
Heim >Technologie-Peripheriegeräte >KI >Mit 100.000 US-Dollar + 26 Tagen wurde ein kostengünstiges LLM mit 100 Milliarden Parametern geboren
Mit 100.000 US-Dollar + 26 Tagen wurde ein kostengünstiges LLM mit 100 Milliarden Parametern geboren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-20 15:49:01854Durchsuche

Papier: https://arxiv.org/pdf/2309.03852.pdf
-
Der Inhalt, der neu geschrieben werden muss, ist: Modelllink: https://huggingface.co/CofeAI/FLM- 101B
Sprache ist symbolischer Natur. Es gab einige Studien, in denen Symbole anstelle von Kategoriebezeichnungen verwendet wurden, um den Intelligenzgrad von LLMs zu bewerten. In ähnlicher Weise verwendete das Team einen symbolischen Mapping-Ansatz, um die Fähigkeit des LLM zu testen, auf unsichtbare Kontexte zu verallgemeinern.
Eine wichtige Fähigkeit der menschlichen Intelligenz besteht darin, vorgegebene Regeln zu verstehen und entsprechende Maßnahmen zu ergreifen. Diese Testmethode wird häufig in verschiedenen Teststufen eingesetzt. Daher wird hier das Regelverständnis zum zweiten Test.
Umgeschriebener Inhalt: Pattern Mining ist ein wichtiger Teil der Intelligenz, der Induktion und Deduktion umfasst. In der Geschichte der wissenschaftlichen Entwicklung spielt diese Methode eine entscheidende Rolle. Darüber hinaus erfordern Testfragen in verschiedenen Wettbewerben häufig diese Beantwortungsfähigkeit. Aus diesen Gründen haben wir Pattern Mining als dritten Bewertungsindikator gewählt
Der letzte und sehr wichtige Indikator ist die Anti-Interferenz-Fähigkeit, die auch eine der Kernfähigkeiten der Intelligenz ist. Studien haben gezeigt, dass sowohl Sprache als auch Bilder leicht durch Lärm gestört werden. Vor diesem Hintergrund verwendete das Team die Störfestigkeit als abschließende Bewertungsgröße.
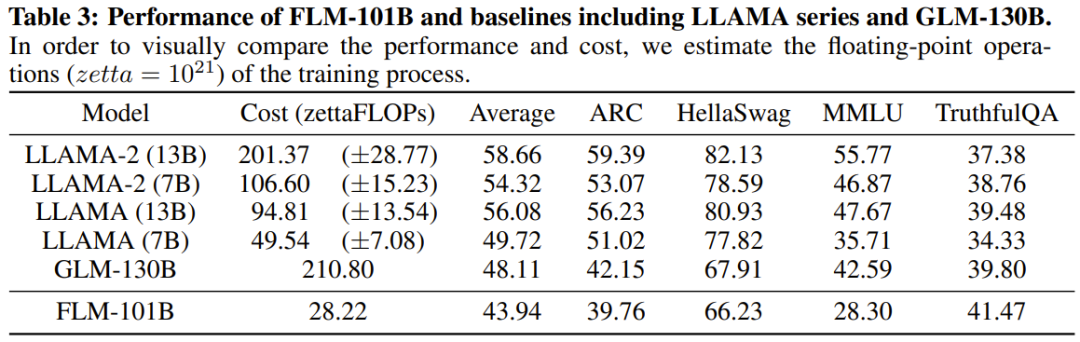
Der Forscher gab an, dass es sich hierbei um einen LLM-Forschungsversuch handelt, mehr als 100 Milliarden Parameter mithilfe einer Wachstumsstrategie von Grund auf zu trainieren. Gleichzeitig ist dies auch das derzeit kostengünstigste 100-Milliarden-Parameter-Modell, das nur 100.000 US-Dollar kostet. Die Forscher glauben, dass diese Methode auch der breiteren wissenschaftlichen Forschungsgemeinschaft helfen kann.
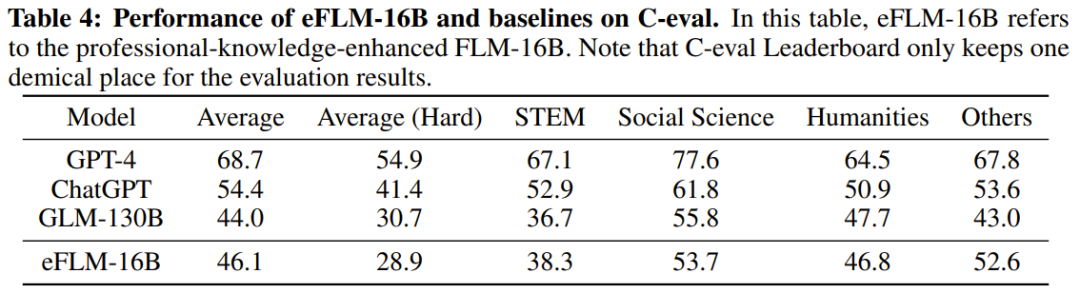
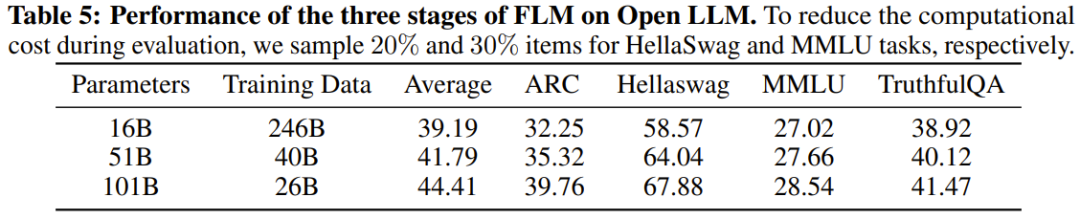
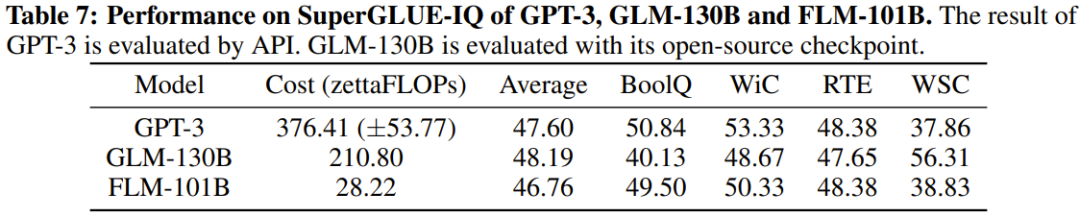
Die Forscher führten außerdem experimentelle Vergleiche des neuen Modells mit zuvor leistungsstarken Modellen durch, einschließlich der Verwendung wissensorientierter Benchmarks und eines neu vorgeschlagenen Benchmarks zur systematischen IQ-Bewertung. Experimentelle Ergebnisse zeigen, dass das Modell FLM-101B wettbewerbsfähig und robust ist
Das Team wird Modellprüfpunkte, Code, zugehörige Tools usw. veröffentlichen, um die Forschung und Entwicklung von zweisprachigem LLM in Chinesisch und Englisch mit einer Skala von 100 Milliarden Parametern zu fördern.


Das obige ist der detaillierte Inhalt vonMit 100.000 US-Dollar + 26 Tagen wurde ein kostengünstiges LLM mit 100 Milliarden Parametern geboren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in die MySQL-Theorie und Grundkenntnisse
- Die Peking-Universität und Alibaba gründen ein gemeinsames Labor, das sich auf die Theorie der künstlichen Intelligenz und die Forschung zu innovativen Algorithmen konzentriert
- Entdeckung der drei wichtigsten Python-Modelle und der zehn häufigsten Algorithmusbeispiele