
Heim >Technologie-Peripheriegeräte >KI >Ein neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen
Ein neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen

- 王林nach vorne
- 2023-07-09 23:17:201218Durchsuche
Nachdem das Vincent-Grafikmodell Stable Diffusion als Open Source verfügbar ist, wurde die „KI-Kunst“ vollständig demokratisiert. Nur mit einer Consumer-Grafikkarte können sehr schöne Bilder erstellt werden.
Im Bereich der Text-zu-Video-Konvertierung ist Runway derzeit das einzige hochwertige kommerzielle Gen-2-Modell, das vor nicht allzu langer Zeit auf den Markt gebracht wurde, und es gibt kein Modell, das in der Open-Source-Branche mithalten kann.
Kürzlich hat ein Autor auf Huggingface ein Text-zu-Video-Synthesemodell Zeroskop_v2 veröffentlicht, das auf der Grundlage des ModelScope-Text-zu-Video-Synthesemodells mit 1,7 Milliarden Parametern entwickelt wurde.
 Bilder
Bilder
Modelllink: https://huggingface.co/cerspense/zerscope_v2_576w
Im Vergleich zur Originalversion weist das von Zeroskop generierte Video kein Wasserzeichen auf und die Glätte und Auflösung sind verbessert Verbessert zur Anpassung an das Seitenverhältnis 16:9.
Entwickler Cerspense sagte, sein Ziel sei es, mit Gen-2 als Open Source zu konkurrieren, das heißt, während die Qualität des Modells verbessert wird, kann es auch von der Öffentlichkeit frei genutzt werden.
Zeroskop_v2 umfasst zwei Versionen. Unter anderem kann Zeroskop_v2 567w schnell ein Video mit einer Auflösung von 576 x 320 Pixeln und einer Bildrate von 30 Bildern/Sekunde erstellen. Es kann zur schnellen Überprüfung von Videokonzepten verwendet werden und erfordert nur etwa 7,9 GB Videospeicher zur Ausführung.
Verwenden Sie Zeroskop_v2 XL, um hochauflösende Videos mit einer Auflösung von 1024 x 576 zu generieren und etwa 15,3 GB Videospeicher zu belegen.
Zeroskop kann auch mit dem Musikgenerierungstool MusicGen verwendet werden, um schnell ein rein originelles Kurzvideo zu erstellen.
Das Training des Zeroskop-Modells verwendet 9923 Videoclips (Clips) und 29769 kommentierte Frames, wobei jeder Clip 24 Frames umfasst. Offset-Rauschen umfassen zufällige Verschiebungen von Objekten innerhalb von Videobildern, leichte Änderungen im Bild-Timing oder kleine Verzerrungen.
Die Einführung von Rauschen während des Trainings kann das Verständnis des Modells für die Datenverteilung verbessern, sodass es vielfältigere und realistischere Videos erstellen und Änderungen in Textbeschreibungen effektiver erklären kann.
So verwenden Sie
Verwenden Sie Stable Diffusion WebUI
Laden Sie die Gewichtsdatei im zs2_XL-Verzeichnis auf Huggingface herunter und legen Sie sie dann im Stable-Diffusion-WebuimodelsModelScopet2v-Verzeichnis ab.
Beim Erstellen von Videos beträgt der empfohlene Intensitätswert für die Rauschunterdrückung 0,66 bis 0,85. drive/1TsZmatSu1-1lNBeOqz3_9Zq5P2c0xTTq?usp=sharing
Klicken Sie zunächst unter Schritt 1 auf die Schaltfläche „Ausführen“ und warten Sie auf die Installation, die etwa 3 Minuten dauert;Bild
Bilder
Klicken Sie auf die Schaltfläche „Ausführen“ neben dem Modell, das Sie installieren möchten. Um schnell ein 3-Sekunden-bearbeitetes Video in Colab zu erhalten, wird empfohlen, ein ZeroScope-Modell mit niedriger Auflösung (576 oder) zu verwenden 448). 
Bilder
erfordern einen Kompromiss aus längeren Ausführungszeiten, wenn Modelle mit höherer Auflösung wie Potat 1 oder ZeroScope XL ausgeführt werden. 
Wählen Sie das in Schritt 2 installierte Modell aus und möchten Sie es verwenden. Für Modelle mit höherer Auflösung werden die folgenden Konfigurationsparameter empfohlen, die keine zu lange Generierungszeit erfordern.

Als nächstes können Sie die Aufforderungswörter des Zielvideos eingeben, um den Effekt zu ändern. Sie können auch negative Aufforderungen (negative Aufforderungen) eingeben und dann auf die Schaltfläche „Ausführen“ klicken.
Nachdem Sie eine Weile gewartet haben, wird das generierte Video im Ausgabeverzeichnis abgelegt.
Bilder Derzeit steckt der Bereich Vincent Video noch in den Kinderschuhen und selbst die besten Tools können nur wenige Sekunden lange Videos erzeugen und weisen oft große visuelle Mängel auf. Aber tatsächlich hatte das vinzentinische Modell zunächst mit ähnlichen Problemen zu kämpfen, doch schon wenige Monate später erreichte es den Fotorealismus. Im Gegensatz zum vinzentinischen Graphenmodell erfordert der Videobereich jedoch beim Training und der Generierung mehr Ressourcen als Bilder. Obwohl Google Phenaki- und Imagen-Video-Modelle entwickelt hat, die hochauflösende, längere und logisch zusammenhängende Videoclips generieren können, sind diese beiden Modelle nicht für die Öffentlichkeit verfügbar; Metas Make-a-Video-Modell ist ebenfalls nicht veröffentlicht . Die derzeit verfügbaren Tools sind immer noch nur das kommerzielle Modell Gen-2 von Runway. Die Veröffentlichung von Zeroskop markiert auch die Entstehung des ersten hochwertigen Open-Source-Modells im Vincent-Videobereich. 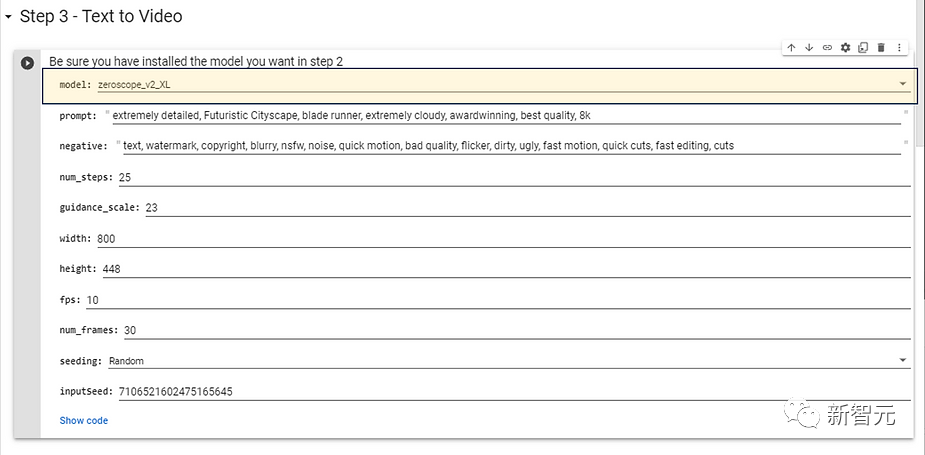
Open-Source-Wettbewerb „Vincent Video“
Das obige ist der detaillierte Inhalt vonEin neues Ventil für KI? Das erste hochwertige „Vinson Video'-Modell Zeroskop löst einen Open-Source-Krieg aus: Es kann mit mindestens 8G Videospeicher laufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr