
Heim >Technologie-Peripheriegeräte >KI >GPT-4-Modellarchitektur durchgesickert: Enthält 1,8 Billionen Parameter und verwendet ein Hybrid-Expertenmodell
GPT-4-Modellarchitektur durchgesickert: Enthält 1,8 Billionen Parameter und verwendet ein Hybrid-Expertenmodell

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-16 11:53:22937Durchsuche

Nachrichten vom 13. Juli, ausländische Medien Semianalysis enthüllte kürzlich das von OpenAI im März dieses Jahres veröffentlichte GPT-4-Großmodell, einschließlich der GPT-4-Modellarchitektur, Trainings- und Inferenzinfrastruktur, Parametervolumen und Trainingsdatensatz, Anzahl der Token, Kosten, Expertenmischung und andere spezifische Parameter und Informationen.
▲ Bildquelle Semianalysis
Ausländische Medien gaben an, dass GPT-4 insgesamt 1,8 Billionen Parameter in 120 Schichten enthält, während GPT-3 nur etwa 175 Milliarden Parameter aufweist. Um die Kosten angemessen zu halten, verwendet OpenAI zum Erstellen ein hybrides Expertenmodell.
IT Home Hinweis: Mixture of Experts ist eine Art neuronales Netzwerk. Das System trennt und trainiert mehrere Modelle basierend auf Daten. Nach der Ausgabe jedes Modells integriert und gibt das System diese Modelle in einer einzigen Aufgabe aus.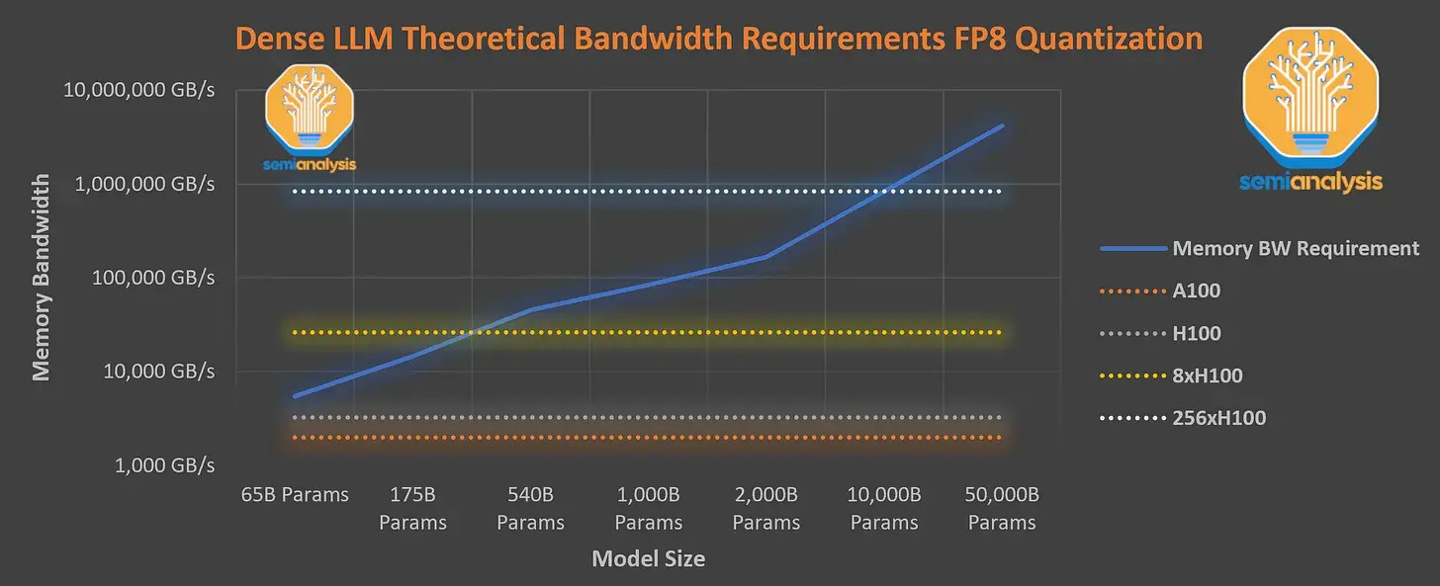
GPT-4 16 gemischte Expertenmodelle (Expertenmischung) mit jeweils 111 Milliarden Parametern verwendet und jede Vorwärtspassroute zwei Expertenmodelle durchläuft .
Darüber hinaus verfügt es über 55 Milliarden gemeinsame Aufmerksamkeitsparameter und wurde mithilfe eines Datensatzes trainiert, der 13 Billionen Token enthält. Die Token sind nicht eindeutig und zählen je nach Anzahl der Iterationen als weitere Token. Die Kontextlänge der GPT-4-Vortrainingsphase beträgt 8 KB, und die 32 KB-Version ist das Ergebnis der Feinabstimmung von 8 KB. Ausländische Medien sagten, dass 8x H100 nicht die erforderliche Dichte bieten kann Geschwindigkeit von 33,33 Token pro Sekunde. Das Training dieses Modells erfordert also extrem hohe Inferenzkosten. Berechnet mit 1 US-Dollar pro Stunde für die physische H100-Maschine belaufen sich die Kosten für ein Training auf bis zu 63 Millionen US-Dollar (ungefähr 451 Millionen Yuan). ).In diesem Zusammenhang entschied sich OpenAI dafür, die A100-GPU in der Cloud zum Trainieren des Modells zu verwenden, wodurch die endgültigen Trainingskosten auf etwa 21,5 Millionen US-Dollar (ca. 154 Millionen Yuan) reduziert wurden, was etwas länger dauerte, um die Trainingskosten zu senken
.Das obige ist der detaillierte Inhalt vonGPT-4-Modellarchitektur durchgesickert: Enthält 1,8 Billionen Parameter und verwendet ein Hybrid-Expertenmodell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr