
Heim >Technologie-Peripheriegeräte >KI >Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token
Microsofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-22 15:34:011322Durchsuche
Wenn jeder seine eigenen großen Modelle weiter aktualisiert und iteriert, ist die Fähigkeit des LLM (Large Language Model), Kontextfenster zu verarbeiten, auch zu einem wichtigen Bewertungsindikator geworden.
Zum Beispiel unterstützt das Promi-Großmodell GPT-4 32.000 Token, was 50 Textseiten entspricht. Das von einem ehemaligen Mitglied von OpenAI gegründete Unternehmen hat Claudes Token-Verarbeitungskapazitäten auf 100.000, etwa 75.000 Wörter, erhöht. was in etwa einer One-Click-Zusammenfassung von „Harry Potter“ Teil Eins entspricht.
In der neuesten Studie von Microsoft haben sie Transformer dieses Mal direkt auf 1 Milliarde Token erweitert. Dies eröffnet neue Möglichkeiten zur Modellierung sehr langer Sequenzen, beispielsweise die Behandlung eines gesamten Korpus oder sogar des gesamten Internets als eine Sequenz.
Zum Vergleich: Die durchschnittliche Person kann 100.000 Token in etwa 5 Stunden lesen und es kann länger dauern, diese Informationen zu verarbeiten, zu merken und zu analysieren. Claude schafft das in weniger als einer Minute. Würde man sie in diese Studie von Microsoft umrechnen, wäre das eine atemberaubende Zahl.
 Bilder
Bilder
- Papieradresse: https://arxiv.org/pdf/2307.02486.pdf
- Projektadresse: https://github.com/microsoft/unilm/tree/master
Konkret schlägt die Forschung LONGNET vor, eine Transformer-Variante, die die Sequenzlänge auf über 1 Milliarde Token erweitern kann, ohne die Leistung bei kürzeren Sequenzen zu beeinträchtigen. Der Artikel schlägt auch eine erweiterte Aufmerksamkeit vor, die den Wahrnehmungsbereich des Modells exponentiell erweitern kann.
LONGNET hat die folgenden Vorteile:
1) Es hat eine lineare Rechenkomplexität;
2) Es kann als verteilter Trainer für längere Sequenzen verwendet werden;
3) Die Aufmerksamkeit kann erweitert werden Die Verwendung ohne Seam ersetzt die Standardaufmerksamkeit und kann nahtlos in bestehende Transformer-basierte Optimierungsmethoden integriert werden.
Experimentelle Ergebnisse zeigen, dass LONGNET sowohl bei der Modellierung langer Sequenzen als auch bei allgemeinen Sprachaufgaben eine starke Leistung zeigt.
In Bezug auf die Forschungsmotivation heißt es in dem Papier, dass die Erweiterung neuronaler Netze in den letzten Jahren zu einem Trend geworden ist und viele Netze mit guter Leistung untersucht wurden. Unter diesen sollte die Sequenzlänge als Teil des neuronalen Netzwerks idealerweise unendlich sein. In der Realität ist jedoch oft das Gegenteil der Fall, sodass das Überschreiten der Sequenzlängenbeschränkung erhebliche Vorteile mit sich bringt:
- Erstens stellt es dem Modell ein großes Speicher- und Empfangsfeld zur Verfügung, sodass es effektiv mit Menschen und anderen kommunizieren kann Welt. Interaktion.
- Zweitens enthält ein längerer Kontext komplexere kausale Zusammenhänge und Argumentationspfade, die das Modell in den Trainingsdaten nutzen kann. Im Gegenteil führen kürzere Abhängigkeiten zu mehr falschen Korrelationen, was der Verallgemeinerung des Modells nicht förderlich ist.
- Drittens kann eine längere Sequenzlänge dem Modell helfen, längere Kontexte zu erkunden, und extrem lange Kontexte können dem Modell auch dabei helfen, das katastrophale Vergessensproblem zu lindern.
Die größte Herausforderung bei der Verlängerung der Sequenzlänge besteht jedoch darin, das richtige Gleichgewicht zwischen Rechenkomplexität und Modellausdruckskraft zu finden.
Modelle im RNN-Stil werden beispielsweise hauptsächlich verwendet, um die Sequenzlänge zu erhöhen. Allerdings schränkt seine sequentielle Natur die Parallelisierung während des Trainings ein, was bei der Modellierung langer Sequenzen von entscheidender Bedeutung ist.
In letzter Zeit sind Zustandsraummodelle für die Sequenzmodellierung sehr attraktiv geworden, die während des Trainings als CNN ausgeführt und zur Testzeit in ein effizientes RNN umgewandelt werden können. Bei normalen Längen ist die Leistung dieses Modelltyps jedoch nicht so gut wie bei Transformer.
Eine weitere Möglichkeit, die Sequenzlänge zu verlängern, besteht darin, die Komplexität des Transformers zu reduzieren, also die quadratische Komplexität der Selbstaufmerksamkeit. Zu diesem Zeitpunkt wurden einige effiziente transformatorbasierte Varianten vorgeschlagen, darunter niedrigrangige Aufmerksamkeitsmethoden, Kernel-basierte Methoden, Downsampling-Methoden und abrufbasierte Methoden. Diese Ansätze müssen Transformer jedoch noch auf die Größenordnung von 1 Milliarde Token skalieren (siehe Abbildung 1).
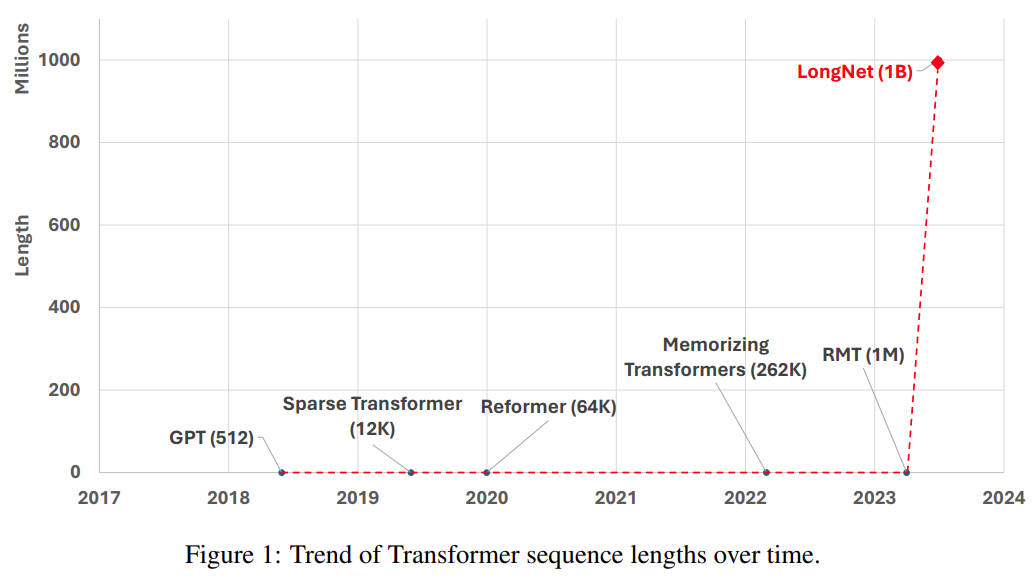 Bilder
Bilder
Die folgende Tabelle zeigt den Vergleich der Rechenkomplexität verschiedener Berechnungsmethoden. N ist die Sequenzlänge und d ist die verborgene Dimension.
 Bilder
Bilder
Methode
Die Forschungslösung LONGNET hat die Sequenzlänge erfolgreich auf 1 Milliarde Token erweitert. Konkret schlägt diese Forschung eine neue Komponente namens erweiterte Aufmerksamkeit vor und ersetzt den Aufmerksamkeitsmechanismus von Vanilla Transformer durch erweiterte Aufmerksamkeit. Ein allgemeines Designprinzip besteht darin, dass die Aufmerksamkeitsverteilung mit zunehmendem Abstand zwischen Token exponentiell abnimmt. Die Studie zeigt, dass dieser Entwurfsansatz eine lineare Rechenkomplexität und eine logarithmische Abhängigkeit zwischen Token erreicht. Dadurch wird der Konflikt zwischen begrenzten Aufmerksamkeitsressourcen und dem Zugriff auf jeden Token gelöst.
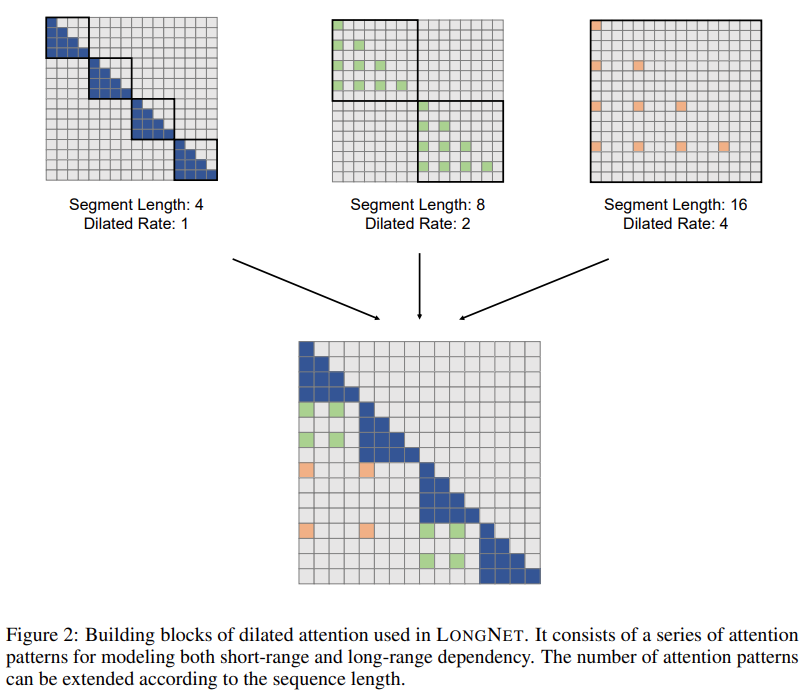 Bilder
Bilder
Während der Implementierung kann LONGNET in einen dichten Transformer umgewandelt werden, um vorhandene Optimierungsmethoden für Transformer (wie Kernelfusion, Quantisierung und verteiltes Training) nahtlos zu unterstützen. Unter Ausnutzung der linearen Komplexität kann LONGNET knotenübergreifend parallel trainiert werden, wobei verteilte Algorithmen verwendet werden, um Rechen- und Speicherbeschränkungen zu überwinden.
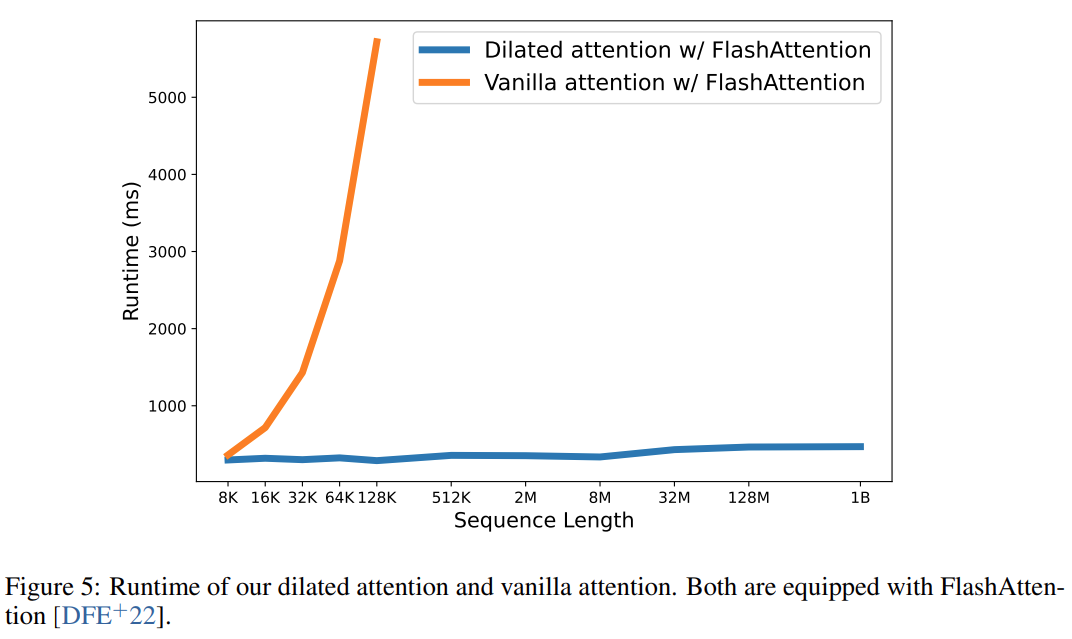
Letztendlich hat diese Forschung die Sequenzlänge effektiv auf 1B Token erweitert, und die Laufzeit war nahezu konstant, wie in der Abbildung unten gezeigt. Im Gegensatz dazu leidet die Laufzeit des Vanilla-Transformers unter quadratischer Komplexität.
Diese Forschung führt den Mehrkopf-Mechanismus der erweiterten Aufmerksamkeit weiter ein. Wie in Abbildung 3 unten dargestellt, führt diese Studie verschiedene Berechnungen über verschiedene Köpfe hinweg durch, indem verschiedene Teile von Abfrage-Schlüssel-Wert-Paaren sparsifiziert werden.
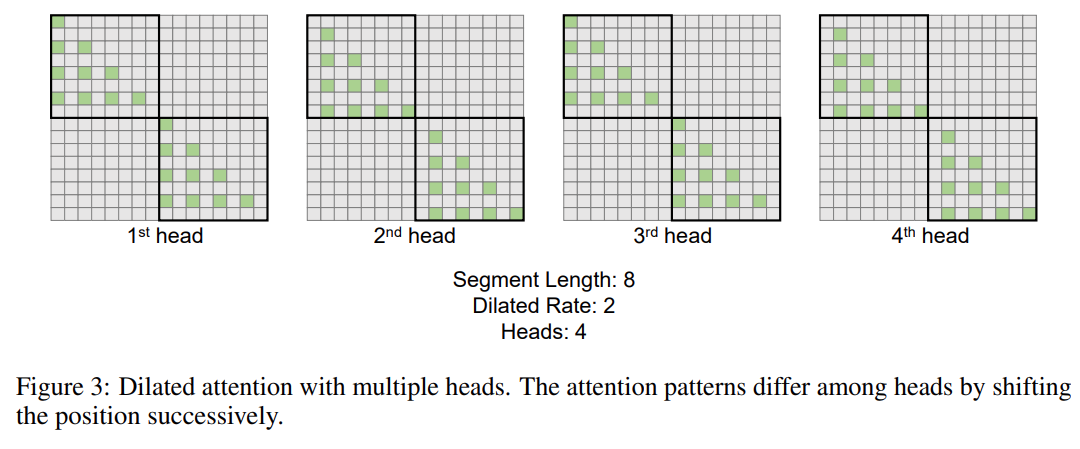 Bilder
Bilder
Verteiltes Training
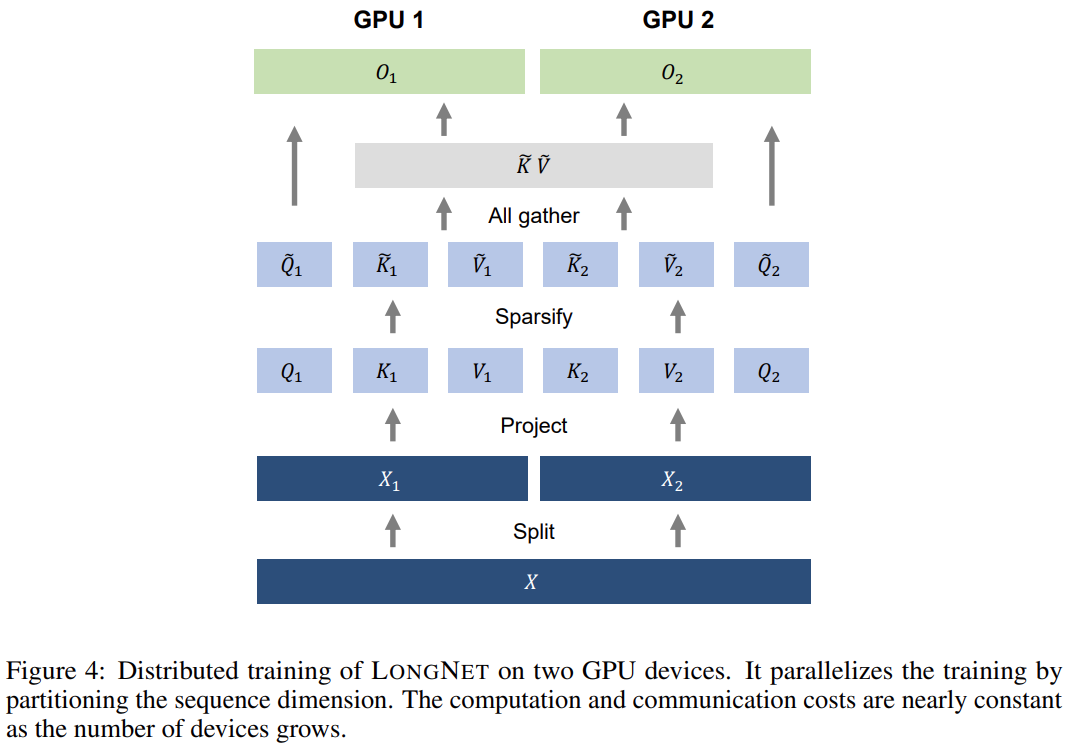
Obwohl die Rechenkomplexität der erweiterten Aufmerksamkeit aufgrund von Rechen- und Speicherbeschränkungen stark reduziert wurde, wird es auf einer einzigen sein GPU Gerät Eine Skalierung der Sequenzlänge auf Millionen ist nicht möglich. Es gibt einige verteilte Trainingsalgorithmen für das Training großer Modelle, wie z. B. Modellparallelität [SPP+19], Sequenzparallelität [LXLY21, KCL+22] und Pipeline-Parallelität [HCB+19]. Diese Methoden reichen jedoch für LONGNET nicht aus ., insbesondere wenn die Sequenzdimension sehr groß ist. 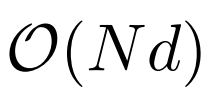 Diese Forschung nutzt die lineare Rechenkomplexität von LONGNET für das verteilte Training von Sequenzdimensionen. Abbildung 4 unten zeigt den verteilten Algorithmus auf zwei GPUs, der weiter auf eine beliebige Anzahl von Geräten skaliert werden kann.
Diese Forschung nutzt die lineare Rechenkomplexität von LONGNET für das verteilte Training von Sequenzdimensionen. Abbildung 4 unten zeigt den verteilten Algorithmus auf zwei GPUs, der weiter auf eine beliebige Anzahl von Geräten skaliert werden kann.
 Experimente
Experimente
Die Studie verglich LONGNET mit Vanilla Transformer und Sparse Transformer. Der Unterschied zwischen den Architekturen besteht in der Aufmerksamkeitsschicht, während die anderen Schichten unverändert bleiben. Die Forscher erweiterten die Sequenzlänge dieser Modelle von 2K auf 32K und reduzierten gleichzeitig die Stapelgröße, um sicherzustellen, dass die Anzahl der Token in jedem Stapel unverändert blieb.
Tabelle 2 fasst die Ergebnisse dieser Modelle für den Stack-Datensatz zusammen. Die Forschung verwendet Komplexität als Bewertungsmaßstab. Die Modelle wurden mit unterschiedlichen Sequenzlängen von 2k bis 32k getestet. Wenn die Eingabelänge die vom Modell unterstützte maximale Länge überschreitet, implementiert die Forschung blockweise kausale Aufmerksamkeit (BCA) [SDP+22], eine hochmoderne Extrapolationsmethode für die Inferenz von Sprachmodellen.
Darüber hinaus wurde in der Studie die absolute Positionskodierung entfernt. Erstens zeigen die Ergebnisse, dass eine Erhöhung der Sequenzlänge während des Trainings im Allgemeinen zu besseren Sprachmodellen führt. Zweitens ist die Methode zur Extrapolation der Sequenzlänge in der Inferenz nicht anwendbar, wenn die Länge viel größer ist, als das Modell unterstützt. Schließlich übertrifft LONGNET durchweg die Basismodelle und demonstriert damit seine Wirksamkeit bei der Sprachmodellierung.
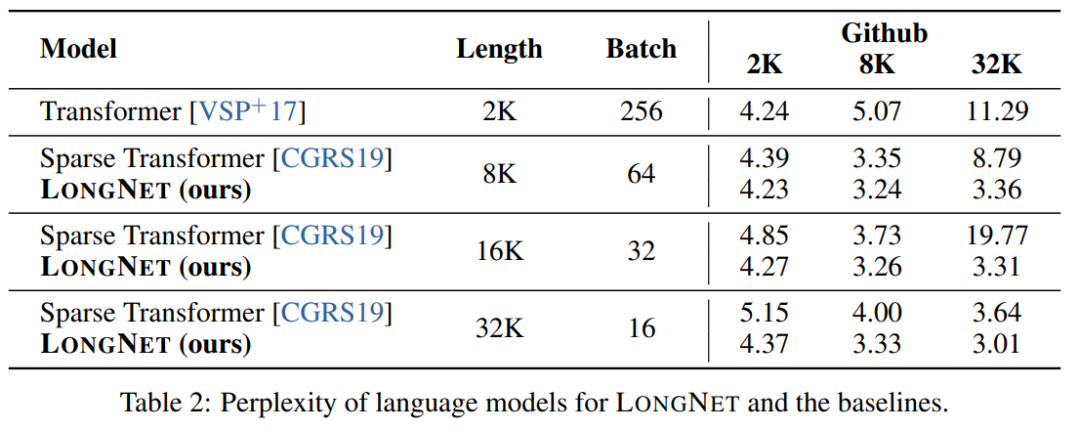
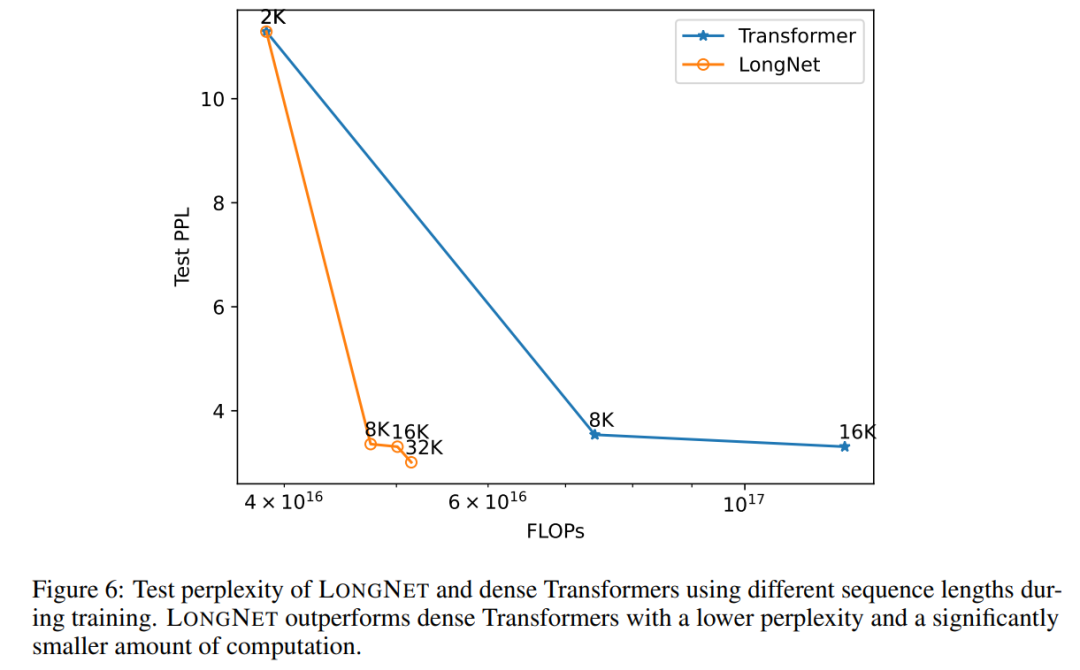
Abbildung 6 zeigt die Sequenzlängen-Erweiterungskurven von Vanilla Transformer und LONGNET. Diese Studie schätzt den Rechenaufwand durch Zählen der gesamten Flops von Matrixmultiplikationen. Die Ergebnisse zeigen, dass sowohl Vanilla Transformer als auch LONGNET durch das Training größere Kontextlängen erreichen. Allerdings kann LONGNET die Kontextlänge effizienter verlängern und so einen geringeren Testverlust mit weniger Rechenaufwand erzielen. Dies zeigt den Vorteil längerer Trainingseingaben gegenüber der Extrapolation. Experimente zeigen, dass LONGNET eine effizientere Möglichkeit ist, die Kontextlänge in Sprachmodellen zu verlängern. Dies liegt daran, dass LONGNET längere Abhängigkeiten effizienter lernen kann.
Modellgröße erweitern
Eine wichtige Eigenschaft großer Sprachmodelle ist, dass der Verlust in einem Potenzgesetz mit zunehmendem Rechenaufwand skaliert. Um zu überprüfen, ob LONGNET immer noch ähnlichen Skalierungsregeln folgt, trainierte die Studie eine Reihe von Modellen mit unterschiedlichen Modellgrößen (von 125 Millionen bis 2,7 Milliarden Parametern). 2,7 Milliarden Modelle wurden mit 300 Milliarden Token trainiert, während die übrigen Modelle etwa 400 Milliarden Token verwendeten. Abbildung 7 (a) zeigt die Expansionskurve von LONGNET im Hinblick auf die Berechnung. Die Studie berechnete die Komplexität mit demselben Testsatz. Dies beweist, dass LONGNET immer noch einem Potenzgesetz folgen kann. Dies bedeutet auch, dass Dense Transformer keine Voraussetzung für die Erweiterung von Sprachmodellen ist. Darüber hinaus werden mit LONGNET Skalierbarkeit und Effizienz gewonnen.
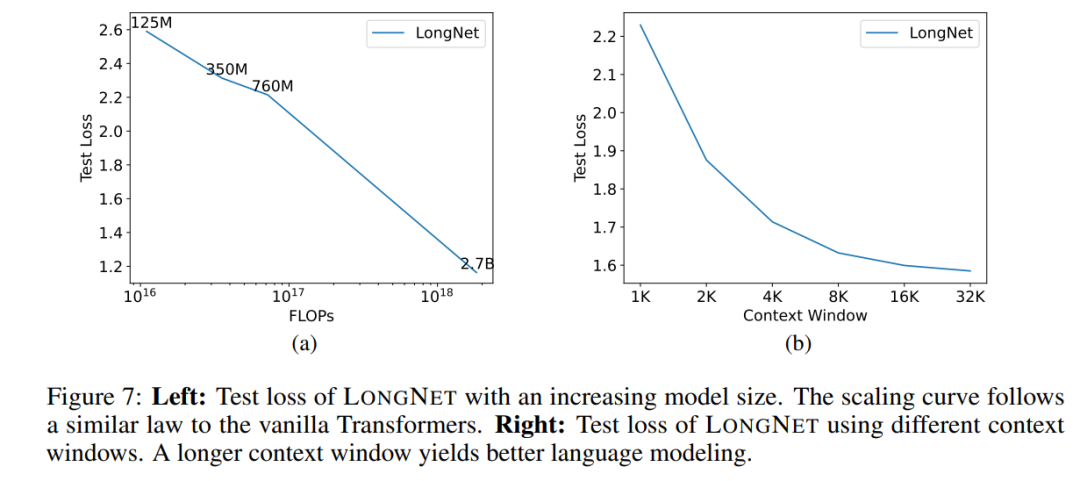
Lange Kontext-Eingabeaufforderung
Eingabeaufforderung ist eine wichtige Möglichkeit, das Sprachmodell zu führen und mit zusätzlichen Informationen zu versorgen. Diese Studie validiert experimentell, ob LONGNET von längeren Kontexthinweisfenstern profitieren kann.
Diese Studie behielt ein Präfix (Präfixe) als Aufforderung bei und testete die Verwirrung seiner Suffixe (Suffixe). Darüber hinaus wurde die Eingabeaufforderung während des Forschungsprozesses schrittweise von 2K auf 32K erweitert. Um einen fairen Vergleich zu ermöglichen, wird die Länge des Suffixes konstant gehalten, während die Länge des Präfixes auf die maximale Länge des Modells erhöht wird. Abbildung 7(b) zeigt die Ergebnisse des Testsatzes. Es zeigt, dass der Testverlust von LONGNET mit zunehmendem Kontextfenster allmählich abnimmt. Dies beweist die Überlegenheit von LONGNET bei der vollständigen Nutzung langer Kontexte zur Verbesserung von Sprachmodellen.
Das obige ist der detaillierte Inhalt vonMicrosofts neues heißes Papier: Transformer expandiert auf 1 Milliarde Token. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr