
Heim >Technologie-Peripheriegeräte >KI >Microsoft schlägt eine patentierte Technologie zur Vorhersage der Haltung beweglicher Objekte für die AR/VR-Erfassung der Körperhaltung vor
Microsoft schlägt eine patentierte Technologie zur Vorhersage der Haltung beweglicher Objekte für die AR/VR-Erfassung der Körperhaltung vor

- 王林nach vorne
- 2023-09-18 19:37:01980Durchsuche
(Nweon, 18. September 2023) Um die reale Körperhaltung eines menschlichen Benutzers genau darzustellen, sind normalerweise relativ detaillierte Informationen über die Position und Ausrichtung der Körperteile des Benutzers erforderlich, diese Informationen sind jedoch nicht immer verfügbar. Wenn beispielsweise ein Headset zur Bereitstellung eines Virtual-Reality-Erlebnisses verwendet wird, kann das System möglicherweise nur räumliche Informationen erhalten, die sich auf den Kopf und die Hände des Benutzers beziehen. Allerdings reicht dies in den meisten Fällen nicht aus, um die reale Körperhaltung eines menschlichen Benutzers genau wiederzugeben
In der Patentanmeldung mit dem Titel „Posenvorhersage für artikulierte Objekte“ schlug Microsoft eine Technologie zur Vorhersage der Pose artikulierter Objekte vor. Insbesondere empfängt das maschinelle Lernmodell die räumlichen Informationen von n verschiedenen Gelenken des artikulierten Objekts, wobei n Gelenke kleiner sind als alle Gelenke des artikulierten Objekts.
Im Falle eines menschlichen Benutzers können die n Gelenke das Kopfgelenk des menschlichen Benutzers und/oder ein oder zwei Handgelenke umfassen, die mit räumlichen Informationen verknüpft sind, die die Parameter des Kopfes und/oder der Hände des Benutzers detailliert beschreiben
Das Modell für maschinelles Lernen wurde darauf trainiert, räumliche Eingabeinformationen für n+m Gelenke eines Gelenkobjekts zu empfangen, wobei m größer oder gleich 1 ist. Beispielsweise empfängt ein maschinelles Lernmodell während des anfänglichen Trainings Eingabedaten, die nahezu allen Gelenken eines artikulierten Objekts entsprechen. Die n+m Gelenke können jedes Gelenk des Gelenkobjekts umfassen.
In anderen Beispielen kann es n+m Gelenke geben, wobei weniger als alle Gelenke eines Gelenkobjekts vorhanden sind. Während des Trainingsprozesses können die in das maschinelle Lernmodell eingegebenen Daten nach und nach ausgeblendet werden. Sie können die entsprechenden Eingabedaten eines bestimmten Knotens in m Knoten durch einen vordefinierten Wert ersetzen oder ihn einfach weglassen
Mit anderen Worten: Ein maschinelles Lernmodell wird darauf trainiert, die Pose eines beweglichen Objekts genau vorherzusagen, basierend auf immer weniger Informationen über die Position/Ausrichtung der verschiedenen beweglichen Teile des beweglichen Objekts.
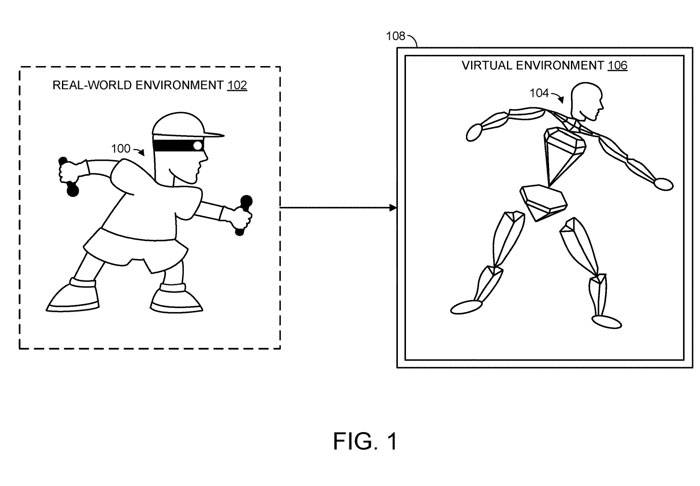
Mit diesem Ansatz sind Modelle für maschinelles Lernen in der Lage, die Pose artikulierter Objekte zur Laufzeit mit nur wenigen Eingabedaten genau vorherzusagen. Microsoft weist darauf hin, dass diese Technologie die reale Pose artikulierter Objekte für menschliche Benutzer genau reproduzieren kann, ohne dass viele Informationen über die Ausrichtung jedes Gelenks erforderlich sind
Mit anderen Worten: Erfindungen können technologische Vorteile bieten, die die Mensch-Computer-Interaktion verbessern, indem sie die realen Gesten menschlicher Benutzer genauer reproduzieren. Zu diesen technischen Vorteilen gehören die Verbesserung der Immersion von Virtual-Reality-Erlebnissen und die Verbesserung der Genauigkeit von Gestenerkennungssystemen
Darüber hinaus kann die beschriebene Technologie den Verbrauch von Rechenressourcen reduzieren und gleichzeitig die tatsächliche Haltung eines menschlichen Benutzers genau reproduzieren, indem sie die Datenmenge reduziert, die als Eingabe für den Haltungsvorhersageprozess gesammelt werden muss.
Beispielmethode 200 zeigt Abbildung 2 zur Vorhersage der Pose eines artikulierten Objekts
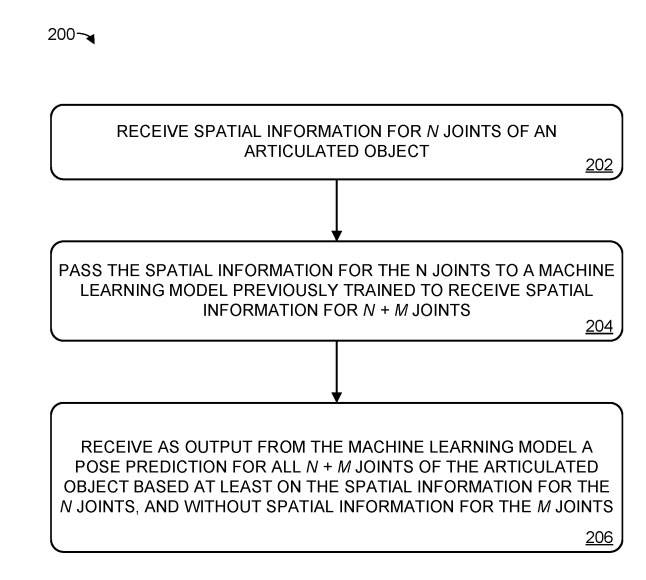
Bei Punkt 202 erhalten Sie die räumlichen Informationen von n Gelenken, die für artikulierte Objekte verwendet werden. Das System erhält die räumlichen Informationen von n Gelenken des Gelenkobjekts, das weniger Gelenke enthält als alle Gelenke des Gelenkobjekts. Stellt man die räumlichen Informationen eines Gelenks als Position und Ausrichtung von sechs Freiheitsgraden dar, die Körperteile verbinden, kann daraus auf den Zustand des Gelenks geschlossen werden
Beispielsweise können die n Gelenke die Kopfgelenke des menschlichen Körpers umfassen, und die räumlichen Informationen der Kopfgelenke können die Parameter des menschlichen Kopfes detailliert beschreiben. Darüber hinaus können die n Gelenke ein oder mehrere Handgelenke des menschlichen Körpers umfassen und die räumlichen Informationen des einen oder der mehreren Handgelenke können die Parameter einer oder mehrerer Hände des menschlichen Körpers detailliert beschreiben.
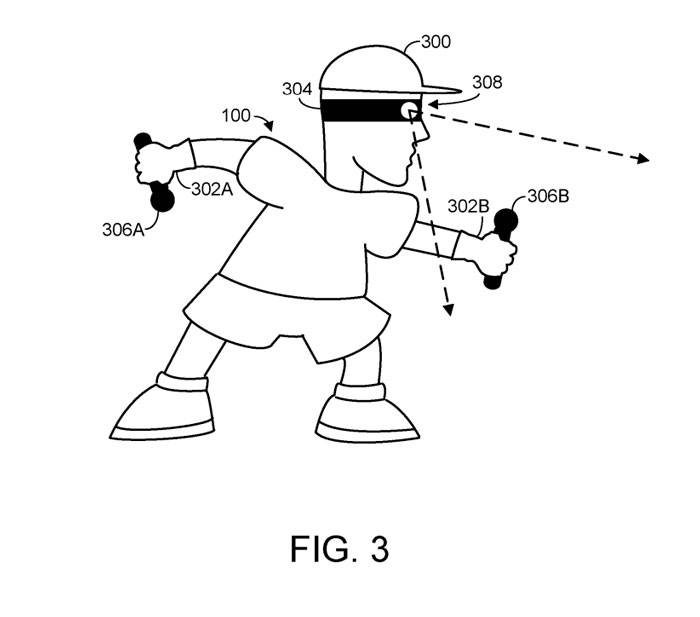
Abbildung 3 zeigt menschliche Benutzer. Der menschliche Benutzer hat einen Kopf 300 und zwei Hände 302A und 302B. Das Computersystem kann räumliche Informationen für ein oder mehrere Gelenke eines menschlichen Benutzers empfangen, zu denen Kopf- und/oder Handgelenke gehören können.
Die räumlichen Informationen von n Gelenken des Gelenkobjekts können aus den von einem oder mehreren Sensoren ausgegebenen Positionierungsdaten abgeleitet werden. Sensoren können in ein oder mehrere Geräte integriert sein, die von entsprechenden Körperteilen eines menschlichen Benutzers gehalten oder getragen werden.
Sensoren können beispielsweise eine oder mehrere Trägheitsmesseinheiten umfassen, die in ein am Kopf montiertes Anzeigegerät und/oder einen Handcontroller integriert sind. Als weiteres Beispiel kann ein Sensor eine oder mehrere Kameras umfassen.
Abbildung 3 zeigt schematisch die verschiedenen Arten von Sensoren, wobei die Ausgabe der Sensoren räumliche Informationen enthalten oder zur Ableitung verwendet werden kann. Insbesondere trägt ein menschlicher Benutzer ein am Kopf montiertes Anzeigegerät 304 auf seinem Kopf 300 .
Darüber hinaus hält der menschliche Benutzer Positionssensoren 306A und 306B, die so konfiguriert sein können, dass sie Bewegungen der Hände des Benutzers erkennen und an das Headset 304 und/oder ein anderes Computersystem melden, das für den Empfang räumlicher Informationen konfiguriert ist.
In Abbildung 2 sind wir wieder bei der 204-Situation. Wir übergeben die räumlichen Informationen von n Gelenken an das zuvor trainierte Modell für maschinelles Lernen. Dieses Modell erhält räumliche Informationen von n+m Gelenken als Eingabe, wobei der Wert von m größer oder gleich 1 ist. Mit anderen Worten: Im Vergleich zum vorherigen Trainingsmodell erhält dieses maschinelle Lernmodell weniger Gelenkrauminformationen
In 206 erhalten Sie als Ausgabe eine Posenvorhersage des artikulierten Objekts aus dem Modell für maschinelles Lernen, wobei die Vorhersage mindestens auf den räumlichen Informationen der n Gelenke basiert und nicht die räumlichen Informationen ihrer Gelenke enthält. Mit anderen Worten: Selbst wenn die räumlichen Informationen von m Gelenken nicht bereitgestellt werden, kann das Modell für maschinelles Lernen die vollständige Haltung des Gelenkobjekts vorhersagen.
Abbildung 4 zeigt ein Beispielmodell 400 für maschinelles Lernen, um diesen Prozess zu veranschaulichen
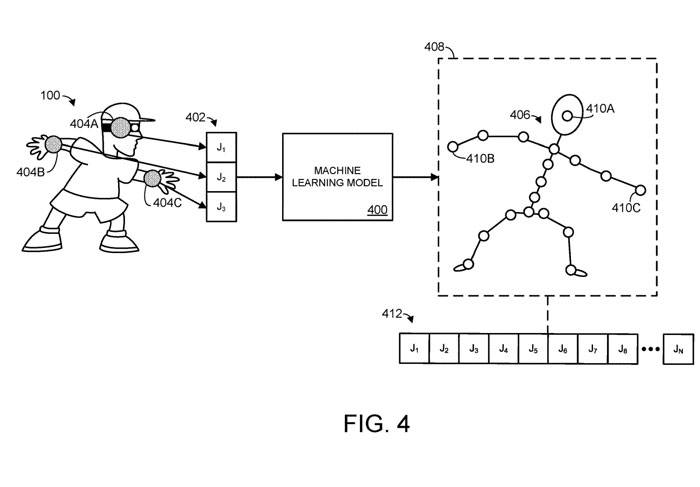
In Abbildung 4 empfängt das Modell für maschinelles Lernen räumliche Informationen 402, die drei verschiedenen Gelenken J1, J2 und J3 entsprechen. Rauminformationen für ein Gelenk können in Form beliebiger geeigneter Computerdaten vorliegen, die die Position und/oder Ausrichtung des mit dem Gelenk verbundenen Körperteils angeben oder daraus abgeleitet werden können.
Räumliche Informationen können beispielsweise direkt die Position und Ausrichtung eines Körperteils angeben und/oder räumliche Informationen können eine oder mehrere Drehungen eines Gelenks relativ zu einer oder mehreren Drehachsen angeben. In Abbildung 4 entsprechen die Gelenke J1, J2, J3 dem Kopfgelenk 404A und zwei Handgelenken 404B/404C eines menschlichen Benutzers, wie durch die schattierten Kreise dargestellt, die über dem Körper des Benutzers liegen.
In diesem Beispiel umfassen die n Gelenke drei Gelenke, die den Kopf- und Handgelenken des menschlichen Körpers entsprechen. Basierend auf den eingegebenen räumlichen Informationen 402 gibt das maschinelle Lernmodell eine vorhergesagte Pose 406 des artikulierten Objekts aus.
Darüber hinaus kann das maschinelle Lernmodell vorhergesagte räumliche Informationen ausgeben, die den durch das virtuelle Gelenk dargestellten Gelenken entsprechen. Menschliche Benutzer können durch Avatare mit cartoonartigen oder nichtmenschlichen Proportionen dargestellt werden. Beispielsweise können die vorhergesagten räumlichen Informationen den durch SMPL dargestellten Gelenken entsprechen.
Mit anderen Worten: Die Gelenke der virtuellen Darstellung der artikulierten Darstellung müssen nicht 1:1 mit den Gelenken des artikulierten Objekts übereinstimmen. Daher kann die vom maschinellen Lernmodell vorhergesagte räumliche Informationsausgabe für Gelenke gelten, die nicht direkt den n+m Gelenken des Gelenkobjekts entsprechen. Beispielsweise kann eine virtuelle Darstellung weniger Wirbelsäulengelenke aufweisen als ein artikuliertes Objekt.
Machine-Learning-Modelle können auf jede geeignete Weise trainiert werden. In einer Ausführungsform kann das maschinelle Lernmodell zuvor unter Verwendung von Trainingseingabedaten mit Ground-Truth-Labels für artikulierte Objekte trainiert worden sein.
Mit anderen Worten, das Modell für maschinelles Lernen kann mit räumlichen Trainingsinformationen der Gelenke des artikulierten Objekts versorgt und als Grundwahrheitsetiketten gekennzeichnet werden, die die tatsächliche Pose des artikulierten Objekts angeben, die den räumlichen Informationen entspricht.
Wie oben erwähnt, kann ein Modell für maschinelles Lernen darauf trainiert werden, räumliche Informationen von n+m Gelenken als Eingabe zu empfangen. Dazu gehört, dass in der ersten Trainingsiteration das maschinelle Lernmodell mit Trainingseingabedaten für alle n+m Gelenke versorgt wird. In einer nachfolgenden Reihe von Trainingsiterationen können die Trainingseingabedaten von m Gelenken schrittweise maskiert werden.
Zum Beispiel kann in der zweiten Trainingsiteration das erste der m Gelenke maskiert werden, wobei die räumlichen Informationen des Gelenks im Trainingsdatensatz durch einen vordefinierten Wert ersetzt werden, der das maskierte Gelenk darstellt, oder einfach weggelassen werden.
Als Beispiel. In der dritten Trainingsiteration kann das zweite der m Gelenke maskiert werden und so weiter, bis alle m Gelenke maskiert sind und nur die räumlichen Informationen von n Gelenken dem Modell für maschinelles Lernen bereitgestellt werden.
Dieser Vorgang ist in den Abbildungen 5a-5d dargestellt. Konkret wird in Abbildung 5A dem Modell 400 für maschinelles Lernen ein Trainingseingabedatensatz bereitgestellt. In dieser Ausführungsform umfassen die Trainingseingabedaten räumliche Informationen, die mehreren unterschiedlichen Haltungen des Gelenkobjekts entsprechen, einschließlich der ersten Haltung 502A und der zweiten Haltung 502B.
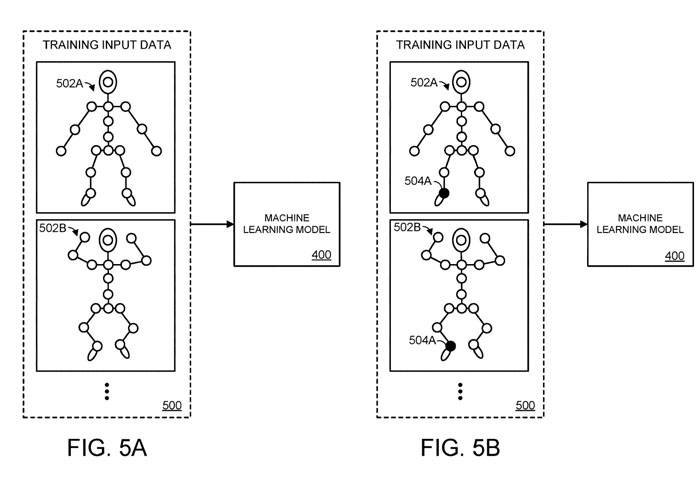
In Abbildung 5A stellen wir die räumlichen Informationen von n+m Gelenken für das Gelenkobjekt des maschinellen Lernmodells bereit. In dieser vereinfachten Darstellung des menschlichen Körpers wird jeder Kreis, der ein Gelenk darstellt, durch ein weißes Füllmuster dargestellt. In Abbildung 5B haben wir jedoch 504A wie gezeigt mit einem schwarzen Füllmuster abgeschirmt, um den Kreis für Steckverbinder 504A darzustellen
Mit anderen Worten: Abbildung 5A stellt die erste Iteration des Trainingsprozesses dar, bei der dem maschinellen Lernmodell räumliche Informationen für alle n+m Gelenke bereitgestellt werden. Abbildung 5B zeigt die zweite Iteration des Trainingsprozesses, bei der das erste Gelenk 504A unter den m Gelenken maskiert wird
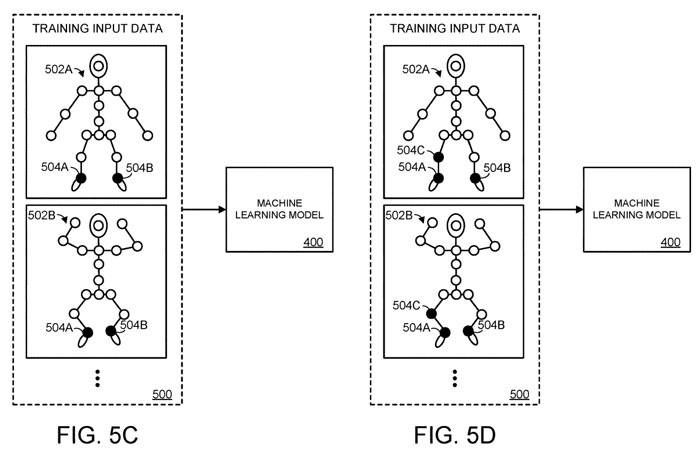
In Abbildung 5C ist das zweite Gelenk 504B unter den m Gelenken, die durch das Scharnier dargestellt werden, verschlossen. In ähnlicher Weise ist in Abbildung 5D das dritte der m Gelenke verschlossen. Mehrere Trainingsiterationen können fortgesetzt werden, bis die räumlichen Informationen jedes der m Gelenke maskiert sind und nur die räumlichen Informationen von n Gelenken dem Modell für maschinelles Lernen bereitgestellt werden.
Im obigen Szenario beschreiben wir die Situation, in der das artikulierte Objekt der gesamte Körper des menschlichen Körpers ist. Gelenkobjekte können jedoch auch andere Formen annehmen
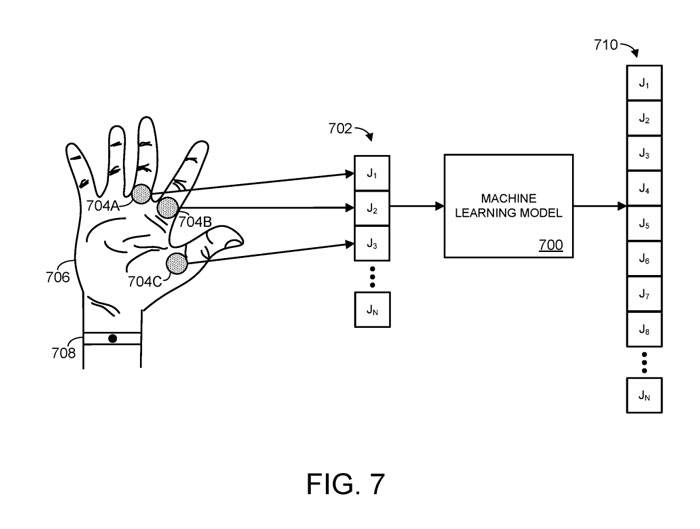
Wie in Abbildung 7 dargestellt, ist das bewegliche Objekt die menschliche Hand, nicht der gesamte menschliche Körper. Konkret zeigt Abbildung 7 ein Beispielmodell 700 für maschinelles Lernen.
Das maschinelle Lernmodell 700 empfängt räumliche Informationen für die Gelenke J1, J2 und J3, die den drei Gelenken 704A-C eines artikulierten Objekts entsprechen, in diesem Fall in Form einer menschlichen Hand 706.
In diesem Fall umfassen die n Gelenke insbesondere ein oder mehrere Fingergelenke der menschlichen Hand. Die räumlichen Informationen eines oder mehrerer Fingergelenke geben Aufschluss über die Parameter eines oder mehrerer Finger oder Fingersegmente der menschlichen Hand. Beispielsweise können räumliche Informationen die Position/Ausrichtung der Finger der Hand und/oder die auf die Gelenke der Hand ausgeübte Drehung angeben
Jede geeignete Methode kann verwendet werden, um Gelenkrauminformationen zu sammeln, beispielsweise über den Positionssensor 708. Beispielsweise könnte ein Positionssensor die Form einer Kamera annehmen, die so konfiguriert ist, dass sie die Hand abbildet. Als weiteres Beispiel könnte ein Positionssensor eine geeignete Hochfrequenzantenne umfassen, die so konfiguriert ist, dass sie die Handoberfläche einem elektromagnetischen Feld aussetzt und die Auswirkung von Bewegung und Nähe leitfähiger menschlicher Haut auf die elektromagnetische Feldimpedanz an der Antenne
bewertetBasierend auf den eingegebenen räumlichen Informationen 702 gibt das Modell für maschinelles Lernen einen Satz vorhergesagter räumlicher Informationen 710 aus. Rauminformationen 710 können verwendet werden, um die vorhergesagte Pose des artikulierten Objekts zu konstruieren. Wie bereits erwähnt, können diese räumlichen Informationen die Position und Ausrichtung von Körperteilen eines artikulierten Objekts darstellen
Verwandte Patente: Microsoft-Patent |. Posenvorhersage für artikulierte Objekte
Microsoft hat ursprünglich im Juni 2022 einen Patentantrag mit dem Titel „Pose Prediction for Articulated Object“ eingereicht, und der Antrag wurde kürzlich vom US-Patent- und Markenamt veröffentlicht
Das obige ist der detaillierte Inhalt vonMicrosoft schlägt eine patentierte Technologie zur Vorhersage der Haltung beweglicher Objekte für die AR/VR-Erfassung der Körperhaltung vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Können AR/VR-Headsets den Marktwert von Apple retten? Die vollständigste Offenbarung ist hier
- 4K+5000nit Helligkeit? Apple Reality Pro-Headset AR/VR freigelegt
- Es wird berichtet, dass das Apple AR/VR-Headset 6 Farben und 2 Spezifikationen bieten wird
- Morgan Stanley-Analyst: Apple hat 300.000–500.000 AR/VR-Headsets auf Lager
- Entdecken Sie Hunderte von AR/VR-Patenten und erkunden Sie alle Aspekte von Apple XR