
Heim >Technologie-Peripheriegeräte >KI >Deine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln
Deine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-16 20:29:021400Durchsuche
Ein Buch aufzuschlagen ist wohltuend, das haben wir schon immer verstanden. Lesen kann Menschen helfen, ihre Sprachkenntnisse zu verbessern und neue Fähigkeiten zu erlernen....
Lesen kann auch die Stimmung verbessern und die psychische Gesundheit verbessern. Wer regelmäßig liest, verfügt über ein größeres Allgemeinwissen und ein tieferes Verständnis für andere Kulturen.
Darüber hinaus haben Studien bewiesen, dass Freude am Lesen mit dem akademischen Erfolg zusammenhängt.
Aber im Zeitalter der Informationsexplosion gibt es zahlreiche Online- und Offline-Leseressourcen. Was zu lesen ist, wird zu einer schwierigen Herausforderung.
Insbesondere die Leseinhalte müssen zu verschiedenen Altersgruppen passen und ansprechend sein.
Und Empfehlungssysteme sind die Lösung für diese Herausforderung. Es präsentiert den Lesern relevantes Lesematerial und hilft ihnen, ihr Interesse aufrechtzuerhalten.
Der Kern des Empfehlungssystems ist maschinelles Lernen (ML), das häufig beim Aufbau verschiedener Arten von Empfehlungssystemen eingesetzt wird: von Videos über Bücher bis hin zu E-Commerce-Plattformen.
Das trainierte ML-Modell kann jedem Benutzer individuell Empfehlungen auf der Grundlage von Benutzerpräferenzen, Benutzerengagement und empfohlenen Elementen geben und so die Benutzererfahrung verbessern.
Googles neueste Forschung schlägt ein Empfehlungssystem für Hörbuchinhalte vor, das die soziale Natur des Lesens (z. B. Bildungsumgebungen) berücksichtigt: den STUDY-Algorithmus.
Da das, was die Kollegen einer Person gerade lesen, einen erheblichen Einfluss darauf haben kann, was sie lesen möchten, ist Google eine Partnerschaft mit Learning Ally eingegangen.
Learning Ally ist eine gemeinnützige Bildungsorganisation mit einer großen digitalen Bibliothek kuratierter Hörbücher für Studenten, die sich perfekt für den Aufbau sozialer Empfehlungsmodelle eignet.
Dadurch kann das Modell von Echtzeitinformationen über die lokalisierten sozialen Gruppen der Schüler (z. B. Klassenzimmer) profitieren.
STUDY-Algorithmus
STUDY-Algorithmus verwendet eine Methode zur Modellierung des Problems des empfohlenen Inhalts als Problem der Vorhersage der Klickrate.
wobei die Interaktionswahrscheinlichkeit des simulierten Benutzers mit jedem spezifischen Element abhängt von:
1) Benutzer- und Elementeigenschaften
2) Der Interaktionsverlaufssequenz des Elements des Benutzers.
Frühere Arbeiten haben gezeigt, dass das Transformer-Modell gut zur Modellierung dieses Problems geeignet ist.
Wenn man jeden Benutzer individuell behandelt, wird die Simulation der Interaktion zu einem Problem der autoregressiven Sequenzmodellierung. Der
STUDY-Algorithmus ist das Endprodukt der Modellierung von Daten mithilfe dieses konzeptionellen Rahmens und der anschließenden Erweiterung dieses Rahmens.
Das Problem der Vorhersage der Klickrate kann die Abhängigkeiten zwischen früheren und zukünftigen Artikelpräferenzen einzelner Benutzer modellieren und während des Trainings Ähnlichkeitsmuster zwischen Benutzern lernen.
Aber ein Problem besteht darin, dass die Methode zur Vorhersage der Klickrate die Abhängigkeiten zwischen verschiedenen Benutzern nicht abbilden kann.
Zu diesem Zweck hat Google das STUDY-Modell entwickelt, das die Mängel der autoregressiven Sequenzmodellierung beheben kann, die die soziale Natur des Lesens nicht modellieren kann.
STUDY kann die Sequenzen von Büchern, die von mehreren Schülern in einer Klasse gelesen werden, zu einer Sequenz zusammenfassen und so Daten von mehreren Schülern in einem Modell sammeln.
Allerdings muss diese Datendarstellung bei der Modellierung mit einem Transformer sorgfältig untersucht werden.
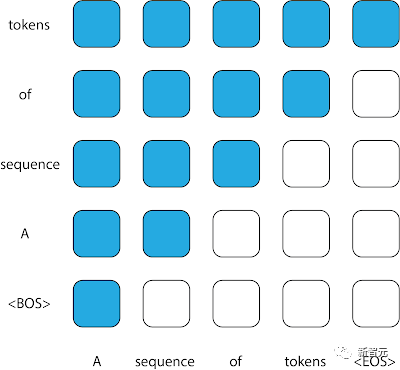
In Transformer ist die Aufmerksamkeitsmaske die Matrix, die steuert, welche Eingaben zur Vorhersage welcher Ausgaben verwendet werden können.
Das Muster, alle vorherigen Token in der Sequenz zu verwenden, um die Vorhersage der Ausgabe zu informieren, führt zu einer oberen dreieckigen Aufmerksamkeitsmatrix, die typischerweise in Kausaldekodierern zu finden ist.
Da jedoch die Sequenzeingabe in das STUDY-Modell nicht in chronologischer Reihenfolge erfolgt, obwohl jede ihrer Teilsequenzen in chronologischer Reihenfolge vorliegt, ist der herkömmliche Kausaldecoder für diese Sequenz nicht mehr geeignet.
Beim Versuch, jeden Token vorherzusagen, lässt das Modell nicht zu, dass sich die Aufmerksamkeit auf jeden Token richtet, der in der Sequenz davor erscheint. Einige dieser Token können spätere Zeitstempel haben und Informationen enthalten, die zum Zeitpunkt der Bereitstellung nicht verfügbar sind .
 Bilder
Bilder
Aufmerksamkeitsmasken, die häufig in Kausaldecodern verwendet werden. Jede Spalte stellt eine Ausgabe dar, und jede Spalte stellt eine Ausgabe dar. Ein Matrixeintrag mit dem Wert 1 (blau dargestellt) an einer bestimmten Position zeigt an, dass das Modell die Eingabe für diese Zeile beobachten kann, wenn es die Ausgabe der entsprechenden Spalte vorhersagt, während ein Wert von 0 (weiß dargestellt) das Gegenteil anzeigt . Das
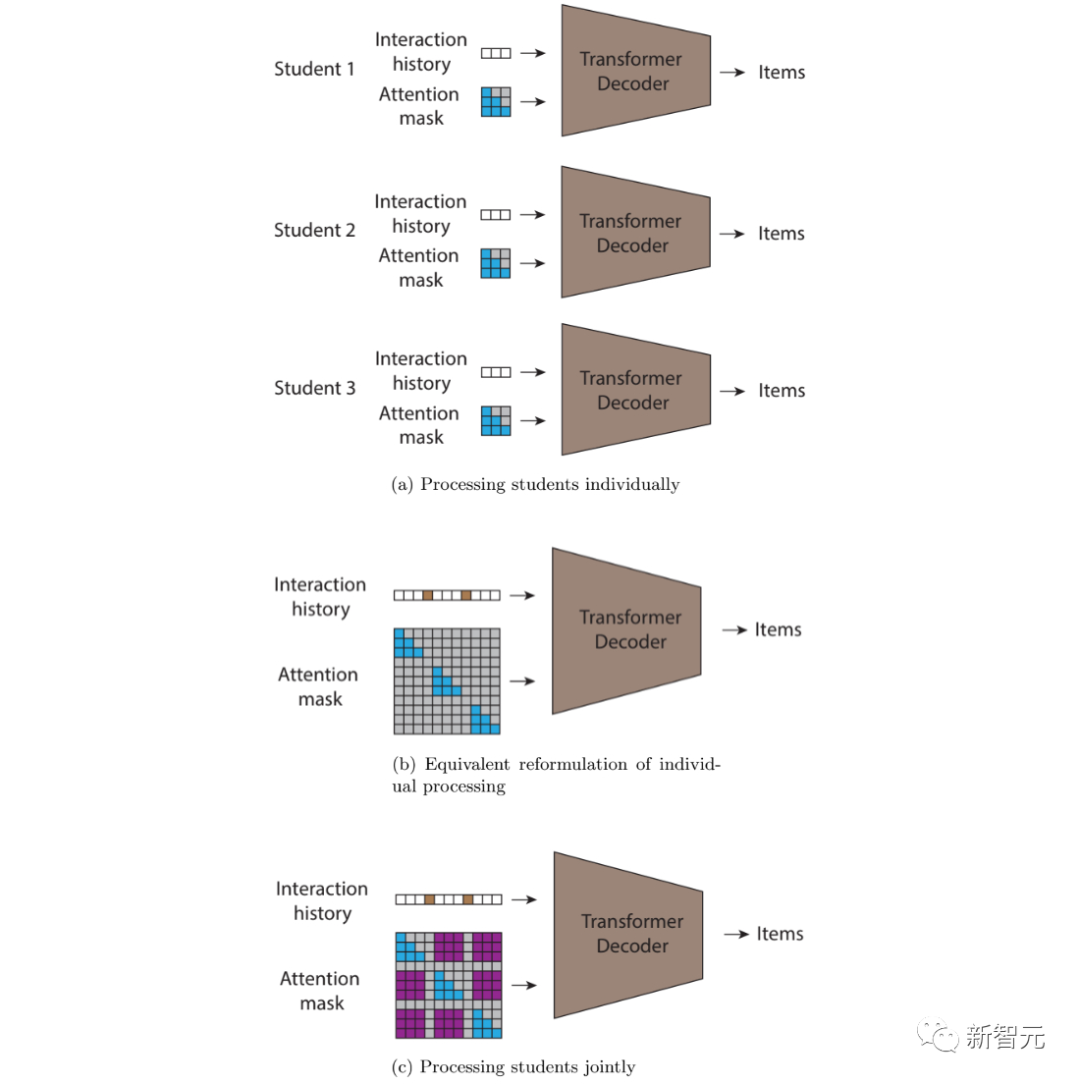
STUDY-Modell basiert auf einem Kausaltransformator, der die Dreiecksmatrix-Aufmerksamkeitsmaske durch eine zeitstempelbasierte flexible Aufmerksamkeitsmaske ersetzt und so Aufmerksamkeit über verschiedene Teilsequenzen hinweg ermöglicht.
Im Vergleich zu gewöhnlichen Konvertern verwaltet das STUDY-Modell eine kausale Dreiecksaufmerksamkeitsmatrix in einer Sequenz und verfügt über flexible Werte in verschiedenen Sequenzen, die vom Zeitstempel abhängen.
Daher beziehen sich Vorhersagen für jeden Ausgabepunkt in der Sequenz auf alle Eingabepunkte, die in der Vergangenheit relativ zum aktuellen Zeitpunkt aufgetreten sind, unabhängig davon, ob sie vor oder nach dem aktuellen Eingabepunkt in der Sequenz aufgetreten sind.
Diese kausale Einschränkung ist wichtig, denn wenn diese Einschränkung während des Trainings nicht durchgesetzt wird, lernt das Modell möglicherweise, zukünftige Informationen zu verwenden, um Vorhersagen zu treffen, was in realen Einsätzen nicht möglich ist.
 Bilder
Bilder
(a) Ein sequentieller autoregressiver Transformator, der jeden Benutzer individuell behandeln kann; (b) Ein äquivalenter gemeinsamer Vorwärtsdurchlauf, der dasselbe berechnet wie (a) (c) Durch Einführung Neue Nicht-Null-Werte in der Aufmerksamkeitsmaske (in Lila dargestellt) ermöglichen den Informationsfluss zwischen Benutzern. Zu diesem Zweck haben wir zugelassen, dass Vorhersagen von allen Interaktionen mit früheren Zeitstempeln abhängig gemacht werden, unabhängig davon, ob die Interaktionen vom selben Benutzer stammten Mehrere Baselines. Machen Sie einen Vergleich.
Das Team verwendete einen autoregressiven CTR-Decoder (genannt „individuell“), eine K-Nearest-Neighbor-Baseline (KNN) und eine vergleichbare soziale Baseline – das Social Attention Memory Network (SAMN).
Sie nutzten Daten aus dem ersten Studienjahr für die Ausbildung und Daten aus dem zweiten Studienjahr für Validierung und Tests.
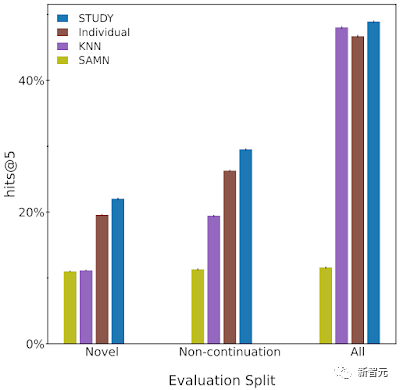
Das Team bewertet diese Modelle, indem es den Prozentsatz der Zeit misst, mit der der nächste Artikel, mit dem der Benutzer tatsächlich interagiert, zu den Top-n-Vorschlägen des Modells gehört.
Zusätzlich zur Bewertung des Modells anhand des gesamten Testsatzes meldet das Team auch die Modellergebnisse für zwei Teilsätze des Testsatzes, die anspruchsvoller sind als der gesamte Datensatz.
Es ist zu beobachten, dass Schüler in der Regel mehrmals mit Hörbüchern interagieren, daher ist es trivial, einfach das letzte Buch zu empfehlen, das ein Benutzer gelesen hat.
Daher bezeichnen die Forscher die erste Testteilmenge als „Nicht-Fortsetzung“. In dieser Teilmenge untersuchen wir nur die Empfehlungsleistung jedes Modells, wenn Schüler mit Büchern interagieren, die sich von der vorherigen Interaktion unterscheiden.
Darüber hinaus hat das Team auch beobachtet, dass die Schüler die Bücher, die sie in der Vergangenheit gelesen haben, noch einmal durchgehen, sodass die empfohlenen Bücher für jeden Schüler auf die Bücher beschränkt sind, die er in der Vergangenheit gelesen hat, was bei der Prüfung möglich ist set Erzielen Sie großartige Leistungen.
Während es durchaus sinnvoll sein kann, Schülern ihre Lieblingsbücher aus der Vergangenheit zu empfehlen, liegt der Wert von Empfehlungssystemen zum großen Teil darin, Benutzern neue, unbekannte Inhalte zu empfehlen.
Um dies zu messen, evaluierte das Team das Modell anhand einer Teilmenge des Testsatzes, bei dem die Schüler zum ersten Mal mit der Bibliographie interagierten. Wir nennen diese Bewertungsteilmenge „neue Teilmenge“.
Es lässt sich feststellen, dass „STUDY“ in fast allen Bewertungen besser als andere Modelle abschneidet.
Bilder
Die Bedeutung der richtigen Gruppierung
 Der Kern des STUDY-Algorithmus besteht darin, Benutzer zu gruppieren und gemeinsame Schlussfolgerungen für mehrere Benutzer derselben Gruppe in einem einzigen Vorwärtsdurchlauf des Modells durchzuführen.
Der Kern des STUDY-Algorithmus besteht darin, Benutzer zu gruppieren und gemeinsame Schlussfolgerungen für mehrere Benutzer derselben Gruppe in einem einzigen Vorwärtsdurchlauf des Modells durchzuführen.
Die Forscher untersuchten anhand einer Ablationsstudie, wie wichtig die praktische Gruppierung für die Modellleistung ist.
In dem vorgeschlagenen Modell gruppierten die Forscher alle Schüler derselben Klasse und Schule.
Wir haben dann mit Gruppierungen experimentiert, die von allen Schülern derselben Klasse und desselben Bezirks definiert wurden, sowie mit der Gruppierung aller Schüler in einer Gruppe und der Verwendung einer zufälligen Teilmenge bei jedem Vorwärtsdurchlauf.
Die Forscher verglichen diese Modelle auch mit „persönlichen“ Modellen als Referenz.
Studien haben ergeben, dass die Verwendung stärker lokalisierter Gruppen effektiver ist, d. h. Schul- und Klassengruppierungen sind besser als Schulbezirks- und Klassengruppierungen.
Dies unterstützt die Hypothese, dass das Forschungsmodell erfolgreich ist, weil Aktivitäten wie Lesen sozial sind: Die Leseentscheidungen der Menschen korrelieren wahrscheinlich mit den Leseentscheidungen ihrer Mitmenschen.
Beide Modi übertreffen die beiden anderen Modi (Einzelgruppenmodus und Einzelmodus), ohne Klassenstufen zur Gruppierung von Schülern zu verwenden.
Dies zeigt, dass Daten von Benutzern mit ähnlichen Leseniveaus und Interessen zur Verbesserung der Leistung des Modells beitragen.
Schließlich beschränkte sich diese Google-Studie auf die Modellierung einer Nutzergruppe unter der Annahme, dass soziale Beziehungen homogen sind.
Referenz:
https://www.php.cn/link/0b32f1a9efe5edf3dd2f38b0c0052bfe
Das obige ist der detaillierte Inhalt vonDeine Freunde schauen auch zu! Der Google STUDY-Algorithmus unterstützt das Buchlisten-Empfehlungssystem, um Schülern die Lust am Lesen zu vermitteln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist die Darstellungsform von Ton- und Videoinformationen im Computer?
- Was bedeutet bps bei der Beschreibung der Informationsübertragung?
- So fragen Sie Systemversionsinformationen unter Linux ab
- Planetenwettbewerb |. 167 Auszeichnungen gewonnen! Live-Übertragung der Botball International Educational Robot Conference Asia Branch