
Heim >Technologie-Peripheriegeräte >KI >UniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!
UniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!

- 王林nach vorne
- 2023-09-16 20:29:10850Durchsuche
Originaltitel: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/pdf/2306.09117.pdf

Papier Idee:
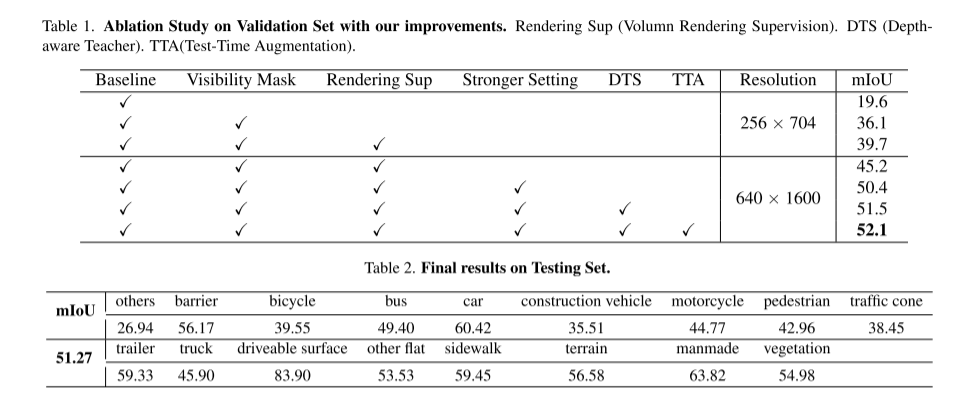
In diesem technischen Bericht schlagen wir eine Lösung namens UniOCC für visionszentrierte 3D-Belegungsvorhersagetrajektorien in der CVPR 2023 nuScenes Open Dataset Challenge vor. Bestehende Belegungsvorhersagemethoden konzentrieren sich hauptsächlich auf die Verwendung von 3D-Belegungsetiketten, um die projizierten Eigenschaften des 3D-Volumenraums zu optimieren. Der Generierungsprozess dieser Etiketten ist jedoch sehr komplex und teuer (basierend auf semantischer 3D-Annotation), ist durch die Voxelauflösung begrenzt und kann keine feinkörnige räumliche Semantik liefern. Um diese Einschränkung zu beheben, schlagen wir eine neue Methode zur Vorhersage der einheitlichen Belegung (UniOcc) vor, die explizit räumliche geometrische Einschränkungen auferlegt und die feinkörnige semantische Überwachung durch Volumenstrahl-Rendering ergänzt. Unsere Methode verbessert die Modellleistung erheblich und zeigt ein gutes Potenzial zur Reduzierung der manuellen Annotationskosten. Angesichts der mühsamen Kommentierung von 3D-Belegungen schlagen wir außerdem das tiefenbewusste Teacher Student (DTS)-Framework vor, um die Vorhersagegenauigkeit mithilfe unbeschrifteter Daten zu verbessern. Unsere Lösung erreichte 51,27 % mIoU im offiziellen Einzelmodell-Ranking und belegte in dieser Herausforderung den dritten Platz von 2D- und 3D-Darstellungen, wodurch Modelle zur Vorhersage der Belegung mit mehreren Kameras verbessert werden. In diesem Artikel wird keine neue Modellarchitektur entworfen, sondern der Schwerpunkt liegt auf der vielseitigen Plug-and-Play-Verbesserung vorhandener Modelle [3, 18, 20].
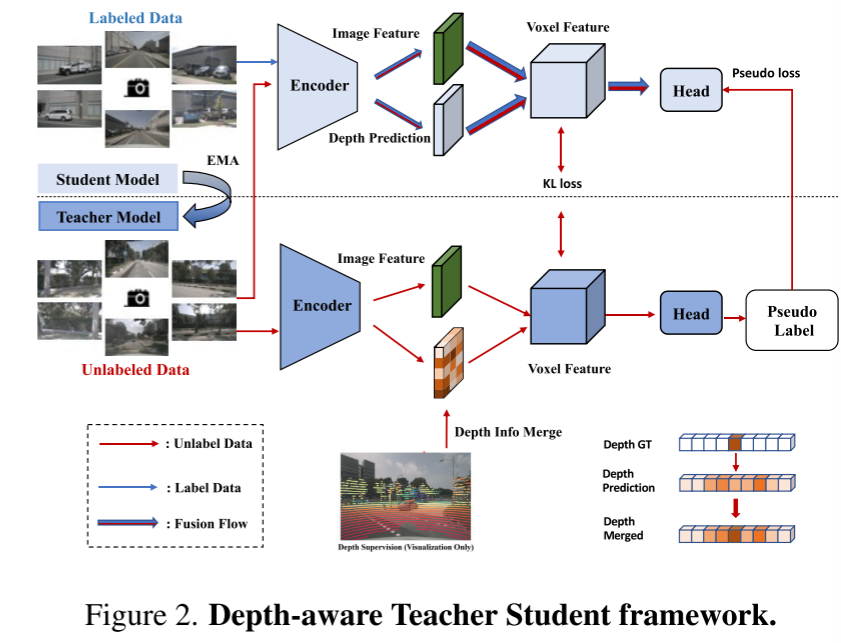
Wie folgt umgeschrieben: In diesem Artikel wird die Funktion zum Generieren von 2D-Semantik- und Tiefenkarten mithilfe von Volumenrendering implementiert, indem die Darstellung auf eine Darstellung im NeRF-Stil aktualisiert wird [1, 15, 21]. Dies ermöglicht eine feinkörnige Überwachung auf 2D-Pixelebene. Durch Strahlenabtastung dreidimensionaler Voxel können die gerenderten zweidimensionalen Pixelsemantiken und Tiefeninformationen erhalten werden. Durch die explizite Integration geometrischer Okklusionsbeziehungen und semantischer Konsistenzbeschränkungen bietet dieses Papier eine explizite Anleitung für das Modell und stellt die Einhaltung dieser Einschränkungen sicher. Es ist erwähnenswert, dass UniOcc das Potenzial hat, die Abhängigkeit von teuren semantischen 3D-Anmerkungen zu verringern. Da es keine 3D-Belegungsbezeichnungen gibt, schneiden Modelle, die nur mit unserer Volumenrendering-Überwachung trainiert wurden, sogar besser ab als Modelle, die mit der 3D-Belegungsüberwachung trainiert wurden. Dies unterstreicht das spannende Potenzial, die Abhängigkeit von teuren semantischen 3D-Annotationen zu reduzieren, da Szenendarstellungen direkt aus kostengünstigen 2D-Segmentierungsetiketten gelernt werden können. Darüber hinaus können durch den Einsatz fortschrittlicher Technologien wie SAM [6] und [14,19] die Kosten für die 2D-Segmentierungsannotation weiter gesenkt werden. In diesem Artikel wird auch das DTS-Framework (Depth Sensing Teacher-Student) vorgestellt, eine selbstüberwachte Trainingsmethode. Im Gegensatz zum klassischen Mean Teacher verbessert DTS die tiefe Vorhersage des Lehrermodells und ermöglicht so ein stabiles und effektives Training unter Verwendung unbeschrifteter Daten. Darüber hinaus werden in diesem Artikel einige einfache, aber effektive Techniken angewendet, um die Leistung des Modells zu verbessern. Dazu gehört die Verwendung sichtbarer Masken im Training, die Verwendung eines stärkeren vorab trainierten Backbone-Netzwerks, die Erhöhung der Voxelauflösung und die Implementierung von Test-Time Data Augmentation (TTA)
Hier ist eine Übersicht über das UniOcc-Framework: Bild 1Bild 2. Tiefenbewusstes Lehrer-Schüler-Framework. 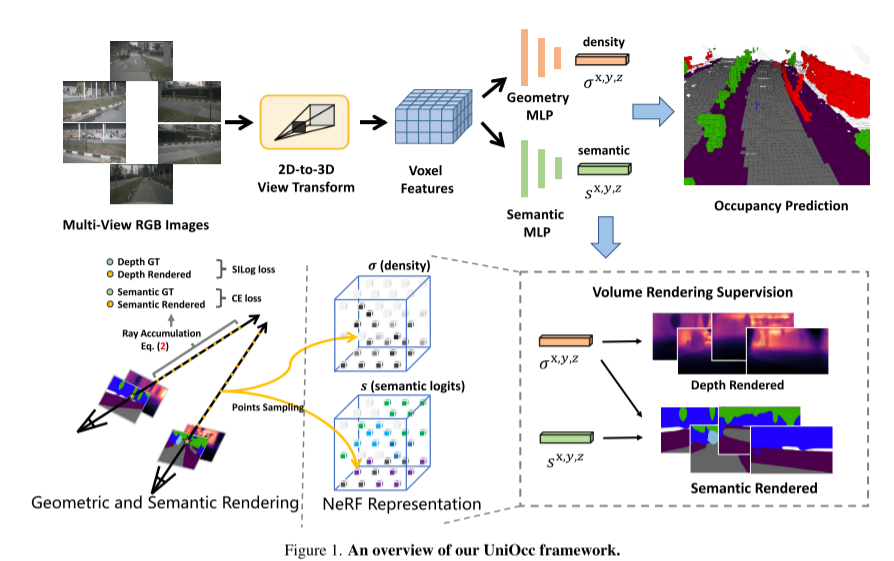
Experimentelle Ergebnisse:
Zitat:

Originallink: https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
Das obige ist der detaillierte Inhalt vonUniOcc: Vereinigung der visionszentrierten Belegungsvorhersage mit geometrischer und semantischer Darstellung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Anwendungen der Datenerfassungstechnologie umfasst die Anwendungsentwicklung intelligenter Gesundheitsarmbänder?
- Was sind die Produkte von Smart Devices?
- Besitzen Sie ein Smartphone mit drei SIM-Karten und drei Standbys?
- Verfügt vivo über einen intelligenten Sprachroboter?
- Detaillierte Erläuterung der Computer-Vision-Bibliothek opencv in Python