
Heim >Java >JavaInterview Fragen >Interviewer: Wie implementiert MySQL ACID?
Interviewer: Wie implementiert MySQL ACID?
- Java后端技术全栈nach vorne
- 2023-08-17 14:39:00784Durchsuche
Im Interview muss der Interviewer nur nach der ACID von MySQL fragen und kann dann sofort den achtteiligen Aufsatz rezitieren (manche Leute können ihn möglicherweise noch nicht beantworten). Was noch ekelhafter ist, ist, dass einige Interviewer sich nicht an die Routine halten und weiterhin fragen: Wie implementiert MySQL ACID?
Sie sind verwirrt. Um ehrlich zu sein, kann diese Frage 95 % der Menschen abschrecken.
Heute geht es in diesem Artikel hauptsächlich um das Implementierungsprinzip von ACID unter der MySQL InnoDB -Engine. Es geht nicht zu sehr auf Grundkenntnisse ein, z. B. was eine Transaktion ist und was die Isolationsstufe bedeutet.
ACID
Wie garantiert MySQL als relationale Datenbank ACID basierend auf der gängigsten InnoDB-Engine?
(Atomizität)Atomizität: Transaktion ist die kleinste Ausführungseinheit und erlaubt keine Teilung. Atomarität stellt sicher, dass Aktionen entweder vollständig abgeschlossen sind oder überhaupt keine Wirkung haben; (Konsistenz) Konsistenz: Daten bleiben vor und nach der Ausführung einer Transaktion konsistent; Datenbank gleichzeitig, eine Transaktion wird nicht durch andere Transaktionen beeinträchtigt. (Haltbarkeit) Haltbarkeit: Nach Abschluss einer Transaktion. Änderungen an Daten in der Datenbank bleiben bestehen, auch wenn die Datenbank ausfällt.
Isolation
Lassen Sie uns zunächst über Isolation sprechen. Das erste sind die vier Isolationsstufen.
Isolationsstufe Nach dem Absenden werden die vorgenommenen Änderungen von anderen Transaktionen gesehen| Wiederholbares Lesen | Bei einer Transaktion ist das Ergebnis des Lesens derselben Daten immer dasselbe, unabhängig davon, ob andere Transaktionen mit den Daten arbeiten und ob die Transaktion festgeschrieben ist. InnoDB-Standardebene. |
| Serialisierung | Transaktionen werden seriell ausgeführt. Lese- und Schreibvorgänge blockieren sich gegenseitig, wodurch die Parallelität des Systems beeinträchtigt wird. |
Unterschiedliche Isolationsstufen sollen unterschiedliche Probleme lösen. Das heißt, Dirty Reads, Phantom Reads und nicht wiederholbare Reads.
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 🏜
|---|---|---|---|
| Erscheinen nicht erlaubt | Kann erscheinen | ||
| Serialisierung | nicht erlaubt | nicht erlaubt | nicht erlaubt |
Also unterschiedliche Isolationsstufen, wie wird Isolation erreicht und warum können sich verschiedene Dinge nicht gegenseitig stören? Die Antwort ist Locks und MVCC.
Sperren
Lass uns zunächst über Sperren sprechen. Wie viele Sperren hat MySQL?
Granularität
In Bezug auf die Granularität bedeutet dies Tabellensperren, Seitensperren und Zeilensperren. Zu den Tabellensperren gehören absichtliche gemeinsame Sperren, absichtliche exklusive Sperren, selbsterhöhende Sperren usw. Zeilensperren werden von jeder Engine auf Engine-Ebene implementiert. Aber nicht alle Engines unterstützen Zeilensperren. Beispielsweise unterstützt die MyISAM-Engine keine Zeilensperren.
Arten von Zeilensperren
In InnoDB-Transaktionen werden Zeilensperren durch Sperren von Indexeinträgen im Index implementiert. Dies bedeutet, dass InnoDB Sperren auf Zeilenebene nur verwendet, wenn Daten über Indexbedingungen abgerufen werden, andernfalls werden Tabellensperren verwendet. Sperren auf Zeilenebene werden ebenfalls in zwei Typen unterteilt: gemeinsame Sperren und exklusive Sperren sowie beabsichtigte gemeinsame Sperren und beabsichtigte exklusive Sperren, die vor dem Sperren erworben werden müssen.
Gemeinsame Sperre: Lesesperre, andere Transaktionen dürfen eine S-Sperre hinzufügen, andere Transaktionen dürfen keine X-Sperre hinzufügen, dh andere Transaktionen können nur lesen, aber nicht schreiben. select...im Freigabemodus sperrenSperren.select...lock in share mode加锁。排它锁:写锁,不允许其他事务再加S锁或者X锁。 insert、update、delete、for update
insert, update, delete, for updateLock. Die Zeilensperre wird hinzugefügt
, wenn sie benötigt wird. Sie wird jedoch nicht sofort freigegeben, wenn sie nicht mehr benötigt wird, sondern erst am Ende der Transaktion. Dies ist das Zwei-Phasen-Sperrprotokoll. 🎜🎜Zeilensperr-Implementierungsalgorithmus
Datensatzsperre
Eine Sperre für einen einzelnen Zeilendatensatz sperrt immer den Indexdatensatz.
Lückensperre
Lückensperre, denken Sie über den Grund für das Phantomlesen nach. Tatsächlich können Zeilensperren nur Zeilen sperren, aber beim Einfügen neuer Datensätze muss die „Lücke“ zwischen Datensätzen aktualisiert werden. Fügen Sie also eine Lückensperre hinzu, um das Phantomlesen zu lösen.
Next-Key Lock
Gap Lock + Record Lock, offen und geschlossen gelassen.
Die Isolierung von Schlössern
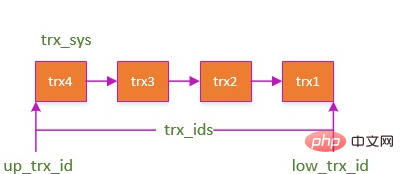
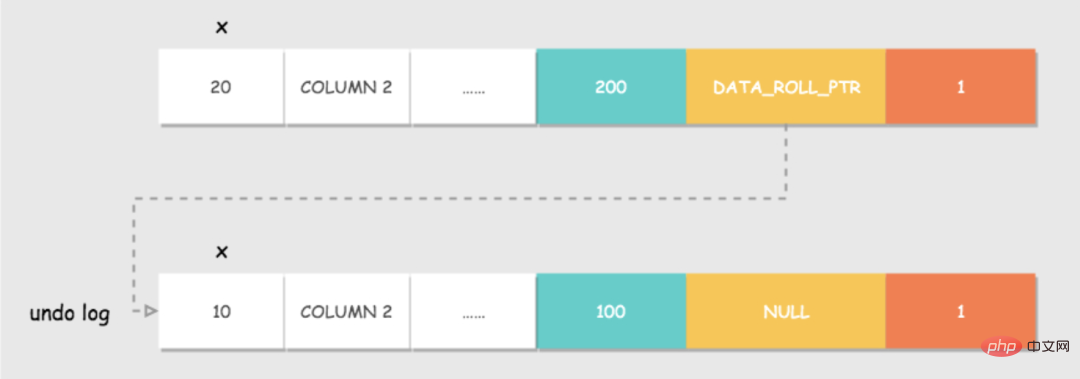
Eine allgemeine Einführung in das untere Schloss, Sie können es sehen. Wenn eine Transaktion Daten schreibt, können andere Transaktionen bei Sperren die Schreibsperre nicht erhalten und keine Daten schreiben. Dadurch wird die Isolation zwischen Transaktionen bis zu einem gewissen Grad sichergestellt. Aber wie bereits erwähnt, warum können andere Transaktionen nicht auch Daten lesen, wenn eine Schreibsperre hinzugefügt wird? Wie bereits erwähnt, kann die aktuelle Transaktion mit der Sperre die Daten nicht ohne Schreibsperre ändern, sie können jedoch weiterhin gelesen werden. Und beim Lesen, auch wenn die Datenzeile von anderen Transaktionen geändert und übermittelt wurde. Derselbe Zeilenwert kann immer noch wiederholt gelesen werden. Dies ist MVCC, Multi-Version-Parallelitätskontrolle, Multi-Version-Parallelitätskontrolle. Das Speicherformat von Zeilendatensätzen in Innodb verfügt über einige zusätzliche Felder: DATA_TRX_ID und DATA_ROLL_PTR. Protokoll rückgängig machen: Zeichnen Sie das Protokoll auf, bevor die Daten geändert werden. Dies wird später ausführlich erläutert. wird am Anfang jeder SQL erstellt und verfügt über mehrere wichtige Attribute: Jetzt starten Sie die Abfrage, ein Select kommt vorbei und eine Datenzeile wird gefunden. DATA_TRX_ID 546ae49bc9a06f6b7aafd76c596ed812= low_limit_id: Gibt an, dass die Daten generiert werden, nachdem die aktuelle Leseansicht erstellt wurde, und die Daten nicht angezeigt werden. up_limit_id Mit Sperren und MVCC wird die Transaktionsisolation gelöst. Lassen Sie mich hier näher darauf eingehen. Löst die Standard-RR-Stufe das Phantomlesen? Phantomlesung zielt normalerweise auf INSERT und Nichtwiederholbarkeit auf UPDATE ab. Wir haben erwartet, dass es Lassen Sie uns über Atomizität sprechen. Wie bereits erwähnt, führt das Rückgängigmachen des Protokolls zu einem Rollback des Protokolls. Um die Isolation zu erreichen, ist MVCC tatsächlich darauf angewiesen, ebenso wie die Atomizität. Der Schlüssel zum Erreichen der Atomizität besteht darin, alle erfolgreich ausgeführten SQL-Anweisungen rückgängig machen zu können, wenn die Transaktion zurückgesetzt wird. Wenn eine Transaktion die Datenbank ändert, generiert InnoDB das entsprechende Rückgängig-Protokoll. Wenn die Transaktionsausführung fehlschlägt oder ein Rollback aufgerufen wird, wodurch die Transaktion zurückgesetzt wird, können die Informationen im Rückgängig-Protokoll zum Zurücksetzen der Daten verwendet werden so wie es vor dem Umbau war. Das Rückgängig-Protokoll ist ein logisches Protokoll, das Informationen zur SQL-Ausführung aufzeichnet. Wenn ein Rollback auftritt, führt InnoDB basierend auf dem Inhalt des Rückgängig-Protokolls das Gegenteil der vorherigen Arbeit aus: Nehmen Sie den Aktualisierungsvorgang als Beispiel: Wenn eine Transaktion eine Aktualisierung ausführt, enthält das generierte Rückgängig-Protokoll den Primärschlüssel der geänderten Zeile (um zu wissen, welche Zeilen geändert wurden), welche Spalten geändert wurden. und die Werte dieser Spalten vor und nach der Änderung. Beim Rollback können Sie diese Informationen verwenden, um die Daten in den Zustand vor der Aktualisierung zurückzusetzen. Innnodb verfügt über viele Protokolle und die Persistenz basiert auf dem Redo-Protokoll. Persistenz hängt definitiv mit dem Schreiben zusammen. Der vollständige Name von WAL lautet Write-Ahead Logging die Festplatte. Genau wie bei Geschäften in einem kleinen Laden gibt es eine rosa Tafel und ein Geschäftsbuch. Wenn Gäste kommen, schreiben Sie zuerst auf die rosa Tafel und notieren Sie sich dann das Geschäftsbuch, wenn Sie nicht beschäftigt sind. Redo-Log ist dieses Pinkboard. Wenn ein Datensatz aktualisiert werden muss, schreibt die InnoDB-Engine den Datensatz zuerst in das Redo-Log (und aktualisiert den Speicher). Zu diesem Zeitpunkt ist die Aktualisierung abgeschlossen. Zu gegebener Zeit wird dieser Vorgangsdatensatz auf der Festplatte aktualisiert. Diese Aktualisierung erfolgt häufig, wenn das System relativ inaktiv ist, genau wie es der Ladenbesitzer nach dem Schließen tut. Redo-Log hat zwei Funktionen: Für Redo-Log gibt es zwei Phasen: Commit und Prepare. Wenn Sie nicht „Zwei-Phasen-Commit“ verwenden, den Status der Datenbank Möglicherweise unterscheidet sich der Status der aus dem Protokoll wiederhergestellten Bibliothek. Schauen wir uns zunächst den anderen Status an. InnoDB stellt auch Cache bereit. Der Pufferpool enthält die Zuordnung einiger Datenseiten auf der Festplatte, die als Puffer für den Zugriff auf die Datenbank dient: Die Verwendung des Pufferpools verbessert die Effizienz beim Lesen und Schreiben von Daten erheblich, bringt jedoch auch neue Probleme mit sich: Wenn MySQL ausfällt und die geänderten Daten im Pufferpool nicht auf die Festplatte geleert wurden, führt dies zu Datenverlust Bei Verlust ist die Dauerhaftigkeit der Transaktion nicht gewährleistet. Also bin ich dem Redo-Log beigetreten. Wenn die Daten geändert werden, wird der Vorgang zusätzlich zur Änderung der Daten im Pufferpool auch im Redo-Protokoll aufgezeichnet. Wenn die Transaktion übermittelt wird, wird die fsync-Schnittstelle aufgerufen, um das Redo-Protokoll zu leeren. Wenn MySQL ausfällt, können Sie die Daten im Redo-Log auslesen und die Datenbank beim Neustart wiederherstellen. Redo-Protokoll verwendet WAL (Write-Ahead-Protokollierung, Write-Ahead-Protokoll) Alle Änderungen werden zuerst in das Protokoll geschrieben und dann im Pufferpool aktualisiert, um sicherzustellen, dass die Daten nicht aufgrund von MySQL-Ausfallzeiten verloren gehen und somit die Haltbarkeit gewährleistet ist Erfordern. Und das hat zwei Vorteile: Apropos, Sie fragen sich vielleicht, dass es auch ein Bin-Protokoll gibt, das auch für Schreibvorgänge und zur Datenwiederherstellung verwendet wird. Was ist der Unterschied? für Anweisungen Warum zuerst das Redo-Log schreiben? Konsistenz ist das ultimative Ziel von Transaktionen. Die in der vorherigen Frage erwähnte Atomizität, Persistenz und Isolation dienen tatsächlich dazu, die Konsistenz des Datenbankstatus sicherzustellen. Natürlich sind dies alles Garantien auf Datenbankebene, und die Implementierung der Konsistenz erfordert auch Garantien auf Anwendungsebene. Das heißt, für Ihr Unternehmen zieht der Kaufvorgang beispielsweise nur das Guthaben des Benutzers ab und reduziert nicht den Lagerbestand. Es ist definitiv unmöglich, sicherzustellen, dass der Status konsistent ist. Wir sind alle mit MySQL vertraut und wissen auch, was ACID ist, aber wie wird die ACID von MySQL implementiert? Manchmal wissen Sie zwar, dass es ein Undo-Log und ein Redo-Log gibt, aber Sie wissen möglicherweise nicht, warum es sie gibt. Wenn Sie den Zweck des Designs kennen, wird es klarer. MVCC
Versionskette
undo log organisiert. 
ReadView
Abfrage starten
Phantom-Read auf RR-Ebene
Ding 1
Ding 2
beginnen
beginnen
wählen Sie * aus der Abteilung aus
??
id name
1 A
2 B
ist. Es stellte sich tatsächlich als id name
1 B
2 B
heraus. Tatsächlich löst die Isolationsstufe des wiederholbaren MySQL-Lesevorgangs das Problem des Phantomlesens nicht vollständig, löst jedoch das Problem des Phantomlesens beim Lesen von Daten. Bei Änderungsvorgängen besteht immer noch ein Phantomleseproblem, was bedeutet, dass MVCC Phantomlesevorgänge nicht vollständig löst.
Atomizität
Persistenz
So führen Sie eine SQL-Update-Anweisung aus
Redo-Log
Pufferpool
binlog
Binlog und Redo-Log
update T set c=c+1 where ID=2;
Konsistenz
Zusammenfassung
Das obige ist der detaillierte Inhalt vonInterviewer: Wie implementiert MySQL ACID?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!