
Heim >Technologie-Peripheriegeräte >KI >Vollständige Datenanalyse in einem Satz: Der neue Datenassistent für große Modelle der Zhejiang-Universität macht eine Datenerfassung überflüssig
Vollständige Datenanalyse in einem Satz: Der neue Datenassistent für große Modelle der Zhejiang-Universität macht eine Datenerfassung überflüssig

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-07-13 22:01:051456Durchsuche
Um Daten zu verarbeiten, reicht dieses eine KI-Tool!
Aufgrund des großen Sprachmodells (LLM) dahinter müssen Sie nur die Daten, die Sie sehen möchten, in einem Satz beschreibenund den Rest überlassen!
Verarbeitung, Analyse und sogar Visualisierung können ganz einfach durchgeführt werden, Sie müssen nicht einmal die Sammlung selbst durchführen.
 Bilder
Bilder
Dieser LLM-basierte KI-Datenassistent heißt Data-Copilot und wurde vom Team der Zhejiang-Universität entwickelt.
Der Vorabdruck des entsprechenden Papiers wurde veröffentlicht.
Der folgende Inhalt wird vom Mitwirkenden bereitgestellt
Verschiedene Branchen wie Finanzen, Meteorologie und Energie erzeugen täglich große Mengen heterogener Daten. Es besteht dringender Bedarf an einem Tool zur effektiven Verwaltung, Verarbeitung und Anzeige dieser Daten.
DataCopilot verwaltet und verarbeitet riesige Datenmengen autonom durch den Einsatz großer Sprachmodelle, um vielfältige Benutzerabfragen, Berechnungen, Vorhersagen, Visualisierungs- und andere Anforderungen zu erfüllen.
Sie müssen nur Text eingeben, um DataCopilot die Daten mitzuteilen, die Sie sehen möchten, ohne langwierige Vorgänge. Sie müssen keinen eigenen Code schreiben DataCopilot wandelt die Originaldaten selbstständig in ein Visualisierungsergebnis um, das der Absicht des Benutzers am besten entspricht.
Um einen universellen Rahmen zu schaffen, der verschiedene Formen datenbezogener Aufgaben abdeckt, schlug das Forschungsteam Data-Copilot vor.
Dieses Modell löst die Probleme des Datenleckrisikos, der schlechten Rechenleistung und der Unfähigkeit, komplexe Aufgaben zu bewältigen, die durch die einfache Verwendung von LLM verursacht werden.
 Bilder
Bilder
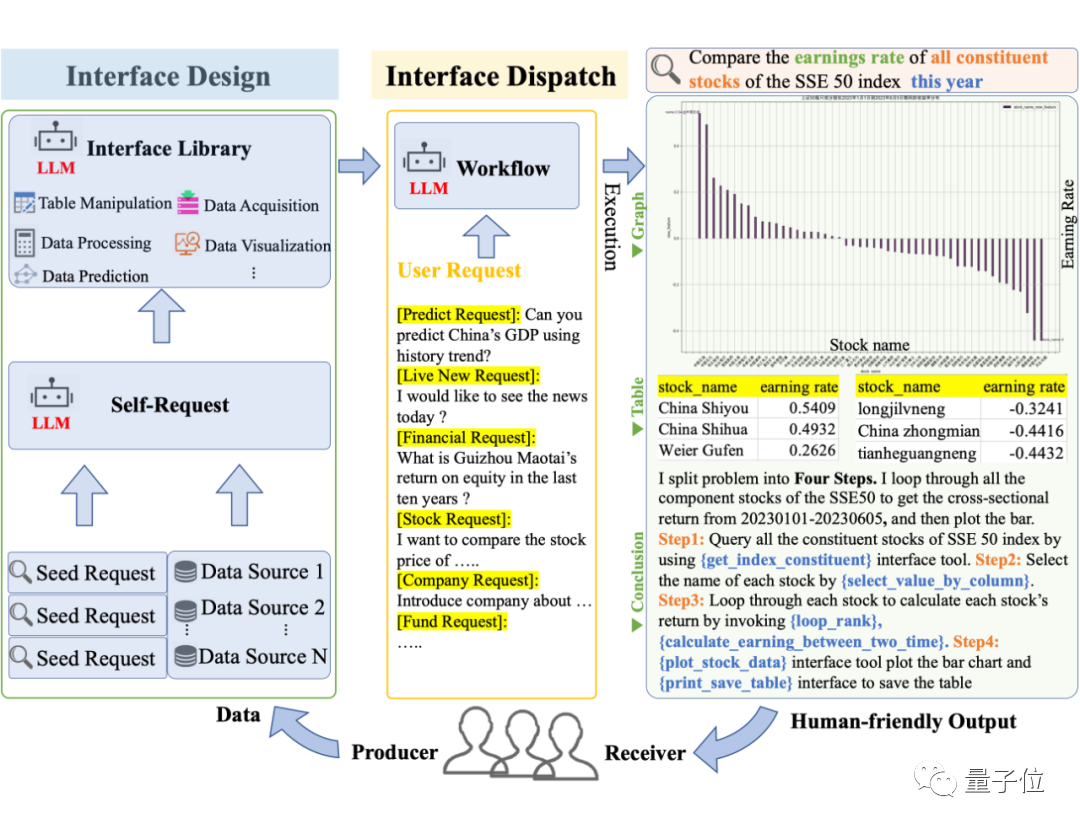
Bei komplexen Anfragen entwirft und plant Data-Copilot selbstständig unabhängige Schnittstellen, um einen Workflow aufzubauen, der den Absichten des Benutzers entspricht. Ohne
menschliche Hilfekann es Rohdaten aus verschiedenen Quellen und in verschiedenen Formaten geschickt in humanisierte Ausgaben wie Grafiken, Tabellen und Text umwandeln.
Bilder Zu den Hauptbeiträgen des Data-Copilot-Projekts gehören:
Zu den Hauptbeiträgen des Data-Copilot-Projekts gehören:
- Ermöglicht die autonome Verwaltung, Verarbeitung, Analyse, Vorhersage und Visualisierung von Daten und kann Rohdaten in informative Ergebnisse umwandeln, die den Absichten der Benutzer am besten entsprechen.
- Tools haben die doppelte
- Identität von Designer und Scheduler, einschließlich zweier Prozesse: dem Designprozess des Schnittstellentools (Designer) und dem Planungsprozess (Scheduler). Die Data-Copilot-Demo basiert auf chinesischen Finanzmarktdaten.
- Entwerfen und führen Sie den Workflow unabhängig aus
Sie können sich auch das folgende Beispiel ansehen, um die Leistung von Data-Copilot zu sehen:
Wie hoch ist die jährliche Wachstumsrate des Nettogewinns aller Aktien von Data-Copilot? Shanghai Stock Exchange 50 Index im ersten Quartal dieses Jahres
Data-Copilot Wir haben unabhängig einen solchen Workflow entworfen:
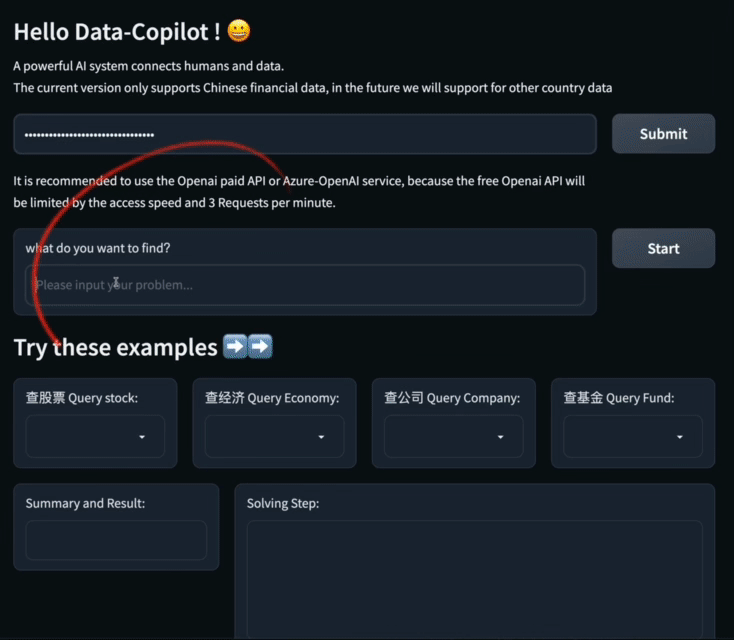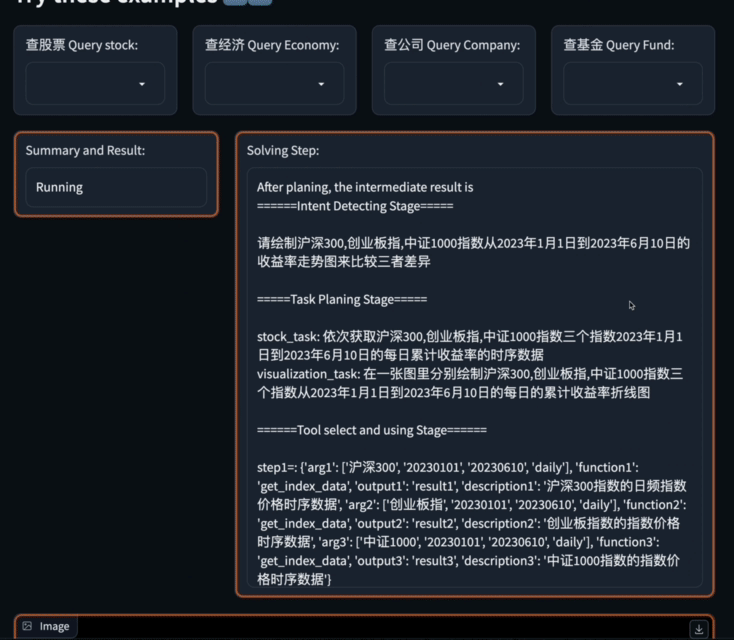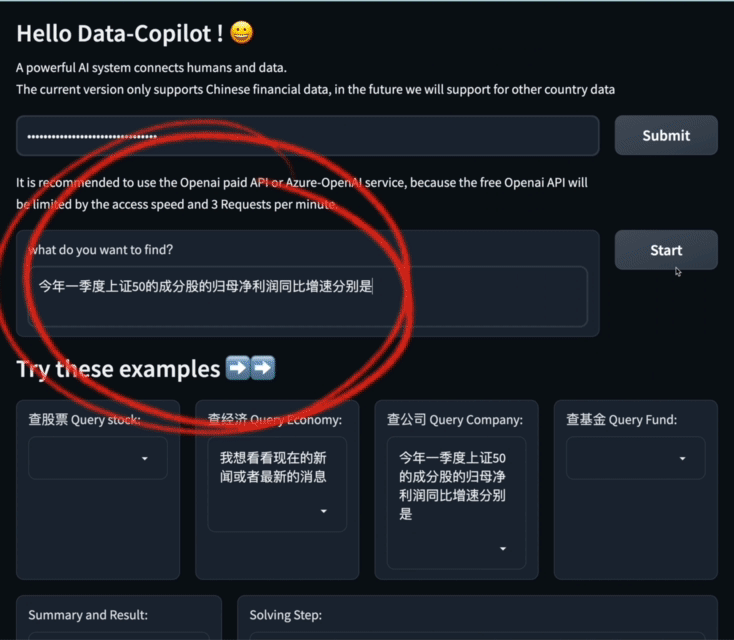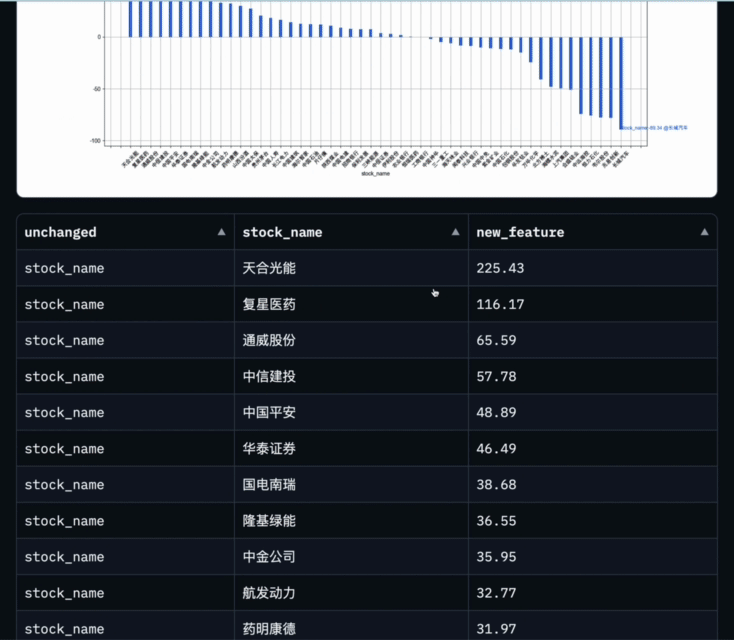
Bilder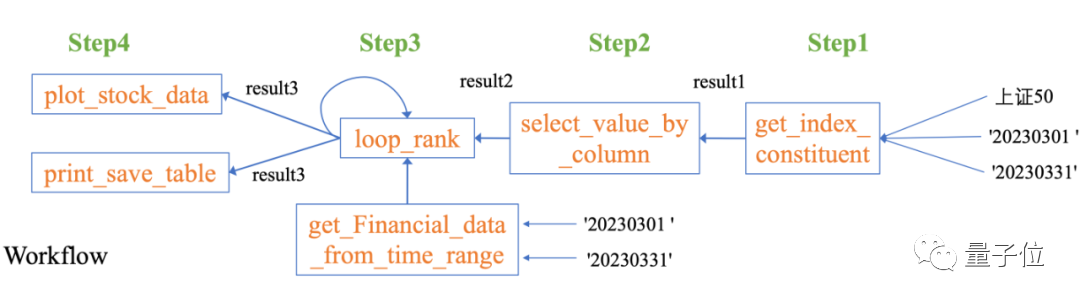 Um dieses komplexe Problem anzugehen, verwendet Data-Copilot die Schnittstelle „loop_rank“, um mehrere Schleifenabfragen zu implementieren .
Um dieses komplexe Problem anzugehen, verwendet Data-Copilot die Schnittstelle „loop_rank“, um mehrere Schleifenabfragen zu implementieren .
Data-Copilot hat dieses Ergebnis erhalten, nachdem dieser Workflow ausgeführt wurde:
Die Abszisse ist der Name jedes Komponentenbestands und die Ordinate ist die jährliche Wachstumsrate des Nettogewinns im ersten Quartal
Bilder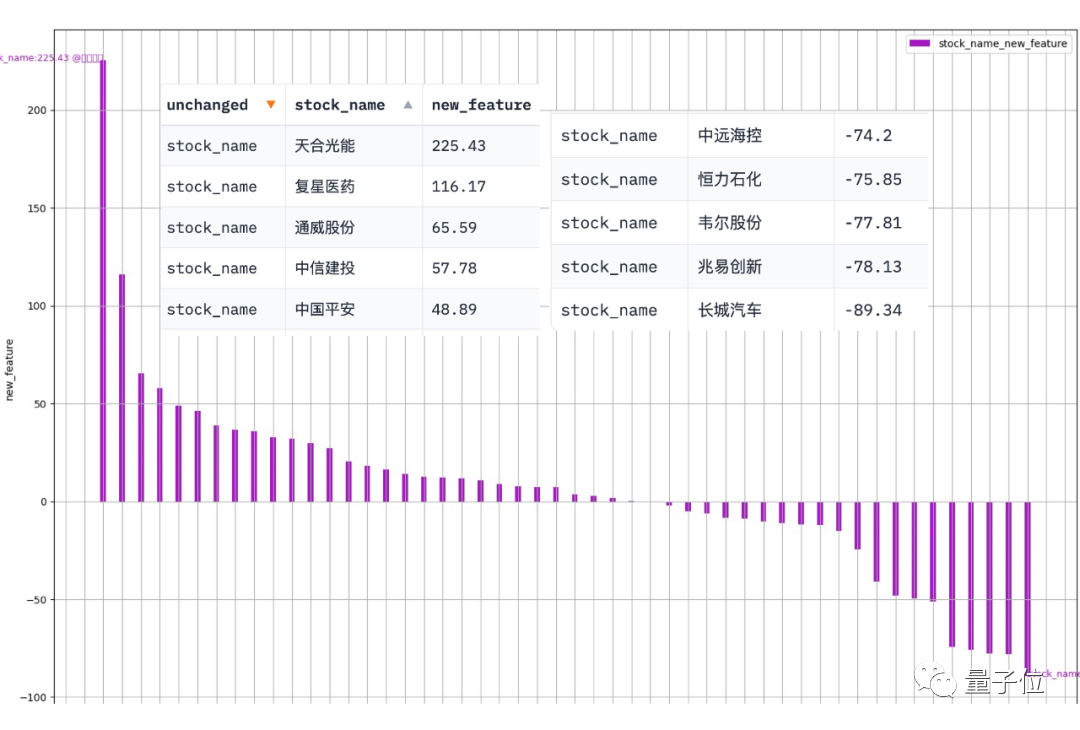 Zusätzlich zu den allgemeinen Datenverarbeitungsprozessen kann Data-Copilot auch vielfältige Workflows generieren.
Zusätzlich zu den allgemeinen Datenverarbeitungsprozessen kann Data-Copilot auch vielfältige Workflows generieren.
Das Forschungsteam testete Data-Copilot in zwei Workflow-Modi: prädiktiv und parallel.
Prognose-Workflow
Data-Copilot kann auch andere Teile als bekannte Daten vorhersagen. Geben Sie beispielsweise die folgende Frage ein:
Prognostizieren Sie das vierteljährliche BIP Chinas in den folgenden vier Quartalen. Data-Copilot setzt diesen Workflow ein:
Historische Daten abrufen BIP-Daten → Verwenden Sie ein lineares Regressionsmodell, um die Zukunft vorherzusagen → Ausgabetabelle
Bild
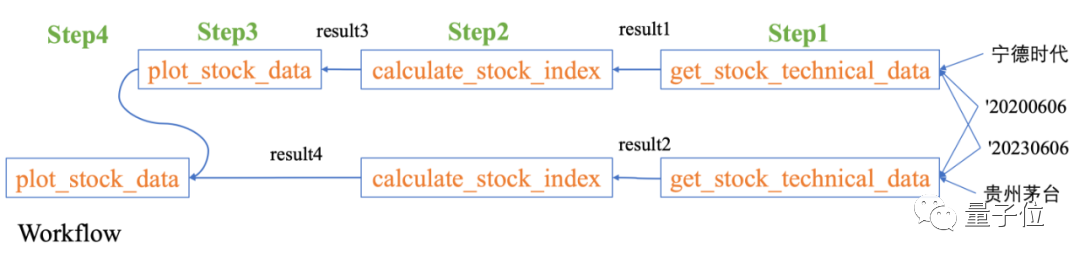
Ich möchte die Kurs-Gewinn-Verhältnisse von CATL und Kweichow Moutai in den letzten drei Jahren sehen Der entsprechende Workflow ist: Aktienkursdaten abrufen → Zugehörige Indizes berechnen → Generieren Sie Diagramme Die verwandte Arbeit der beiden Bestände ist gleichzeitig parallel, und das endgültige Diagramm sieht wie folgt aus: Data-Copilot ist eine allgemeine Methode großes Sprachmodellsystem mit Schnittstellendesign und Schnittstellenplanung. Es gibt zwei Hauptphasen. Data-Copilot erreicht eine hochautomatisierte Datenverarbeitung und -visualisierung durch automatisches Generieren von Anfragen und unabhängiges Entwerfen von Schnittstellen, um Benutzeranforderungen zu erfüllen und Benutzern Ergebnisse in verschiedenen Formen anzuzeigen. Wie im Bild oben gezeigt, muss zuerst die Datenverwaltung implementiert werden, und für den ersten Schritt sind Schnittstellentools erforderlich. Data-Copilot wird eine Vielzahl von Schnittstellen als Datenverwaltungstools entwerfen. Bei den Schnittstellen handelt es sich um Module bestehend aus natürlicher Sprache (funktionale Beschreibung) und Code (Implementierung), die für Aufgaben wie Datenerfassung und -verarbeitung zuständig sind. Wie unten gezeigt: Das von Data-Copilot selbst entwickelte Schnittstellentool für die Datenverarbeitung. Jede Schnittstelle verfügt über eine klare und explizite Funktionsbeschreibung. Wie in der Abbildung oben für die beiden Abfragen dargestellt, bildet Data-Copilot einen Workflow von Daten zu Ergebnissen in mehreren Formularen durch Planung und Aufruf verschiedener Schnittstellen in Echtzeitanforderungen. Papieradresse: https://arxiv.org/abs/2306.07209 HuggingFace DEMO: https://huggingface .co/spaces/zwq2018/Data-Copilot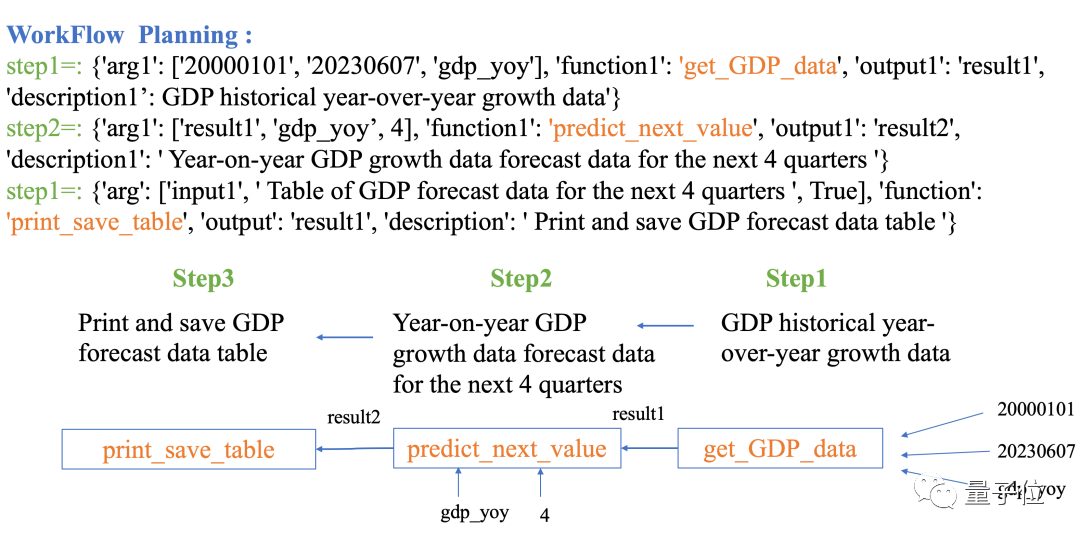 Die Ergebnisse nach der Ausführung sind wie folgt:
Die Ergebnisse nach der Ausführung sind wie folgt: 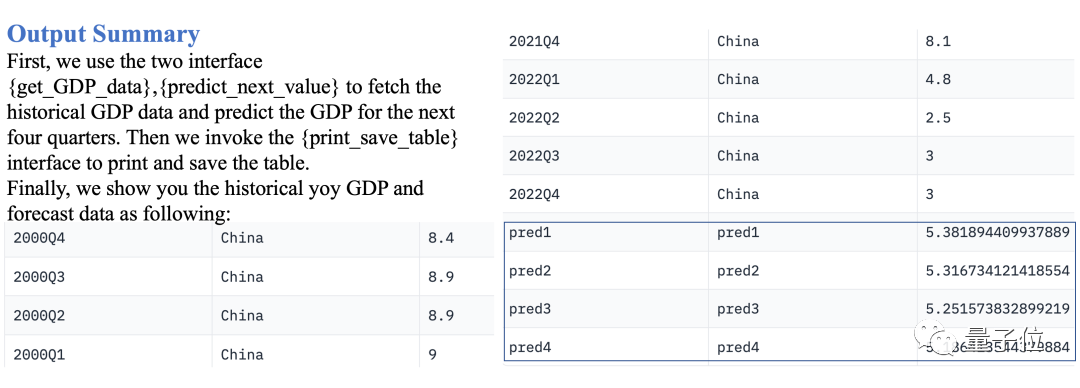 Bilder
BilderParalleler Workflow
 Bild
Bild 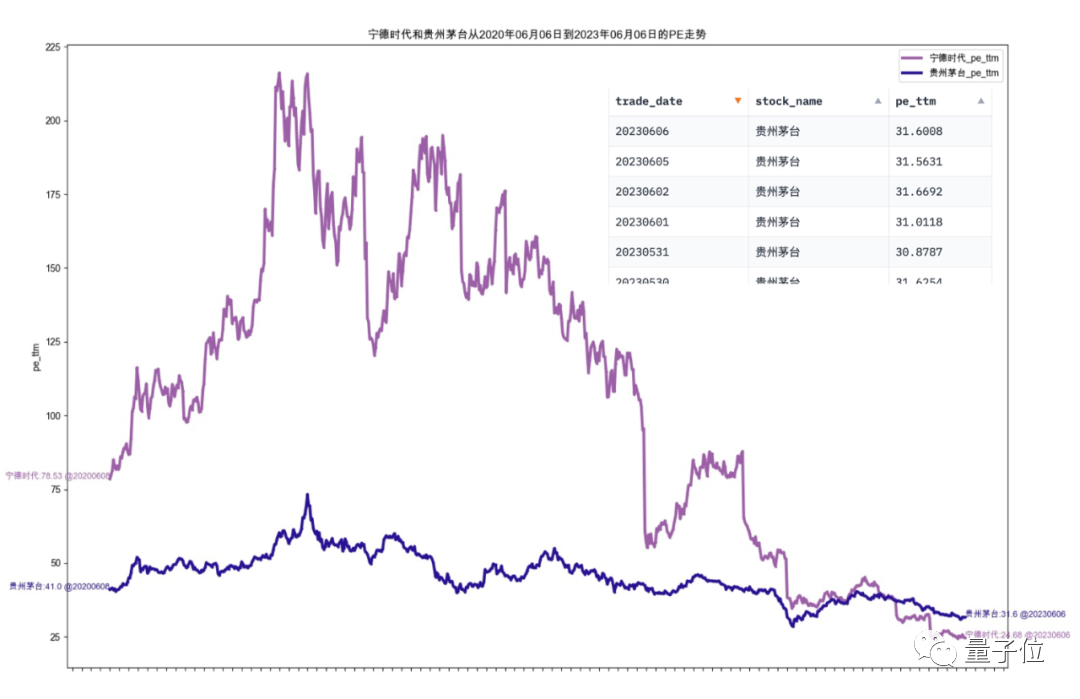 Bild
Bild Hauptmethode
 Bilder
BilderSchnittstellendesign
 Data-Copilot führt zunächst eine Absichtsanalyse durch, um die Anfrage des Benutzers genau zu verstehen. Sobald die Absicht des Benutzers genau verstanden ist, plant Data-Copilot einen angemessenen Arbeitsablauf, um die Anfrage des Benutzers zu bearbeiten. Data-Copilot generiert einen JSON-Code mit festem Format, der jeden Planungsschritt darstellt, z. .
Data-Copilot führt zunächst eine Absichtsanalyse durch, um die Anfrage des Benutzers genau zu verstehen. Sobald die Absicht des Benutzers genau verstanden ist, plant Data-Copilot einen angemessenen Arbeitsablauf, um die Anfrage des Benutzers zu bearbeiten. Data-Copilot generiert einen JSON-Code mit festem Format, der jeden Planungsschritt darstellt, z. .
Das obige ist der detaillierte Inhalt vonVollständige Datenanalyse in einem Satz: Der neue Datenassistent für große Modelle der Zhejiang-Universität macht eine Datenerfassung überflüssig. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr