
Heim >Technologie-Peripheriegeräte >KI >SurroundOcc: Surround 3D-Belegungsraster, neues SOTA!
SurroundOcc: Surround 3D-Belegungsraster, neues SOTA!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-18 20:25:011820Durchsuche
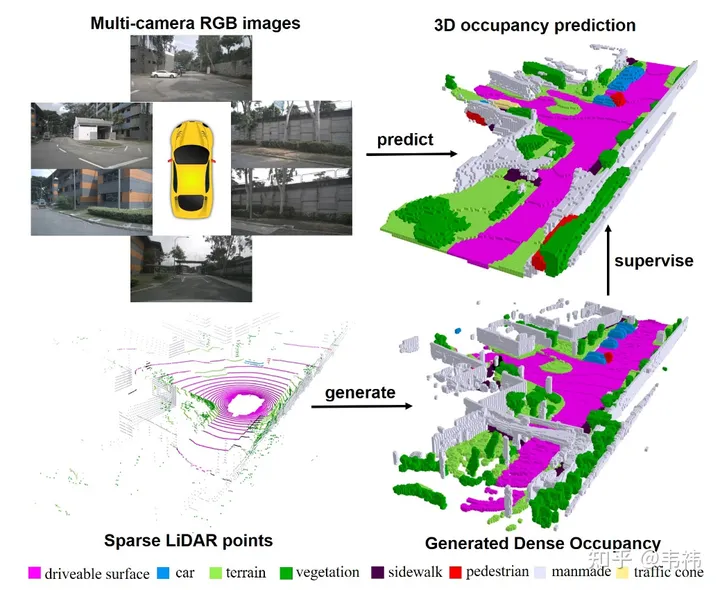
In dieser Arbeit haben wir einen dichten Belegungs-Rasterdatensatz aus Punktwolken mit mehreren Frames erstellt und ein dreidimensionales Belegungs-Rasternetzwerk basierend auf der transformatorbasierten 2D-3D-Unet-Struktur entworfen. Wir fühlen uns geehrt, dass unser Artikel in ICCV 2023 aufgenommen wurde. Der Projektcode ist jetzt Open Source und jeder ist herzlich eingeladen, ihn auszuprobieren.

arXiv: https://arxiv.org/pdf/2303.09551.pdf
Code: https://github.com/weiyithu/SurroundOcc
Homepage-Link: https://weiyithu.github.io/ SurroundOcc/
Ich war in letzter Zeit wie verrückt auf der Suche nach einem Job und hatte keine Zeit zum Schreiben. Als ich meine Arbeit beendet hatte, dachte ich, es wäre besser, einen zu schreiben Zhihu-Zusammenfassung. Tatsächlich ist die Einleitung des Artikels bereits von verschiedenen öffentlichen Stellen gut geschrieben, und dank ihrer Publizität können Sie sich direkt auf das Herzstück des autonomen Fahrens beziehen: nuScenes SOTA! SurroundOcc: Rein visuelles 3D-Belegungsvorhersagenetzwerk für autonomes Fahren (Tsinghua & Tianda). Im Allgemeinen gliedert sich der Beitrag in zwei Teile. Ein Teil befasst sich mit der Verwendung von LIDAR-Punktwolken mit mehreren Frames zum Aufbau eines dichten Belegungsdatensatzes und der andere Teil befasst sich mit dem Entwurf eines Netzwerks für die Belegungsvorhersage. Tatsächlich ist der Inhalt beider Teile relativ einfach und leicht zu verstehen. Wenn Sie etwas nicht verstehen, können Sie mich jederzeit fragen. In diesem Artikel möchte ich also über etwas anderes als die These sprechen. Zum einen geht es darum, die aktuelle Lösung zu verbessern, um sie einfacher bereitzustellen, und zum anderen geht es um die zukünftige Entwicklungsrichtung.
Bereitstellung
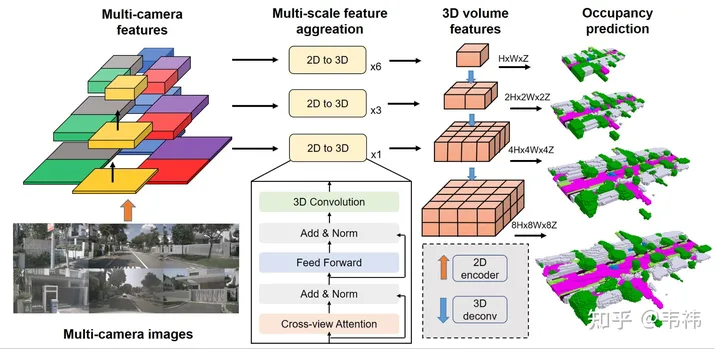
Ob ein Netzwerk einfach bereitzustellen ist, hängt hauptsächlich davon ab, ob es Operatoren gibt, die auf der Platinenseite schwer zu implementieren sind. Die beiden schwierigeren Operatoren in der SurroundOcc-Methode sind der Transformator Schicht und 3D-Faltung.
Die Hauptfunktion des Transformators besteht darin, 2D-Features in 3D-Raum umzuwandeln. Tatsächlich kann dieser Teil auch mit LSS, Homography oder sogar mlp implementiert werden, sodass dieser Teil des Netzwerks entsprechend der implementierten Lösung geändert werden kann. Aber meines Wissens ist die Transformatorlösung nicht kalibrierungsempfindlich und weist im Vergleich zu anderen Lösungen eine bessere Leistung auf. Es wird empfohlen, dass diejenigen, die in der Lage sind, den Transformatoreinsatz zu implementieren, die Originallösung verwenden.
Für die 3D-Faltung können Sie sie durch eine 2D-Faltung ersetzen. Hier müssen Sie das ursprüngliche 3D-Feature von (C, H, W, Z) in das 2D-Feature von (C* Z, H, W) umformen und dann Sie können die 2D-Faltung zur Merkmalsextraktion verwenden. Im letzten Schritt der Belegungsvorhersage können Sie sie wieder in (C, H, W, Z) umformen und eine Überwachung durchführen. Andererseits verbraucht die Skip-Verbindung aufgrund ihrer höheren Auflösung mehr Videospeicher. Während der Bereitstellung kann sie entfernt werden und es bleibt nur die Ebene mit der minimalen Auflösung übrig. Unser Experiment hat ergeben, dass diese beiden Vorgänge in der 3D-Faltung einige Drop-Punkte bei Nuscenes haben, aber der Umfang des Datensatzes der Branche ist viel größer als bei Nuscenes, und manchmal ändern sich einige Schlussfolgerungen, und die Drop-Punkte sollten kleiner oder gar nicht sein.
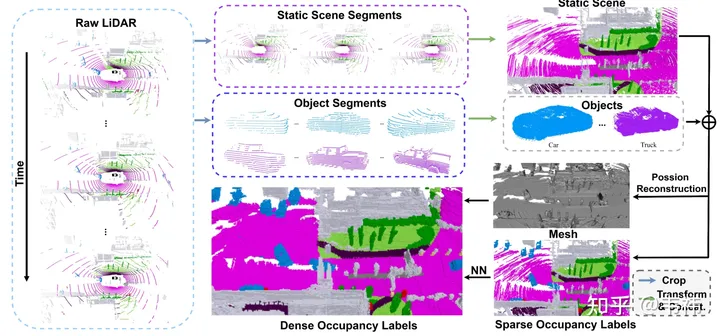
In Bezug auf die Datensatzkonstruktion ist die Poisson-Rekonstruktion der zeitaufwändigste Schritt. Wir verwenden den Nuscenes-Datensatz, der zur Erfassung 32-Zeilen-Lidar verwendet. Selbst bei Verwendung der Multi-Frame-Stitching-Technologie haben wir festgestellt, dass die genähte Punktwolke immer noch viele Löcher aufweist. Deshalb haben wir die Poisson-Rekonstruktion eingesetzt, um diese Löcher zu füllen. Allerdings sind viele derzeit in der Branche verwendete Lidar-Punktwolken relativ dicht, wie z. B. M1, RS128 usw. Daher kann in diesem Fall der Poisson-Rekonstruktionsschritt weggelassen werden, um die Erstellung des Datensatzes zu beschleunigen
Andererseits verwendet SurroundOcc den in Nuscenes mit Anmerkungen versehenen dreidimensionalen Zielerkennungsrahmen, um statische Szenen und dynamische Objekte zu trennen. In der tatsächlichen Anwendung kann jedoch Autolabel, ein großes dreidimensionales Zielerkennungs- und -verfolgungsmodell, verwendet werden, um den Erkennungsrahmen jedes Objekts in der gesamten Sequenz zu erhalten. Im Vergleich zu manuell annotierten Beschriftungen weisen die mit großen Modellen erzielten Ergebnisse definitiv einige Fehler auf. Die offensichtlichste Manifestation ist das Phänomen der Geisterbilder nach dem Zusammenfügen mehrerer Objektrahmen. Tatsächlich stellt die Besetzung jedoch keine so hohen Anforderungen an die Form von Objekten. Solange die Position des Erkennungsrahmens relativ genau ist, kann er die Anforderungen erfüllen.
Zukünftige Wegbeschreibungen
Die aktuelle Methode basiert immer noch auf Lidar, um Belegungsüberwachungssignale bereitzustellen, aber viele Autos, insbesondere einige Autos mit Fahrassistenz auf niedrigem Niveau, verfügen nicht über Lidar. Diese Autos können eine große Menge an RGB-Daten zurückübertragen Schattenmodus, dann ist eine zukünftige Richtung, ob wir RGB nur für selbstüberwachtes Lernen verwenden können. Eine natürliche Lösung besteht darin, NeRF zur Überwachung zu verwenden. Insbesondere bleibt der vordere Backbone-Teil unverändert, um eine Belegungsvorhersage zu erhalten, und dann wird Voxel-Rendering verwendet, um das RGB aus jeder Kameraperspektive zu erhalten, und der Verlust erfolgt mit dem wahren RGB-Wert Erstellen Sie ein Überwachungssignal. Es ist jedoch schade, dass diese einfache Methode nicht sehr gut funktioniert hat, als wir sie ausprobiert haben. Der mögliche Grund dafür ist, dass die Reichweite der Outdoor-Szene zu groß ist und der Nerf sie möglicherweise nicht halten kann, aber es ist auch möglich dass wir es nicht richtig eingestellt haben. Sie können es noch einmal versuchen.
Die andere Richtung ist Timing & Besetzungsfluss. Tatsächlich ist der Belegungsfluss für nachgelagerte Aufgaben weitaus nützlicher als die Einzelbildbesetzung. Während des ICCV hatten wir keine Zeit, den Datensatz zum Beschäftigungsfluss zusammenzustellen, und als wir das Papier veröffentlichten, mussten wir viele Basislinien für den Beschäftigungsfluss vergleichen, sodass wir zu diesem Zeitpunkt nicht daran gearbeitet haben. Für Timing-Netzwerke können Sie auf die Lösungen von BEVFormer und BEVDet4D zurückgreifen, die relativ einfach und effektiv sind. Der schwierige Teil ist immer noch der Flussdatensatz. Allgemeine Objekte können mithilfe des dreidimensionalen Zielerkennungsrahmens der Sequenz berechnet werden, aber speziell geformte Objekte wie kleine Tierplastiktüten müssen möglicherweise mithilfe der Szenenflussmethode annotiert werden.

Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
Das obige ist der detaillierte Inhalt vonSurroundOcc: Surround 3D-Belegungsraster, neues SOTA!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Technologie ist RPA?
- Was sind Web-Frontend-Technologien?
- Wie viel wissen Sie über die Trägheitsnavigationstechnologie für autonomes Fahren?
- Dieser Artikel vermittelt Ihnen ein leicht verständliches Verständnis des autonomen Fahrens
- Ein Artikel zum Verständnis der Lidar- und visuellen Fusionswahrnehmung des autonomen Fahrens