
Heim >Technologie-Peripheriegeräte >KI >Es wurde ein großes Modellentwicklungs-Toolset erstellt!
Es wurde ein großes Modellentwicklungs-Toolset erstellt!

- 王林nach vorne
- 2023-09-17 14:21:081242Durchsuche
Der Inhalt, der neu geschrieben werden muss, ist: Autor Richard MacManus Technologie-Stack.
Schnelle Ingenieure können möglicherweise nicht die Nerven von Entwicklern berühren, die zu großen Modellen eilen, aber ein Satz eines Produktmanagers oder einer Führungskraft: Kann ein „Agent“ entwickelt werden, kann eine „Kette“ implementiert werden und „Welcher Vektor?“ Datenbank zu verwenden?“ sind derzeit zu großen Mainstream-Unternehmen für große Modellanwendungen geworden, die Technologiestudenten dazu gebracht haben, die Schwierigkeiten bei der Generierung von KI-Entwicklung zu überwinden.
Was sind die Schichten des neuen Technologie-Stacks? Wo ist der schwierigste Teil? Dieser Artikel wird Sie dazu bringen, es herauszufinden
1. Der Technologie-Stack muss aktualisiert werden. Entwickler läuten die Ära der KI-Ingenieure ein
Im vergangenen Jahr sind einige Tools entstanden, die dies ermöglicht haben Entwickler von KI-Anwendungen Das Ökosystem beginnt zu reifen. Für diejenigen, die sich auf die Entwicklung künstlicher Intelligenz konzentrieren, gibt es inzwischen sogar einen Begriff, nämlich „KI-Ingenieur“. Laut Shawn @swyx Wang ist dies der nächste Schritt für „prompte Ingenieure“. Er hat außerdem ein Koordinatendiagramm erstellt, das die Position von KI-Ingenieuren im breiteren Ökosystem der künstlichen Intelligenz visuell veranschaulicht. Quelle: swyx
Große Sprachmodelle (LLM) sind die Kerntechnologie von KI-Ingenieuren. Es ist kein Zufall, dass sowohl LangChain als auch LlamaIndex Tools sind, die LLM erweitern und ergänzen. Aber welche anderen Tools stehen dieser neuen Generation von Entwicklern zur Verfügung? Das bisher beste Diagramm, das ich zum LLM-Stack gesehen habe, stammt von der Risikokapitalgesellschaft Andreessen Horowitz (a16z). Das Folgende ist seine Sicht auf den „LLM-App-Stack“: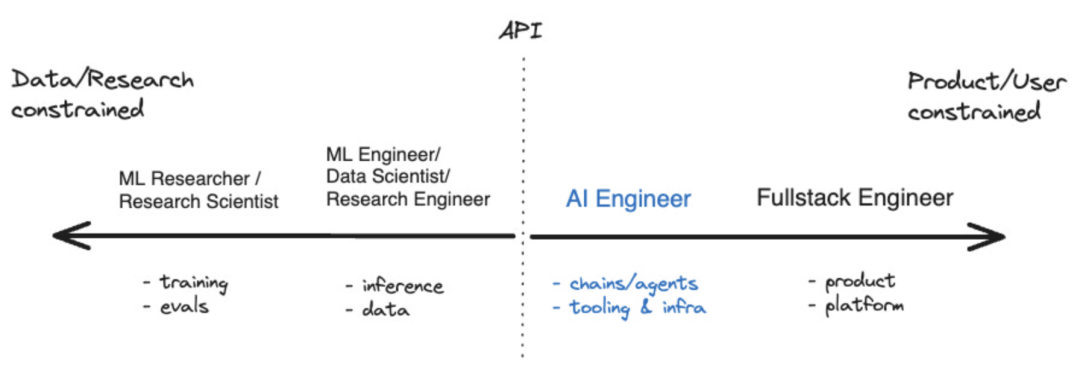 Bildquelle: a16z
Bildquelle: a16z
2 Ja, die oberste Ebene sind Daten
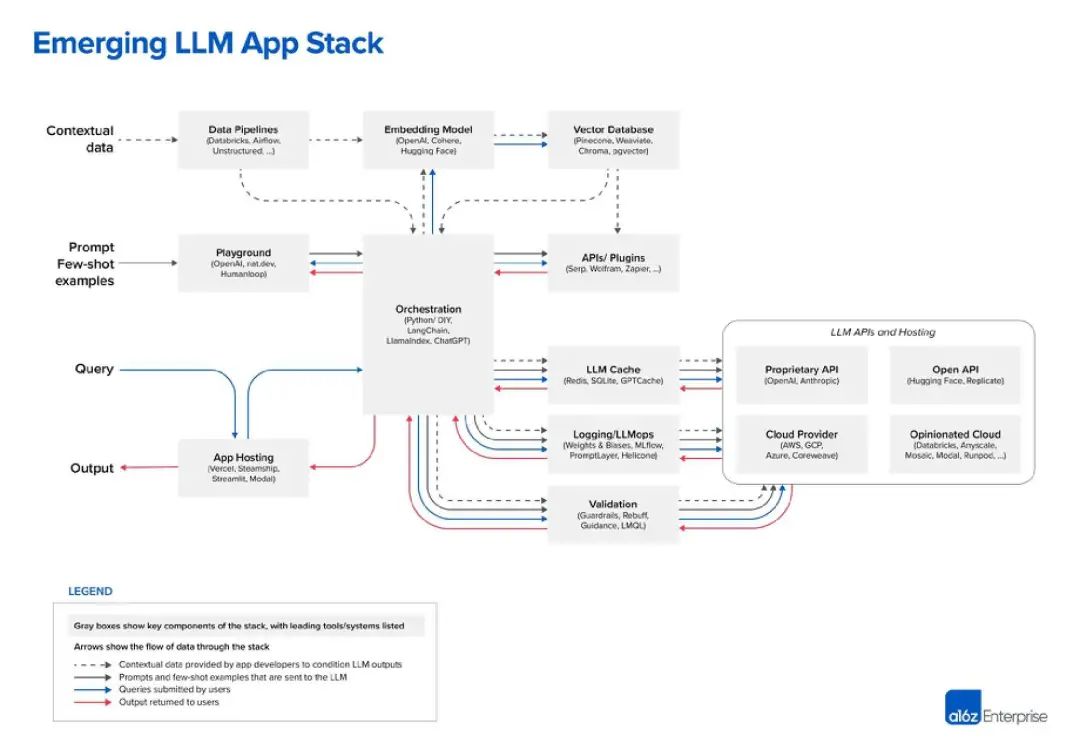 Im LLM-Technologie-Stack sind Daten die wichtigste Komponente. das ist sehr offensichtlich. Laut der Grafik von a16z liegen die Daten oben. In LLM ist das „eingebettete Modell“ ein sehr kritischer Bereich. Sie können zwischen OpenAI, Cohere, Hugging Face oder Dutzenden anderen LLM-Optionen wählen, einschließlich des immer beliebter werdenden Open-Source-LLM Vor der Verwendung von LLM ist außerdem eine „Datenpipeline“ erforderlich gegründet werden. Betrachten Sie beispielsweise Databricks und Airflow als zwei Beispiele, oder die Daten können „unstrukturiert“ verarbeitet werden. Dies gilt auch für die Periodizität von Daten und kann Unternehmen dabei helfen, die Daten zu „bereinigen“ oder einfach zu organisieren, bevor sie in ein benutzerdefiniertes LLM eingegeben werden. „Data Intelligence“-Unternehmen wie Alation bieten diese Art von Diensten an, was ein wenig nach Tools wie „Business Intelligence“ klingt, die im IT-Technologie-Stack besser bekannt sind
Im LLM-Technologie-Stack sind Daten die wichtigste Komponente. das ist sehr offensichtlich. Laut der Grafik von a16z liegen die Daten oben. In LLM ist das „eingebettete Modell“ ein sehr kritischer Bereich. Sie können zwischen OpenAI, Cohere, Hugging Face oder Dutzenden anderen LLM-Optionen wählen, einschließlich des immer beliebter werdenden Open-Source-LLM Vor der Verwendung von LLM ist außerdem eine „Datenpipeline“ erforderlich gegründet werden. Betrachten Sie beispielsweise Databricks und Airflow als zwei Beispiele, oder die Daten können „unstrukturiert“ verarbeitet werden. Dies gilt auch für die Periodizität von Daten und kann Unternehmen dabei helfen, die Daten zu „bereinigen“ oder einfach zu organisieren, bevor sie in ein benutzerdefiniertes LLM eingegeben werden. „Data Intelligence“-Unternehmen wie Alation bieten diese Art von Diensten an, was ein wenig nach Tools wie „Business Intelligence“ klingt, die im IT-Technologie-Stack besser bekannt sind
Der letzte Teil der Datenschicht ist die Vektordatenbank, die entstanden ist in letzter Zeit sehr beliebt, zum Speichern und Verarbeiten von LLM-Daten. Nach der Definition von Microsoft handelt es sich hierbei um eine Datenbank, die Daten als hochdimensionale Vektoren speichert, bei denen es sich um mathematische Darstellungen von Merkmalen oder Attributen handelt. Daten werden mithilfe der Einbettungstechnologie als Vektoren gespeichert. In einem Medienchat wies der führende Vektordatenbankanbieter Pinecone darauf hin, dass seine Tools häufig mit Datenpipeline-Tools wie Databricks verwendet werden. In diesem Fall werden die Daten typischerweise an anderer Stelle gespeichert (z. B. in einem Data Lake) und dann über ein maschinelles Lernmodell in eingebettete Daten umgewandelt. Nach der Verarbeitung und Aufteilung werden die resultierenden Vektoren an Pinecone gesendet
3. Hinweise und Abfragen
Die nächsten beiden Ebenen können als Hinweise und Abfragen zusammengefasst werden – Dies ist die KI-Anwendung mit LLM und (optional) Interaktionspunkt für andere Datentool-Schnittstellen. A16z positioniert LangChain und LlamaIndex als „Orchestrierungs-Frameworks“, was bedeutet, dass Entwickler diese Tools nutzen können, sobald sie verstehen, welches LLM sie verwenden des „Linkings“, also der Abfrage und Verwaltung von Daten zwischen der Anwendung und dem LLM. Dieser Orchestrierungsprozess umfasst die Interaktion mit externen API-Schnittstellen, das Abrufen von Kontextdaten aus der Vektordatenbank und die Verwaltung des Speichers über mehrere LLM-Aufrufe hinweg. Das interessanteste Kästchen im Diagramm von a16z ist „Playground“, das OpenAI, nat.dev und Humanloop umfasst
A16z ist im Blogbeitrag nicht genau definiert, aber wir können daraus schließen, dass „Playground“-Tools Entwicklern dabei helfen können, A16z so genannt „ Stichwort Jiu-Jitsu". An diesen Stellen können Entwickler mit verschiedenen Aufforderungstechniken experimentieren.
Humanloop ist ein britisches Unternehmen und ein Feature seiner Plattform ist der „Collaborative Prompt Workspace“. Darüber hinaus beschreibt es sich selbst als „vollständiges Entwicklungs-Toolkit für Produktions-LLM-Funktionalität“. Im Grunde ermöglicht es Ihnen also, LLM-Sachen auszuprobieren und sie dann in Ihrer Anwendung bereitzustellen, wenn es funktioniert
4. Fließbandbetrieb: LLMOps
Derzeit wird der Aufbau großer Produktionslinien allmählich klarer. Auf der rechten Seite der Orchestrierungsbox befinden sich viele Operationsboxen, einschließlich LLM-Caching und -Überprüfung. Darüber hinaus gibt es eine Reihe von LLM-bezogenen Cloud-Diensten und API-Diensten, darunter offene API-Repositories wie Hugging Face und proprietäre API-Anbieter wie OpenAI
Dies ist möglicherweise die Entwicklung, die wir vom „Cloud Native“ gewohnt sind. Die ähnlichste Sache im People-Technology-Stack ist, dass viele DevOps-Unternehmen künstliche Intelligenz zu ihrer Produktliste hinzugefügt haben, was kein Zufall ist. Im Mai sprach ich mit Jyoti Bansal, CEO von Harness. Harness betreibt eine „Software-Delivery-Plattform“, die sich auf den „CD“-Teil des CI/CD-Prozesses konzentriert.
Bansai sagte mir, dass KI die mühsamen und sich wiederholenden Aufgaben im Softwarebereitstellungslebenszyklus erleichtern kann, von der Generierung von Spezifikationen auf der Grundlage vorhandener Funktionalität bis hin zum Schreiben von Code. Darüber hinaus könne KI Codeüberprüfungen, Schwachstellentests und Fehlerbehebungen automatisieren und sogar CI/CD-Pipelines für Builds und Bereitstellungen erstellen, sagte er. Laut einem anderen Gespräch, das ich im Mai geführt habe, verändert KI auch die Entwicklerproduktivität. Trisha Gee vom Build-Automatisierungstool Gradle sagte mir, dass KI die Entwicklung beschleunigen kann, indem sie die Zeit für sich wiederholende Aufgaben wie das Schreiben von Standardcode verkürzt und es Entwicklern ermöglicht, sich auf das Gesamtbild zu konzentrieren, beispielsweise sicherzustellen, dass der Code den Geschäftsanforderungen entspricht.
5. Web3 ist draußen, der große Modellentwicklungs-Stack ist da
Im aufstrebenden LLM-Entwicklungstechnologie-Stack können wir eine Reihe neuer Produkttypen beobachten, wie zum Beispiel Orchestrierungs-Frameworks (wie LangChain und LlamaIndex), Vektordatenbanken und Humanloop Warten auf die Plattform „Spielplatz“. Alle diese Produkte erweitern und/oder ergänzen die Kerntechnologie der aktuellen Ära: große Sprachmodelle
Genauso wie der Aufstieg von Tools der Cloud-nativen Ära wie Spring Cloud und Kubernetes in den vergangenen Jahren. Aber jetzt versuchen fast alle großen, kleinen und erstklassigen Unternehmen im Cloud-nativen Zeitalter ihr Bestes, ihre Tools an die KI-Technik anzupassen, was für die zukünftige Entwicklung des LLM-Technologie-Stacks von großem Nutzen sein wird.
Ja, dieses Mal ist das große Modell wie „auf den Schultern von Riesen stehen“. Die besten Innovationen in der Computertechnologie bauen immer auf dem vorherigen Fundament auf. Vielleicht ist die „Web3“-Revolution deshalb gescheitert – sie baute nicht so sehr auf der vorherigen Generation auf, sondern versuchte, sie an sich zu reißen.
Der LLM-Technologie-Stack scheint es geschafft zu haben, er ist zu einer Brücke von der Ära der Cloud-Entwicklung zu einem neueren, auf künstlicher Intelligenz basierenden Entwickler-Ökosystem geworden
Referenzlink: https://www.php.cn/link/ c589c3a8f99401b24b9380e86d939842
Das obige ist der detaillierte Inhalt vonEs wurde ein großes Modellentwicklungs-Toolset erstellt!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die PHP-Microservice-Frameworks?
- Entdeckung der drei wichtigsten Python-Modelle und der zehn häufigsten Algorithmusbeispiele
- Wie groß ist der Unterschied zwischen dem großen Modell der Alpaka-Serie und ChatGPT? Nach ausführlicher Auswertung verstummte ich
- Kingsoft Office WPS AI wird große Modelle in Tabellen, Text, Präsentationen und PDFs einbetten
- Wer sagt, dass Apple ins Hintertreffen gerät? KI wurde auf der WWDC nicht erwähnt, große Modelle wurden jedoch auf unauffällige Weise vorgestellt