
Heim >Technologie-Peripheriegeräte >KI >GPT-4 nutzt hybride Großmodelle? Untersuchungen belegen, dass die Optimierung der MoE+-Anweisungen tatsächlich zu einer besseren Leistung großer Modelle führt
GPT-4 nutzt hybride Großmodelle? Untersuchungen belegen, dass die Optimierung der MoE+-Anweisungen tatsächlich zu einer besseren Leistung großer Modelle führt

- 王林nach vorne
- 2023-07-17 16:57:251435Durchsuche
Seit der Einführung von GPT-4 sind die Menschen von seinen leistungsstarken Emergenzfähigkeiten begeistert, darunter hervorragende Sprachverständnisfähigkeiten, Generierungsfähigkeiten, logische Denkfähigkeiten usw. Diese Fähigkeiten machen GPT-4 zu einem der modernsten Modelle im maschinellen Lernen. Allerdings hat OpenAI bisher keine technischen Details zu GPT-4 bekannt gegeben.
Letzten Monat erwähnte George Hotz GPT-4 in einem Interview mit einem KI-Technologie-Podcast namens Latent Space und sagte, dass GPT-4 eigentlich ein Hybridmodell sei. Konkret sagte George Hotez, dass GPT-4 ein integriertes System verwendet, das aus 8 Expertenmodellen besteht, von denen jedes 220 Milliarden Parameter hat (etwas mehr als die 175 Milliarden Parameter von GPT-3), und dass diese Modelle auf unterschiedliche Daten und Aufgaben trainiert werden Verteilungen.

Interview von Latent Space.
Dies mag nur eine Spekulation von George Hotz sein, aber dieses Modell hat durchaus eine gewisse Legitimität. Kürzlich bestätigte ein gemeinsam von Forschern von Google, UC Berkeley, MIT und anderen Institutionen veröffentlichter Artikel, dass die Kombination aus Hybrid-Expertenmodell (MoE) und Instruktionsoptimierung die Leistung großer Sprachmodelle (LLM) erheblich verbessern kann. ? . Fügen Sie in diesem Fall lernbare Parameter zu großen Sprachmodellen (LLM) hinzu. Instruction Tuning ist eine Technik, um LLM darin zu trainieren, Anweisungen zu befolgen. Die Studie ergab, dass MoE-Modelle stärker von der Befehlsoptimierung profitierten als dichte Modelle und schlug daher vor, MoE und Befehlsoptimierung zu kombinieren.
 Die Studie wurde empirisch in drei experimentellen Umgebungen durchgeführt, darunter
Die Studie wurde empirisch in drei experimentellen Umgebungen durchgeführt, darunter
direkte Feinabstimmung einer einzelnen Downstream-Aufgabe ohne Anweisungsoptimierung;
Downstream-Aufgabe nach Anweisungsoptimierung. Durchführung von wenigen Schüssen im Kontext oder Zero-Shot-Generalisierung; weitere Feinabstimmung einzelner Downstream-Aufgaben nach
Befehlsoptimierung.
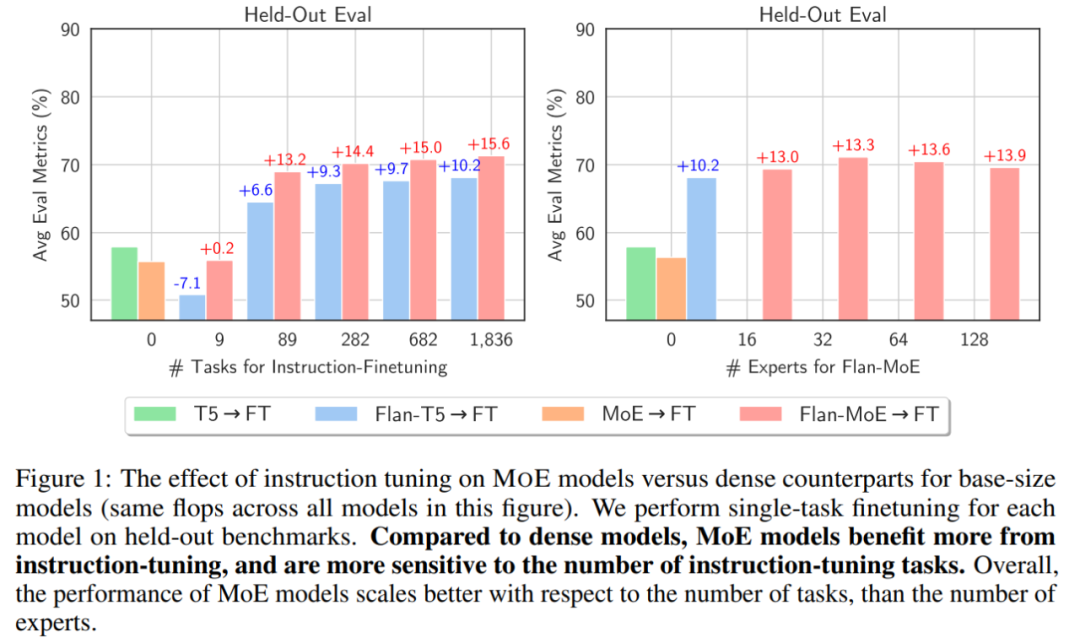
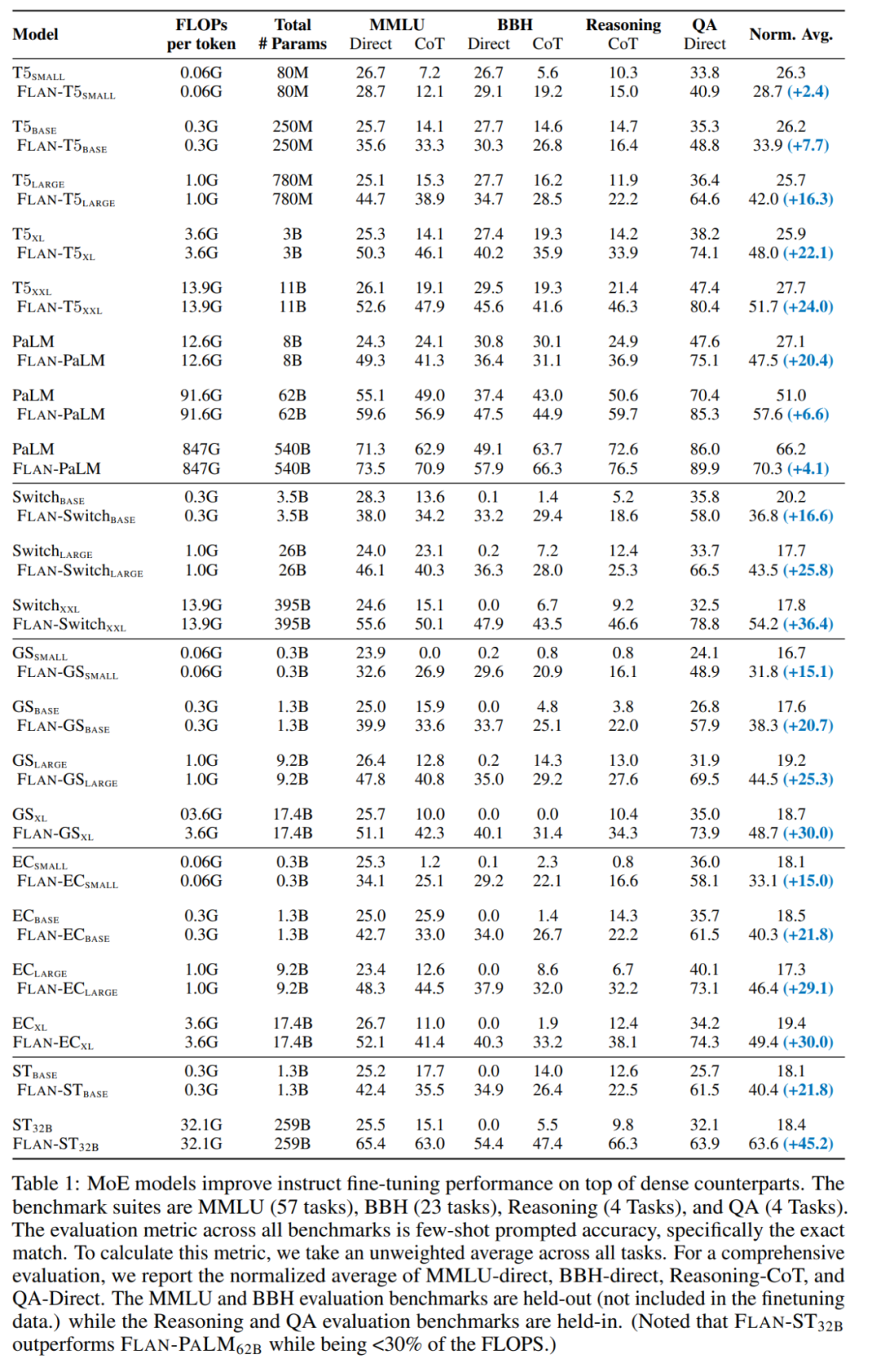
- Im ersten Fall sind MoE-Modelle im Allgemeinen dichten Modellen mit der gleichen Rechenleistung unterlegen. Mit der Einführung der Befehlsoptimierung (zweiter und dritter Fall) ist FLAN-MoE_32B (Fine-tuned LAnguage Net, abgekürzt als Flan) ein befehlsabgestimmtes Modell und Flan-MoE das Befehlsoptimierungsmodell (Excellent MoE). übertrifft FLAN-PALM_62B bei vier Benchmark-Aufgaben, nutzt aber nur ein Drittel der FLOPs.
- Wie in der Abbildung unten gezeigt, ist MoE→FT vor der Verwendung der Befehlsoptimierung nicht so gut wie T5→FT. Nach der Befehlsoptimierung übertrifft Flan-MoE→FT Flan-T5→FT. Der Nutzen von MoE durch die Befehlsoptimierung (+15,6) ist größer als der des dichten Modells (+10,2):
- Bild
Es scheint, dass GPT-4 tatsächlich eine gewisse Grundlage für die Einführung eines Hybridmodells hat Profitieren Sie von der Optimierung der Anweisungen. Erhalten Sie größere Vorteile von den Besten:
Bilder
 Methodenübersicht
Methodenübersicht
Die Forscher verwendeten MoE mit geringer Aktivierung im FLAN-MOE (ein Satz fein abgestimmter gemischter Expertenmodelle mit geringer Dichte). mit Anleitung) Modell (Mixture-of-Experts). Darüber hinaus ersetzten sie die Feedforward-Komponenten anderer Transformer-Schichten durch MoE-Schichten.
 Jede MoE-Schicht kann als „Experte“ verstanden werden. Anschließend werden diese Experten mithilfe der Softmax-Aktivierungsfunktion modelliert, um eine Wahrscheinlichkeitsverteilung zu erhalten.
Jede MoE-Schicht kann als „Experte“ verstanden werden. Anschließend werden diese Experten mithilfe der Softmax-Aktivierungsfunktion modelliert, um eine Wahrscheinlichkeitsverteilung zu erhalten.
Obwohl jede MoE-Schicht viele Parameter hat, werden die Experten nur spärlich aktiviert. Dies bedeutet, dass für ein bestimmtes Eingabe-Token nur eine begrenzte Teilmenge von Experten die Aufgabe erledigen kann, wodurch dem Modell eine größere Kapazität zur Verfügung gestellt wird.
Für eine MoE-Schicht mit E-Experten bietet dies effektiv O (E^2) verschiedene Kombinationen von Feedforward-Netzwerken, was eine größere Rechenflexibilität ermöglicht.
Da es sich bei FLAN-MoE um ein auf Anweisungen abgestimmtes Modell handelt, ist die Optimierung von Anweisungen sehr wichtig. In dieser Studie wurde FLAN-MOE auf der Grundlage des kollektiven FLAN-Datensatzes verfeinert. Darüber hinaus wurde in dieser Studie die Eingabesequenzlänge jedes FLAN-MOE auf 2048 und die Ausgabelänge auf 512 angepasst.
Experimente und Analyse
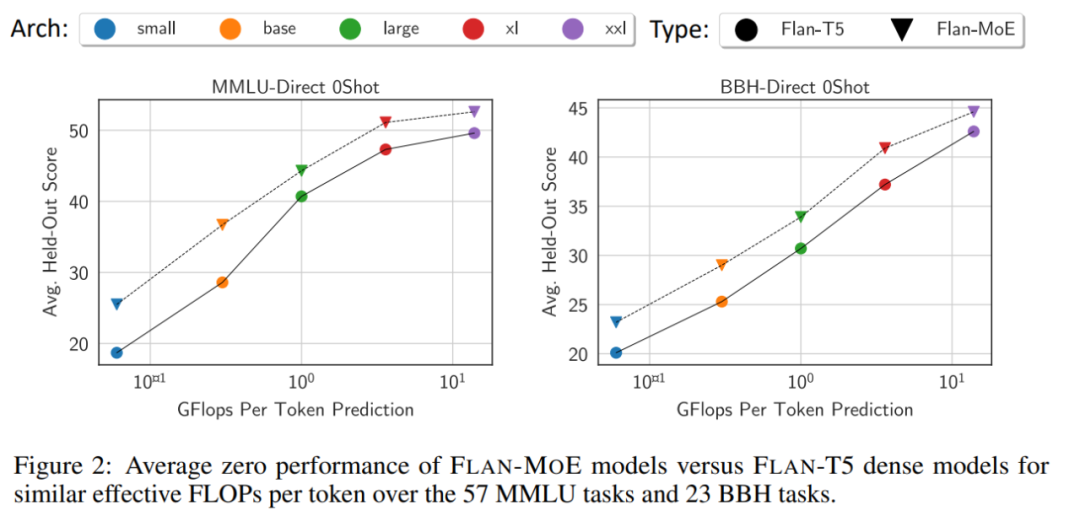
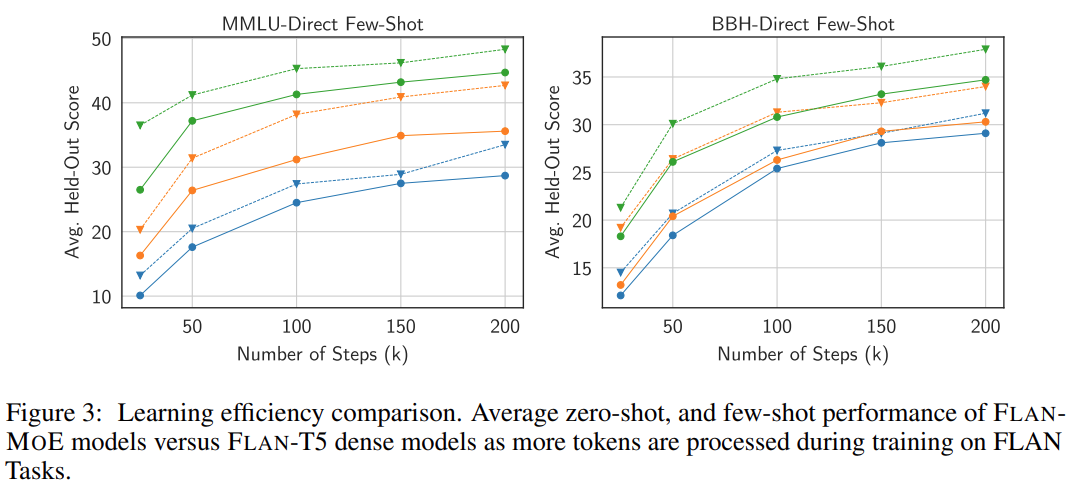
Im Durchschnitt übertrifft Flan-MoE sein dichtes Gegenstück (Flan-T5) auf allen Modellmaßstäben, ohne dass zusätzliche Berechnungen erforderlich sind.
 Bilder
Bilder
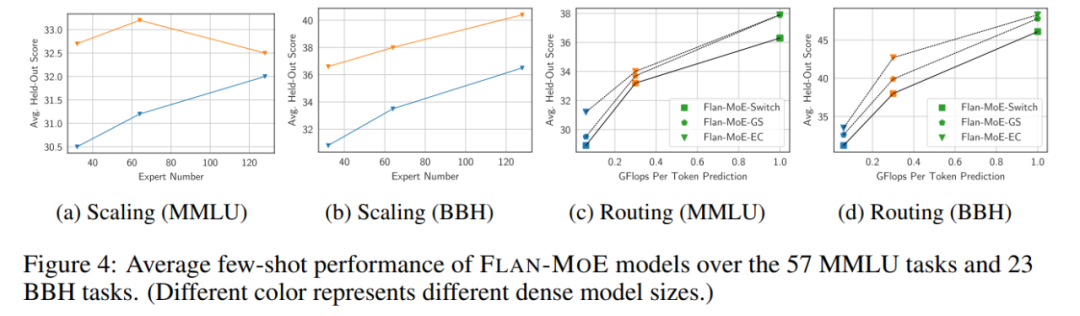
Anzahl der Experten. Abbildung 4 zeigt, dass das Modell mit zunehmender Anzahl von Experten zunächst von einem umfangreicheren Satz spezialisierter Subnetzwerke profitiert, von denen jedes in der Lage ist, eine andere Aufgabe oder einen anderen Aspekt im Problembereich zu bearbeiten. Dieser Ansatz macht MoE äußerst anpassungsfähig und effizient bei der Bewältigung komplexer Aufgaben, wodurch die Leistung insgesamt verbessert wird. Da jedoch die Zahl der Experten weiter zunimmt, beginnen die Modellleistungszuwächse abzunehmen und erreichen schließlich einen Sättigungspunkt.
 Bilder
Bilder
Abbildung 3 und Tabelle 1 untersuchen im Detail, wie sich unterschiedliche Routing-Entscheidungen auf die Leistung der Befehlsoptimierung auswirken: Durch den Vergleich zwischen FLAN-Switch- und FLAN-GS-Strategien kann gefolgert werden, dass die Aktivierung von mehr Experten die Leistung verbessert über vier Benchmarks hinweg. Unter diesen Benchmarks weist das MMLU-Direct-Modell die deutlichste Verbesserung auf und stieg von 38,0 % auf 39,9 % für BASE/LARGE-Modelle.
Bemerkenswert ist, dass die Befehlsoptimierung die Leistung des MoE-Modells bei der Beibehaltung von MMLU, BBH sowie internen QA- und Inferenz-Benchmarks im Vergleich zu dichten Modellen gleicher Kapazität erheblich steigerte. Diese Vorteile werden bei größeren MoE-Modellen noch verstärkt. Beispielsweise verbessert die Befehlsoptimierung die Leistung für ST_32B um 45,2 %, während diese Verbesserung für FLAN-PALM_62B mit etwa 6,6 % relativ gering ist.
Bei Modellerweiterungen übertrifft Flan-MoE (Flan-ST-32B) Flan-PaLM-62B.
 Bilder
Bilder
Darüber hinaus führte die Studie einige analytische Experimente durch, indem die Gating-Funktion, das Expertenmodul und die MoE-Parameter des gegebenen Modells eingefroren wurden. Wie in Tabelle 2 unten gezeigt, zeigen experimentelle Ergebnisse, dass das Einfrieren des Expertenmoduls oder der MoE-Komponente einen negativen Einfluss auf die Modellleistung hat.
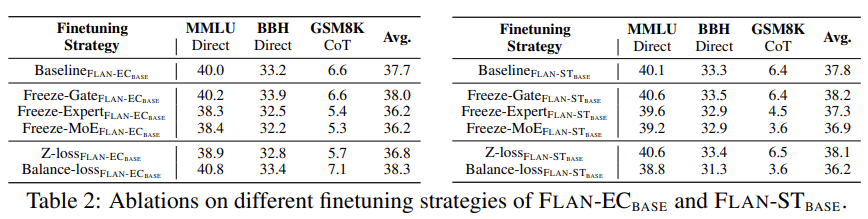
Im Gegensatz dazu wird die Freeze-Gating-Funktion die Modellleistung leicht verbessern, obwohl dies nicht offensichtlich ist. Die Forscher spekulieren, dass diese Beobachtung mit der Unteranpassung von FLAN-MOE zusammenhängt. Im Rahmen der Studie wurden auch Ablationsexperimente durchgeführt, um die in Abbildung 5 unten beschriebene Ablationsstudie zur Feinabstimmung der Dateneffizienz zu untersuchen.
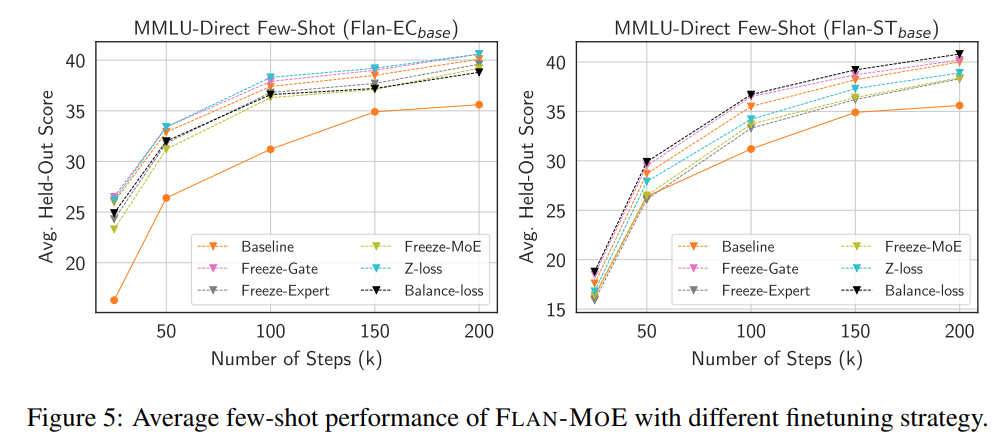
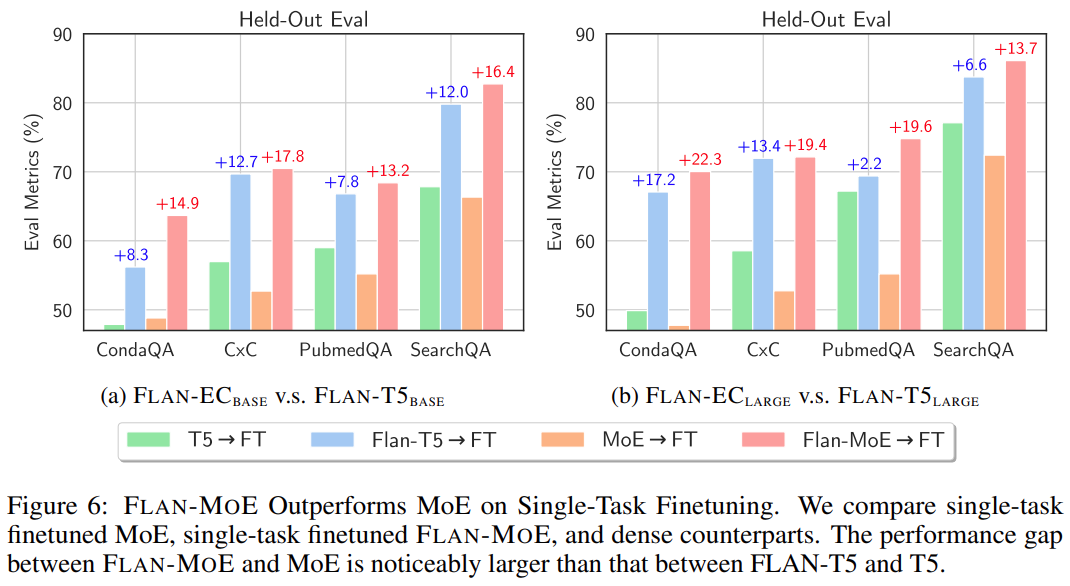
Um schließlich die Lücke zwischen der direkten Feinabstimmung von MoE und FLAN-MOE zu vergleichen, wurden in dieser Studie Experimente zur Einzeltask-Feinabstimmung von MoE, Einzeltask-Feinabstimmung von FLAN-MoE und durchgeführt dichte Modelle. Die Ergebnisse sind wie in Abbildung 6 dargestellt:
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonGPT-4 nutzt hybride Großmodelle? Untersuchungen belegen, dass die Optimierung der MoE+-Anweisungen tatsächlich zu einer besseren Leistung großer Modelle führt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr