
Heim >Technologie-Peripheriegeräte >KI >Mit 180 Milliarden Parametern wird das weltweit führende Open-Source-Großmodell Falcon offiziell angekündigt! Zerstöre LLaMA 2, die Leistung liegt nahe an GPT-4
Mit 180 Milliarden Parametern wird das weltweit führende Open-Source-Großmodell Falcon offiziell angekündigt! Zerstöre LLaMA 2, die Leistung liegt nahe an GPT-4

- PHPznach vorne
- 2023-09-13 16:13:011117Durchsuche
Über Nacht hat das weltweit leistungsstärkste Open-Source-Großmodell Falcon 180B das gesamte Internet in Aufruhr versetzt!
Mit 180 Milliarden Parametern hat Falcon das Training auf 3,5 Billionen Token abgeschlossen und liegt direkt an der Spitze der Hugging Face-Rangliste.
Im Benchmark-Test besiegte Falcon 180B Llama 2 in verschiedenen Aufgaben wie Argumentation, Kodierung, Leistungs- und Wissenstests.
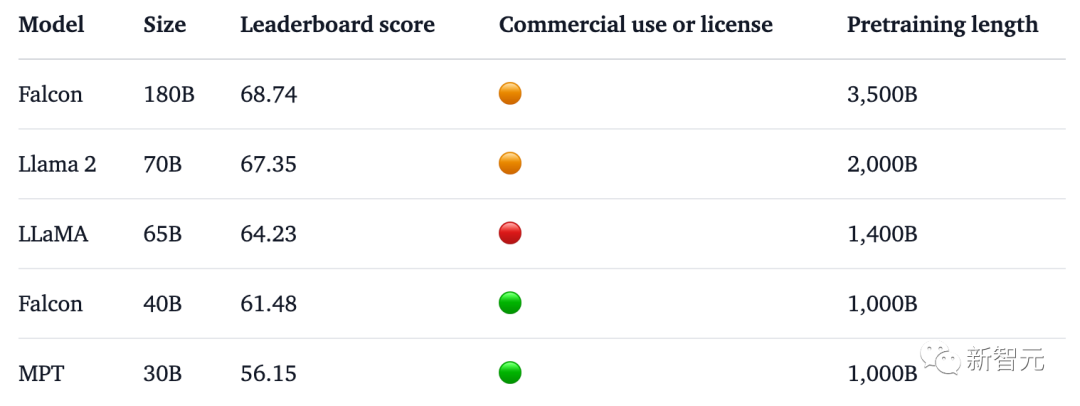
Selbst Falcon 180B liegt auf Augenhöhe mit Google PaLM 2 und seine Leistung liegt nahe an GPT-4.
Der leitende NVIDIA-Wissenschaftler Jim Fan stellte dies jedoch in Frage:
- Der Code macht nur 5 % der Falcon-180B-Trainingsdaten aus.
Und Code ist bei weitem die nützlichsten Daten, um die Denkfähigkeit zu verbessern, die Werkzeugnutzung zu beherrschen und KI-Agenten zu verbessern. Tatsächlich ist GPT-3.5 auf der Grundlage von Codex fein abgestimmt.
- Keine Kodierung von Benchmark-Daten.
Ohne Programmierfähigkeiten können Sie nicht behaupten, „besser als GPT-3.5“ oder „nahe an GPT-4“ zu sein. Es sollte ein integraler Bestandteil des Rezepts vor dem Training sein und keine spätere Anpassung sein.
- Für Sprachmodelle mit Parametern größer als 30B ist es an der Zeit, ein Hybrid-Expertensystem (MoE) einzuführen. Bisher haben wir nur OSS MoE LLM
Werfen wir einen Blick darauf: Was ist der Ursprung des Falcon 180B?

Das leistungsstärkste Open-Source-Großmodell der Welt
Zuvor hat Falcon drei Modellgrößen auf den Markt gebracht, nämlich 1.3B, 7.5B und 40B.
Offiziell ist Falcon 180B eine aktualisierte Version von 40B. Es wurde von TII, dem weltweit führenden Technologieforschungszentrum in Abu Dhabi, auf den Markt gebracht und steht zur kostenlosen kommerziellen Nutzung zur Verfügung.

Diesmal führten die Forscher technische Innovationen am Basismodell durch, wie beispielsweise die Verwendung von Multi-Query Attention, um die Skalierbarkeit des Modells zu verbessern.
Für den Trainingsprozess basiert Falcon 180B auf Amazon SageMaker, der Cloud-Plattform für maschinelles Lernen von Amazon, und hat das Training mit 3,5 Billionen Token auf bis zu 4096 GPUs abgeschlossen.
Gesamt-GPU-Berechnungszeit, ca. 7.000.000.
Die Parametergröße von Falcon 180B ist 2,5-mal so groß wie die von Llama 2 (70B), und der für das Training erforderliche Rechenaufwand ist 4-mal so groß wie die von Llama 2.
Unter den spezifischen Trainingsdaten ist Falcon 180B hauptsächlich der RefinedWe-Datensatz (der etwa 85 % ausmacht).
Darüber hinaus wird auf einer Mischung aus organisierten Daten wie Gesprächen, technischen Dokumenten und einem kleinen Teil Code trainiert.
Dieser Datensatz vor dem Training ist groß genug, selbst 3,5 Billionen Token belegen nur weniger als eine Epoche.
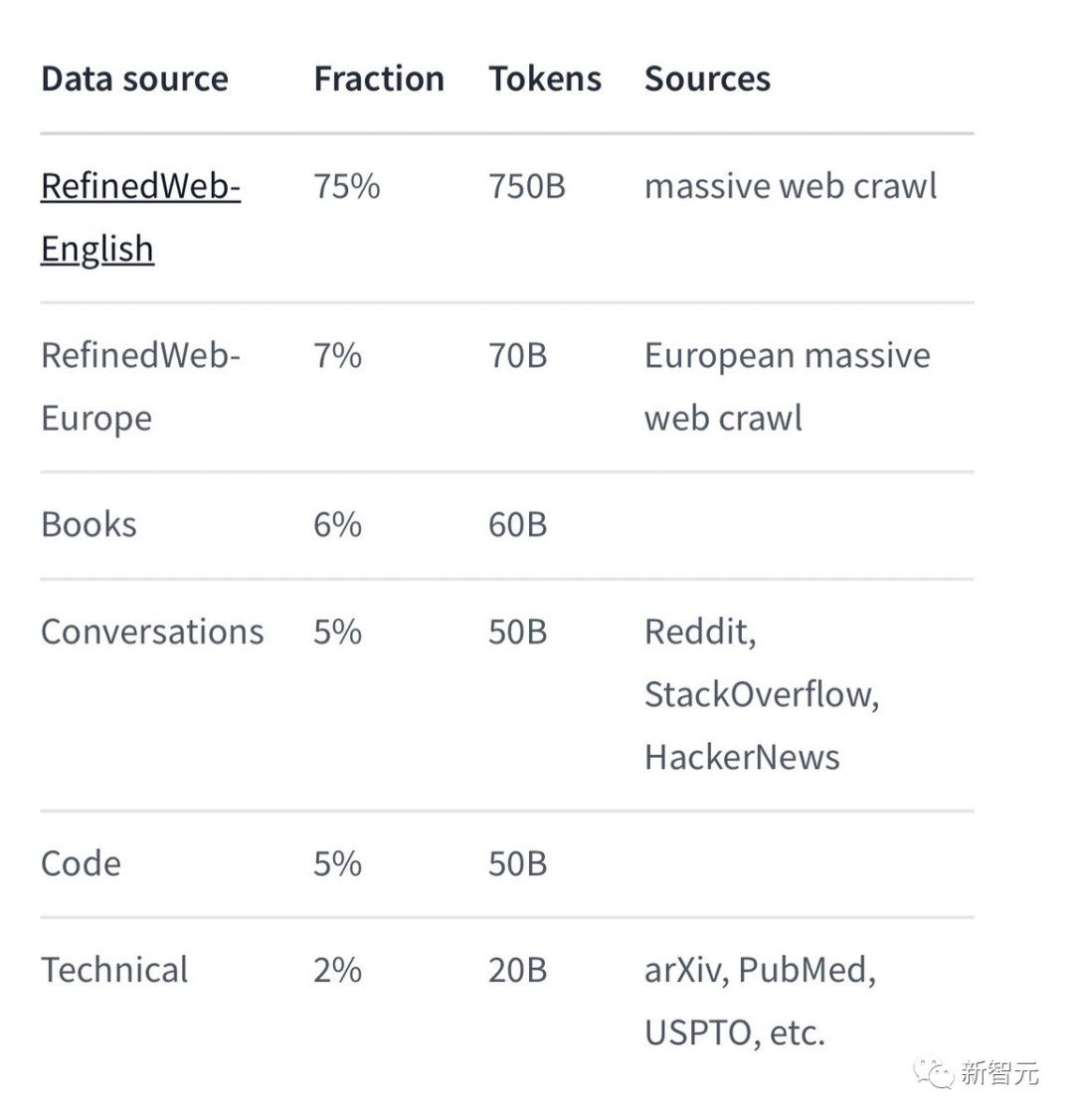
Der Beamte behauptet, dass Falcon 180B derzeit das „beste“ Open-Source-Großmodell ist. Die spezifische Leistung ist wie folgt:
Beim MMLU-Benchmark übertrifft die Leistung des Falcon 180B Llama 2 70B und GPT. 3.5.
Auf Augenhöhe mit Googles PaLM 2-Large bei HellaSwag, LAMBADA, WebQuestions, Winogrande, PIQA, ARC, BoolQ, CB, COPA, RTE, WiC, WSC und ReCoRD.
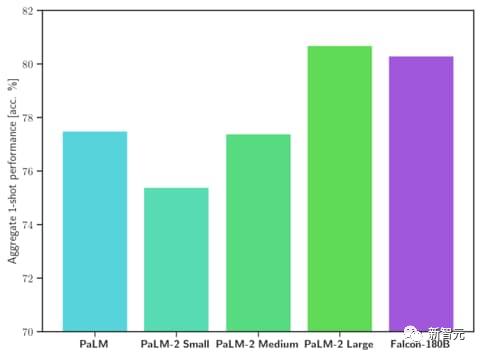
Darüber hinaus ist es derzeit das offene Großmodell mit der höchsten Punktzahl (68,74 Punkte) auf der Open-Source-Großmodellliste Hugging Face und übertrifft LlaMA 2 (67,35).
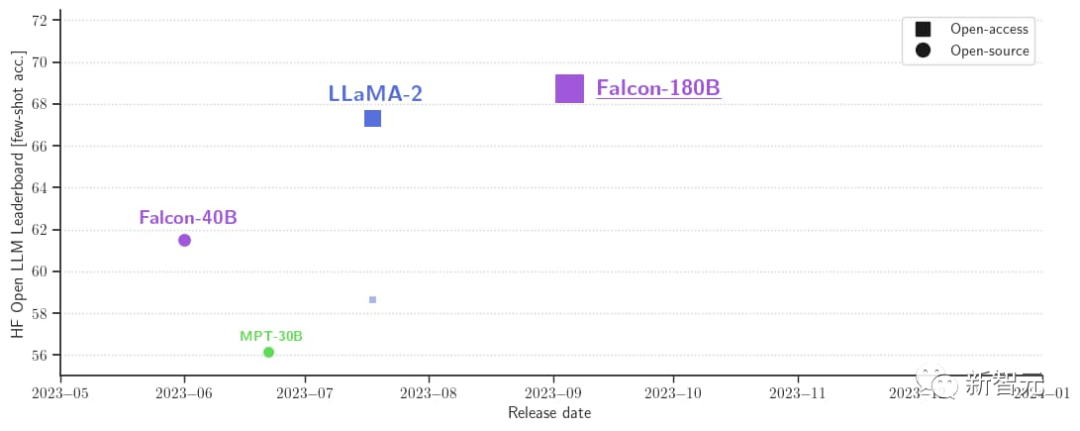
Falcon 180B ist jetzt verfügbar
Gleichzeitig veröffentlichten die Forscher auch das Chat-Konversationsmodell Falcon-180B-Chat. Das Modell ist auf Konversations- und Unterrichtsdatensätze abgestimmt, die Open-Platypus, UltraChat und Airoboros abdecken.

Jetzt kann jeder eine Demo-Erfahrung machen.
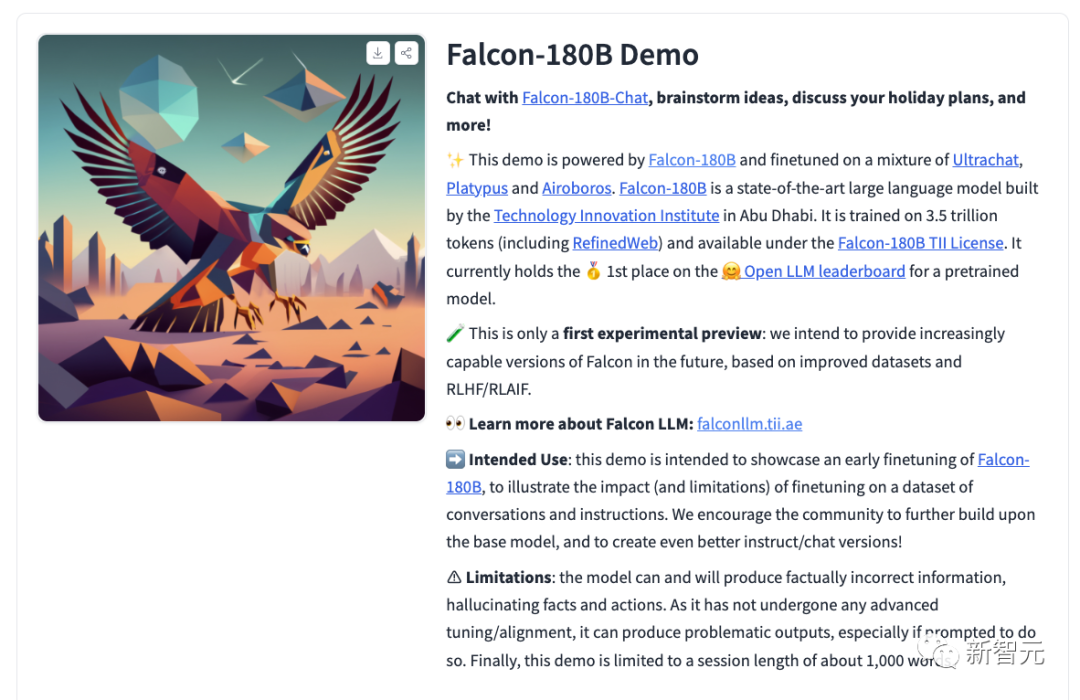
Adresse: https://huggingface.co/tiiuae/falcon-180B-chat
Prompt-Format
Das Basismodell verfügt nicht über ein Prompt-Format, da es sich nicht um eine große Konversation handelt Das Modell wird auch nicht durch Befehle trainiert und reagiert daher nicht im Dialog.
Vorgefertigte Modelle sind eine großartige Plattform für die Feinabstimmung, aber vielleicht sollten Sie sie nicht direkt verwenden. Das Dialogmodell verfügt über einen einfachen Dialogmodus.
System: Add an optional system prompt hereUser: This is the user inputFalcon: This is what the model generatesUser: This might be a second turn inputFalcon: and so on
Transformers
Ab Transformers 4.33 kann Falcon 180B im Hugging Face-Ökosystem verwendet und heruntergeladen werden.
Stellen Sie sicher, dass Sie in Ihrem Hugging Face-Konto angemeldet sind und die neueste Version von Transformers installiert haben:
pip install --upgrade transformershuggingface-cli login
bfloat16
Hier erfahren Sie, wie Sie das Basismodell in bfloat16 verwenden. Da es sich beim Falcon 180B um ein großes Modell handelt, beachten Sie bitte die Hardwareanforderungen.
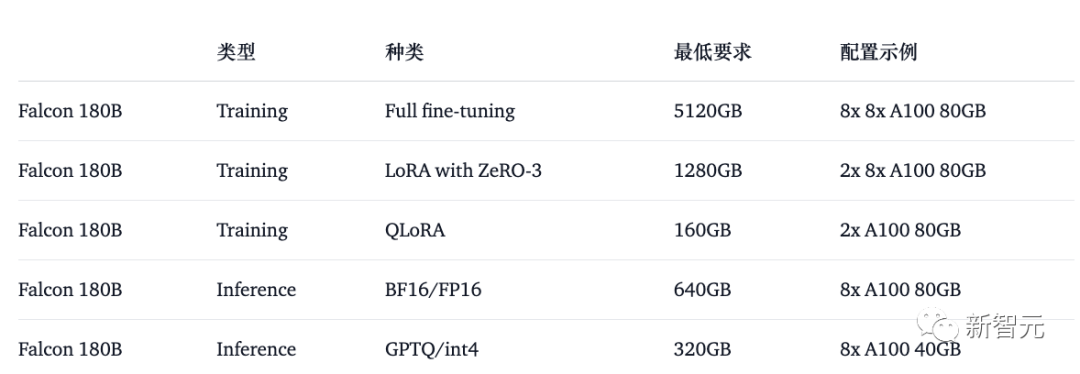
In dieser Hinsicht sind die Hardwareanforderungen wie folgt:
Es ist ersichtlich, dass Sie mindestens 8X8X A100 80G benötigen, wenn Sie die Falcon 180B vollständig optimieren möchten. Sie benötigen außerdem eine 8XA100 80G GPU.
from transformers import AutoTokenizer, AutoModelForCausalLMimport transformersimport torchmodel_id = "tiiuae/falcon-180B"tokenizer = AutoTokenizer.from_pretrained(model_id)model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,device_map="auto",)prompt = "My name is Pedro, I live in"inputs = tokenizer(prompt, return_tensors="pt").to("cuda")output = model.generate(input_ids=inputs["input_ids"],attention_mask=inputs["attention_mask"],do_sample=True,temperature=0.6,top_p=0.9,max_new_tokens=50,)output = output[0].to("cpu")print(tokenizer.decode(output)
kann die folgende Ausgabe erzeugen:
My name is Pedro, I live in Portugal and I am 25 years old. I am a graphic designer, but I am also passionate about photography and video.I love to travel and I am always looking for new adventures. I love to meet new people and explore new places.
unter Verwendung von 8-Bit- und 4-Bit-Bits und Bytes
Zusätzlich 8-Bit und 4-Bit. quantisierte Versionen des Falken 180B werden ausgewertet. Es gibt fast keinen Unterschied zu bfloat16!
Das sind gute Nachrichten für die Inferenz, da Benutzer quantisierte Versionen bedenkenlos verwenden können, um die Hardwareanforderungen zu reduzieren.
Beachten Sie, dass die Inferenz in der 8-Bit-Version viel schneller ist als in der 4-Bit-Version. Um die Quantisierung nutzen zu können, müssen Sie die „bitsandbytes“-Bibliothek installieren und beim Laden des Modells die entsprechenden Flags aktivieren:
model = AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.bfloat16,**load_in_8bit=True,**device_map="auto",)
Conversation Model
Wie oben erwähnt, wurde eine Version des Modells verfeinert Zur Dialogverfolgung wird eine sehr einfache Trainingsvorlage verwendet. Wir müssen dem gleichen Muster folgen, um Argumentationen im Chat-Stil durchzuführen.
Als Referenz können Sie sich die Funktion [format_prompt] in der Chat-Demo ansehen:
def format_prompt(message, history, system_prompt):prompt = ""if system_prompt:prompt += f"System: {system_prompt}\n"for user_prompt, bot_response in history:prompt += f"User: {user_prompt}\n"prompt += f"Falcon: {bot_response}\n"prompt += f"User: {message}\nFalcon:"return prompt
Wie Sie oben sehen können, werden Benutzerinteraktionen und Modellantworten durch die Trennzeichen User: und Falcon: vorangestellt. Wir verbinden sie zu einer Eingabeaufforderung, die den gesamten Gesprächsverlauf enthält. Auf diese Weise kann eine Systemaufforderung zur Anpassung des Build-Stils bereitgestellt werden.
Heiße Kommentare von Internetnutzern
Viele Internetnutzer diskutieren über die wahre Stärke von Falcon 180B.
Absolut unglaublich. Es schlägt GPT-3.5 und liegt auf Augenhöhe mit Googles PaLM-2 Large. Das ist ein Game Changer!

Ein CEO eines Startups sagte, ich habe den Konversationsroboter Falcon-180B getestet und er sei nicht besser als das Chatsystem Llama2-70B. Auch die HF OpenLLM-Rangliste zeigt gemischte Ergebnisse. Dies ist angesichts der größeren Größe und des größeren Trainingssatzes überraschend.
Zum Beispiel:
Geben Sie einige Gegenstände und lassen Sie Falcon-180B und Llama2-70B diese jeweils beantworten, um zu sehen, was der Effekt ist?
Falcon-180B zählt den Sattel fälschlicherweise als Tier. Llama2-70B antwortete prägnant und gab die richtige Antwort.


Das obige ist der detaillierte Inhalt vonMit 180 Milliarden Parametern wird das weltweit führende Open-Source-Großmodell Falcon offiziell angekündigt! Zerstöre LLaMA 2, die Leistung liegt nahe an GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!