
Heim >Technologie-Peripheriegeräte >KI >Das Byte-Team schlug das Lynx-Modell vor: multimodale LLMs, die kognitive Generierungslisten-SoTA verstehen
Das Byte-Team schlug das Lynx-Modell vor: multimodale LLMs, die kognitive Generierungslisten-SoTA verstehen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-17 21:57:301317Durchsuche
Aktuelle Large Language Models (LLMs) wie GPT4 haben hervorragende multimodale Fähigkeiten bei der Befolgung offener Anweisungen bei gegebenem Bild gezeigt. Allerdings hängt die Leistung dieser Modelle stark von der Wahl der Netzwerkstruktur, der Trainingsdaten und der Trainingsstrategien ab, diese Wahl wurde jedoch in der bisherigen Literatur nicht ausführlich diskutiert. Darüber hinaus mangelt es derzeit an geeigneten Benchmarks zur Bewertung und zum Vergleich dieser Modelle, was die Entwicklung multimodaler LLMs einschränkt.
 Bilder
Bilder
- Papier: https://arxiv.org/abs/2307.02469
- Website: https://lynx-llm.github.io/
- Code: https: //github.com/bytedance/lynx-llm
In diesem Artikel führt der Autor eine systematische und umfassende Studie zum Training solcher Modelle unter quantitativen und qualitativen Aspekten durch. Für die Netzwerkstruktur wurden mehr als 20 Varianten erstellt, verschiedene LLM-Backbones und Modelldesigns wurden für die Trainingsdaten verglichen, die Auswirkungen von Daten und Stichprobenstrategien wurden im Hinblick auf Anweisungen untersucht; Die Fähigkeit, Anweisungen zu folgen, wurde untersucht. Für Benchmarks schlägt der Artikel erstmals Open-VQA vor, ein offenes visuelles Frage-Antwort-Bewertungsset einschließlich Bild- und Videoaufgaben.
Basierend auf den experimentellen Schlussfolgerungen schlug der Autor Lynx vor, das im Vergleich zum bestehenden Open-Source-Modell im GPT4-Stil das genaueste multimodale Verständnis zeigt und gleichzeitig die beste Multimodalität beibehält.
Bewertungsschema
Anders als bei typischen visuellen Sprachaufgaben besteht die größte Herausforderung bei der Bewertung von Modellen im GPT4-Stil darin, die Leistung von Textgenerierungsfunktionen und multimodaler Verständnisgenauigkeit in Einklang zu bringen. Um dieses Problem zu lösen, schlagen die Autoren einen neuen Benchmark Open-VQA einschließlich Video- und Bilddaten vor und führen eine umfassende Bewertung aktueller Open-Source-Modelle durch.
Konkret werden zwei quantitative Bewertungsschemata übernommen:
- Sammeln Sie den Open Visual Question Answering (Open-VQA)-Testsatz, der Informationen zu Objekten, OCR, Zählen, Argumentation, Aktionserkennung und zeitlicher Reihenfolge enthält . und andere verschiedene Kategorien von Fragen. Im Gegensatz zum VQA-Datensatz, der Standardantworten enthält, sind die Antworten von Open-VQA offenes Ergebnis. Um die Leistung bei Open-VQA zu bewerten, wird GPT4 als Diskriminator verwendet und die Ergebnisse stimmen zu 95 % mit der menschlichen Bewertung überein.
- Darüber hinaus verwendete der Autor den von mPLUG-owl [1] bereitgestellten OwlEval-Datensatz, um die Textgenerierungsfähigkeit des Modells zu bewerten. Obwohl er nur 50 Bilder und 82 Fragen enthält, deckt er die Generierung von Geschichten und Werbung ab. Codegenerierung usw. Verschiedene Fragen und Rekrutierung menschlicher Kommentatoren, um die Leistung verschiedener Modelle zu bewerten.
Fazit
Um die Trainingsstrategie multimodaler LLMs eingehend zu untersuchen, untersucht der Autor hauptsächlich die Netzwerkstruktur (Präfix-Feinabstimmung/Queraufmerksamkeit) und Trainingsdaten (Datenauswahl und -kombination). Verhältnis), Anweisungen (Einzelanweisung/Mehr als zwanzig Varianten wurden in verschiedenen Aspekten wie Diversifikationsanzeige festgelegt), LLMs-Modell (LLaMA [5]/Vicuna [6]), Bildpixel (420/224) usw. und die Folgende Hauptschlussfolgerungen wurden durch Experimente gezogen:
- Multimodale LLMs haben eine schlechtere Fähigkeit, Anweisungen zu befolgen als LLMs. Zum Beispiel tendiert InstructBLIP [2] dazu, unabhängig von Eingabeanweisungen kurze Antworten zu generieren, während andere Modelle dazu neigen, unabhängig von Anweisungen lange Sätze zu generieren, was nach Ansicht der Autoren auf das Fehlen hochwertiger und vielfältiger Multi- Modalität, die durch Befehlsdaten verursacht wird.
- Die Qualität der Trainingsdaten ist entscheidend für die Leistung des Modells. Basierend auf den Ergebnissen von Experimenten mit verschiedenen Daten wurde festgestellt, dass die Verwendung einer kleinen Menge hochwertiger Daten eine bessere Leistung erbringt als die Verwendung großer, verrauschter Daten. Der Autor glaubt, dass dies der Unterschied zwischen generativem Training und kontrastivem Training ist, da generatives Training direkt die bedingte Verteilung von Wörtern lernt und nicht die Ähnlichkeit zwischen Text und Bildern. Für eine bessere Modellleistung müssen daher zwei Dinge in Bezug auf die Daten erfüllt sein: 1) hochwertiger, glatter Text enthalten; 2) Text- und Bildinhalte sind gut aufeinander abgestimmt.
- Quests und Eingabeaufforderungen sind entscheidend für die Zero-Shot-Fähigkeit. Durch die Verwendung verschiedener Aufgaben und Anweisungen kann die Fähigkeit des Modells zur Erzeugung von Nullschüssen bei unbekannten Aufgaben verbessert werden, was mit Beobachtungen in Klartextmodellen übereinstimmt.
- Es ist wichtig, Korrektheit und Sprachgenerierungsfähigkeiten in Einklang zu bringen. Wenn das Modell bei nachgelagerten Aufgaben (z. B. VQA) untertrainiert ist, ist es wahrscheinlicher, dass es fabrizierte Inhalte generiert, die nicht mit der visuellen Eingabe übereinstimmen, und wenn das Modell bei nachgelagerten Aufgaben übertrainiert ist, generiert es tendenziell kurze Antworten und wird nicht in der Lage sein, Benutzeranweisungen zu befolgen, die zu längeren Antworten führen.
- Präfix-Finetuning (PT) ist derzeit die beste Lösung für die multimodale Anpassung von LLMs. In Experimenten kann das Modell mit Präfix-Feinabstimmungsstruktur die Fähigkeit verbessern, verschiedenen Anweisungen schneller zu folgen und ist einfacher zu trainieren als die Modellstruktur mit Kreuzaufmerksamkeit (CA). (Präfix-Tuning und Queraufmerksamkeit sind zwei Modellstrukturen, Einzelheiten finden Sie im Einführungsabschnitt zum Lynx-Modell.) -Style-Modell mit Präfix-Feinabstimmung. In der ersten Phase werden etwa 120 Millionen Bild-Text-Paare verwendet, um visuelle und sprachliche Einbettungen auszurichten. In der zweiten Phase werden 20 Bilder oder Videos für multimodale Aufgaben und Daten zur Verarbeitung natürlicher Sprache (NLP) verwendet, um die Modelle anzupassen Befehlsfolgefähigkeiten.
Bilder
Die Gesamtstruktur des Lynx-Modells ist in Abbildung 1 oben dargestellt.
Die visuelle Eingabe wird vom visuellen Encoder verarbeitet, um visuelle Token (Token) $$W_v$$ zu erhalten. Nach der Zuordnung wird sie mit den Befehls-Tokens $$W_l$$ als Eingabe von LLMs gespleißt Die Struktur wird in diesem Artikel als „Präfix-Feinabstimmung“ bezeichnet, um sie von der von Flamingo verwendeten Struktur „Queraufmerksamkeit“ zu unterscheiden [3].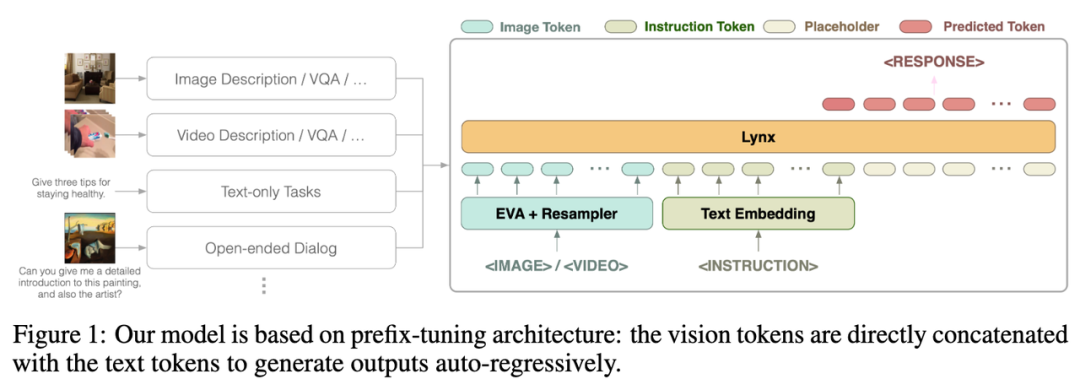 Darüber hinaus stellten die Autoren fest, dass die Schulungskosten durch das Hinzufügen von
Darüber hinaus stellten die Autoren fest, dass die Schulungskosten durch das Hinzufügen von
nach bestimmten Schichten eingefrorener LLMs weiter gesenkt werden können.
ModelleffektDer Autor bewertete die Leistung vorhandener multimodaler Open-Source-LLM-Modelle anhand der manuellen Bewertung von Open-VQA, Mme [4] und OwlEval (die Ergebnisse finden Sie in der Tabelle unten und siehe das Bewertungsdetailpapier). Es ist ersichtlich, dass das Lynx-Modell die beste Leistung bei Open-VQA-Bild- und Videoverständnisaufgaben, der manuellen OwlEval-Bewertung und Mme-Wahrnehmungsaufgaben erzielt hat. Unter diesen erreicht InstructBLIP bei den meisten Aufgaben ebenfalls eine hohe Leistung, aber seine Antwort ist zu kurz. Im Vergleich dazu liefert das Lynx-Modell in den meisten Fällen prägnante Gründe, die Antwort auf der Grundlage der richtigen Antwort zu unterstützen. freundlich (siehe Abschnitt „Fälle anzeigen“ weiter unten für einige Fälle).
1. Die Indikatorergebnisse des Open-VQA-Bildtestsatzes sind in Tabelle 1 unten aufgeführt:
Bilder
2 Die Indikatorergebnisse des Open-VQA-Videotestsatzes sind wie folgt in Tabelle 1 unten 2 dargestellt. Bilder
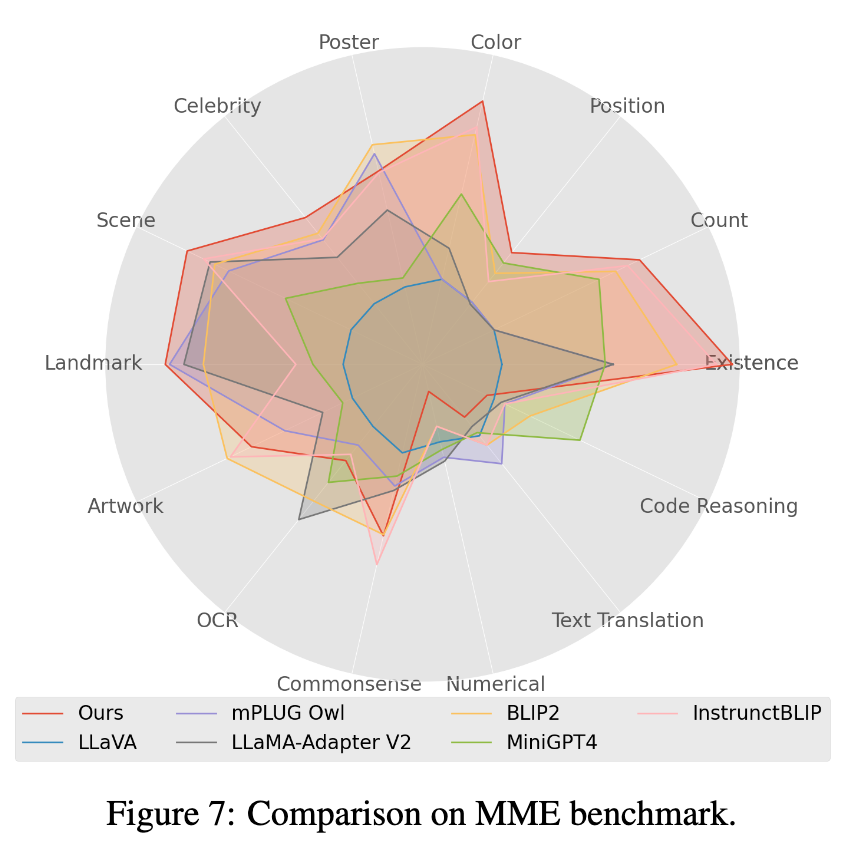
3. Wählen Sie das Modell mit der höchsten Punktzahl in Open-VQA aus, um eine manuelle Effektbewertung für den OwlEval-Bewertungssatz durchzuführen. Die Ergebnisse sind in Abbildung 4 oben dargestellt. Aus den Ergebnissen der manuellen Bewertung geht hervor, dass das Lynx-Modell die beste Leistung bei der Sprachgenerierung aufweist.
 Bilder
Bilder
4. Im Mme-Benchmarktest erzielten Wahrnehmungsklassenaufgaben die beste Leistung, wobei 7 der 14 Klassenunteraufgaben am besten abschnitten. (Detaillierte Ergebnisse finden Sie im Anhang des Papiers)
Fälle mit offenen VQA-Bildern
OwlEval.-Fälle
Open-VQA-Videofall
Zusammenfassung
In diesem Artikel ermittelt der Autor durch Experimente an mehr als zwanzig Varianten multimodaler LLMs das Lynx-Modell mit Präfix-Feinabstimmung als Hauptstruktur und gibt einen Open-VQA-Bewertungsplan mit an offene Antworten. Experimentelle Ergebnisse zeigen, dass das Lynx-Modell die genaueste multimodale Verständnisgenauigkeit bietet und gleichzeitig die besten multimodalen Generierungsfähigkeiten beibehält.
Das obige ist der detaillierte Inhalt vonDas Byte-Team schlug das Lynx-Modell vor: multimodale LLMs, die kognitive Generierungslisten-SoTA verstehen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr