Dieser Artikel schlägt eine einfache und effektive Methode OPRO vor, die ein großes Sprachmodell als Optimierer verwendet. Die Optimierungsaufgabe kann in natürlicher Sprache beschrieben werden, was besser ist als die von Menschen entworfenen Eingabeaufforderungen.
Optimierung ist in allen Bereichen von entscheidender Bedeutung. Einige Optimierungen beginnen mit der Initialisierung und aktualisieren dann die Lösung iterativ, um die Zielfunktion zu optimieren. Solche Optimierungsalgorithmen müssen häufig für einzelne Aufgaben angepasst werden, um den spezifischen Herausforderungen des Entscheidungsraums gerecht zu werden, insbesondere bei der ableitungsfreien Optimierung. In der Studie, die wir als Nächstes vorstellen werden, wählten die Forscher einen anderen Ansatz. Sie verwendeten große Sprachmodelle (LLM), um als Optimierer zu fungieren, und erzielten bei verschiedenen Aufgaben eine bessere Leistung als von Menschen entworfene Hinweise. Diese Forschung stammt von Google DeepMind. Sie haben eine einfache und effektive Optimierungsmethode OPRO (Optimierung durch PROmpting) vorgeschlagen, bei der die Optimierungsaufgabe in natürlicher Sprache beschrieben werden kann. Die Eingabeaufforderung von LLM kann beispielsweise „Take“ sein „Ein tiefer Atemzug: Lösen Sie dieses Problem Schritt für Schritt“, oder es könnte lauten: „Kombinieren wir unsere numerischen Befehle und unser klares Denken, um die Antwort schnell und genau zu entschlüsseln“ und so weiter. In jedem Optimierungsschritt generiert LLM eine neue Lösung basierend auf Hinweisen zuvor generierter Lösungen und deren Werten, bewertet dann die neue Lösung und fügt sie dem nächsten Optimierungsschritt Prompt hinzu. Abschließend wendet die Studie die OPRO-Methode auf die lineare Regression und das Problem des Handlungsreisenden (das berühmte NP-Problem) an und fährt dann mit der Prompt-Optimierung fort, mit dem Ziel, Anweisungen zu finden, die die Aufgabengenauigkeit maximieren. In diesem Artikel wird eine umfassende Bewertung mehrerer LLMs durchgeführt, darunter Text-Bison und Palm 2-L in der PaLM-2-Modellfamilie sowie gpt-3.5-turbo und gpt-4 in der GPT-Modellfamilie. Das Experiment optimierte die Eingabeaufforderungen für GSM8K und Big-Bench Hard. Die Ergebnisse zeigen, dass die besten von OPRO optimierten Eingabeaufforderungen 8 % höher sind als die manuell erstellten Eingabeaufforderungen für GSM8K und höher als die manuell erstellten Eingabeaufforderungen für die Big-Bench-Hard-Aufgabe. Leistung bis zu 50 %. 
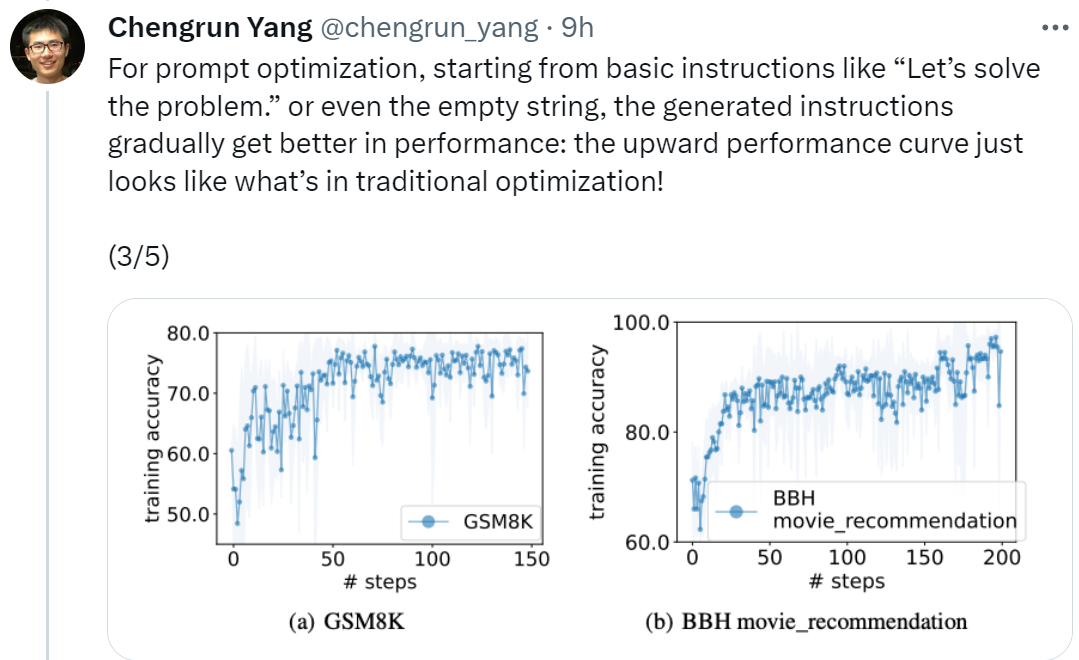
Adresse des Artikels: https://arxiv.org/pdf/2309.03409.pdfChengrun Yang, der Erstautor des Artikels und Forscher bei Google DeepMind, sagte: „Um Leistung zu erbringen Bei der sofortigen Optimierung beginnen wir mit „Lass uns beginnen“. Beginnend mit grundlegenden Anweisungen wie „Lösen Sie das Problem“ oder sogar einer leeren Zeichenfolge verbessern die von OPRO generierten Anweisungen die LLM-Leistung schrittweise. Die in der folgenden Abbildung dargestellte Aufwärtsleistungskurve sieht genauso aus wie die Situation bei der traditionellen Optimierung! Menschen und können auf ähnliche Aufgaben übertragen werden. IT und Text-Bison sind prägnanter, während die Anweisungen von GPT lang und detailliert sind. Obwohl einige Anweisungen der obersten Ebene „Schritt-für-Schritt“-Eingabeaufforderungen enthalten, kann OPRO andere semantische Ausdrücke finden und eine vergleichbare oder bessere Genauigkeit erreichen. Einige Forscher sagten jedoch: „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen.“ Dieser Tipp ist auf Googles PaLM-2 (Genauigkeitsrate 80,2) sehr effektiv. Wir können jedoch nicht garantieren, dass es bei allen Modellen und in allen Situationen funktioniert, daher sollten wir es nicht überall blind verwenden.
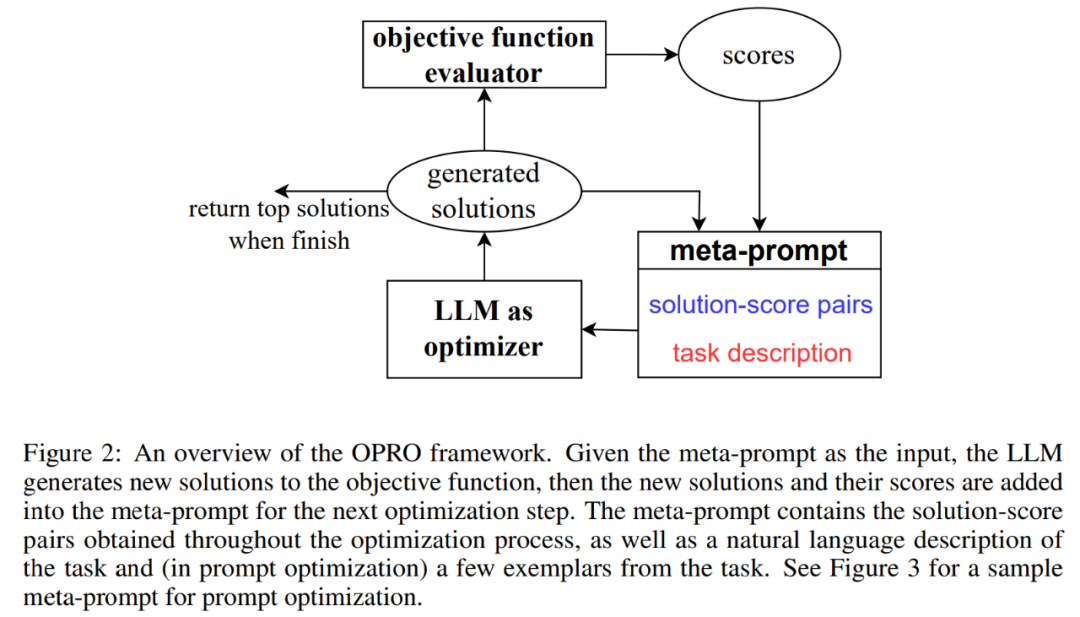
Abbildung 2 zeigt das Gesamtgerüst von OPRO. Bei jedem Optimierungsschritt generiert LLM Kandidatenlösungen für die Optimierungsaufgabe basierend auf der Beschreibung des Optimierungsproblems und zuvor bewerteten Lösungen im Meta-Prompt (unterer rechter Teil von Abbildung 2). Als nächstes bewertet LLM die neuen Lösungen und fügt sie zu Metatipps für den anschließenden Optimierungsprozess hinzu. Der Optimierungsprozess wird beendet, wenn LLM keine neue Lösung mit einem besseren Optimierungswert vorschlägt oder die maximale Anzahl an Optimierungsschritten erreicht.
Abbildung 3 zeigt ein Beispiel. Meta-Hinweise enthalten zwei Kerninhalte: Der erste Teil sind die zuvor generierten Hinweise und ihre entsprechende Trainingsgenauigkeit, der zweite Teil ist die Beschreibung des Optimierungsproblems, einschließlich mehrerer zufällig ausgewählter Beispiele aus dem Trainingssatz, um die interessierende Aufgabe zu veranschaulichen.
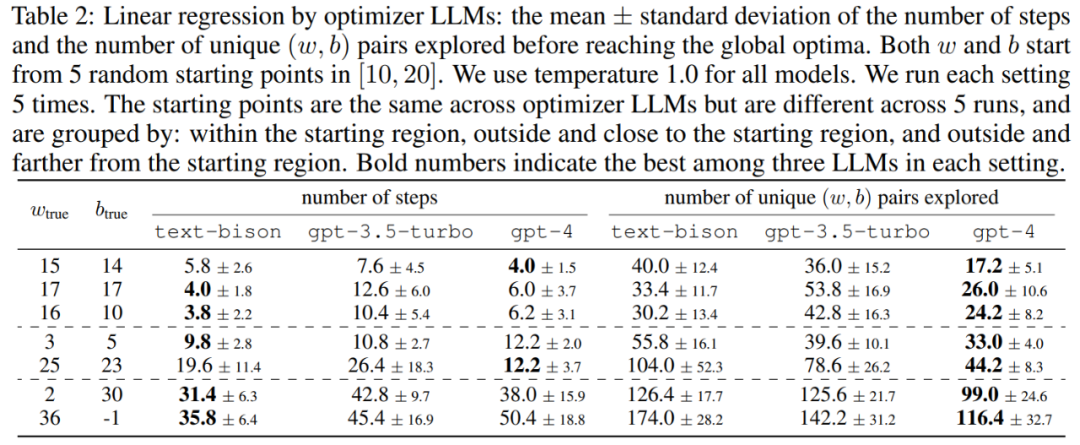
Dieser Artikel demonstriert zunächst das Potenzial von LLM als Optimierer für „mathematische Optimierung“. Die Ergebnisse des linearen Regressionsproblems sind in Tabelle 2 dargestellt:
Als nächstes untersucht der Artikel auch die Ergebnisse von OPRO zum Problem des Handlungsreisenden (TSP). Konkret bezieht sich TSP auf einen gegebenen Satz Aus n Knoten und ihren Koordinaten besteht die TSP-Aufgabe darin, den kürzesten Weg ausgehend vom Startknoten zu finden, alle Knoten zu durchqueren und schließlich zum Startknoten zurückzukehren.
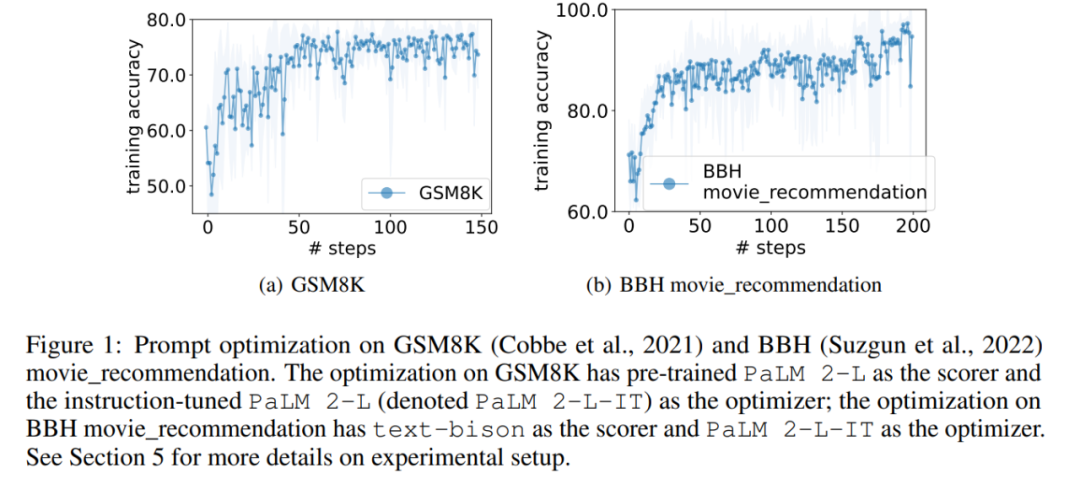
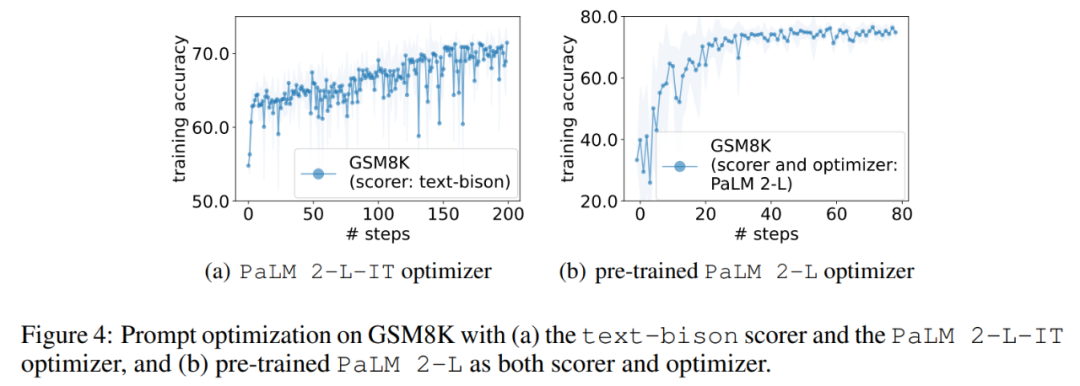
Im Experiment verwendet dieser Artikel das vorab trainierte PaLM 2-L, das durch Anweisungen fein abgestimmte PaLM 2-L, Text-Bison, GPT-3.5-Turbo, und gpt-4 als LLM-Optimierer; vorab trainiertes PaLM 2-L und text-bison als Scorer-LLM. Beim Bewertungsbenchmark GSM8K geht es um Grundschulmathematik, mit 7473 Trainingsbeispielen und 1319 Testbeispielen; der Big-Bench Hard (BBH)-Benchmark deckt ein breites Themenspektrum ab, das über arithmetisches Denken hinausgeht, einschließlich symbolischer Operationen und gesundem Menschenverstand . Ergebnisse von GSM8K Die Kurve zeigt einen allgemeinen Aufwärtstrend, wobei während des Optimierungsprozesses mehrere Sprünge auftreten: Als nächstes zeigt dieser Artikel die Ergebnisse der Verwendung des Text-Bison-Scorers und des PaLM 2-L-IT-Optimierers zur Generierung der Q_begin-Anweisung. In diesem Artikel beträgt die Trainingsgenauigkeit zu diesem Zeitpunkt 57,1, ausgehend von leeren Anweisungen, und dann beginnt die Trainingsgenauigkeit zu steigen. Die Optimierungskurve in Abbildung 4 (a) zeigt einen ähnlichen Aufwärtstrend, bei dem es einige Sprünge in der Trainingsgenauigkeit gibt: BBH-Ergebnisse
Abbildung 5 zeigt visuell alle 23 Unterschiede in der Genauigkeit für jeden Aufgabe im Vergleich zur Anweisung „Lass uns Schritt für Schritt denken“ zwischen der BBH-Aufgabe. Zeigt, dass OPRO Anweisungen besser findet als „Lass uns Schritt für Schritt denken“. Bei fast allen Aufgaben gibt es einen großen Vorteil: Die in diesem Dokument enthaltenen Anweisungen übertrafen ihn um mehr als 5 % bei 19/23 Aufgaben mit dem PaLM 2-L-Grader und bei 15/23 Aufgaben mit dem Text-Bison-Grader.
Ähnlich wie bei GSM8K wird in diesem Artikel festgestellt, dass die Optimierungskurven fast aller BBH-Aufgaben einen Aufwärtstrend aufweisen, wie in Abbildung 6 dargestellt. Das obige ist der detaillierte Inhalt vonDeepMind hat herausgefunden, dass die schnelle Methode, großen Modellen „Atmen Sie tief ein und machen Sie einen Schritt nach dem anderen' zu vermitteln, äußerst effektiv ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!