
Heim >Technologie-Peripheriegeräte >KI >Andrew Ng gefällt es! Wissenschaftler von Harvard und MIT haben mithilfe von Schach bewiesen, dass große Sprachmodelle tatsächlich die Welt „verstehen'.
Andrew Ng gefällt es! Wissenschaftler von Harvard und MIT haben mithilfe von Schach bewiesen, dass große Sprachmodelle tatsächlich die Welt „verstehen'.

- 王林nach vorne
- 2023-09-15 11:29:011567Durchsuche
Im Jahr 2021 veröffentlichte die Linguistin Emily M. Bender einen Artikel, in dem sie argumentierte, dass große Sprachmodelle nichts anderes als „stochastische Papageien“ seien. Sie verstehen die reale Welt nicht und zählen nur das Vorkommen eines bestimmten Wortes generiert zufällig plausibel aussehende Wörter wie ein Papagei.
Aufgrund der Uninterpretierbarkeit neuronaler Netze ist sich die akademische Gemeinschaft auch nicht darüber im Klaren, ob das Sprachmodell ein zufälliger Papagei ist, und die Meinungen verschiedener Parteien gehen stark auseinander.
Aufgrund des Mangels an allgemein anerkannten Tests ist die Frage, ob ein Modell „die Welt verstehen“ kann, eher eine philosophische als eine wissenschaftliche Frage geworden.
Kürzlich veröffentlichten Forscher der Harvard University und des MIT gemeinsam eine neue Studie Othello-GPT, die die Wirksamkeit interner Darstellungen in einem einfachen Brettspiel überprüfte. Sie glauben, dass die interne Darstellung des von ihr erstellten Sprachmodells tatsächlich etabliert ist ein Weltmodell, nicht nur eine einfache Erinnerung oder Statistik, aber die Quelle seiner Fähigkeit ist noch unklar.

Link zum Papier: https://arxiv.org/pdf/2210.13382.pdf
Der experimentelle Prozess ist sehr einfach. Ohne vorherige Kenntnis der Othello-Regeln stellten die Forscher fest, dass das Modell Vorhersagen treffen kann Erfassen Sie legale Spielzüge und erfassen Sie den Zustand des Bretts mit sehr hoher Genauigkeit.
Andrew Ng drückte in der Kolumne „Brief“ große Anerkennung für diese Forschung aus. Er glaubt, dass es auf der Grundlage dieser Forschung Grund zu der Annahme gibt, dass groß angelegte Sprachmodelle ein ausreichend komplexes Weltmodell aufgebaut haben, und zwar bis zu einem gewissen Grad Insofern verstehen sie die Welt.
Blog-Link: https://www.deeplearning.ai/the-batch/does-ai-understand-the-world/
Allerdings sagte Andrew Ng auch, dass Philosophie zwar wichtig ist, Diese Debatte wird wahrscheinlich ewig weitergehen, also kommen wir zum Programmieren!
Schachbrett-Weltmodell
Stellt man sich das Schachbrett als einfache „Welt“ vor und fordert, dass das Modell während des Spiels fortlaufend Entscheidungen trifft, kann man zunächst testen, ob das Sequenzmodell die Weltdarstellung erlernen kann.

Die Forscher wählten ein einfaches Othello-Spiel, Othello, als experimentelle Plattform. Die Regel besteht darin, vier Schachfiguren in die Mitte des 8*8-Schachbretts zu legen, jeweils zwei für Schwarz und Weiß Abwechselnd werden alle feindlichen Figuren (außer Leerzeichen) zwischen den beiden Figuren der eigenen Seite zu eigenen Figuren (genannt Eroberungsfiguren). Am Ende ist der Vorstand voll besetzt, derjenige mit den meisten Söhnen gewinnt.
Im Vergleich zu Schach sind die Regeln von Othello viel einfacher. Gleichzeitig ist der Suchraum von Schachspielen so groß, dass das Modell die Sequenzgenerierung nicht über den Speicher abschließen kann, sodass es sich sehr gut zum Testen der Weltdarstellung eignet Lernfähigkeit des Modells.
Othello-Sprachmodell
Die Forscher trainierten zunächst ein GPT-Varianten-Sprachmodell (Othello-GPT) und gaben das Spielskript (eine Reihe von Schachbewegungsoperationen, die der Spieler durchführte) in das Modell ein, aber das Modell enthielt keine Informationen über Vorkenntnisse des Spiels und der dazugehörigen Regeln.
Das Modell ist nicht explizit darauf trainiert, Strategieverbesserungen, Gewinnspiele usw. zu verfolgen, weist jedoch eine relativ hohe Genauigkeit bei der Generierung legaler Othello-Bewegungsoperationen auf.
Datensatz
Die Forscher verwendeten zwei Sätze von Trainingsdaten:
Championship (Championship) konzentrierte sich mehr auf die Datenqualität, die hauptsächlich von professionellen menschlichen Spielern in zwei Othello-Turnieren übernommen wurde. Ein strategischerer Denkschritt , aber nur 7605 bzw. 132921 Spielproben wurden gesammelt. Nachdem die beiden Datensätze zusammengeführt wurden, wurden sie im Verhältnis 8:2 zufällig in einen Trainingssatz (20 Millionen Proben) und einen Verifizierungssatz (3,796 Millionen Proben) aufgeteilt. .
Synthetisch (Synthetisch) legt mehr Wert auf den Datenumfang und besteht aus zufälligen und legalen Bewegungsoperationen. Die Datenverteilung unterscheidet sich vom Meisterschaftsdatensatz, wird jedoch gleichmäßig aus dem Othello-Spielbaum mit 20 Millionen Stichproben entnommen . Wird für das Training und 3,796 Millionen Proben für die Validierung verwendet.
Die Beschreibung jedes Spiels besteht aus einer Reihe von Token und die Vokabulargröße beträgt 60 (8*8-4)
Modell und Training
Die Architektur des Modells ist 8-schichtig GPT-Modell mit 8 Köpfen, die versteckte Dimension beträgt 512
Die Gewichte des Modells werden vollständig zufällig initialisiert, einschließlich der Worteinbettungsebene, obwohl es eine geometrische Beziehung in der Wortliste gibt, die die Schachbrettposition darstellt (wie z. B. C4). niedriger als B4) wird diese induktive Verzerrung nicht klar zum Ausdruck gebracht und überlässt es dem Modell, zu lernen.
Legale Bewegungen vorhersagen
Der Hauptbewertungsindikator des Modells ist, ob die vom Modell vorhergesagten Bewegungsvorgänge den Regeln von Othello entsprechen.
Othello-GPT, das auf dem synthetischen Datensatz trainiert wurde, hat eine Fehlerrate von 0,01 % und auf dem Meisterschaftsdatensatz eine Fehlerrate von 5,17 %, verglichen mit einer Fehlerrate von 93,29 % für das untrainierte Othello-GPT Diese beiden Datensätze ermöglichen es dem Modell, die Spielregeln bis zu einem gewissen Grad zu lernen.
Eine mögliche Erklärung ist, dass sich das Modell alle Bewegungsabläufe des Othello-Spiels merkt.
Um diese Vermutung zu testen, haben die Forscher einen neuen Datensatz synthetisiert: Zu Beginn jedes Spiels hat Othello vier mögliche Eröffnungspositionen (C5, D6, E3 und F4) und alle C5-Eröffnungspositionen. Es wurde als Trainingssatz verwendet und dann wurden die C5-Eröffnungsdaten als Test verwendet, das heißt, es wurde festgestellt, dass die Modellfehlerrate immer noch nur 0,02 % betrug Die hohe Leistung von Othello-GPT ist also nicht auf das Gedächtnis zurückzuführen, da die Testdaten während des Trainingsprozesses völlig unsichtbar sind. Was genau sorgt also dafür, dass das Modell erfolgreich vorhersagt?
Untersuchung interner Darstellungen
Ein häufig verwendetes Werkzeug zur Erkennung interner Darstellungen neuronaler Netze sind Sonden. Jede Sonde ist ein Klassifikator oder Regressor, dessen Eingabe aus den internen Aktivierungen des Netzwerks besteht und darauf trainiert ist, interessierende Merkmale vorherzusagen.
Um bei dieser Aufgabe zu erkennen, ob die interne Aktivierung von Othello-GPT die Darstellung des aktuellen Schachbrettzustands enthält, wird nach Eingabe der Bewegungssequenz der interne Aktivierungsvektor verwendet, um den nächsten Bewegungsschritt vorherzusagen.
Bei Verwendung linearer Sonden ist die trainierte interne Darstellung von Othello-GPT nur geringfügig genauer als zufällige Schätzungen.
 Bei Verwendung nichtlinearer Sonden (zweischichtiges MLP) sinkt die Fehlerrate erheblich, was beweist, dass der Platinenstatus nicht auf einfache Weise in der Netzwerkaktivierung gespeichert wird.
Bei Verwendung nichtlinearer Sonden (zweischichtiges MLP) sinkt die Fehlerrate erheblich, was beweist, dass der Platinenstatus nicht auf einfache Weise in der Netzwerkaktivierung gespeichert wird.
Interventionsexperiment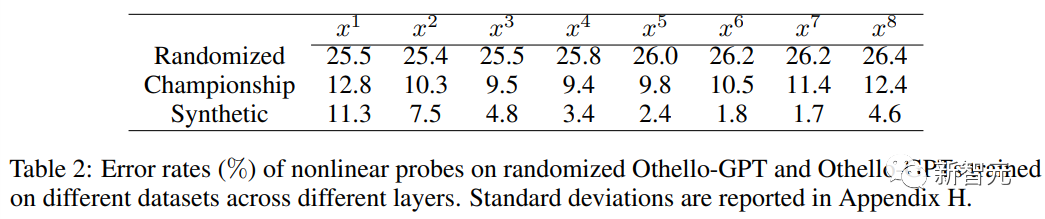
Um den kausalen Zusammenhang zwischen Modellvorhersagen und Darstellungen der entstehenden Welt zu bestimmen, das heißt, ob der Zustand des Boards tatsächlich die Vorhersageergebnisse des Netzwerks beeinflusst, führten die Forscher eine Reihe von Interventionsexperimenten durch und messen die Ergebnisse Auswirkungen.
Anhand einer Reihe von Aktivierungen von Othello-GPT verwenden Sie Sonden, um den Board-Status vorherzusagen, zeichnen Sie die zugehörigen Bewegungsvorhersagen auf und ändern Sie dann die Aktivierungen, damit die Sonden den aktualisierten Board-Status vorhersagen können.
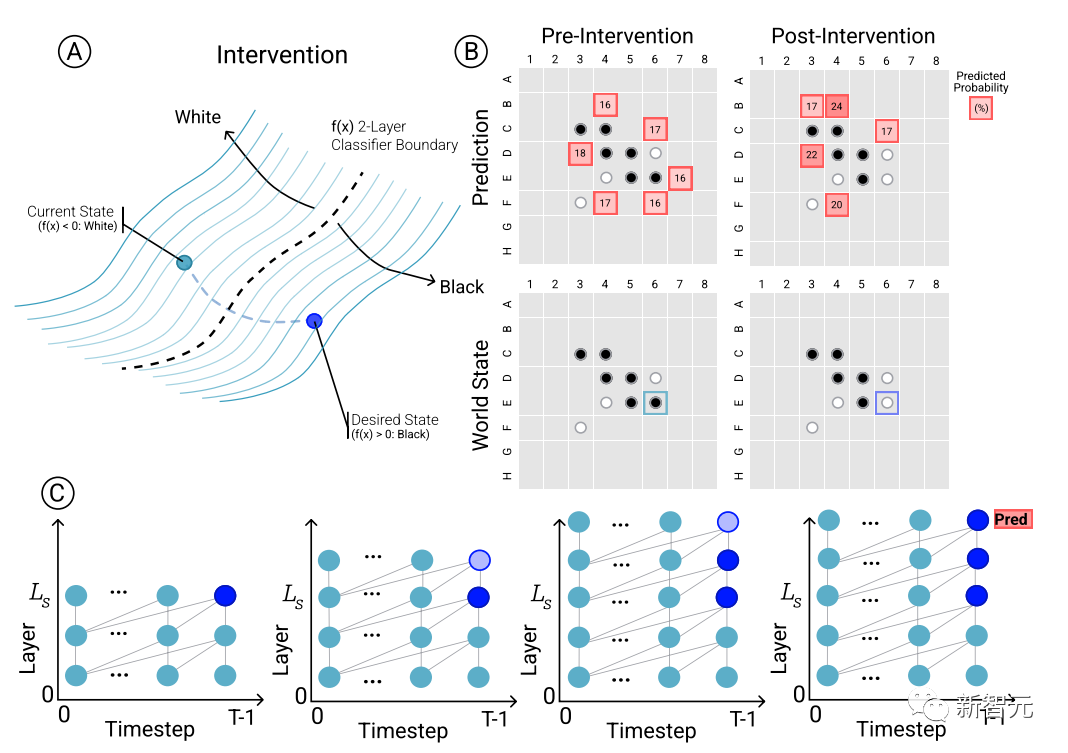 Der Eingriffsvorgang umfasst das Ändern der Schachfigur in einer bestimmten Position von Weiß auf Schwarz usw. Eine kleine Änderung führt zu den Modellergebnissen und stellt fest, dass die interne Darstellung die Vorhersage zuverlässig vervollständigen kann, d. Es besteht eine Lücke zwischen der internen Darstellung und der Modellvorhersage.
Der Eingriffsvorgang umfasst das Ändern der Schachfigur in einer bestimmten Position von Weiß auf Schwarz usw. Eine kleine Änderung führt zu den Modellergebnissen und stellt fest, dass die interne Darstellung die Vorhersage zuverlässig vervollständigen kann, d. Es besteht eine Lücke zwischen der internen Darstellung und der Modellvorhersage.
Visualisierung
Zusätzlich zu den Interventionsexperimenten zur Überprüfung der Gültigkeit der internen Darstellung visualisierten die Forscher beispielsweise auch die Vorhersageergebnisse. Beispielsweise kann das Modell für jede Schachfigur auf dem Schachbrett gefragt werden, ob die Interventionstechnologie vorhanden ist wird verwendet, um die Schachfigur zu ändern. Wie sich die vorhergesagten Ergebnisse ändern, hängt von der Bedeutung der vorhergesagten Ergebnisse ab.
Dann werden die Karten basierend auf der von top1 vorhergesagten Ausprägung des aktuellen Schachbrettstatus eingefärbt und visualisiert. Da die gezeichnete Karte auf der Grundlage des latenten Raums des Netzwerks eingegeben wird, kann sie auch als latente Ausprägungskarte bezeichnet werden.
Es ist ersichtlich, dass in den latenten Salienzkarten der Top-1-Vorhersagen von Othello-GPTs, die sowohl auf synthetischen als auch auf Meisterschaftsdatensätzen trainiert wurden, klare Muster erkennbar sind.
Die synthetische Version von Othello-GPT zeigt einen höheren Signifikanzwert bei legalen Operationspositionen, während der Signifikanzwert bei illegalen Operationen deutlich niedriger ist. Selbst Schachspieler mit etwas Erfahrung können die Absicht des Modells erkennen; Die Ausprägungskarte der Turnierversion ist zwar relativ hoch, andere Positionen weisen jedoch auch eine höhere Ausprägung auf. Dies kann daran liegen, dass Othello-Meister die Gesamtsituation stärker berücksichtigen.
Das obige ist der detaillierte Inhalt vonAndrew Ng gefällt es! Wissenschaftler von Harvard und MIT haben mithilfe von Schach bewiesen, dass große Sprachmodelle tatsächlich die Welt „verstehen'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!