbildung dargestellt. Für jedes gegebene LiDAR-Beispiel wird das spärliche Ziel durch polares Einfügen verschlüsselt und das polare Einfügen berechnet die zu extrahierende Ausrichtung und Drehung Fragen Sie dichte Ziele aus der Datenbank ab und fügen Sie durch Einfügen zusätzliche Punkte für spärliche Ziele hinzu. In diesem Artikel wird zunächst das Hilfsmodell mit erweiterten Daten trainiert und die erweiterten LIDAR-Daten in das Hilfsmodell eingespeist, um nach seiner Konvergenz hochwertige Merkmale f* zu generieren.
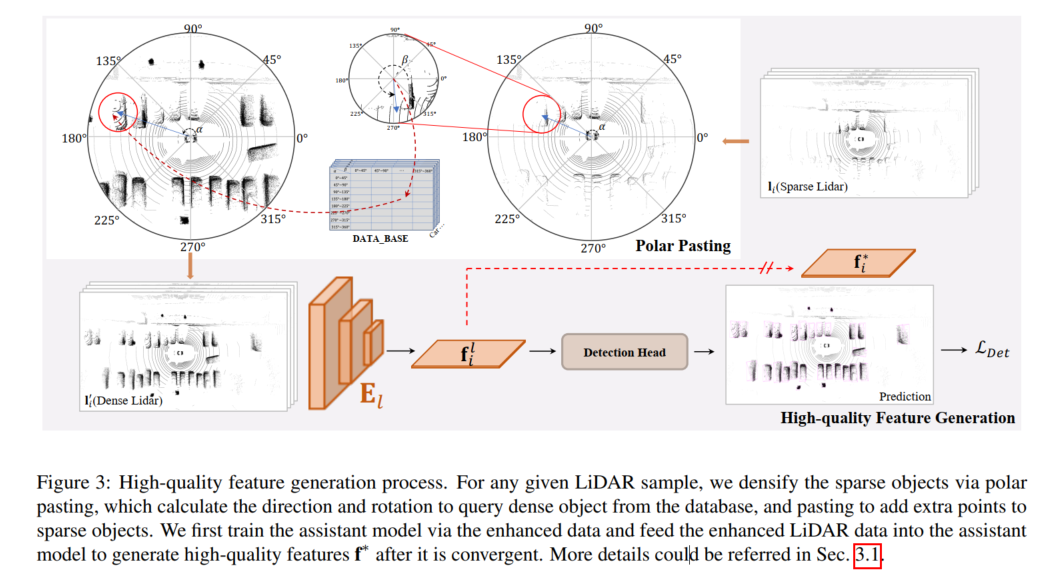
Hochwertige Feature-Generierung
Um eine Überwachung auf Feature-Ebene in SupFusion bereitzustellen, wird ein Hilfsmodell übernommen, um hochwertige Features aus den erweiterten Daten zu erfassen, wie in Abbildung 3 dargestellt. Zunächst wird ein Hilfsmodell trainiert, um qualitativ hochwertige Funktionen bereitzustellen. Für jede Probe in D werden die spärlichen LIDAR-Daten durch Polarpaste erweitert, um verbesserte Daten zu erhalten. Dabei wird das alternative Ziel durch Hinzufügen der in der Polargruppierung generierten Punktmenge verschlüsselt. Nachdem das Hilfsmodell konvergiert ist, werden die verbesserten Proben dann in das optimierte Hilfsmodell eingegeben, um hochwertige Merkmale für das Training des 3D-Erkennungsmodells der Lidar-Kamera zu erfassen. Um eine bessere Anwendung auf einen bestimmten Lidar-Kameradetektor zu ermöglichen und die Implementierung zu vereinfachen, übernehmen wir hier einfach den Lidar-Zweigdetektor als Hilfsmodell!
Detektortraining
Für jeden gegebenen Lidar-Kameradetektor wird das Modell mithilfe der vorgeschlagenen Hilfsüberwachung auf Funktionsebene trainiert. Anhand einer Probe , werden das Lidar und die Kamera zunächst in die 3D- und 2D-Encoder eingegeben, um die entsprechenden Merkmale zu erfassen. Diese Merkmale werden in das Fusionsmodell eingegeben, um die fusionierten Merkmale zu generieren und zur Erkennung zu fließen. Machen Sie die endgültige Vorhersage in Dein Kopf. Darüber hinaus wird die vorgeschlagene Hilfsüberwachung eingesetzt, um fusionierte Features mit hochwertigen Features zu simulieren, die aus dem vorab trainierten Hilfsmodell und erweiterten LiDAR-Daten generiert werden. Der obige Prozess kann wie folgt formuliert werden:
Polar Sampling
Um qualitativ hochwertige Funktionen bereitzustellen, stellt dieser Artikel eine neue Datenverbesserungsmethode namens Polar Sampling in der vorgeschlagenen SupFusion vor, um das spärliche Problem This zu lösen Das Problem führt häufig zu Erkennungsfehlern. Zu diesem Zweck führen wir eine dichte Verarbeitung dünner Ziele in LIDAR-Daten durch, ähnlich wie bei der Verarbeitung dichter Ziele. Die Erfassung von Polarkoordinaten besteht aus zwei Teilen: der Gruppierung von Polarkoordinaten und dem Einfügen von Polarkoordinaten. Bei der Gruppierung von Polarkoordinaten erstellen wir hauptsächlich eine Datenbank zum Speichern dichter Ziele, die zum Einfügen von Polarkoordinaten verwendet wird, sodass spärliche Ziele dichter werden.
Unter Berücksichtigung der Eigenschaften des Lidar-Sensors sind die gesammelten Punktwolkendaten natürlich spezifisch Dichteverteilung. Beispielsweise hat ein Objekt mehr Punkte auf seiner dem Lidar-Sensor zugewandten Oberfläche und weniger Punkte auf den gegenüberliegenden Seiten. Die Dichteverteilung wird hauptsächlich durch Orientierung und Drehung beeinflusst, während die Dichte der Punkte hauptsächlich von der Entfernung abhängt. Objekte, die näher am Lidar-Sensor liegen, weisen eine dichtere Punktdichte auf. Davon inspiriert besteht das Ziel dieser Arbeit darin, spärliche Ziele in großer Entfernung und dichte Ziele in kurzer Entfernung entsprechend der Richtung und Drehung der spärlichen Ziele zu verdichten, um die Dichteverteilung aufrechtzuerhalten. Wir erstellen ein Polarkoordinatensystem für die gesamte Szene und das Ziel basierend auf der Mitte der Szene und dem spezifischen Ziel und definieren die positive Richtung des Lidar-Sensors als 0 Grad, um die entsprechende Richtung und Drehung zu messen. Anschließend sammeln wir Ziele mit ähnlichen Dichteverteilungen (z. B. mit ähnlicher Ausrichtung und Rotation) und generieren für jede Gruppe ein dichtes Ziel in polaren Gruppierungen und verwenden dieses in polarer Paste, um spärliche Ziele zu verdichten
Polare Gruppierung
Wie in Abbildung 4 dargestellt Hier wird eine Datenbank B erstellt, um den generierten dichten Objektpunktsatz l entsprechend der Richtung und Drehung in der Polargruppierung zu speichern, die in Abbildung 4 als α und β aufgezeichnet sind!
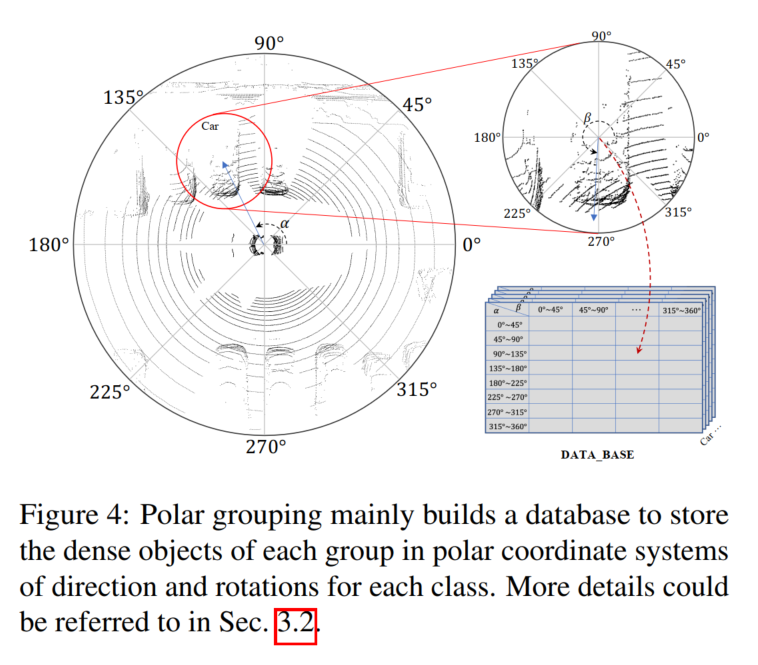
Durchsuchen Sie zunächst den gesamten Datensatz, berechnen Sie den Polarwinkel aller Ziele nach Position und stellen Sie die Drehung im Benchmark bereit. Zweitens teilen Sie die Ziele anhand ihrer Polarwinkel in Gruppen ein. Teilen Sie die Ausrichtung und Drehung manuell in N Gruppen ein, und für jeden Zielpunktsatz l können Sie ihn entsprechend dem Index in die entsprechende Gruppe einordnen:
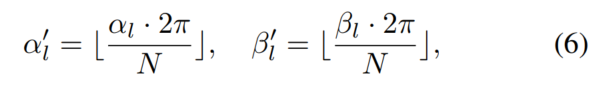
Polar Pasting
Wie in Abbildung 2 dargestellt, wird Polar Pasting verwendet, um spärliche LIDAR-Daten zu verbessern, um Hilfsmodelle zu trainieren und hochwertige Features zu generieren. Wenn eine LiDAR-Stichprobe ,,,, Ziele enthält, kann für jedes Ziel die gleiche Ausrichtung und Drehung wie beim Gruppierungsprozess berechnet werden, und die dichten Ziele werden von B gemäß der Beschriftung und dem Index abgefragt, die aus Gleichung erhalten werden können. 6 für die erweiterte Stichprobe Alle Ziele erreichen und erweiterte Statistiken erhalten.
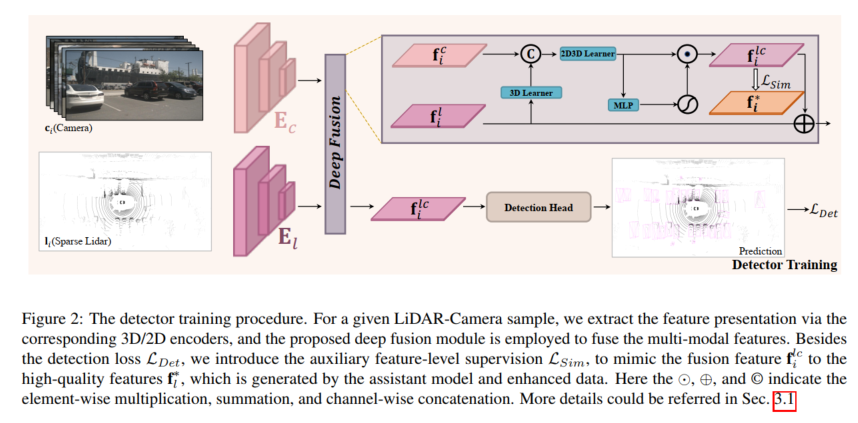
Deep Fusion
Um die hochwertigen Funktionen zu simulieren, die durch erweiterte LiDAR-Daten generiert werden, ist das Fusionsmodell darauf ausgelegt, die fehlenden Informationen spärlicher Ziele aus den satten Farb- und Kontextfunktionen in der Kameraeingabe zu extrahieren. Zu diesem Zweck schlägt dieser Artikel ein Deep-Fusion-Modul vor, um Bildfunktionen zu nutzen und Lidar-Demonstrationen durchzuführen. Die vorgeschlagene Deep Fusion besteht hauptsächlich aus 3D-Lernern und 2D-3D-Lernern. Der 3D-Learner ist eine einfache Faltungsschicht, die zum Übertragen von 3D-Renderings in den 2D-Raum verwendet wird. Um dann 2D-Features und 3D-Renderings (z. B. im 2D-Raum) zu verbinden, wird ein 2D-3D-Lerner verwendet, um LiDAR-Kamerafunktionen zu fusionieren. Schließlich werden die fusionierten Features durch MLP und Aktivierungsfunktionen gewichtet, die als Ausgabe des Deep-Fusion-Moduls wieder zu den ursprünglichen Lidar-Features hinzugefügt werden. Der 2D-3D-Lerner besteht aus gestapelten MLP-Blöcken der Tiefe K und lernt, Kamerafunktionen zu nutzen, um LIDAR-Darstellungen spärlicher Ziele zu vervollständigen und hochwertige Merkmale dichter LIDAR-Ziele zu simulieren.
Experimentelle Vergleichsanalyse
Experimentelle Ergebnisse (mAP@R40 %). Hier sind drei Kategorien von einfachen, mittleren (mod.) und harten Fällen sowie die Gesamtleistung aufgeführt. Hier repräsentieren L, LC, LC* den entsprechenden Lidar-Detektor, den Lidar-Kamera-Fusionsdetektor und die Ergebnisse des Vorschlags dieses Artikels. Δ steht für eine Verbesserung. Die besten Ergebnisse sind fett gedruckt, wobei L voraussichtlich das Hilfsmodell ist und mit dem erweiterten Validierungssatz getestet wird. MVXNet wird basierend auf mmdetection3d neu implementiert. PV-RCNN-LC und Voxel RCNN LC werden basierend auf dem Open-Source-Code von VFF neu implementiert.
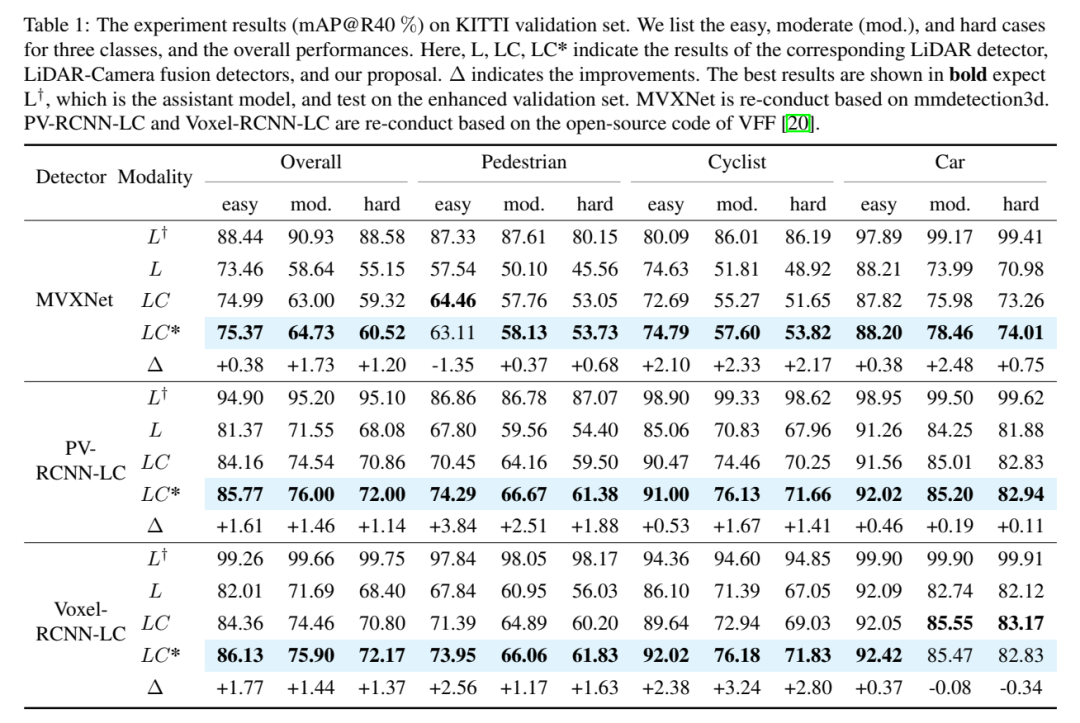
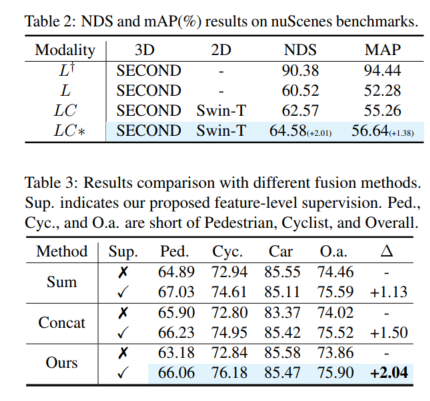
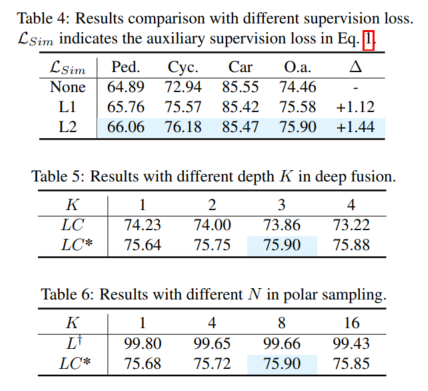
Umgeschriebener Inhalt: Gesamtleistung. Gemäß den Vergleichsergebnissen in Tabelle 1 zeigt der Vergleich von 3DmAP@R40 basierend auf drei Detektoren die Gesamtleistung jeder Kategorie und jeder Schwierigkeitsklasse. Es ist deutlich zu erkennen, dass durch die Einführung eines zusätzlichen Kameraeingangs die Lidar-Kameramethode (LC) den Lidar-basierten Detektor (L) in der Leistung übertrifft. Durch die Einführung von Polarsampling zeigt das Hilfsmodell (L†) eine bewundernswerte Leistung auf dem erweiterten Validierungssatz (z. B. über 90 % mAP). Durch die zusätzliche Überwachung mit hochwertigen Funktionen und dem vorgeschlagenen Deep-Fusion-Modul verbessert unser Vorschlag kontinuierlich die Erkennungsgenauigkeit. Im Vergleich zum Basismodell (LC) erreicht unser Vorschlag beispielsweise eine 3D-mAP-Verbesserung von +1,54 % bzw. +1,24 % bei mittleren und harten Zielen. Darüber hinaus haben wir auch Experimente mit dem nuScenes-Benchmark auf Basis von SECOND-LC durchgeführt. Wie in Tabelle 2 gezeigt, wurden NDS und mAP um +2,01 % bzw. +1,38 % verbessert. Im Vergleich zum Basismodell verbessern SupFusion und Deep Fusion nicht nur die Gesamtleistung, sondern auch die Erkennungsleistung jeder Kategorie, einschließlich Fußgänger. Beim Vergleich der durchschnittlichen Verbesserung in drei Kategorien (z. B. mittlerer Fall) können folgende Beobachtungen gemacht werden: Radfahrer sahen die größte Verbesserung (+2,41 %), während Fußgänger und Autos Verbesserungen von +1,35 % bzw. +0,86 % verzeichneten. Die Gründe liegen auf der Hand: (1) Autos sind leichter zu erkennen und erzielen bessere Ergebnisse als Fußgänger und Radfahrer und daher schwieriger zu verbessern. (2) Radfahrer erzielen mehr Verbesserungen als Fußgänger, da Fußgänger kein Raster bilden und weniger dichte Ziele erzeugen als Radfahrer und daher geringere Leistungsverbesserungen erzielen!
 Bitte klicken Sie auf den folgenden Link, um den Originalinhalt anzuzeigen: https://mp.weixin.qq.com/s/vWew2p9TrnzK256y-A4UFw
Bitte klicken Sie auf den folgenden Link, um den Originalinhalt anzuzeigen: https://mp.weixin.qq.com/s/vWew2p9TrnzK256y-A4UFw

Das obige ist der detaillierte Inhalt vonSupFusion: Erforschen Sie, wie Lidar-Kamera-fusionierte 3D-Erkennungsnetzwerke effektiv überwacht werden können?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Trainieren Sie einfach einmal, um neue 3D-Szenen zu generieren! Die Entwicklungsgeschichte von Googles „Light Field Neural Rendering'
- Wie lange wird es dauern, bis autonomes Fahren realisierbar ist?
- Autonomes Fahren lässt sich durch Dimensionsreduktion nur schwer angreifen
- Wie entwickelt man autonomes Fahren und das Internet der Fahrzeuge in PHP?
- Autonomes Fahren und intelligente Netzwerktechnologie in Java