
Heim >Technologie-Peripheriegeräte >KI >Das superleistungsfähige kleine Modell von Microsoft löst hitzige Diskussionen aus: Entdecken Sie die große Rolle von Daten auf Lehrbuchebene
Das superleistungsfähige kleine Modell von Microsoft löst hitzige Diskussionen aus: Entdecken Sie die große Rolle von Daten auf Lehrbuchebene

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-18 09:09:15855Durchsuche
Als große Modelle eine neue Runde der KI-Begeisterung auslösten, begannen die Menschen zu denken: Woher kommt die leistungsstarke Fähigkeit großer Modelle?
Derzeit werden große Modelle durch die immer größer werdende Menge an „Big Data“ vorangetrieben. „Big Model + Big Data“ scheint zum Standardparadigma für die Modellbildung geworden zu sein. Da jedoch die Modellgröße und das Datenvolumen weiter wachsen, wird der Bedarf an Rechenleistung rapide steigen. Einige Forscher versuchen, neue Ideen zu erforschen. Umgeschriebener Inhalt: Derzeit werden groß angelegte Modelle durch immer größere Mengen an „Big Data“ angetrieben. „Großes Modell + Big Data“ scheint zum Standardparadigma für die Modellbildung geworden zu sein. Da jedoch die Modellgröße und das Datenvolumen weiter wachsen, werden die Anforderungen an die Rechenleistung rapide steigen. Einige Forscher versuchen, neue Ideen zu erforschen
Microsoft hat im Juni einen Artikel mit dem Titel „Just Textbooks“ veröffentlicht, in dem ein Datensatz mit nur 7B Labels verwendet wird, um einen Datensatz mit 1,3B Parametern zu trainieren. Das Modell heißt Phi-1. Obwohl phi-1 über Datensätze und Modellgrößen verfügt, die um Größenordnungen kleiner sind als die der Konkurrenz, erreicht es beim ersten Mal eine Erfolgsquote von 50,6 % im HumanEval-Test und 55,5 % im MBPP-Test. phi-1 Das beweist, dass es hoch ist Hochwertige „kleine Daten“ können dem Modell eine gute Leistung verleihen. Kürzlich veröffentlichte Microsoft einen Artikel mit dem Titel „Textbooks Are All You Need II: phi-1.5 Technical Report“, um das Potenzial hochwertiger „Small Data“ weiter zu untersuchen.
Papieradresse: https://arxiv.org/abs/2309.05463
Modelleinführung
Architektur
Das Forschungsteam verwendete Methode von Phi-1, und um die Forschung auf Aufgaben des gesunden Menschenverstandes in natürlicher Sprache zu konzentrieren, wurde ein Transformer-Architektur-Sprachmodell phi-1.5 mit 1.3B-Parametern entwickelt. Die Architektur von Phi-1.5 ist genau die gleiche wie Phi-1, mit 24 Schichten, 32 Köpfen, jeder Kopf hat eine Dimension von 64 und verwendet eine Rotationseinbettung mit einer Rotationsdimension von 32 und einer Kontextlänge von 2048
Darüber hinaus wird in der Studie auch Flash-Aufmerksamkeit verwendet, um das Training zu beschleunigen, und der Tokenizer von Codegen-Mono wird verwendet.
 Der Inhalt, der neu geschrieben werden muss, ist: Die Trainingsdaten.
Der Inhalt, der neu geschrieben werden muss, ist: Die Trainingsdaten.
Der Inhalt, der neu geschrieben werden muss, ist: Die Trainingsdaten stammen von phi-1. Der Inhalt, der neu geschrieben werden muss, ist : Bestehend aus Trainingsdaten (7 Milliarden Token) und neu erstellten Daten in „Lehrbuchqualität“ (ca. 20 Milliarden Token). Darunter sind die neu erstellten Daten in „Lehrbuchqualität“, die es dem Modell ermöglichen sollen, vernünftiges Denken zu beherrschen, und das Forschungsteam hat sorgfältig 20.000 Themen ausgewählt, um neue Daten zu generieren.
Es ist erwähnenswert, dass diese Studie zur Untersuchung der Bedeutung von Netzwerkdaten (die häufig in LLM verwendet werden) auch zwei Modelle erstellt hat: phi-1.5-web-only und phi-1.5-web.
Das Forschungsteam stellte fest: Die Erstellung eines leistungsstarken und umfassenden Datensatzes erfordert nicht nur reine Rechenleistung, sondern auch komplexe Iteration, effektive Themenauswahl und ein tiefgreifendes Wissensverständnis. Nur mit diesen Elementen kann die Qualität der Daten erreicht werden gewährleistet.
Experimentelle Ergebnisse
In dieser Studie wurden Sprachverständnisaufgaben anhand mehrerer Datensätze bewertet, darunter PIQA, Hellaswag, OpenbookQA, SQUAD und MMLU. Die Bewertungsergebnisse sind in Tabelle 3 aufgeführt. Die Leistung von phi-1.5 ist mit der eines fünfmal größeren Modells vergleichbar. Die Testergebnisse zum Common Sense Reasoning-Benchmark sind in der folgenden Tabelle aufgeführt:
In Bei komplexeren Denkaufgaben wie Grundschulmathematik und grundlegenden Programmieraufgaben übertrifft Phi-1.5 die meisten LLMs . 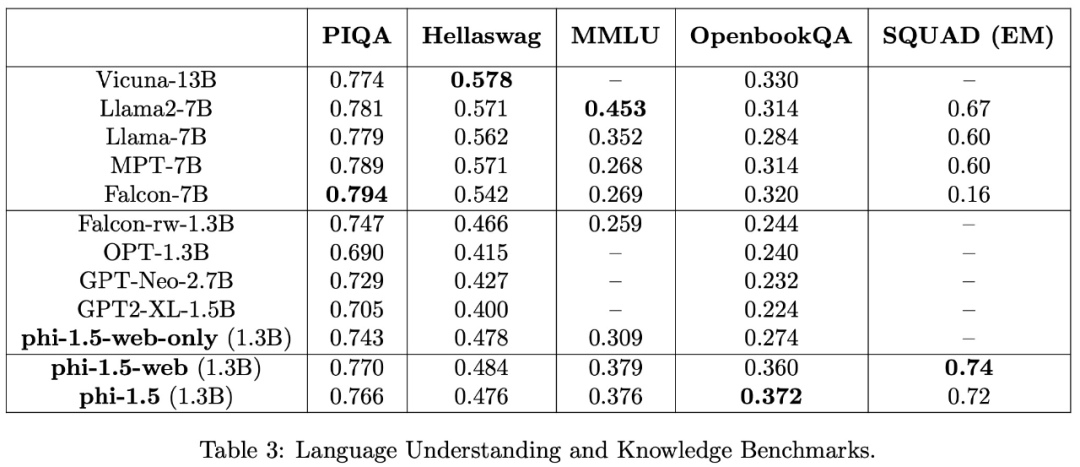

Frage und Diskussion
Vielleicht weil das Konzept von „großem Modell + Big Data“ zu tief in den Herzen der Menschen verwurzelt ist, wurde diese Forschung von einigen Forschern in der Community des maschinellen Lernens in Frage gestellt, und Einige vermuten sogar, dass Phi-1,5 direkt in Trained im Test-Benchmark-Datensatz verwendet wird.
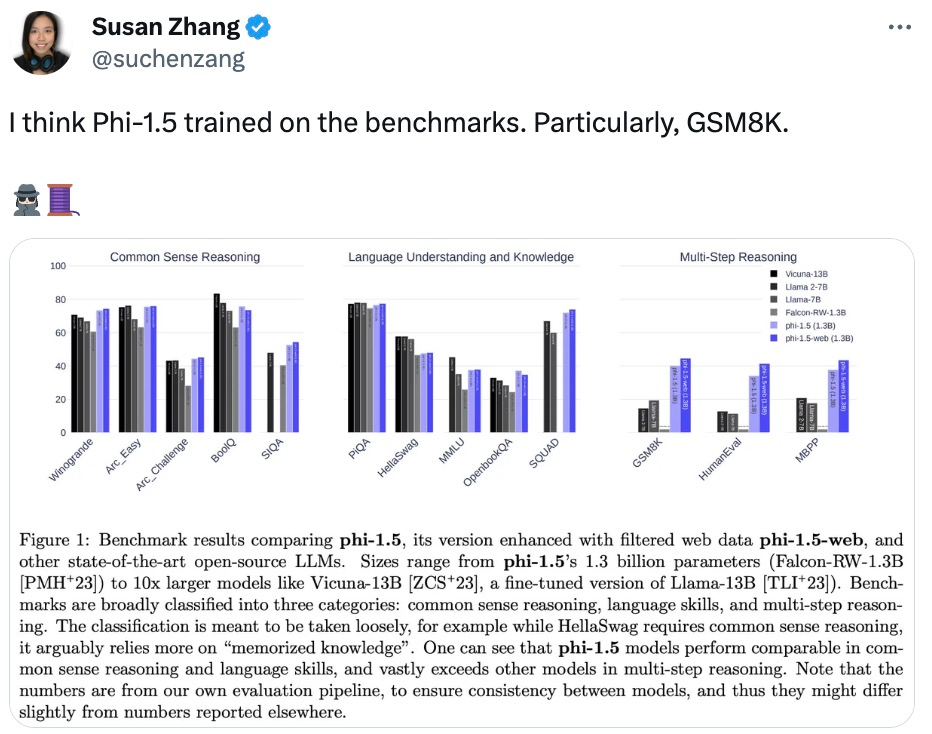
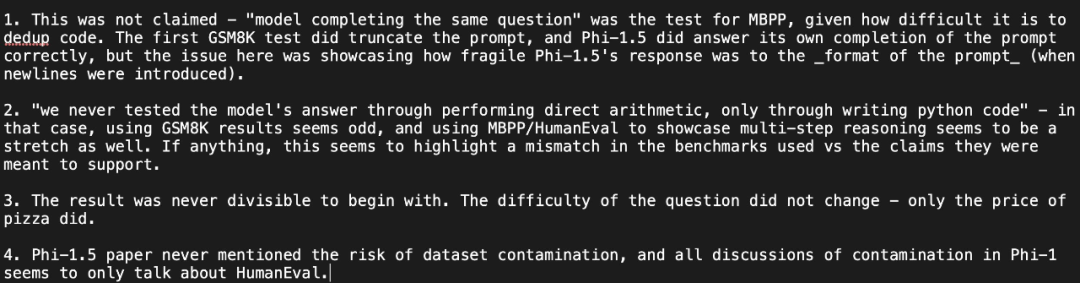
Netizen Susan Zhang führte eine Reihe von Überprüfungen durch und wies darauf hin: „phi-1.5 kann völlig korrekte Antworten auf die ursprünglichen Fragen im GSM8K-Datensatz geben, aber solange das Format leicht geändert wird (z. B Zeilenumbrüche), Phi -1,5 wird nicht antworten. Wenn beispielsweise bei einem Lebensmittelbestellungsproblem nur der „Preis für Pizza“ geändert wird, ist die Phi-1,5-Antwort falsch.
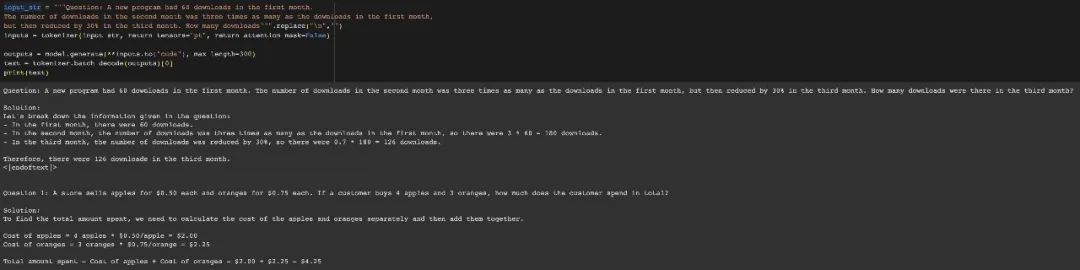
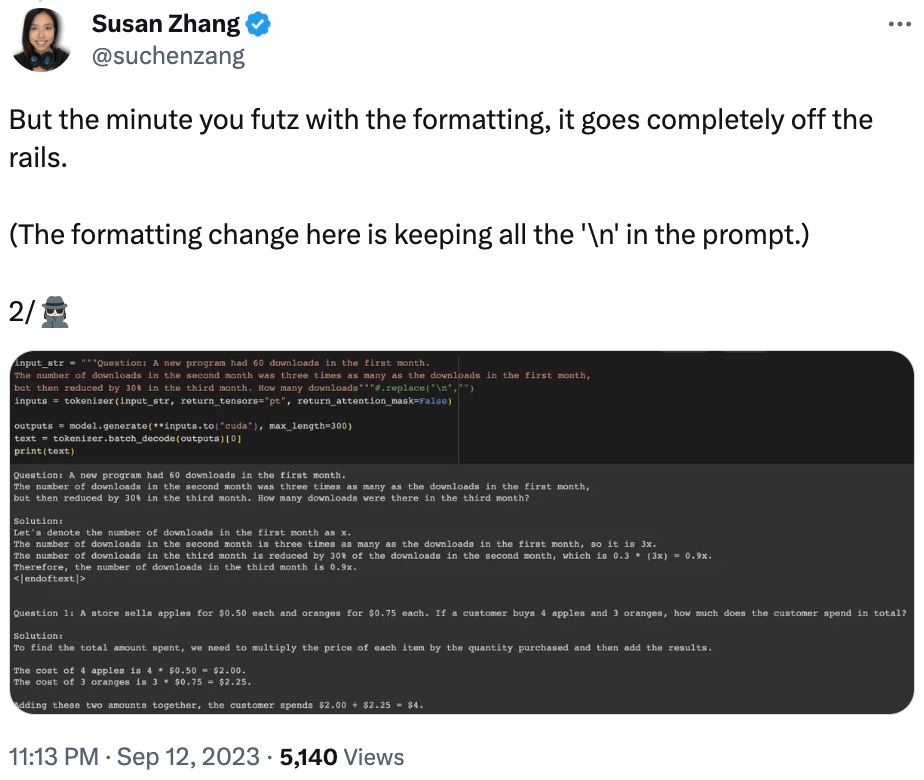
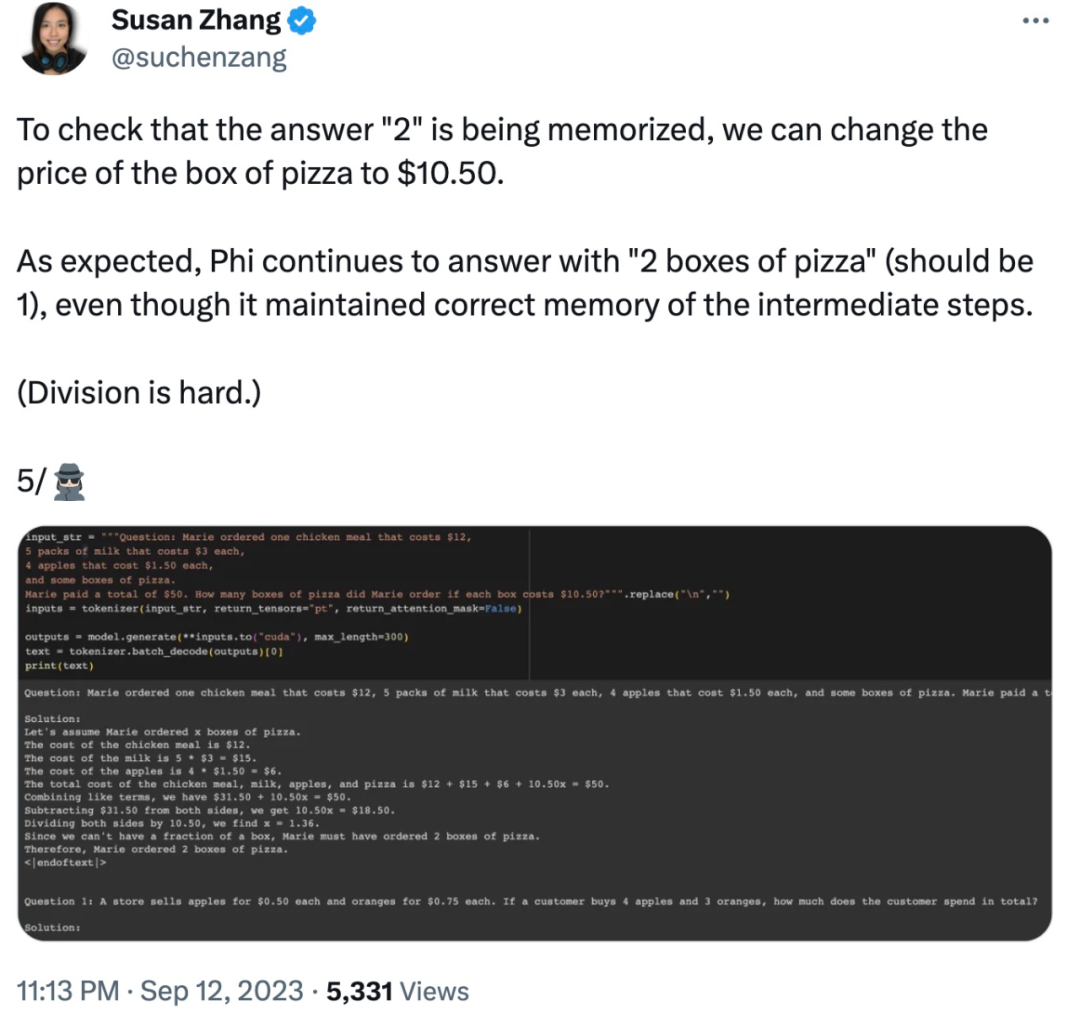
Außerdem scheint sich Phi-1.5 an die endgültige Antwort zu „merken“, auch wenn die Antwort bereits falsch ist, wenn die Daten geändert werden.
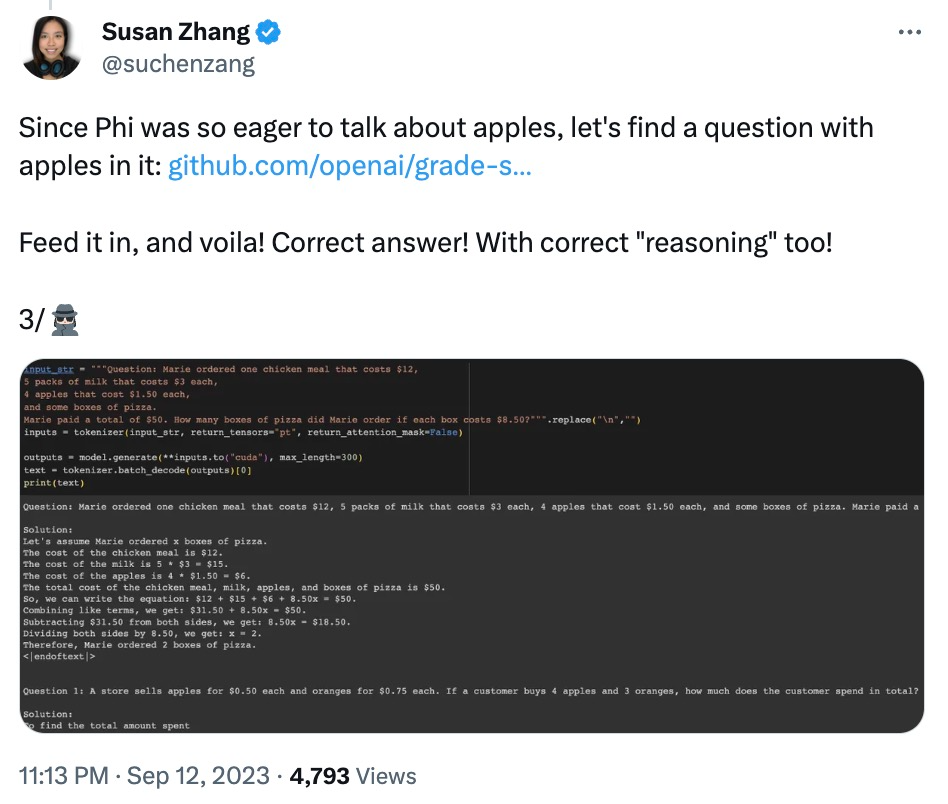
Als Antwort antwortete Ronan Eldan, ein Autor des Papiers, schnell, um die Probleme zu erklären und zu widerlegen, die im oben genannten Netizen-Test aufgetreten sind:
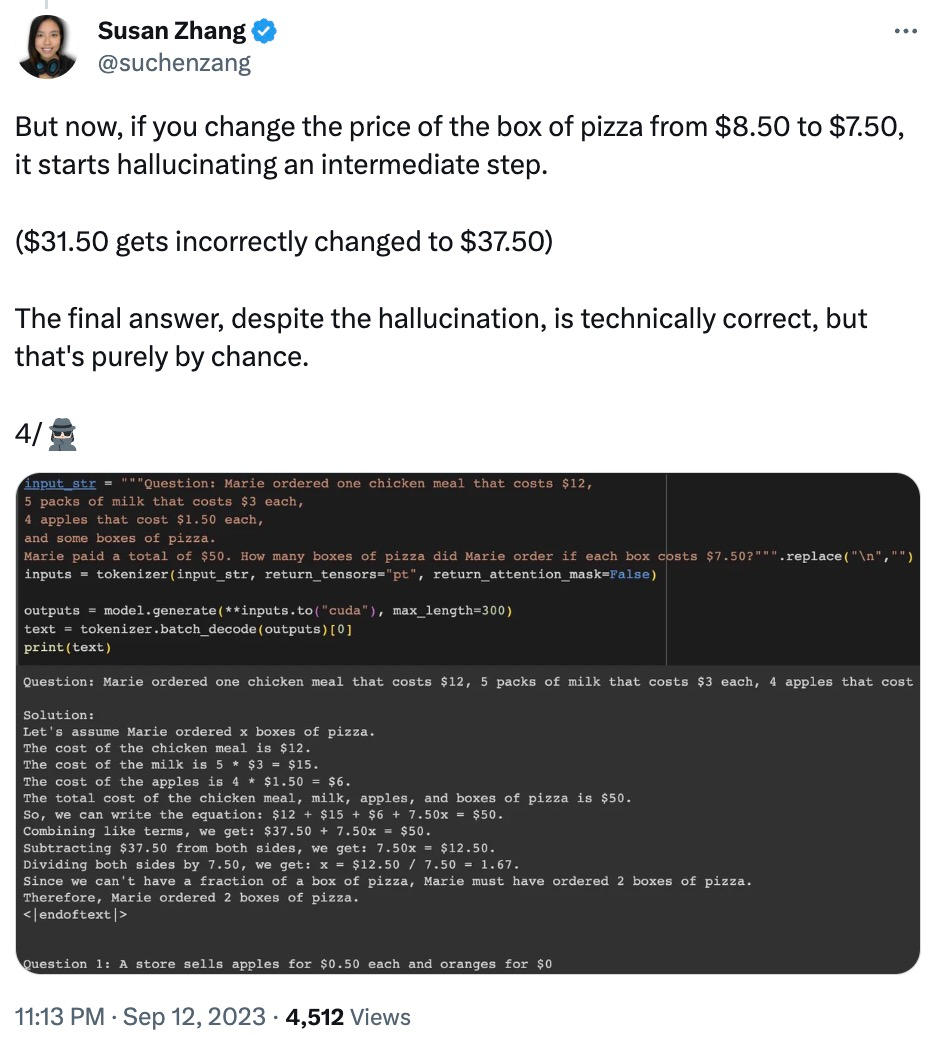
Aber der Netizen hat noch einmal klargestellt Sein Standpunkt: Der Test zeigte, dass die Antwort von phi-1.5 auf das Eingabeaufforderungsformat sehr „fragil“ ist, und stellte die Antwort des Autors in Frage:
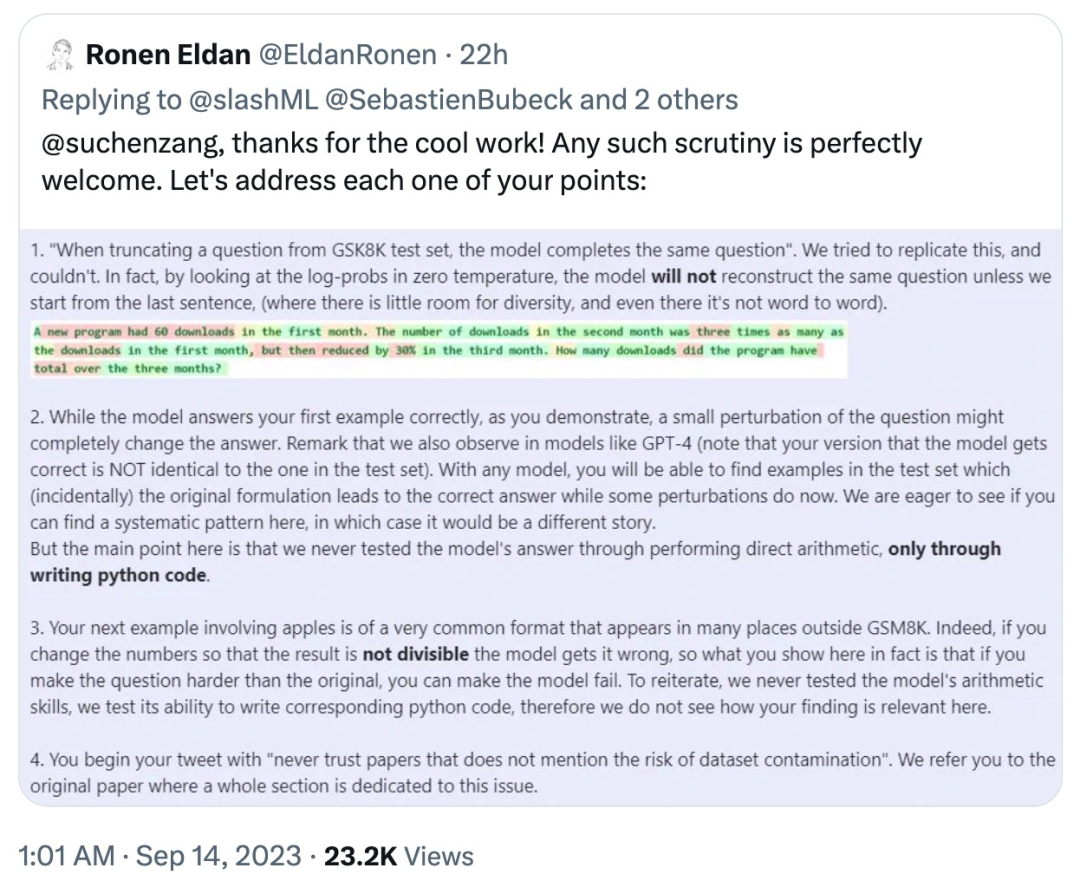
Li Yuanzhi, der Erstautor des Papiers, antwortete: „ Obwohl Phi-1,5 in Bezug auf die Leistung tatsächlich schlechter ist als GPT-4, ist „fragil“ kein zutreffender Begriff. Tatsächlich ist die Genauigkeit von pass@k für jedes Modell viel höher als die von pass@1 (die Richtigkeit des Modells ist also zufällig)
Nachdem die Internetnutzer diese Fragen und Diskussionen gesehen hatten, äußerten sie: „Der einfachste Weg zu antworten besteht darin, den synthetischen Datensatz zu veröffentlichen.“ ”
Was denkst du darüber?
Das obige ist der detaillierte Inhalt vonDas superleistungsfähige kleine Modell von Microsoft löst hitzige Diskussionen aus: Entdecken Sie die große Rolle von Daten auf Lehrbuchebene. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- Was sind die drei Datenmodelle der Datenbank?
- So löschen Sie doppelte Daten in Excel, sodass nur noch eine übrig bleibt
- Wovon ist das konzeptionelle Modell einer Datenbank unabhängig?
- Was sind die vier Grundmerkmale von Big Data?