
Heim >Technologie-Peripheriegeräte >KI >Ist die Feinabstimmung der „wissensbasierten Bildfrage und -antwort' sinnlos? Google veröffentlicht das Suchsystem AVIS: Nur wenige Stichproben übertreffen das überwachte PALI, und die Genauigkeit wird verdreifacht
Ist die Feinabstimmung der „wissensbasierten Bildfrage und -antwort' sinnlos? Google veröffentlicht das Suchsystem AVIS: Nur wenige Stichproben übertreffen das überwachte PALI, und die Genauigkeit wird verdreifacht

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-08-24 19:21:041464Durchsuche
Mit der Unterstützung großer Sprachmodelle (LLM) wurden bedeutende Ergebnisse bei multimodalen Aufgaben in Kombination mit Vision erzielt, wie z. B. Bildbeschreibung, visuelle Fragebeantwortung (VQA) und Objekterkennung mit offenem Vokabular
Allerdings nutzt das aktuelle visuelle Sprachmodell (VLM) grundsätzlich nur die visuellen Informationen im Bild, um die Aufgabe abzuschließen, und schneidet bei Datensätzen wie Informeek und OK-VQA, die externes Wissen zur Unterstützung der Fragenbeantwortung erfordern, oft schlecht ab.

Kürzlich hat Google eine neue autonome visuelle Informationssuchmethode AVIS veröffentlicht, die große Sprachmodelle (LLM) verwendet, um Strategien für die Verwendung externer Tools dynamisch zu formulieren, einschließlich des Aufrufs von APIs, der Analyse von Ausgabeergebnissen, der Entscheidungsfindung und anderen Bild-Fragen und Antworten vermitteln wichtiges Wissen.

Bitte klicken Sie auf den folgenden Link, um das Papier zu lesen: https://arxiv.org/pdf/2306.08129.pdf
AVIS integriert hauptsächlich drei Arten von Tools:
1 Bild-Tools zum Extrahieren visueller Informationen
2. Web-Suchtools zum Abrufen von Wissen und Fakten aus der offenen Welt
3. Bildsuchtools, mit denen visuell ähnliche Bilder abgerufen und dann verwendet werden können Sie basieren auf großen Schritten. Der Planer des Sprachmodells wählt bei jedem Schritt ein Tool und Abfrageergebnisse aus, um dynamisch Antworten auf Fragen zu generieren.
Simulation menschlicher Entscheidungsfindung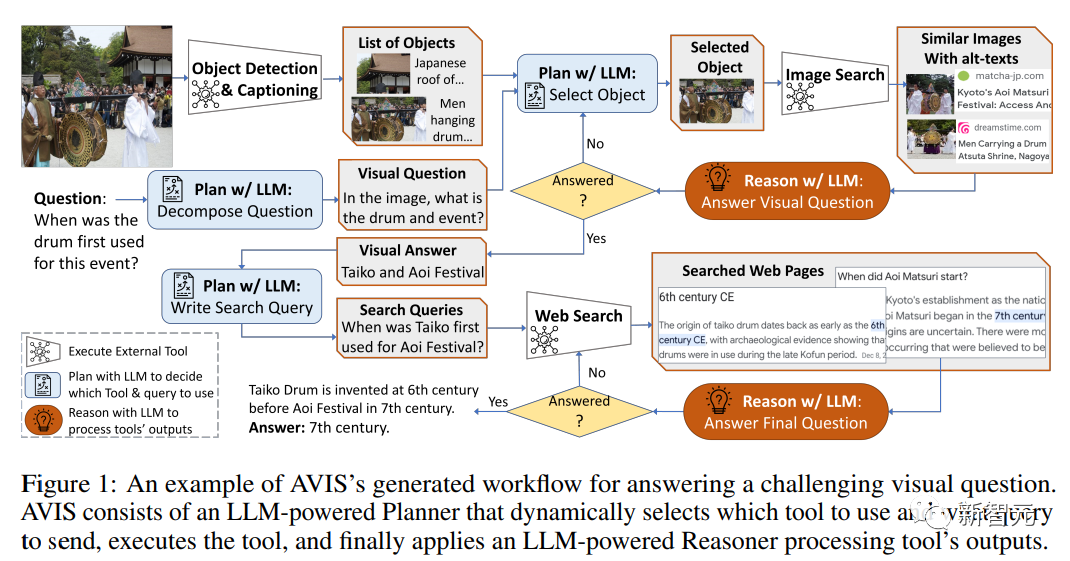
Viele visuelle Probleme in Infoseek- und OK-VQA-Datensätzen sind selbst für Menschen recht schwierig und erfordern normalerweise die Unterstützung verschiedener externer Tools. Daher entschieden sich die Forscher, zunächst eine Benutzerumfrage durchzuführen und Menschen zu beobachten Lösungen für komplexe Sehprobleme.
Zunächst stellen wir den Benutzern eine Reihe verfügbarer Tools zur Verfügung, darunter PALI, PALM und Websuche. Als nächstes zeigen wir das Eingabebild, die Frage, den erkannten Objektausschnitt, verknüpfte Wissensdiagrammentitäten aus den Bildsuchergebnissen, ähnliche Bildtitel, verwandte Produkttitel und Bildbeschreibungen
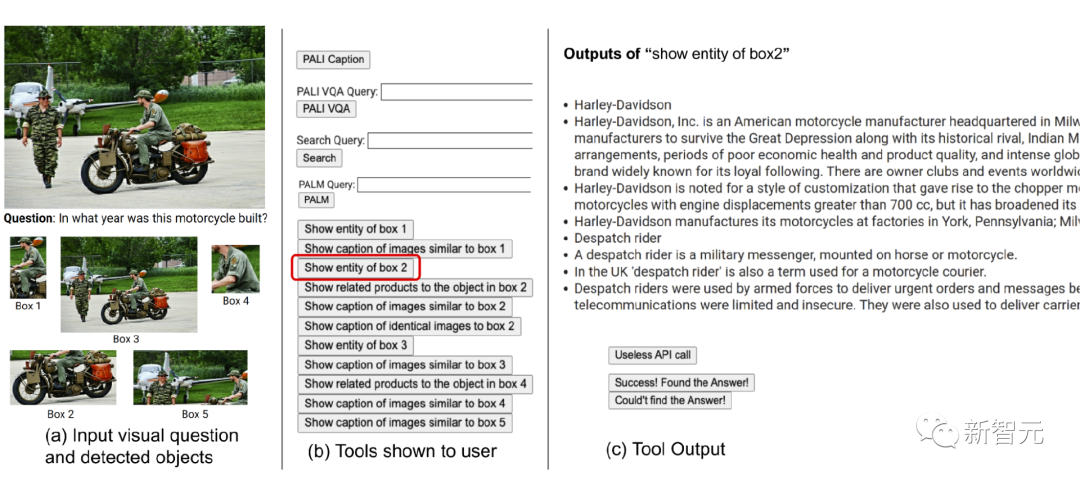 Als nächstes zeichnen die Forscher die Benutzeroperationen und -ausgaben auf. und verwendet zwei Methoden, um das System zur Antwort zu führen:
Als nächstes zeichnen die Forscher die Benutzeroperationen und -ausgaben auf. und verwendet zwei Methoden, um das System zur Antwort zu führen:
1 Erstellen Sie ein Übergangsdiagramm, indem Sie die Reihenfolge der vom Benutzer getroffenen Entscheidungen analysieren, die verschiedene Zustände und die Menge der verfügbaren Operationen in jedem Zustand enthält.
Umgeschriebener Inhalt: AVIS-Konvertierungsdiagramm Das neu gestaltete AVIS-Konvertierungsdiagramm ist eine grafische Darstellung zur Veranschaulichung des AVIS-Konvertierungsprozesses. Dieses Diagramm veranschaulicht die verschiedenen Phasen und Schritte von AVIS anschaulich und stellt sie dem Benutzer auf leicht verständliche Weise dar. Durch dieses Konvertierungsdiagramm können Benutzer das Funktionsprinzip und den Betriebsprozess von AVIS besser verstehen. Das Design dieses Diagramms ist prägnant und klar, sodass Benutzer den AVIS-Konvertierungsprozess schnell verstehen können. Sowohl Anfänger als auch erfahrene Benutzer können den Konvertierungsprozess mithilfe dieses AVIS-Konvertierungsdiagramms leicht verstehen und anwenden.
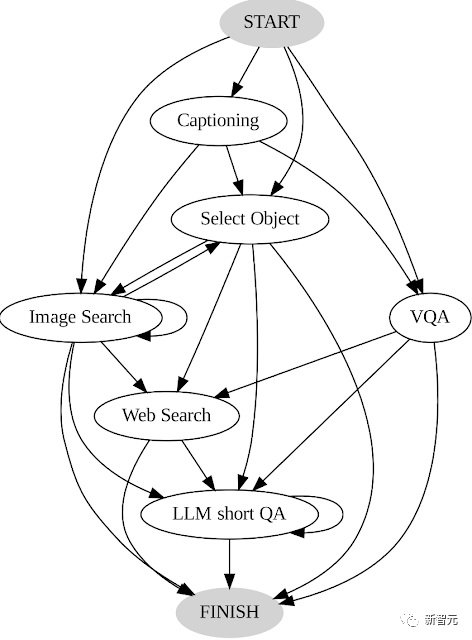 Im Startzustand kann das System beispielsweise nur drei Vorgänge ausführen: PALI-Beschreibung, PALI-VQA oder Zielerkennung.
Im Startzustand kann das System beispielsweise nur drei Vorgänge ausführen: PALI-Beschreibung, PALI-VQA oder Zielerkennung.
Um die Leistung und Effektivität des Systems zu verbessern, können Beispiele menschlicher Entscheidungsfindung verwendet werden, um den Planer und Denker bei der Interaktion mit relevanten Kontextinstanzen anzuleiten.
Gesamtrahmen
Der AVIS-Ansatz übernimmt eine dynamische Entscheidung -Entwicklung von Strategien zur Beantwortung von Anfragen nach visuellen Informationen
Das System besteht aus drei Hauptkomponenten:
Der Inhalt, der neu geschrieben werden muss, ist: 1. Planer (Planer), der zur Bestimmung nachfolgender Vorgänge verwendet wird, einschließlich geeigneter API-Aufrufe und Abfragen, die verarbeitet werden müssen
2. Arbeitsspeicher (Arbeitsspeicher), Erhaltene Ergebnisinformationen aus der API-Ausführung.
3. Der Reasoner wird zur Verarbeitung der Ausgabe des API-Aufrufs verwendet und kann bestimmen, ob die erhaltenen Informationen ausreichen, um die endgültige Antwort zu generieren, oder ob ein zusätzlicher Datenabruf erforderlich ist.
Sie müssen entscheiden, welches Tool verwendet wird jedes Mal zu verwenden Neben den an das System gesendeten Abfragen führt der Planer eine Reihe von Vorgängen basierend auf dem aktuellen Status durch. Der Planer stellt auch mögliche Folgemaßnahmen bereit
Um das Problem zu lösen dass der Suchraum aufgrund zu vieler potenzieller Aktionsräume zu groß ist. Das Problem besteht darin, dass der Planer auf das Übergangsdiagramm zurückgreifen muss, um irrelevante Aktionen zu eliminieren, mit Ausnahme von Aktionen, die zuvor ausgeführt und im Arbeitsspeicher gespeichert wurden.
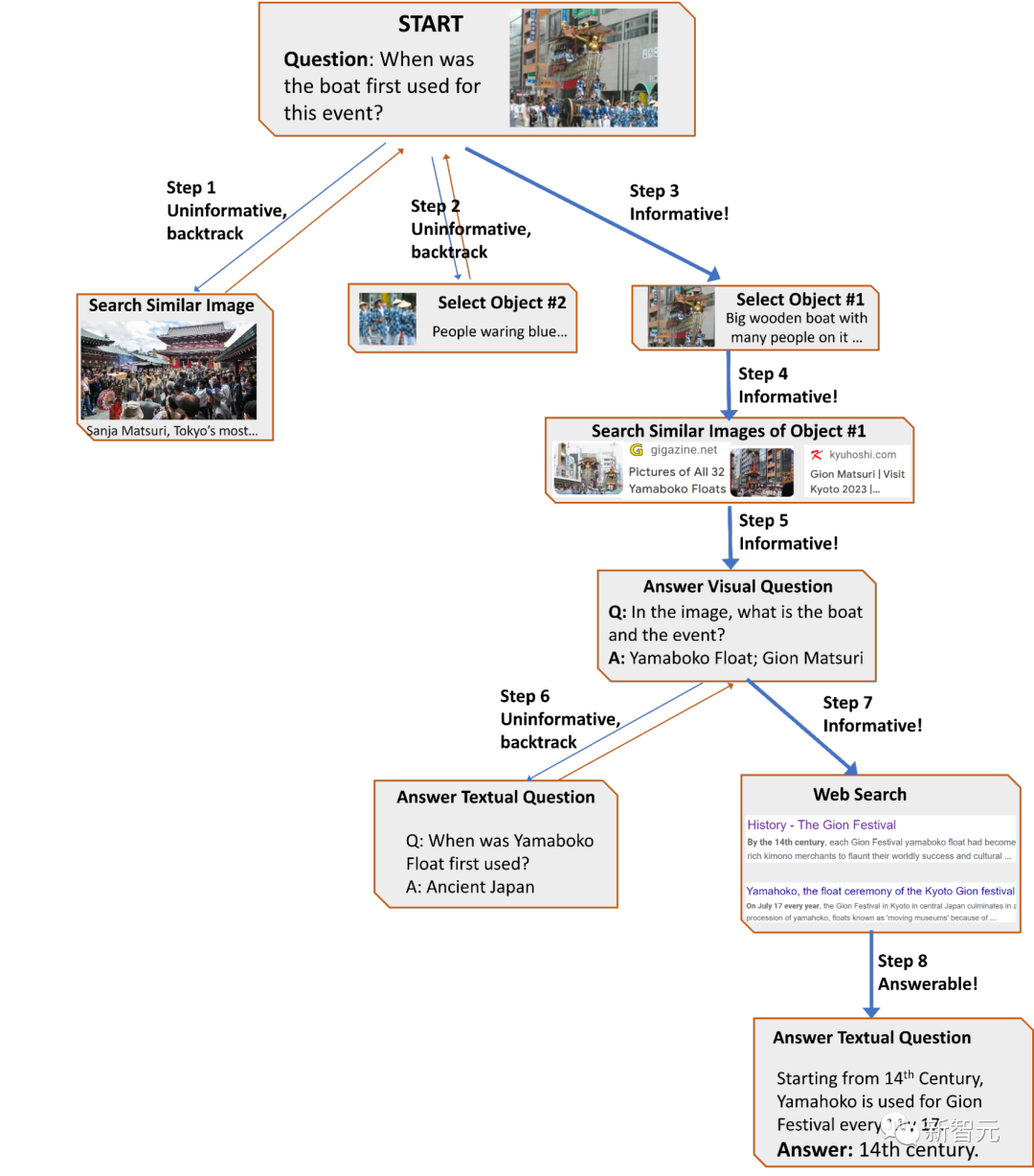
Dann stellt der Planer eine Reihe von Kontextbeispielen aus den Benutzerforschungsdaten zusammen, kombiniert mit den Aufzeichnungen früherer Tool-Interaktionen, der Planer formuliert Eingabeaufforderungen und gibt sie in das Sprachmodell ein, und das LLM gibt eine strukturierte Antwort zurück , bestimmt das nächste zu aktivierende Tool und die abzusendende Abfrage.
Der gesamte Designprozess kann durch mehrere Aufrufe an den Planer gesteuert werden, um dynamische Entscheidungen voranzutreiben und Schritt für Schritt Antworten zu generieren.

Forscher verwenden Reasoner, um die Ausgabe der Werkzeugausführung zu analysieren, nützliche Informationen zu extrahieren und entscheiden Kategorie der Tool-Ausgabe: informativ, nicht informativ oder endgültige Antwort
Wenn der Reasoner ein Ergebnis von „Antwort bereitstellen“ zurückgibt, wird es direkt als Endergebnis ausgegeben und die Aufgabe beendet, wenn das Ergebnis keine Informationen enthält. Es kehrt zur Planung zurück und wählt eine andere Aktion basierend auf dem aktuellen Status aus. Wenn der Denker die Ausgabe des Tools für nützlich hält, ändert es den Status und überträgt die Kontrolle zurück an den Planer, um im neuen Status eine neue Entscheidung zu treffen.
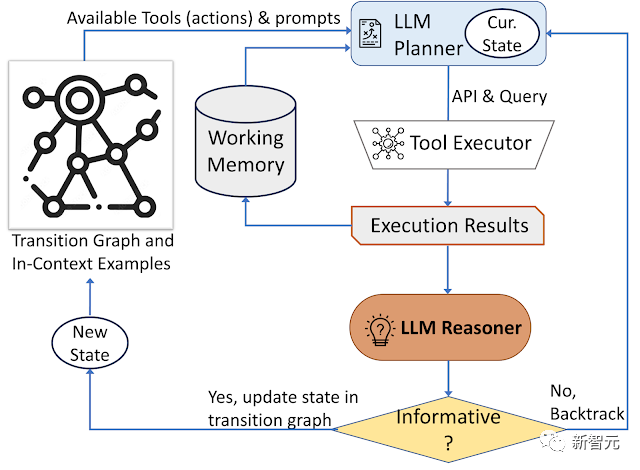
AVIS verwendet eine dynamische Entscheidungsstrategie, um auf Suchanfragen mit visuellen Informationen zu reagieren.
Experimentelle Ergebnisse Das Bildbeschreibungsmodell kann Beschreibungen für Eingabebilder und zugeschnittene Bilder von erkannten Objekten generieren.
Objekterkennung mithilfe eines Objektdetektors, der auf einer Obermenge des Open Images-Datensatzes trainiert wurde und von der kategoriespezifischen Google Lens-API unter Verwendung eines hohen Konfidenzschwellenwerts bereitgestellt wird, wobei nur die Erkennungsfelder mit dem höchsten Rang im Eingabebild beibehalten werden.
Verwenden Sie die Google-Bildsuche, um Informationen zum Bildzuschnitt in Bezug auf erkannte Boxen zu erhalten.
Bei der Entscheidungsfindung behandelt der Planer die Verwendung jeder Information als separaten Vorgang, da jede Information Hunderte von Token enthalten kann, die erforderlich sind komplexe Verarbeitung und Argumentation.
In einigen Fällen können Bilder Textinhalte wie Straßennamen oder Markennamen enthalten. Sie können die Funktion zur optischen Zeichenerkennung (OCR) in der Google Lens-API verwenden, um diese Texte zu extrahieren.
Mithilfe der Google-Such-API für Websuchen können Sie eine Textabfrage eingeben und die Ausgabe relevanter Dokumentlinks und -ausschnitte erhalten Gleichzeitig kann ein Knowledge-Graph-Panel mit direkten Antworten und bis zu fünf Fragen im Zusammenhang mit der Eingabeabfrage bereitgestellt werden. Experimentelle Ergebnisse. Die Forscher führten Experimente mit dem AVIS-Framework zur Auswertung von Infoseek- und OK-VQA-Datensätzen durch Aus den Ergebnissen geht hervor, dass selbst sehr robuste visuelle Sprachmodelle wie OFA- und PALI-Modelle nach einer Feinabstimmung des Infoseek-Datensatzes keine hohe Genauigkeit erreichen können. Ohne Feinabstimmung erreichte die AVIS-Methode erfolgreich eine Genauigkeit von 50,7 % das fein abgestimmte PALI-Modell.
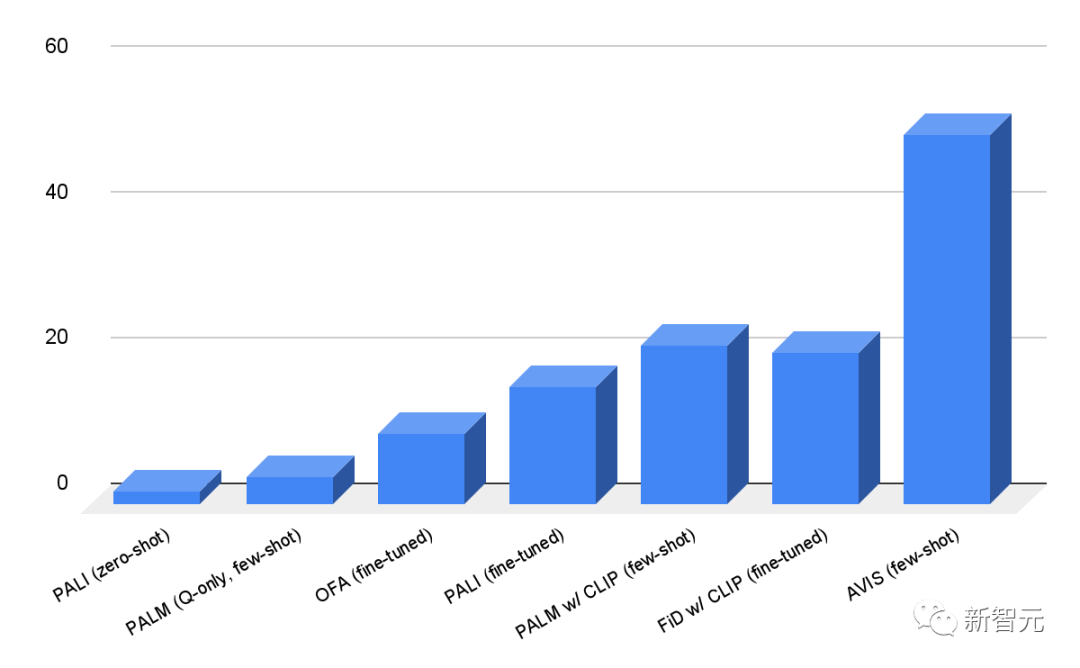
Die meisten Frage- und Antwortbeispiele in OK-VQA basieren eher auf gesundem Menschenverstand als auf detailliertem Wissen, sodass der Leistungsunterschied möglicherweise darauf zurückzuführen ist. PALI ist in der Lage, das in den Modellparametern kodierte allgemeine Wissen zu nutzen, ohne auf die Unterstützung von externem Wissen angewiesen zu sein. Ein Schlüsselmerkmal von AVIS ist die Fähigkeit, Entscheidungen dynamisch zu treffen, anstatt eine feste Reihenfolge auszuführen Beispiel Das Beispiel zeigt die Flexibilität von AVIS bei der Verwendung verschiedener Tools in verschiedenen Phasen.
Es ist erwähnenswert, dass das Reasoner-Design in diesem Artikel es AVIS ermöglicht, irrelevante Informationen zu identifizieren, zum vorherigen Status zurückzukehren und die Suche zu wiederholen.

Im zweiten Beispiel zur Pilztaxonomie traf AVIS beispielsweise zunächst die falsche Entscheidung, indem es das Blattobjekt auswählte, da es für das Problem irrelevant war, AVIS zu einer Neuplanung veranlasste und das Objekt dann erfolgreich auswählte Das hing mit dem Problem zusammen. Falsche Objekte im Zusammenhang mit Truthahnschwanzpilzen, wodurch die richtige Antwort gefunden wurde: Stereum Werkzeuge Intensive Sehprobleme.
Bei diesem Ansatz entscheiden sich die Forscher dafür, aus Benutzerstudien gesammelte menschliche Entscheidungsdaten als Anker zu verwenden, einen strukturierten Rahmen zu übernehmen und einen LLM-basierten Planer zu verwenden, um dynamisch über die Werkzeugauswahl und die Abfragebildung zu entscheiden. 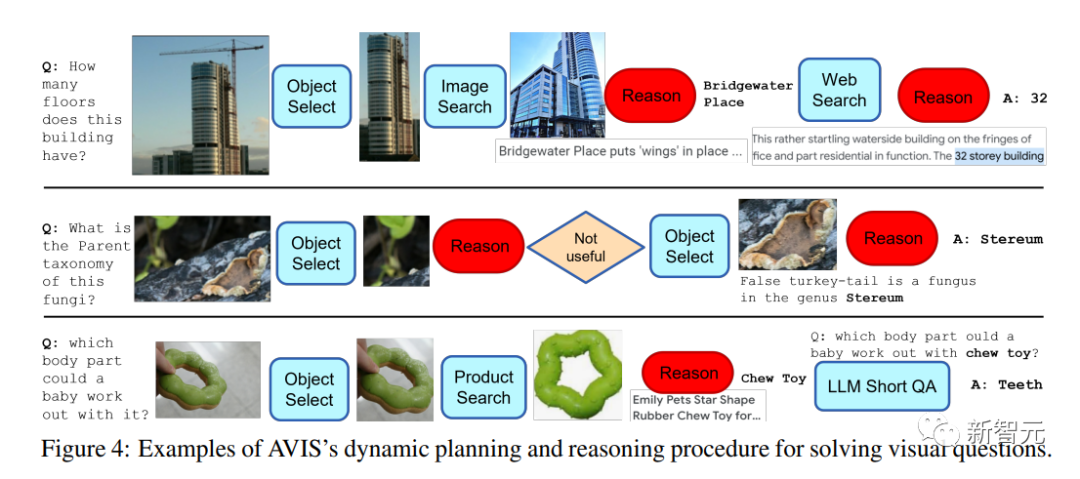
The Der LLM-gesteuerte Reasoner kann wichtige Informationen aus der Ausgabe des ausgewählten Tools verarbeiten und extrahieren, indem er den Planer und den Reasoner iterativ verwendet, um verschiedene Tools auszuwählen, bis alle notwendigen Informationen zur Beantwortung der visuellen Frage gesammelt sind
Das obige ist der detaillierte Inhalt vonIst die Feinabstimmung der „wissensbasierten Bildfrage und -antwort' sinnlos? Google veröffentlicht das Suchsystem AVIS: Nur wenige Stichproben übertreffen das überwachte PALI, und die Genauigkeit wird verdreifacht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Schichten des TCP/IP-Referenzmodells?
- Was sind die gängigen Softwareentwicklungsmodelle?
- IBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren
- Von BERT bis ChatGPT, ein umfassender Überblick über neun Top-Forschungseinrichtungen, darunter die Beihang-Universität: das „Grundmodell vor der Ausbildung', das wir im Laufe der Jahre gemeinsam verfolgt haben
- ChatGPT-Modelle können direkt trainiert werden! East China Normal University und NUS Open-Source-HugNLP-Framework: Aktualisieren Sie die Rangliste mit einem Klick und vereinheitlichen Sie das NLP-Training vollständig