
Heim >Technologie-Peripheriegeräte >KI >Die Kosten für das Training großer Modelle wurden um fast die Hälfte reduziert! Der neueste Optimierer der National University of Singapore wurde eingesetzt
Die Kosten für das Training großer Modelle wurden um fast die Hälfte reduziert! Der neueste Optimierer der National University of Singapore wurde eingesetzt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-17 22:13:171500Durchsuche
Der Optimierer belegt beim Training großer Sprachmodelle eine große Menge an Speicherressourcen.
Jetzt gibt es eine neue Optimierungsmethode, die den Speicherverbrauch bei gleichbleibender Leistung um die Hälfte reduziert.
Dieses Ergebnis wurde von der National University of Singapore erstellt. Es wurde auf der ACL-Konferenz mit dem Outstanding Paper Award ausgezeichnet und wurde in die Praxis umgesetzt.
 Bilder
Bilder
Mit der zunehmenden Anzahl von Parametern großer Sprachmodelle wird das Problem des Speicherverbrauchs während des Trainings immer schwerwiegender.
Das Forschungsteam schlug den CAME-Optimierer vor, der die gleiche Leistung wie Adam bietet und gleichzeitig den Speicherverbrauch reduziert.
 Bilder
Bilder
Der CAME-Optimierer hat beim Vortraining mehrerer häufig verwendeter großer Sprachmodelle die gleiche oder sogar eine bessere Trainingsleistung als der Adam-Optimierer erzielt und zeigt eine größere Robustheit gegenüber großen Batch-Vortrainingsszenarien Sex.
Darüber hinaus kann das Training großer Sprachmodelle mit dem CAME-Optimierer die Kosten für das Training großer Modelle erheblich senken.
Implementierungsmethode
Der CAME-Optimierer wurde basierend auf dem Adafactor-Optimierer verbessert, was bei den Vortrainingsaufgaben großer Sprachmodelle häufig zu einem Verlust der Trainingsleistung führt.
Die nichtnegative Matrixfaktorisierungsoperation in Adafactor führt zwangsläufig zu Fehlern beim Training tiefer neuronaler Netze, und die Korrektur dieser Fehler führt zu Leistungsverlusten.
Und durch Vergleich wird festgestellt, dass die Konfidenz von mt höher ist, wenn die Differenz zwischen dem Startwert mt und dem aktuellen Wert t gering ist.
 Bild
Bild
Davon inspiriert schlug das Team einen neuen Optimierungsalgorithmus vor.
Der blaue Teil im Bild unten ist der erhöhte Teil von CAME im Vergleich zu Adafactor.
 Picture
Picture
Der CAME-Optimierer führt eine Aktualisierungsmengenkorrektur basierend auf der Konfidenz der Modellaktualisierung durch und führt außerdem eine nichtnegative Matrixzerlegungsoperation für die eingeführte Konfidenzmatrix durch.
Am Ende konnte CAME mit der Einnahme von Adafactor erfolgreich die Wirkung von Adam erzielen.
Der gleiche Effekt verbraucht nur die Hälfte der Ressourcen
Das Team nutzte CAME, um jeweils BERT-, GPT-2- und T5-Modelle zu trainieren.
Die bisher häufig verwendeten Werte Adam (bessere Wirkung) und Adafactor (geringerer Verbrauch) sind die Referenzen zur Messung der CAME-Leistung.
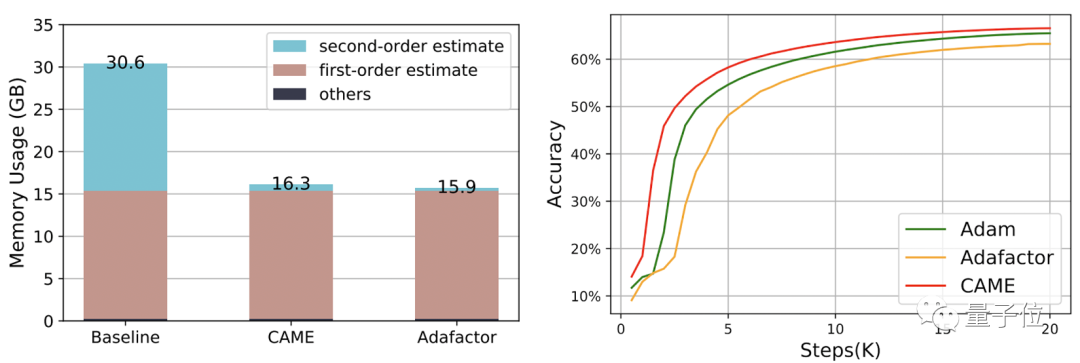
Unter anderem erreichte CAME beim BERT-Training die gleiche Genauigkeit wie Adafaactor in nur halb so vielen Schritten.
 △Die linke Seite ist im 8K-Maßstab, die rechte Seite im 32K-Maßstab
△Die linke Seite ist im 8K-Maßstab, die rechte Seite im 32K-Maßstab
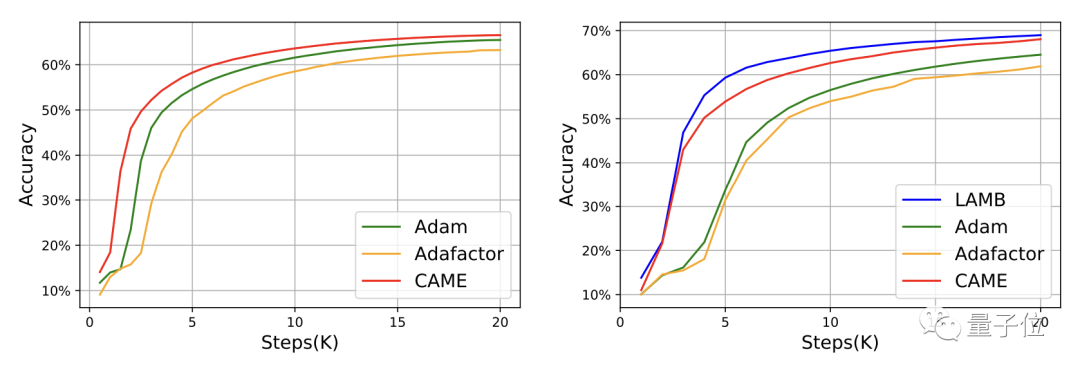
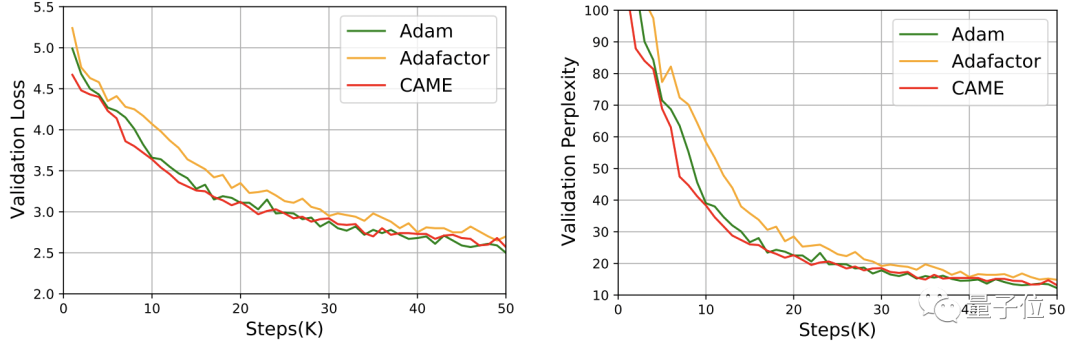
Für GPT-2 kommt die Leistung von CAME aus der Perspektive von Verlust und Verwirrung der von Adam sehr nahe.

Beim Training des T5-Modells zeigte CAME ebenfalls ähnliche Ergebnisse.
Was die Feinabstimmung des Modells betrifft, ist die Genauigkeitsleistung von CAME der Benchmark nicht unterlegen.
In Bezug auf den Ressourcenverbrauch verbraucht CAME bei Verwendung von PyTorch zum Trainieren von BERT mit 4B-Datenvolumen fast die Hälfte der Speicherressourcen im Vergleich zur Basislinie.
Teamprofil
Das HPC-AI Laboratory der National University of Singapore ist ein Labor für Hochleistungsrechnen und künstliche Intelligenz unter der Leitung von Professor You Yang.
Das Labor engagiert sich für die Forschung und Innovation im Bereich Hochleistungsrechnen, maschinelle Lernsysteme und verteiltes Parallelrechnen und fördert Anwendungen in Bereichen wie groß angelegten Sprachmodellen.
Der Leiter des Labors, You Yang, ist der Präsident Young Professor(Presidential Young Professor) des Fachbereichs Informatik an der National University of Singapore.
You Yang wurde 2021 in die Forbes Under 30 Elite List (Asien) aufgenommen und gewann den IEEE-CS Supercomputing Outstanding Newcomer Award. Sein aktueller Forschungsschwerpunkt liegt auf der verteilten Optimierung groß angelegter Deep-Learning-Trainingsalgorithmen.
Luo Yang, der Erstautor dieses Artikels, ist Masterstudent im Labor. Sein aktueller Forschungsschwerpunkt liegt auf der Stabilität und dem effizienten Training des Trainings großer Modelle.
Papieradresse: https://arxiv.org/abs/2307.02047
GitHub-Projektseite: https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
Das obige ist der detaillierte Inhalt vonDie Kosten für das Training großer Modelle wurden um fast die Hälfte reduziert! Der neueste Optimierer der National University of Singapore wurde eingesetzt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr