
Heim >Technologie-Peripheriegeräte >KI >GPT-4: Trauen Sie sich, den von mir geschriebenen Code zu verwenden? Untersuchungen zeigen, dass die API-Missbrauchsrate bei über 62 % liegt
GPT-4: Trauen Sie sich, den von mir geschriebenen Code zu verwenden? Untersuchungen zeigen, dass die API-Missbrauchsrate bei über 62 % liegt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-13 09:13:01854Durchsuche
Eine neue Ära der Sprachmodellierung ist angebrochen. Große Sprachmodelle (LLM) können nicht nur natürliche Sprache verstehen, sondern sogar maßgeschneiderten Code entsprechend den Benutzeranforderungen generieren.
Daher entscheiden sich immer mehr Softwareentwickler dafür, große Sprachmodelle abzufragen, um Programmierfragen zu beantworten, z. B. die Verwendung von APIs zum Generieren von Codeausschnitten oder zum Erkennen von Fehlern im Code. Große Sprachmodelle können besser zugeschnittene Antworten auf Programmierfragen abrufen als die Suche in Online-Programmierforen wie Stack Overflow.
LLM ist schnell, aber dadurch verbergen sich auch potenzielle Risiken bei der Codegenerierung. Aus Sicht der Softwareentwicklung wurden die Robustheit und Zuverlässigkeit der Fähigkeit von LLM, Code zu generieren, nicht gründlich untersucht, obwohl viele Forschungsergebnisse veröffentlicht wurden (im Hinblick auf die Vermeidung syntaktischer Fehler und die Verbesserung des semantischen Verständnisses des generierten Codes).
Im Gegensatz zur Situation in Online-Programmierforen wird der von LLM generierte Code nicht von Community-Kollegen überprüft, sodass API-Missbrauchsprobleme auftreten können, wie z. B. fehlende Grenzprüfungen beim Lesen von Dateien und der Variablenindizierung, fehlendes Schließen von Datei-E/A, Transaktionsabschluss schlägt fehl usw. Selbst wenn das generierte Codebeispiel Funktionen ordnungsgemäß ausführen oder ausführen kann, kann ein Missbrauch zu schwerwiegenden potenziellen Risiken im Produkt führen, wie z. B. Speicherverlusten, Programmabstürzen, Fehlern bei der Speicherbereinigung usw.
Was noch schlimmer ist, ist, dass die Programmierer, die diese Fragen stellen, am anfälligsten sind, da sie mit größerer Wahrscheinlichkeit neu in der API sind und potenzielle Probleme in den generierten Codeschnipseln nicht erkennen können.
Die folgende Abbildung zeigt ein Beispiel eines Softwareentwicklers, der LLM nach Programmierfragen stellt. Es ist ersichtlich, dass Llama-2 Codefragmente mit korrekter Syntax, korrekten Funktionen und Syntaxausrichtung bereitstellen kann, es besteht jedoch ein Problem ist nicht robust und zuverlässig genug, weil Es berücksichtigt nicht die Tatsache, dass die Datei bereits existiert oder der Ordner nicht existiert.

Daher muss bei der Bewertung der Codegenerierungsfähigkeiten großer Sprachmodelle die Zuverlässigkeit des Codes berücksichtigt werden.
In Bezug auf die Bewertung der Codegenerierungsfähigkeiten großer Sprachmodelle konzentrieren sich die meisten vorhandenen Benchmarks auf die funktionale Korrektheit der Ausführungsergebnisse des generierten Codes. Das heißt, solange der generierte Code die funktionalen Anforderungen des Benutzers erfüllen kann, Der Benutzer akzeptiert es einfach.
Aber im Bereich der Softwareentwicklung reicht es nicht aus, dass der Code korrekt ausgeführt wird. Was Softwareentwickler brauchen, ist Code, der die neue API auf lange Sicht korrekt und zuverlässig nutzen kann, ohne potenzielle Risiken einzugehen.
Außerdem liegen die meisten aktuellen Programmierprobleme weit außerhalb der Softwareentwicklung. Die meisten seiner Datenquellen sind Online-Programmier-Challenge-Netzwerke wie Codeforces, Kattis, Leetcode usw. Obwohl die Leistung bemerkenswert ist, reicht sie nicht aus, um die Softwareentwicklung in praktischen Anwendungsszenarien zu unterstützen.
Zu diesem Zweck schlugen Li Zhong und Zilong Wang von der University of California, San Diego RobustAPI vor, ein Framework, das die Zuverlässigkeit und Robustheit von Code bewerten kann, der von großen Sprachmodellen generiert wird, das einen Datensatz von Programmierproblemen und eine enthält Abstrakter Grammatik-Evaluator für Bäume (AST).

Papieradresse: https://arxiv.org/pdf/2308.10335.pdf
Ziel des Datensatzes ist es, eine Bewertungsumgebung zu schaffen, die der realen Softwareentwicklung nahe kommt. Zu diesem Zweck sammelten die Forscher repräsentative Fragen zu Java von Stack Overflow. Java ist eine der beliebtesten Programmiersprachen und wird dank der WORA-Funktion (Write Once Run Anywhere) häufig für die Softwareentwicklung verwendet.
Für jede Frage stellten die Forscher eine detaillierte Beschreibung und eine zugehörige Java-API bereit. Sie haben außerdem eine Reihe von Vorlagen zum Aufrufen großer Sprachmodelle entworfen, um Codeausschnitte und entsprechende Erklärungen zu generieren.
Die Forscher stellen außerdem einen Evaluator bereit, der einen abstrakten Syntaxbaum (AST) verwendet, um die generierten Codeausschnitte zu analysieren und sie mit erwarteten API-Nutzungsmustern zu vergleichen.
Die Forscher formalisierten das KI-Nutzungsmuster auch in eine strukturierte Aufrufsequenz nach der Methode von Zhang et al. (2018). Diese strukturierte Abfolge von Aufrufen kann zeigen, wie diese APIs richtig eingesetzt werden können, um potenzielle Systemrisiken zu beseitigen. Aus softwaretechnischer Sicht gilt jeder Verstoß gegen diese strukturierte Aufrufsequenz als Fehler.
Forscher sammelten 1208 echte Fragen von Stack Overflow, an denen 24 repräsentative Java-APIs beteiligt waren. Die Forscher führten auch experimentelle Auswertungen durch, die nicht nur Closed-Source-Sprachmodelle (GPT-3.5 und GPT-4), sondern auch Open-Source-Sprachmodelle (Llama-2 und Vicuna-1.5) umfassten. Für die Hyperparametereinstellungen des Modells verwendeten sie die Standardeinstellungen und führten keine weiteren Hyperparameteranpassungen durch. Sie entwarfen außerdem zwei experimentelle Formen: Zero-Shot und One-Shot, die jeweils null bzw. ein Demonstrationsbeispiel in der Eingabeaufforderung bereitstellen.
Die Forscher analysierten den von LLM generierten Code umfassend und untersuchten häufige API-Missbräuche. Sie hoffen, dass dies Licht auf das wichtige Problem des API-Missbrauchs bei der Generierung von Code in LLM werfen wird und dass diese Forschung auch eine neue Dimension der Bewertung von LLM über die häufig verwendete funktionale Korrektheit hinaus bieten kann. Darüber hinaus werden der Datensatz und der Schätzer Open Source sein.
Die Beiträge dieses Papiers werden wie folgt zusammengefasst:
- Ein neuer Maßstab zur Bewertung der Zuverlässigkeit und Robustheit der LLM-Codegenerierung wird vorgeschlagen: RobustAPI.
- bietet ein umfassendes Bewertungsframework, das einen Datensatz mit Stack Overflow-Fragen und einen API-Nutzungsprüfer mithilfe von AST umfasst. Basierend auf diesem Rahmen analysierten die Forscher die Leistung häufig verwendeter LLMs, darunter GPT-3.5, GPT-4, Llama-2 und Vicuna-1.5.
- Umfassende Analyse der Leistung von LLM-generiertem Code. Sie fassen häufige API-Missbrauchsfälle für jedes Modell zusammen und zeigen Verbesserungsmöglichkeiten für zukünftige Forschung auf.
Methodenübersicht
RobustAPI ist ein Framework zur umfassenden Bewertung der Zuverlässigkeit und Robustheit von LLM-generiertem Code.
Der Datenerfassungsprozess und der Eingabeaufforderungsgenerierungsprozess beim Erstellen dieses Datensatzes werden im Folgenden beschrieben. Anschließend werden die in RobustAPI bewerteten API-Missbrauchsmuster angegeben und die möglichen Folgen des Missbrauchs werden abschließend erörtert Statische Analyse von Missbrauchsfällen mittels abstrakter Syntaxbäume.
Es wurde festgestellt, dass die neue Methode im Vergleich zu regelbasierten Methoden wie dem Keyword-Matching den API-Missbrauch von LLM-generiertem Code mit höherer Genauigkeit bewerten kann.
Datenerfassung
Um bestehende Forschungsergebnisse im Bereich Software Engineering zu nutzen, war der Ausgangspunkt für die Entwicklung von RobustAPI für die Forscher der Datensatz von BeispielCheck (Zhang et al. 2018). BeispielCheck ist ein Framework zur Untersuchung häufiger Java-API-Missbrauchsfälle in Web-Frage-und-Antwort-Foren.
Der Forscher wählte aus diesem Datensatz 23 gängige Java-APIs aus, wie in Tabelle 1 unten gezeigt. Diese 23 APIs decken 5 Bereiche ab, darunter String-Verarbeitung, Datenstrukturen, mobile Entwicklung, Verschlüsselung und Datenbankoperationen.

Prompt-Generierung
RobustAPI enthält auch eine Prompt-Vorlage, die mit Beispielen aus dem Datensatz gefüllt werden kann. Anschließend sammelten die Forscher die Antworten von LLM auf die Eingabeaufforderung und verwendeten einen API-Checker, um die Zuverlässigkeit ihres Codes zu bewerten.

In dieser Eingabeaufforderung werden zunächst die Aufgabeneinführung und das erforderliche Antwortformat angegeben. Wenn es sich bei dem durchgeführten Experiment dann um ein Experiment mit wenigen Stichproben handelt, wird auch eine Demonstration mit wenigen Stichproben durchgeführt. Hier ist ein Beispiel:
Demo-Beispiel
Demo-Beispiele helfen LLM nachweislich dabei, natürliche Sprache zu verstehen. Um die Codegenerierungsfähigkeit von LLM gründlich zu analysieren, entwarfen die Forscher zwei Einstellungen mit wenigen Schüssen: eine irrelevante Demonstration mit einer Stichprobe und eine abhängige Demonstration mit einer Stichprobe.
In einer agnostischen Demo-Einstellung mit einer einzigen Stichprobe verwenden die für LLM bereitgestellten Demo-Beispiele agnostische APIs. Die Forscher stellten die Hypothese auf, dass solche Demonstrationsbeispiele syntaktische Fehler im generierten Code beseitigen würden. Nicht verwandte Beispiele, die in RobustAPI verwendet werden, sind wie folgt:

In einer Einzelstichproben-Korrelations-Demo-Einstellung verwenden die für LLM bereitgestellten Demo-Beispiele dieselbe API wie die, die für das gegebene Problem verwendet wird. Dieses Beispiel enthält ein Frage-Antwort-Paar. Die Fragen in dieser Demo waren nicht im Testdatensatz enthalten und die Antworten wurden manuell korrigiert, um sicherzustellen, dass es keine API-Missbrauchsfälle gab und die Semantik der Antworten und Fragen gut aufeinander abgestimmt war.
Java-API-Missbrauch
Die Forscher haben 40 API-Regeln für 23 APIs in RobustAPI zusammengefasst, die in der Dokumentation dieser APIs überprüft wurden. Zu diesen Regeln gehören:
(1) Schutzbedingungen für APIs, die vor API-Aufrufen überprüft werden sollten. Beispielsweise sollte das Ergebnis von File.exists() vor File.createNewFile() überprüft werden.
(2) Die erforderliche API-Aufrufsequenz, d. h. die API sollte in einer bestimmten Reihenfolge aufgerufen werden. Beispielsweise sollte close() nach File.write() aufgerufen werden.
(3) API-Kontrollstruktur. Beispielsweise sollte SimpleDateFormat.parse() in einer Try-Catch-Struktur enthalten sein.
Ein Beispiel ist unten aufgeführt:

API-Missbrauch erkennen
Um die Richtigkeit der API-Nutzung im Code zu bewerten, kann RobustAPI API-Missbrauch gemäß API-Nutzungsregeln erkennen. Der Ansatz besteht darin, die Aufrufergebnisse und Kontrollstrukturen aus dem Codesegment zu extrahieren, wie in Abbildung 2 unten dargestellt.

Der Code-Checker überprüft zunächst das generierte Code-Snippet, um zu sehen, ob es sich um einen Codeabschnitt in einer Methode oder einer Methode aus einer Klasse handelt, damit er das Snippet kapseln und verwenden kann. Erstellen Sie einen abstrakten Syntaxbaum ( AST).
Der Inspektor geht dann durch den AST und zeichnet alle Methodenaufrufe und Kontrollstrukturen der Reihe nach auf, wodurch eine Folge von Aufrufen generiert wird.
Als nächstes vergleicht der Prüfer diese Aufruffolge mit den API-Nutzungsregeln. Es leitet den Instanztyp für jeden Methodenaufruf ab und verwendet diesen Typ und diese Methode als Schlüssel, um die entsprechenden API-Nutzungsregeln abzurufen.
Abschließend berechnet der Prüfer die längste gemeinsame Sequenz zwischen dieser Aufrufsequenz und den API-Nutzungsregeln.
Wenn die Aufrufsequenz nicht den erwarteten API-Nutzungsregeln entspricht, meldet der Prüfer einen API-Missbrauch.
Experimentelle Ergebnisse
Die Forscher bewerteten RobustAPI auf 4 LLMs: GPT-3.5, GPT-4, Llama-2 und Vicuna-1.5.
Zu den im Experiment verwendeten Bewertungsindikatoren gehören: API-Missbrauchsrate, Prozentsatz ausführbarer Proben und Gesamtprozentsatz des API-Missbrauchs.
Der Zweck des Experiments besteht darin, die folgenden Fragen zu beantworten:
- Frage 1: Wie hoch ist die API-Missbrauchsrate dieser LLMs bei der Lösung realer Programmierprobleme?
- Frage 2: Welchen Einfluss haben irrelevante Demoproben auf die Ergebnisse?
- Frage 3: Können korrekte API-Nutzungsbeispiele die API-Missbrauchsraten senken?
- Frage 4: Warum besteht der von LLM generierte Code die API-Nutzungsprüfung nicht?
Informationen zum spezifischen experimentellen Prozess finden Sie im Originalpapier. Hier sind 5 Erkenntnisse der Forscher:
Ergebnis 1: Das derzeit beste Sprachmodell im großen Maßstab weist im Allgemeinen API-Fehler in seinen realen Antworten auf -Weltweite Programmierprobleme. Verwenden Sie Fragen.

Ergebnis 2: Von allen LLM-Antworten, die ausführbaren Code enthalten, weisen 57–70 % der Codeschnipsel API-Missbrauchsprobleme auf, die schwerwiegende Folgen in der Produktion haben können.
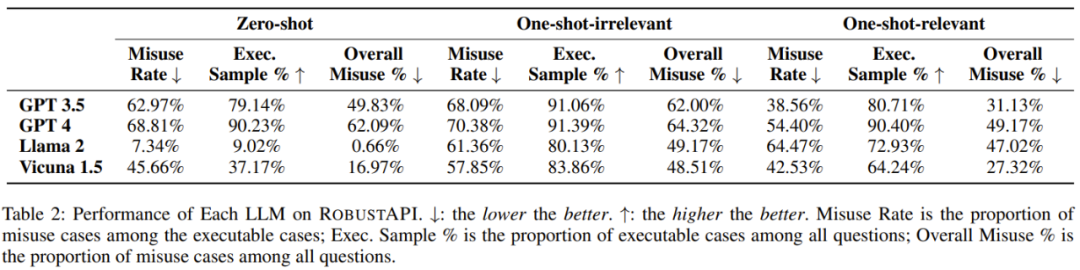
Ergebnis 3: Irrelevante Beispielbeispiele tragen nicht dazu bei, die API-Missbrauchsrate zu reduzieren, sondern lösen effektivere Antworten aus, die effektiv zum Benchmarking der Modellleistung verwendet werden können.
Ergebnis 4: Einige LLMs können Beispiele für die korrekte Verwendung lernen, was die API-Missbrauchsraten reduzieren kann.
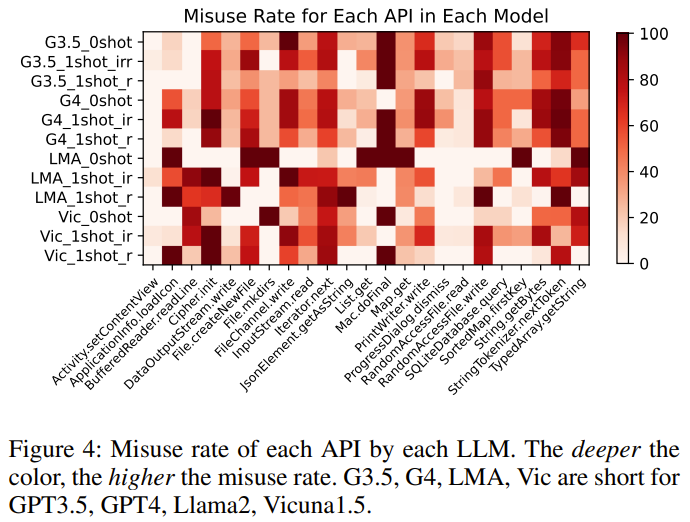
Ergebnis 5: GPT-4 hat die höchste Anzahl an Antworten, die ausführbaren Code enthalten. Für die Basis-API weisen verschiedene LLMs auch unterschiedliche Trends bei den Missbrauchsraten auf.
Darüber hinaus zeigte der Forscher in der Arbeit auch einen typischen Fall auf Basis von GPT-3.5 auf: Das Modell reagiert unter verschiedenen experimentellen Einstellungen unterschiedlich.
Die Aufgabe besteht darin, das Modell zu bitten, mithilfe der PrintWriter.write-API beim Schreiben einer Zeichenfolge in eine Datei zu helfen.

Die Antworten unterscheiden sich geringfügig in den agnostischen Demoeinstellungen für Null-Samples und One-Samples, aber beide weisen API-Missbrauchsprobleme auf – es werden keine Ausnahmen berücksichtigt. Nachdem dem Modell korrekte Beispiele für die API-Nutzung gegeben wurden, lernt das Modell, wie die API verwendet wird, und erstellt zuverlässigen Code.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGPT-4: Trauen Sie sich, den von mir geschriebenen Code zu verwenden? Untersuchungen zeigen, dass die API-Missbrauchsrate bei über 62 % liegt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So löschen Sie überflüssige Modelle in ZBrush
- Wir stellen eines der GIT-Codezweigverwaltungsmodelle vor
- Was ist das Datenmodell mit Baumstruktur?
- Bei der diesjährigen Aufnahmeprüfung für das Englische College nutzte die CMU ein Rekonstruktions-Vortraining, um eine hohe Punktzahl von 134 zu erreichen und damit GPT3 deutlich zu übertreffen
- US-Medien: Musk und andere fordern zu Recht eine Aussetzung des KI-Trainings und müssen aus Sicherheitsgründen langsamer fahren