
Heim >Technologie-Peripheriegeräte >KI >Der akademische ACL-Bericht von Chen Danqi ist da! Ausführliche Erläuterung der 7 Hauptrichtungen und 3 Hauptherausforderungen der „Plug-in'-Datenbank für große Modelle, 3 Stunden voller nützlicher Informationen
Der akademische ACL-Bericht von Chen Danqi ist da! Ausführliche Erläuterung der 7 Hauptrichtungen und 3 Hauptherausforderungen der „Plug-in'-Datenbank für große Modelle, 3 Stunden voller nützlicher Informationen

- PHPznach vorne
- 2023-07-23 08:29:081676Durchsuche
Der Absolvent der Tsinghua Yao-Klasse Chen Danqi hielt zuletzt eine Rede beim ACL 2023!
Das Thema ist in letzter Zeit immer noch eine sehr heiße Forschungsrichtung –
wie GPT-3, PaLM und andere (große)Sprachmodelle, müssen sie sich auf Abruf verlassen, um ihre eigenen Mängel auszugleichen? um ihre Anwendungen besser umzusetzen?
In dieser Rede stellten sie und drei weitere Redner gemeinsam mehrere wichtige Forschungsrichtungen zu diesem Thema vor, darunter Trainingsmethoden, Anwendungen und Herausforderungen.
 Bilder
Bilder
Die Reaktion des Publikums während der Rede war ebenfalls sehr enthusiastisch. Viele Internetnutzer stellten ihre Fragen ernsthaft und mehrere Redner versuchten ihr Bestes, um ihre Fragen zu beantworten.
 Bilder
Bilder
Was die konkrete Wirkung dieser Rede betrifft? Einige Internetnutzer sagten im Kommentarbereich direkt „empfehlen“.
 Bilder
Bilder
Worüber genau haben sie in dieser dreistündigen Rede gesprochen? Welche anderen Orte sind es wert, gehört zu werden?
Warum benötigen große Modelle „Plug-in“-Datenbanken?
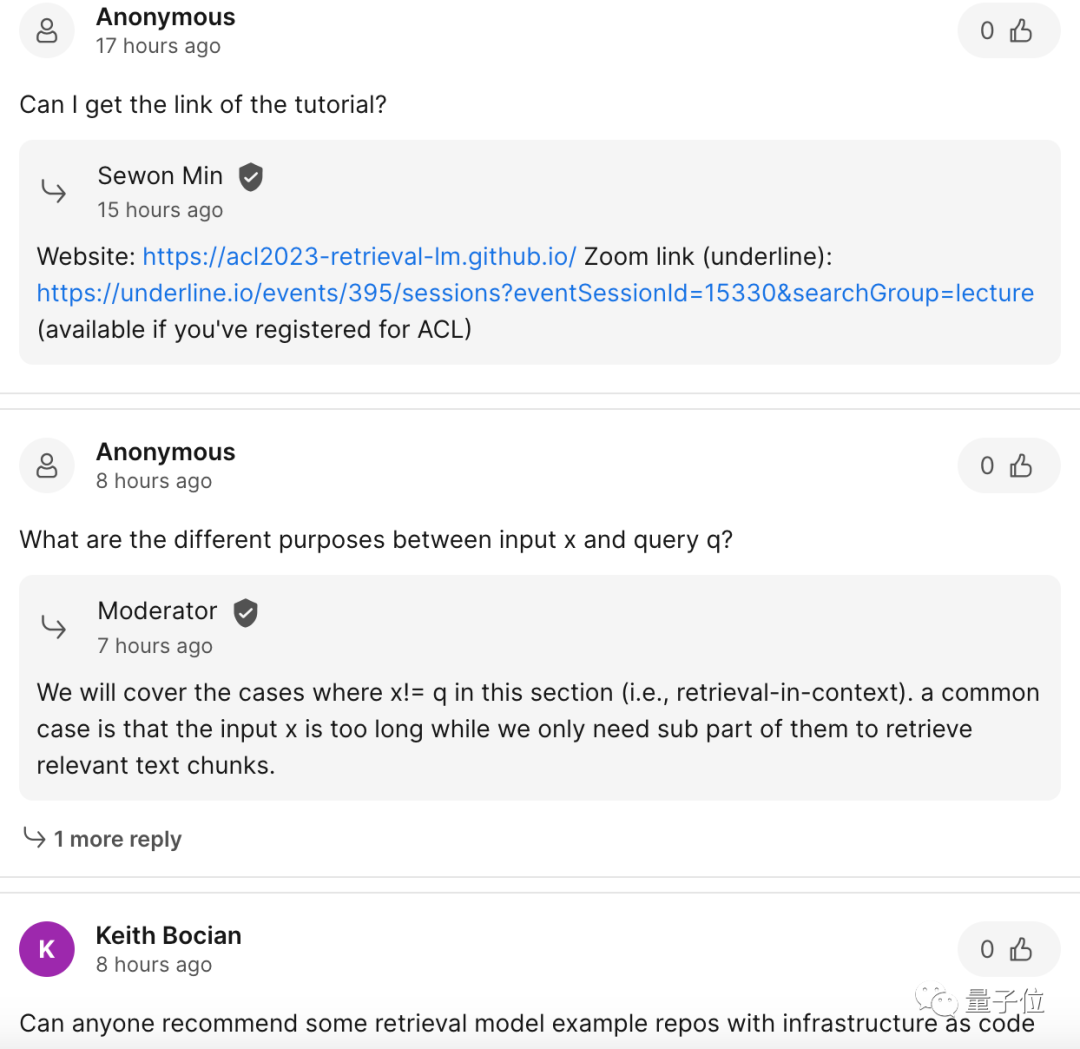
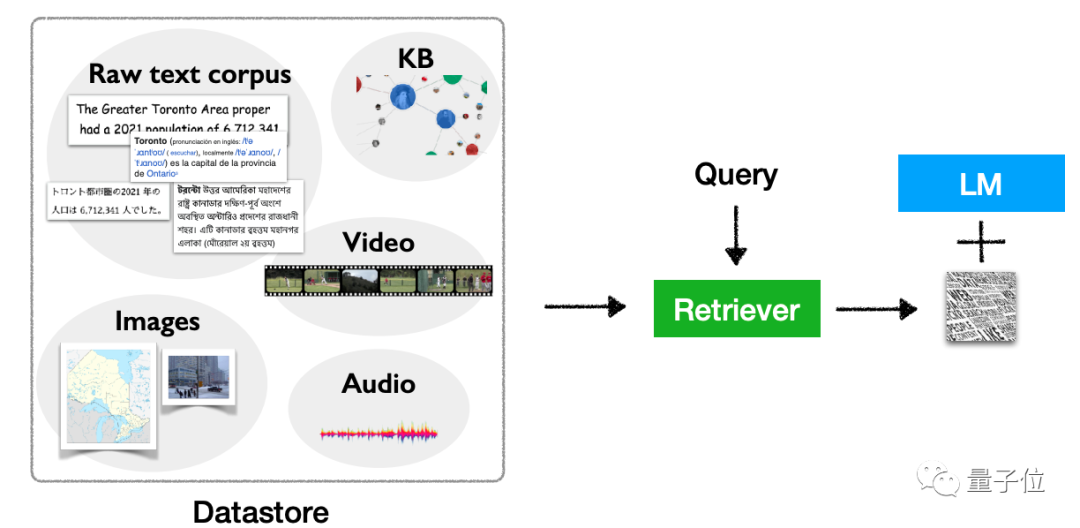
Das Kernthema dieser Rede ist „Retrieval-basiertes Sprachmodell“, das zwei Elemente umfasst: Retrieval und Sprachmodell.
Nach der Definition bezieht es sich auf das „Einbinden“ einer Datenabrufdatenbank in das Sprachmodell, das Abrufen dieser Datenbank bei der Durchführung von Inferenzen (und anderen Operationen) und schließlich die Ausgabe basierend auf den Abrufergebnissen.
Diese Art von Plug-in-Datenspeicher wird auch als semiparametrisches Modell oder nichtparametrisches Modell bezeichnet.
 Bilder
Bilder
Der Grund, warum wir diese Richtung studieren müssen, liegt darin, dass (große)Sprachmodelle wie GPT-3 und PaLM gute Ergebnisse gezeigt haben, es aber auch einige Kopfschmerzen gab.“ Fehler, Es gibt drei Hauptprobleme:
1, Die Anzahl der Parameter ist zu groß, und wenn ein erneutes Training auf der Grundlage neuer Daten erfolgt, sind die Berechnungskosten zu hoch;
2, Der Speicher ist nicht gut (Vor uns liegt eine lange Zeit Texte, ich vergesse, mich an das Folgende zu erinnern) , es wird mit der Zeit Halluzinationen verursachen und es ist leicht, Daten durchsickern zu lassen
3. Bei der aktuellen Menge an Parametern ist es unmöglich, sich an das gesamte Wissen zu erinnern.
Architektur, Ausbildung, Multimodalität, Anwendungen und Herausforderungen dieser Forschungsrichtung zu diskutieren.
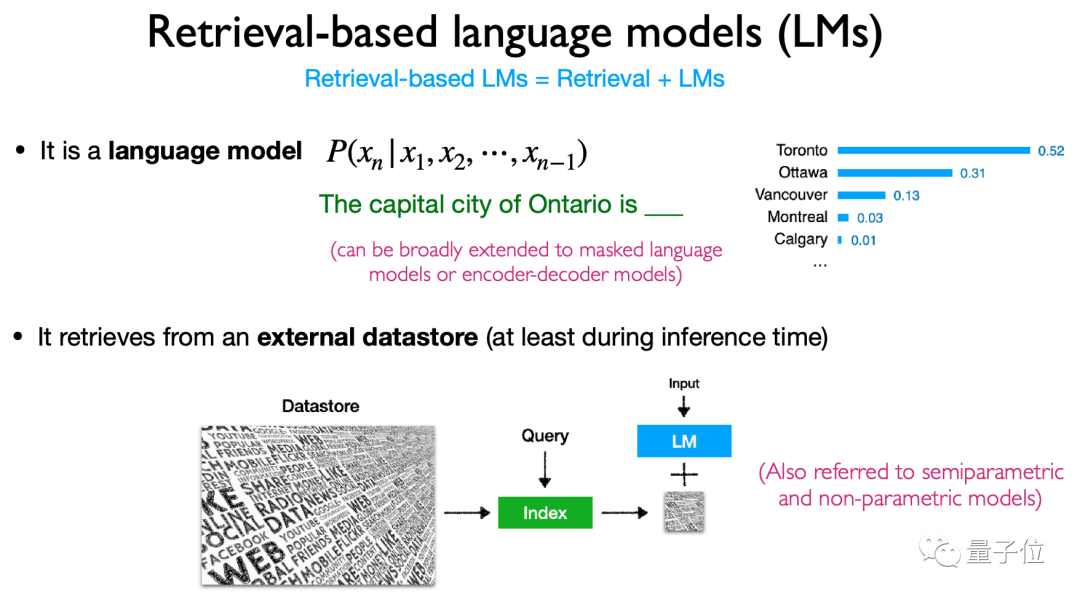
In derArchitektur werden hauptsächlich der Inhalt, die Abrufmethode und das „Timing“ des Abrufs basierend auf dem Abruf des Sprachmodells vorgestellt.
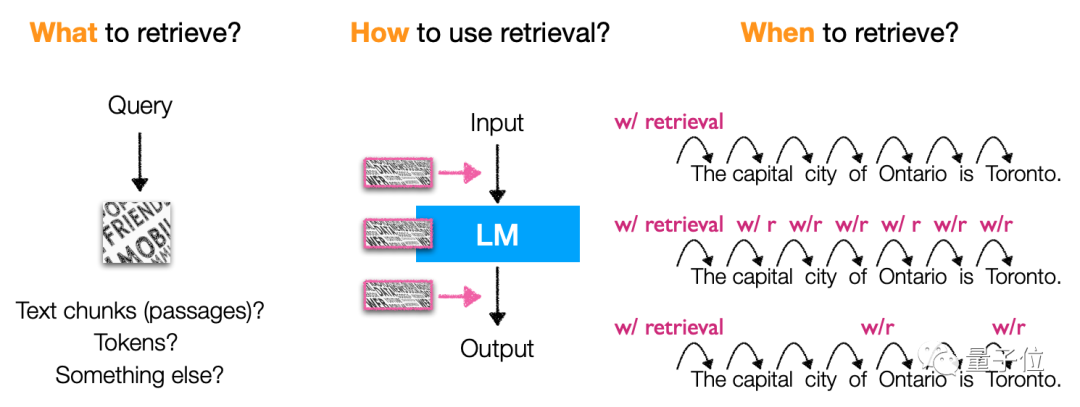
Insbesondere ruft dieser Modelltyp hauptsächlich Token, Textblöcke und Entitätswörter ab(Entitätserwähnungen) Auch die Methoden und der Zeitpunkt des Abrufs sind sehr vielfältig, was es zu einer sehr flexiblen Modellarchitektur macht.
 Bilder
Bilder
Trainingsmethoden liegt der Schwerpunkt auf unabhängigem Training (unabhängiges Training, Sprachmodell und Abrufmodell werden separat trainiert), kontinuierlichem Lernen (sequentielles Training) und Multitasking Lernen(gemeinsames Training) und andere Methoden.
 Bilder
Bilder
Anwendung betrifft, kann diese Art von Modell nicht nur für die Codegenerierung, Klassifizierung, wissensintensives NLP und andere Aufgaben verwendet werden, sondern auch durch Feinabstimmung und Verstärkung Lernen, basierend auf Suchbegriffen und anderen Methoden können verwendet werden.
Außerdem sind die Anwendungsszenarien sehr flexibel, einschließlich Long-Tail-Szenarien, Szenarien, die Wissensaktualisierungen erfordern, und Szenarien mit Datenschutz und Sicherheit usw. Diese Art von Modell kann verwendet werden.Natürlich geht es nicht nur um Text. Diese Art von Modell hat auch das Potenzial für eine multimodaleErweiterung, sodass es für andere Aufgaben als Text verwendet werden kann.
 Bilder
Bilder
Es hört sich so an, als hätte diese Art von Modell viele Vorteile, aber es gibt auch einige Herausforderungen, die auf abrufbasierten Sprachmodellen basieren.
In seiner abschließenden „Abschluss“-Rede hob Chen Danqi mehrere große Probleme hervor, die in dieser Forschungsrichtung gelöst werden müssen.
Erstens, kleines Sprachmodell + (kontinuierliche Erweiterung) Große Datenbank, bedeutet das im Wesentlichen, dass die Anzahl der Parameter des Sprachmodells immer noch sehr groß ist? Wie kann dieses Problem gelöst werden?
Obwohl die Anzahl der Parameter dieses Modelltyps beispielsweise sehr gering sein kann, nur 7 Milliarden Parameter, kann die Plug-in-Datenbank 2T erreichen ...
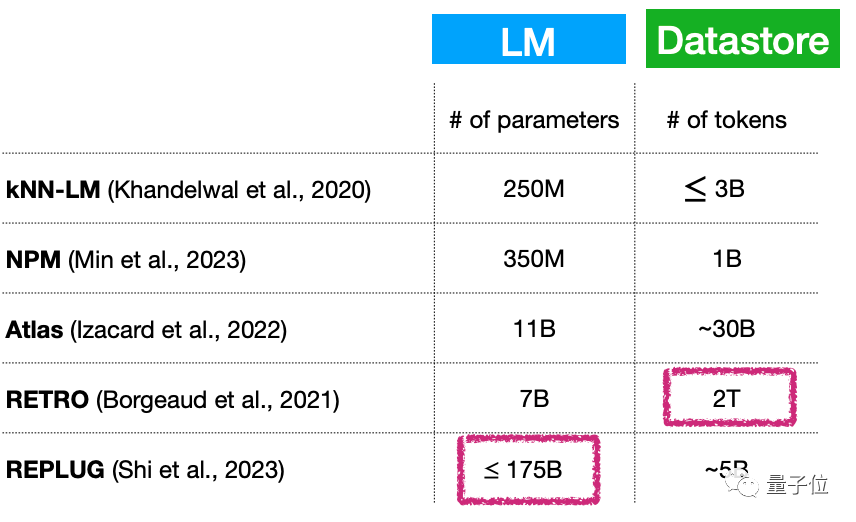 Bilder
Bilder
Zweitens die Effizienz der Ähnlichkeit suchen. Die Gestaltung von Algorithmen zur Maximierung der Sucheffizienz ist derzeit eine sehr aktive Forschungsrichtung.
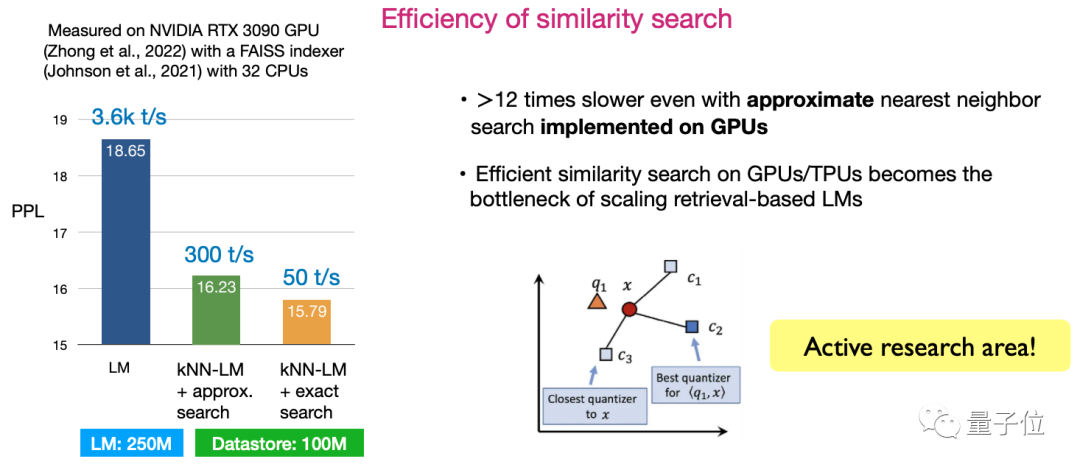 Bilder
Bilder
Drittens: Erledige komplexe Sprachaufgaben. Einschließlich offener Textgenerierungsaufgaben und komplexer Textbegründungsaufgaben ist auch die Verwendung von abrufbasierten Sprachmodellen zur Erledigung dieser Aufgaben eine Richtung, die einer weiteren Erforschung bedarf.
 Bilder
Bilder
Natürlich erwähnte Chen Danqi auch, dass diese Themen nicht nur Herausforderungen, sondern auch Forschungsmöglichkeiten darstellen. Freunde, die noch auf der Suche nach Abschlussthemen sind, können darüber nachdenken, diese in die Forschungsliste aufzunehmen. Es ist erwähnenswert, dass es sich bei dieser Rede nicht um ein Thema handelt, das „aus dem Nichts“ ist. Die vier Redner haben es auf der offiziellen Seite nachdenklich erwähnt Website Links zu Artikeln, auf die in der Rede verwiesen wird, wurden veröffentlicht.
Von Modellarchitektur, Trainingsmethoden, Anwendungen, Multimodalität bis hin zu Herausforderungen: Wenn Sie sich für einen Teil dieser Themen interessieren, können Sie auf der offiziellen Website die entsprechenden klassischen Papiere finden:
Bilder Vor Ort Antworten auf die Verwirrung des Publikums
Vor Ort Antworten auf die Verwirrung des Publikums
Für eine solch informative Rede sind die vier Hauptredner nicht ohne Hintergrundwissen. Während der Rede beantworteten sie auch geduldig die Fragen des Publikums.
Lassen Sie uns zunächst darüber sprechen, wer die Redner in Kangkang sind.
Der erste ist
Chen Danqi, Assistenzprofessor für Informatik an der Princeton University, der diese Rede hielt.
Bilder Sie ist in letzter Zeit eine der beliebtesten jungen chinesischen Wissenschaftlerinnen auf dem Gebiet der Informatik und ist außerdem Absolventin der Tsinghua Yao-Klasse im Jahr 2008.
Sie ist in letzter Zeit eine der beliebtesten jungen chinesischen Wissenschaftlerinnen auf dem Gebiet der Informatik und ist außerdem Absolventin der Tsinghua Yao-Klasse im Jahr 2008.
In der Informatik-Wettbewerbsszene ist sie ziemlich legendär – der „CDQ Divide and Conquer-Algorithmus“ ist nach ihr benannt. 2008 gewann sie für das chinesische Team eine IOI-Goldmedaille.
Und ihre 156-seitige Doktorarbeit „Neural Reading Comprehension and Beyond“ wurde einst sehr populär und gewann in diesem Jahr nicht nur den Stanford Best Doctoral Thesis Award, sie wurde auch zum beliebtesten Thema an der Stanford University in den letzten zehn Jahren . Eine der Abschlussarbeiten. Jetzt ist Chen Danqi nicht nur Assistenzprofessor für Informatik an der Princeton University, sondern auch Co-Leiter des NLP-Teams der Schule und Mitglied des AIML-Teams.
Ihre Forschungsrichtung konzentriert sich hauptsächlich auf die Verarbeitung natürlicher Sprache und maschinelles Lernen und sie interessiert sich für einfache und zuverlässige Methoden, die bei praktischen Problemen machbar, skalierbar und generalisierbar sind.
Ebenfalls von der Princeton University gibt es Chen Danqis Lehrling
Zhong Zexuan(Zexuan Zhong). Bilder
Seine neueste Forschung konzentriert sich auf das Extrahieren strukturierter Informationen aus unstrukturiertem Text, das Extrahieren von Sachinformationen aus vorab trainierten Sprachmodellen, die Analyse der Generalisierungsfähigkeiten dichter Retrieval-Modelle und die Entwicklung von Schulungen für die Retrieval-basierte Sprachmodelltechnologie. Zu den Hauptrednern gehören außerdem Akari Asai und Sewon Min von der Washington University. Akari Asai ist ein Doktorand im vierten Jahr an der University of Washington mit Schwerpunkt auf natürlicher Sprachverarbeitung. Er schloss sein Bachelor-Studium an der University of Tokyo in Japan ab. Sie interessiert sich hauptsächlich für die Entwicklung zuverlässiger und anpassungsfähiger Systeme zur Verarbeitung natürlicher Sprache, um die Fähigkeiten zur Informationsbeschaffung zu verbessern. In letzter Zeit konzentriert sich ihre Forschung hauptsächlich auf allgemeine Wissensabrufsysteme, effiziente adaptive NLP-Modelle und andere Bereiche. Sewon Min ist Doktorand in der Natural Language Processing Group der University of Washington und hat vier Jahre lang nebenberuflich als Forscher bei Meta AI gearbeitet von der Seoul National University mit einem Bachelor-Abschluss. In letzter Zeit konzentriert sie sich hauptsächlich auf Sprachmodellierung, Sprachabruf und die Schnittstelle der beiden. Während der Rede stellte das Publikum auch begeistert viele Fragen, beispielsweise warum Ratlosigkeit(Perplexität) als Hauptindikator der Rede verwendet wird. Der Sprecher gab eine vorsichtige Antwort: Beim Vergleich parametrisierter Sprachmodelle wird häufig die Ratlosigkeit (PPL) verwendet. Ob sich Verbesserungen der Perplexität jedoch auf nachgelagerte Anwendungen übertragen lassen, bleibt eine Forschungsfrage. Untersuchungen haben nun gezeigt, dass Ratlosigkeit gut mit nachgelagerten Aufgaben (insbesondere Generierungsaufgaben) korreliert und dass Ratlosigkeit oft sehr stabile Ergebnisse liefert und anhand umfangreicher Auswertungsdaten ausgewertet werden kann (Bewertungsdaten sind im Vergleich zu nachgelagerten Aufgaben unbeschriftet , was durch die Cue-Empfindlichkeit und das Fehlen umfangreicher beschrifteter Daten beeinträchtigt werden kann, was zu instabilen Ergebnissen führt) . Einige Internetnutzer haben diese Frage gestellt: In Bezug auf die Aussage, dass „die Schulungskosten für Sprachmodelle hoch sind und die Einführung des Abrufs dieses Problem lösen kann“, ersetzen Sie einfach die zeitliche Komplexität durch Platz Komplexität (Datenspeicherung) ? Die Antwort des Redners stammt von Tante Jiang: Der Schwerpunkt unserer Diskussion liegt darauf, wie wir das Sprachmodell auf eine kleinere Größe reduzieren und dadurch den Zeit- und Platzbedarf reduzieren können. Tatsächlich verursacht die Datenspeicherung jedoch auch zusätzlichen Overhead, der sorgfältig abgewogen und untersucht werden muss, und wir glauben, dass dies eine aktuelle Herausforderung darstellt. Im Vergleich zum Training eines Sprachmodells mit mehr als 10 Milliarden Parametern ist es meiner Meinung nach derzeit am wichtigsten, die Trainingskosten zu senken. Wenn Sie die PPT dieser Rede finden oder sich die spezifische Wiedergabe ansehen möchten, können Sie zur offiziellen Website gehen~ Offizielle Website: https://acl2023-retrieval- lm.github.io / Zhong Zexuan ist Doktorand im vierten Jahr an der Princeton University. Ich schloss mein Studium an der University of Illinois in Urbana-Champaign mit einem Master-Abschluss unter der Leitung von Xie Tao ab. Ich schloss mein Studium an der Fakultät für Informatik der Universität Peking mit einem Bachelor-Abschluss ab und arbeitete als Praktikant bei Microsoft Research Asia unter der Leitung von Nie Zaiqing.
Zhong Zexuan ist Doktorand im vierten Jahr an der Princeton University. Ich schloss mein Studium an der University of Illinois in Urbana-Champaign mit einem Master-Abschluss unter der Leitung von Xie Tao ab. Ich schloss mein Studium an der Fakultät für Informatik der Universität Peking mit einem Bachelor-Abschluss ab und arbeitete als Praktikant bei Microsoft Research Asia unter der Leitung von Nie Zaiqing.  Pictures
Pictures Pictures
Pictures Bilder
Bilder Bilder
Bilder
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonDer akademische ACL-Bericht von Chen Danqi ist da! Ausführliche Erläuterung der 7 Hauptrichtungen und 3 Hauptherausforderungen der „Plug-in'-Datenbank für große Modelle, 3 Stunden voller nützlicher Informationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr