
Heim >Technologie-Peripheriegeräte >KI >Wie erstaunlich ist das einfache Sprachkonvertierungsmodell, das den sprachübergreifenden Austausch menschlicher Stimmen und Hundegebell unterstützt und nur die nächsten Nachbarn verwendet?
Wie erstaunlich ist das einfache Sprachkonvertierungsmodell, das den sprachübergreifenden Austausch menschlicher Stimmen und Hundegebell unterstützt und nur die nächsten Nachbarn verwendet?

- 王林nach vorne
- 2023-07-04 17:57:091178Durchsuche
Die Stimmenwelt, an der KI teilnimmt, ist wirklich magisch. Sie kann nicht nur die Stimme einer Person in die einer anderen Person verwandeln, sondern auch Stimmen mit Tieren austauschen.
Wir wissen, dass das Ziel der Sprachkonvertierung darin besteht, die Quellstimme in die Zielstimme umzuwandeln und dabei den Inhalt unverändert zu lassen. Neuere Any-to-Any-Sprachkonvertierungsmethoden verbessern die Natürlichkeit und Sprecherähnlichkeit, allerdings auf Kosten einer deutlich erhöhten Komplexität. Dies bedeutet, dass Training und Inferenz teurer werden, wodurch es schwieriger wird, Verbesserungen zu bewerten und zu etablieren.
Die Frage ist, erfordert eine qualitativ hochwertige Sprachkonvertierung Komplexität? In einem aktuellen Artikel der Universität Stellenbosch in Südafrika untersuchten mehrere Forscher dieses Problem.

- Papieradresse: https://arxiv.org/pdf/2305.18975.pdf
- GitHub-Adresse: https://bshall.github.io/knn-vc/
Die Höhepunkte der Forschung sind: Sie führten K-Nearest Neighbor Speech Conversion (kNN-VC) ein, eine einfache und leistungsstarke Methode zur Sprachkonvertierung von beliebiger Sprache . Anstatt ein explizites Transformationsmodell zu trainieren, wird einfach die K-Nearest-Neighbor-Regression verwendet.
Konkret verwendeten die Forscher zunächst ein selbstüberwachtes Sprachdarstellungsmodell, um die Merkmalssequenz der Quelläußerung und der Referenzäußerung zu extrahieren, und wandelten dann jeden Frame der Quelldarstellung in den Zielsprecher um, indem sie ihn durch den nächstgelegenen ersetzten Nachbar in der Referenz und verwenden Sie schließlich einen neuronalen Vocoder, um die konvertierten Merkmale zu synthetisieren und die konvertierte Sprache zu erhalten.
Den Ergebnissen nach zu urteilen, erreicht KNN-VC trotz seiner Einfachheit eine vergleichbare oder sogar verbesserte Verständlichkeit und Sprecherähnlichkeit sowohl bei subjektiven als auch objektiven Bewertungen im Vergleich zu mehreren grundlegenden Sprachkonvertierungssystemen.
Lassen Sie uns die Wirkung der KNN-VC-Sprachkonvertierung schätzen. Zunächst wird KNN-VC auf die Konvertierung menschlicher Stimmen auf Quell- und Zielsprecher angewendet, die im LibriSpeech-Datensatz nicht zu finden sind.
... -VC unterstützt auch die sprachübergreifende Sprachkonvertierung. Zum Beispiel Spanisch nach Deutsch, Deutsch nach Japanisch, Chinesisch nach Spanisch. ? Erstaunlicherweise kann KNN-VC auch menschliche Stimmen austauschen und Hundegebell.
Quelle Hundegebell00:09
Quelle menschliche Stimme00:05
Synthetische Stimme. 400:08
S synthetische Stimme 5 00:05
Sehen wir uns an, wie KNN-VC läuft und im Vergleich zu anderen Jixian-Methoden abschneidet.
Methodenübersicht und experimentelle ErgebnisseDas Architekturdiagramm von kNN-VC ist unten dargestellt und folgt der Encoder-Konverter-Vocoder-Struktur. Zuerst extrahiert der Encoder selbstüberwachte Darstellungen der Quell- und Referenzsprache, dann ordnet der Konverter jeden Quellrahmen seinem nächsten Nachbarn in der Referenz zu und schließlich generiert der Vocoder Audiowellenformen basierend auf den konvertierten Merkmalen.
Der Encoder verwendet WavLM, der Konverter verwendet die K-Nächste-Nachbarn-Regression und der Vocoder verwendet HiFiGAN. Die einzige Komponente, die trainiert werden muss, ist der Vocoder.
Für den WavLM-Encoder verwendete der Forscher nur das vorab trainierte WavLM-Large-Modell und führte im Artikel kein Training dafür durch. Für das kNN-Transformationsmodell ist kNN nichtparametrisch und erfordert kein Training. Für den HiFiGAN-Vocoder wurde das ursprüngliche Repo des HiFiGAN-Autors zum Vocodieren der WavLM-Funktionen verwendet und war damit der einzige Teil, der geschult werden musste.
BilderIn dem Experiment verglichen die Forscher zunächst KNN-VC mit anderen Basismethoden und verwendeten die größten verfügbaren Zieldaten (etwa 8 Minuten Audio pro Sprecher), um das Sprachkonvertierungssystem zu testen.
Für KNN-VC verwendet der Forscher alle Zieldaten als Matching-Set. Bei der Basismethode ermitteln sie den Durchschnitt der Sprechereinbettungen für jede Zieläußerung.
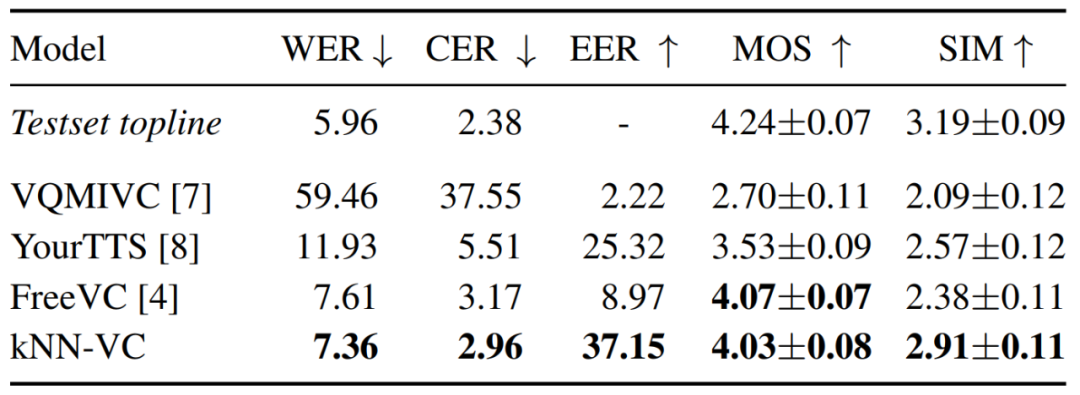
Tabelle 1 unten zeigt die Ergebnisse für Verständlichkeit, Natürlichkeit und Sprecherähnlichkeit für jedes Modell. Wie man sehen kann, erreicht kNN-VC eine ähnliche Natürlichkeit und Klarheit wie das beste Basis-FreeVC, jedoch mit deutlich verbesserter Sprecherähnlichkeit. Dies bestätigt auch die Aussage dieses Artikels: Eine hochwertige Sprachkonvertierung erfordert keine erhöhte Komplexität.
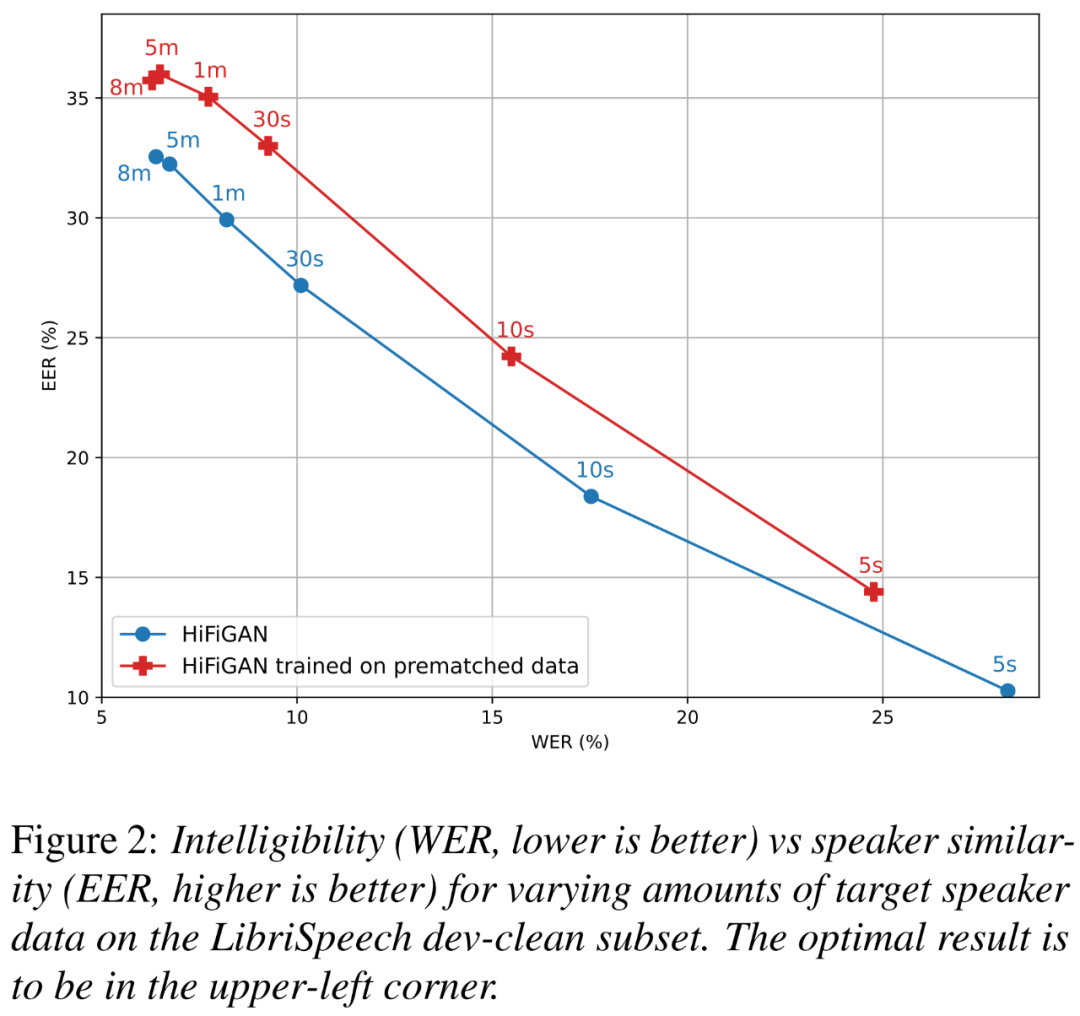
Darüber hinaus wollten die Forscher verstehen, wie viel Verbesserung durch HiFi-GAN erzielt wurde, das auf vorab abgeglichenen Daten trainiert wurde, und wie stark sich die Datengröße des Ziellautsprechers auf die Verständlichkeit und die Ähnlichkeit der Sprecher auswirkte.
Abbildung 2 unten zeigt die Beziehung zwischen WER (kleiner ist besser) und EER (höher ist besser) für zwei HiFi-GAN-Varianten bei unterschiedlichen Ziellautsprechergrößen.
 Bilder
Bilder
Heiße Kommentare von Internetnutzern
Für diese neue Sprachkonvertierungsmethode kNN-VC, die „nur nächste Nachbarn verwendet“, denken einige Leute, dass in dem Artikel ein vorab trainiertes Sprachmodell verwendet wird , daher wird „nur“ verwendet. Nicht ganz korrekt. Aber es ist unbestreitbar, dass kNN-VC immer noch einfacher ist als andere Modelle.
Die Ergebnisse belegen auch, dass kNN-VC im Vergleich zu sehr komplexen Any-to-Any-Sprachkonvertierungsmethoden genauso effektiv, wenn nicht sogar die beste ist.
 Bilder
Bilder
Einige Leute sagten auch, dass das Beispiel der Verwechslung von menschlicher Stimme und Hundegebell sehr interessant sei.
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonWie erstaunlich ist das einfache Sprachkonvertierungsmodell, das den sprachübergreifenden Austausch menschlicher Stimmen und Hundegebell unterstützt und nur die nächsten Nachbarn verwendet?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr