
Heim >Technologie-Peripheriegeräte >KI >Wie kann man Transformer BEV nutzen, um Extremsituationen des autonomen Fahrens zu meistern?
Wie kann man Transformer BEV nutzen, um Extremsituationen des autonomen Fahrens zu meistern?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-30 21:05:541234Durchsuche
Autonome Fahrsysteme müssen sich in praktischen Anwendungen verschiedenen komplexen Szenarien stellen, insbesondere Corner Cases (Extremsituationen), die höhere Anforderungen an die Wahrnehmung und Entscheidungsfähigkeit des autonomen Fahrens stellen. Corner Case bezieht sich auf extreme oder seltene Situationen, die beim tatsächlichen Fahren auftreten können, wie z. B. Verkehrsunfälle, schlechte Wetterbedingungen oder komplexe Straßenverhältnisse. Die BEV-Technologie verbessert die Wahrnehmungsfähigkeiten autonomer Fahrsysteme durch die Bereitstellung einer globalen Perspektive, die eine bessere Unterstützung bei der Bewältigung dieser Extremsituationen bieten soll. In diesem Artikel wird untersucht, wie die BEV-Technologie (Bird's Eye View) dem autonomen Fahrsystem dabei helfen kann, mit Corner Case umzugehen und die Zuverlässigkeit und Sicherheit des Systems zu verbessern.
 Pictures
Pictures
Transformer ist ein Deep-Learning-Modell, das auf dem Selbstaufmerksamkeitsmechanismus basiert und erstmals bei Aufgaben zur Verarbeitung natürlicher Sprache verwendet wurde. Die Kernidee besteht darin, über einen Selbstaufmerksamkeitsmechanismus Fernabhängigkeiten in der Eingabesequenz zu erfassen und dadurch die Fähigkeit des Modells zur Verarbeitung von Sequenzdaten zu verbessern.
Die effektive Kombination der beiden oben genannten ist auch eine sehr beliebte neue Technologie bei autonomen Fahrstrategien.
01 BEV-Analyse technischer Vorteile
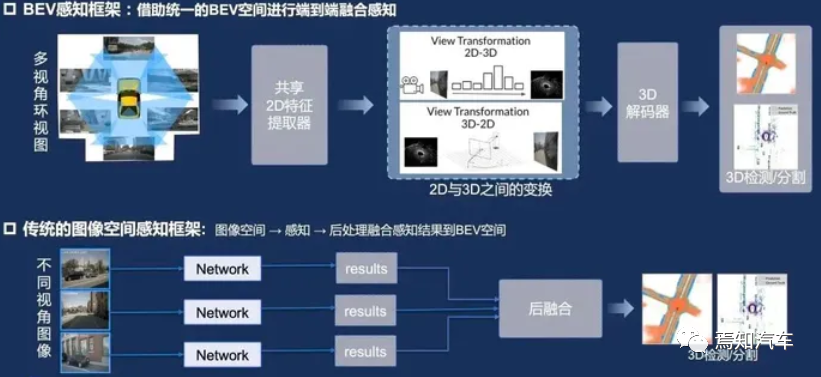
BEV ist eine Methode zur Projektion dreidimensionaler Umgebungsinformationen auf eine zweidimensionale Ebene, wobei Objekte und Gelände in der Umgebung aus einer Top-Down-Perspektive angezeigt werden. Im Bereich des autonomen Fahrens kann BEV dazu beitragen, dass das System die Umgebung besser versteht und die Genauigkeit der Wahrnehmung und Entscheidungsfindung verbessert. In der Umgebungswahrnehmungsphase kann BEV multimodale Daten wie Lidar, Radar und Kamera auf derselben Ebene zusammenführen. Diese Methode kann Okklusions- und Überlappungsprobleme zwischen Daten beseitigen und die Genauigkeit der Objekterkennung und -verfolgung verbessern. Gleichzeitig kann BEV eine klare Darstellung der Umgebung für nachfolgende Vorhersage- und Entscheidungsphasen bereitstellen, was sich positiv auf die Verbesserung der Gesamtleistung des Systems auswirkt.
1. Vergleich von Lidar- und BEV-Technologie:
Zuallererst kann die BEV-Technologie eine globale Perspektive der Umweltwahrnehmung bieten, die dazu beiträgt, die Leistung autonomer Fahrsysteme in komplexen Szenarien zu verbessern. Allerdings weist Lidar eine höhere Genauigkeit hinsichtlich Entfernung und räumlicher Informationen auf.
Zweitens erfasst die BEV-Technologie Bilder über Kameras und kann Farb- und Texturinformationen erhalten, während die Leistung von Lidar in dieser Hinsicht schwach ist.
Darüber hinaus sind die Kosten der BEV-Technologie relativ niedrig und für den kommerziellen Einsatz in großem Maßstab geeignet.
2. Vergleich zwischen BEV-Technologie und herkömmlichen Single-View-Kameras
Die herkömmliche Single-View-Kamera ist ein häufig verwendetes Fahrzeugerfassungsgerät, das Umgebungsinformationen rund um das Fahrzeug erfassen kann. Allerdings weisen Single-View-Kameras gewisse Einschränkungen hinsichtlich Sichtfeld und Informationserfassung auf. Die BEV-Technologie integriert Bilder von mehreren Kameras, um eine globale Perspektive und ein umfassenderes Verständnis der Umgebung um das Fahrzeug herum zu ermöglichen.
 Bilder
Bilder
BEV-Technologie hat bei komplexen Szenen und extremen Wetterbedingungen ein besseres Umweltbewusstsein als Einzelansichtskameras, da BEV Bildinformationen aus verschiedenen Winkeln zusammenführen kann, wodurch die Umweltbewusstseinswahrnehmung des Systems verbessert wird.
BEV-Technologie kann dem autonomen Fahrsystem dabei helfen, Eckfälle wie komplexe Straßenverhältnisse, enge oder blockierte Straßen usw. besser zu bewältigen, während Einzelansichtskameras in diesen Situationen möglicherweise nicht gut funktionieren.
Natürlich erfordert BEV im Hinblick auf Kosten und Ressourcenverbrauch die Bildwahrnehmung, -rekonstruktion und -zusammenfügung aus verschiedenen Betrachtungswinkeln und verbraucht daher mehr Rechenleistung und Speicherressourcen. Obwohl die BEV-Technologie den Einsatz mehrerer Kameras erfordert, sind die Gesamtkosten immer noch niedriger als bei Lidar und ihre Leistung ist im Vergleich zu Single-View-Kameras deutlich verbessert.
Zusammenfassend lässt sich sagen, dass die BEV-Technologie im Vergleich zu anderen Wahrnehmungstechnologien im Bereich des autonomen Fahrens gewisse Vorteile hat. Insbesondere bei der Bearbeitung von Corner Cases kann die BEV-Technologie eine globale Perspektive der Umweltwahrnehmung bieten und dazu beitragen, die Leistung autonomer Fahrsysteme in komplexen Szenarien zu verbessern. Um jedoch die Vorteile der BEV-Technologie voll auszuschöpfen, sind noch weitere Forschungs- und Entwicklungsarbeiten erforderlich, um die Leistung bei den Bildverarbeitungsfunktionen, der Sensorfusionstechnologie und der Vorhersage abnormalen Verhaltens zu verbessern. Gleichzeitig kann in Kombination mit anderen Wahrnehmungstechnologien (wie Lidar) und Deep-Learning- und Machine-Learning-Algorithmen die Stabilität und Sicherheit des autonomen Fahrsystems in verschiedenen Szenarien weiter verbessert werden.
02 Autonomes Fahrsystem auf Basis von Transformer und BEV
Gleichzeitig spielt Bird's Eye View (BEV) als effektive Methode zur Umgebungswahrnehmung eine wichtige Rolle im autonomen Fahrsystem. Durch die Kombination der Vorteile von Transformer und BEV können wir ein durchgängiges autonomes Fahrsystem aufbauen, um eine hochpräzise Wahrnehmung, Vorhersage und Entscheidungsfindung zu erreichen. In diesem Artikel wird außerdem untersucht, wie Transformer und BEV effektiv kombiniert und im Bereich des autonomen Fahrens eingesetzt werden können, um die Systemleistung zu verbessern.
Die spezifischen Schritte sind wie folgt:
1. Datenvorverarbeitung:
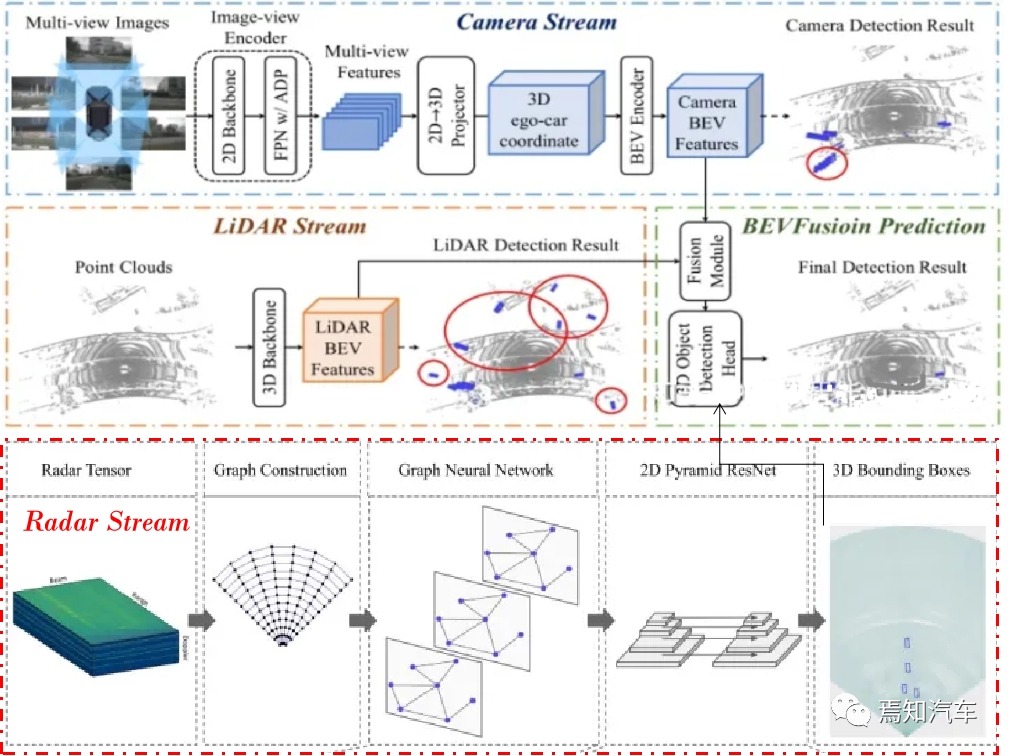
Multimodale Daten wie Lidar, Radar und Kamera im BEV-Format zusammenführen und notwendige Vorverarbeitungsvorgänge wie Datenverbesserung durchführen , Normalisierung usw.
Zuerst müssen wir multimodale Daten wie Lidar, Radar und Kamera in das BEV-Format konvertieren. Für Lidar-Punktwolkendaten können wir die dreidimensionale Punktwolke auf eine zweidimensionale Ebene projizieren und dann die Ebene rastern, um eine Höhenkarte für Radardaten zu erstellen. Wir können die Entfernungs- und Winkelinformationen in eine Höhenkarte umwandeln. Karl-Koordinaten werden dann auf der BEV-Ebene gerastert; für Kameradaten können wir die Bilddaten auf die BEV-Ebene projizieren, um eine Farb- oder Intensitätskarte zu erstellen.
 Bilder
Bilder
2. In der Wahrnehmungsphase des autonomen Fahrens kann das Transformer-Modell verwendet werden, um Merkmale in multimodalen Daten wie Lidar-Punktwolken, Bildern, und Radardaten warten. Durch die Durchführung eines End-to-End-Trainings dieser Daten kann Transformer automatisch die intrinsische Struktur und die Wechselbeziehungen dieser Daten erlernen und so Hindernisse in der Umgebung effektiv identifizieren und lokalisieren.
Verwenden Sie das Transformer-Modell, um Merkmale aus BEV-Daten zu extrahieren, um Hindernisse zu erkennen und zu lokalisieren.
Stapeln Sie diese BEV-Formatdaten zu einem Mehrkanal-BEV-Bild. Angenommen, die BEV-Höhenkarte des Lidar ist H(x, y), die BEV-Entfernungskarte des Radars ist R(x, y) und die BEV-Intensitätskarte der Kamera ist I(x, y), dann ist die Mehrkanal-BEV-Bilder können ausgedrückt werden als:
B(x, y) = [H(x, y), R(x, y), I(x, y)]
wobei B( x, y) stellt den Pixelwert des Mehrkanal-BEV-Bildes an den Koordinaten (x, y) dar, [] stellt die Kanalüberlagerung dar.
3. Vorhersagemodul:
Verwenden Sie basierend auf der Ausgabe des Wahrnehmungsmoduls das Transformer-Modell, um das zukünftige Verhalten und die Flugbahn anderer Verkehrsteilnehmer vorherzusagen. Durch das Erlernen historischer Flugbahndaten ist Transformer in der Lage, die Bewegungsmuster und Interaktionen von Verkehrsteilnehmern zu erfassen und so genauere Vorhersagen für autonome Fahrsysteme zu liefern.
Konkret verwenden wir zunächst Transformer, um Merkmale aus Mehrkanal-BEV-Bildern zu extrahieren. Unter der Annahme, dass das eingegebene BEV-Bild B(x, y) ist, können wir Merkmale F(x, y) durch mehrschichtigen Selbstaufmerksamkeitsmechanismus und Positionskodierung extrahieren:
F(x, y) = Transformer(B( x , y))
wobei F(x, y) die Feature-Map darstellt, den Feature-Wert an der Koordinate (x, y).
Dann verwenden wir die extrahierten Merkmale F(x, y), um das Verhalten und die Flugbahn anderer Verkehrsteilnehmer vorherzusagen. Der Decoder von Transformer kann verwendet werden, um Vorhersageergebnisse zu generieren, wie unten gezeigt:
P(t) = Decoder(F(x, y), t)
wobei P(t) die Vorhersage zum Zeitpunkt t darstellt Ergebnis: Decoder repräsentiert Transformer-Decoder.
Durch die oben genannten Schritte können wir eine Datenfusion und Vorhersage basierend auf Transformer und BEV erreichen. Die spezifische Transformer-Struktur und die Parametereinstellungen können entsprechend den tatsächlichen Anwendungsszenarien angepasst werden, um eine optimale Leistung zu erzielen.
4. Entscheidungsmodul:
Basierend auf den Ergebnissen des Vorhersagemoduls, kombiniert mit den Verkehrsregeln und dem Fahrzeugdynamikmodell, wird das Transformer-Modell verwendet, um eine geeignete Fahrstrategie zu generieren.
Bilder
Durch die Integration von Umweltinformationen, Verkehrsregeln und Fahrzeugdynamikmodellen in das Modell ist Transformer in der Lage, effiziente und sichere Fahrstrategien zu erlernen. Wie Pfadplanung, Geschwindigkeitsplanung usw. Darüber hinaus können mithilfe des Multi-Head-Selbstaufmerksamkeitsmechanismus von Transformer die Gewichtungen zwischen verschiedenen Informationsquellen effektiv ausgeglichen werden, um in komplexen Umgebungen vernünftigere Entscheidungen zu treffen.
Die folgenden Schritte sind für die Einführung dieser Methode erforderlich:
1. Datenerfassung und Vorverarbeitung:
Zuerst muss eine große Menge an Fahrdaten erfasst werden, einschließlich Fahrzeugstatusinformationen (z. B Geschwindigkeit, Beschleunigung, Lenkradwinkel) usw.), Informationen zum Straßenzustand (z. B. Straßentyp, Verkehrszeichen, Fahrspurlinien usw.), Informationen zur Umgebung (z. B. andere Fahrzeuge, Fußgänger, Fahrräder usw.) und die Aktionen vom Fahrer übernommen. Diese Daten werden vorverarbeitet, einschließlich Datenbereinigung, Standardisierung und Merkmalsextraktion.
2. Datenkodierung und Serialisierung:
Kodieren Sie die gesammelten Daten in eine für die Transformer-Modelleingabe geeignete Form. Dies umfasst typischerweise die Diskretisierung kontinuierlicher numerischer Daten und die Umwandlung der diskretisierten Daten in Vektorform. Gleichzeitig müssen die Daten serialisiert werden, damit das Transformer-Modell Zeitinformationen verarbeiten kann.
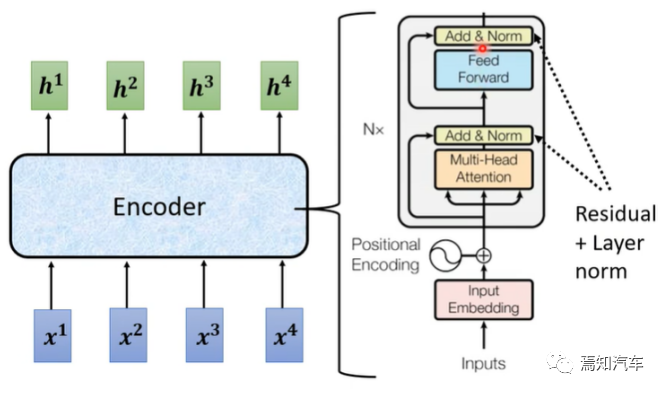
2.1, Transformer-Encoder
Transformer-Encoder besteht aus mehreren identischen Unterschichten, jede Unterschicht enthält zwei Teile: Multi-Head Attention (Multi-Head Attention) und Feed-Forward-Neuronales Netzwerk (Feed -Forward Neural Network).
Mehrkopf-Selbstaufmerksamkeit: Teilen Sie zunächst die Eingabesequenz in h verschiedene Köpfe auf, berechnen Sie die Selbstaufmerksamkeit jedes Kopfes separat und verbinden Sie dann die Ausgaben dieser Köpfe miteinander. Dadurch werden Abhängigkeiten auf verschiedenen Ebenen in der Eingabesequenz erfasst.
 Bild
Bild
Die Berechnungsformel für lange Selbstaufmerksamkeit lautet:
MHA(X) = Concat(head_1, head_2, ..., head_h) * W_O
wobei MHA( X) stellt die Ausgabe der Mehrkopf-Selbstaufmerksamkeit dar, head_i stellt die Ausgabe des i-ten Kopfes dar und W_O ist die Ausgabegewichtsmatrix.
Feedforward-Neuronales Netzwerk: Als nächstes wird die Ausgabe der Mehrkopf-Selbstaufmerksamkeit an das Feedforward-Neuronale Netzwerk weitergeleitet. Feedforward-Neuronale Netze enthalten normalerweise zwei vollständig verbundene Schichten und eine Aktivierungsfunktion (z. B. ReLU). Die Berechnungsformel des vorwärtsgerichteten neuronalen Netzwerks lautet:
FFN(x) = max(0, xW_1 + b_1) * W_2 + b_2
wobei FFN(x) die Ausgabe des vorwärtsgerichteten neuronalen Netzwerks W_1 darstellt und W_2 ist die Gewichtsmatrix, b_1 und b_2 sind Bias-Vektoren und max(0, x) repräsentiert die ReLU-Aktivierungsfunktion.
Darüber hinaus enthält jede Unterschicht im Encoder Restverbindungen und Schichtnormalisierung (Schichtnormalisierung), was dazu beiträgt, die Trainingsstabilität und Konvergenzgeschwindigkeit des Modells zu verbessern.
2.2. Transformer-Decoder
Ähnlich wie der Encoder besteht auch der Transformer-Decoder aus mehreren identischen Unterschichten: Multi-Head-Selbstaufmerksamkeit, Encoder-Decoder -Decoder Aufmerksamkeit und Feed-Forward-Neuronale Netze.
Mehrkopf-Selbstaufmerksamkeit: Dasselbe wie die Mehrkopf-Selbstaufmerksamkeit im Encoder, die zur Berechnung des Korrelationsgrads zwischen jedem Element in der Decoder-Eingabesequenz verwendet wird.
Encoder-Decoder-Achtung: Wird zur Berechnung des Korrelationsgrads zwischen der Decoder-Eingangssequenz und der Encoder-Ausgangssequenz verwendet. Die Berechnungsmethode ähnelt der Selbstaufmerksamkeit, mit der Ausnahme, dass der Abfragevektor aus der Eingabesequenz des Decoders und der Schlüsselvektor und der Wertvektor aus der Ausgabesequenz des Encoders stammen.
Feedforward-Neuronales Netzwerk: Dasselbe wie das Feedforward-Neuronale Netzwerk im Encoder. Jede Unterschicht im Decoder enthält auch Restverbindungen und Schichtnormalisierung. Durch das Stapeln mehrerer Encoder- und Decoderschichten ist Transformer in der Lage, Sequenzdaten mit komplexen Abhängigkeiten zu verarbeiten.
3. Erstellen Sie ein Transformer-Modell:
Erstellen Sie ein Transformer-Modell, das für autonome Fahrszenarien geeignet ist, einschließlich der Einstellung der entsprechenden Anzahl von Schichten, der Anzahl der Köpfe und der Größe der verborgenen Schichten. Darüber hinaus muss das Modell auch entsprechend den Aufgabenanforderungen feinabgestimmt werden, beispielsweise mithilfe einer Fahrstrategie, um eine Verlustfunktion für die Aufgabe zu generieren.
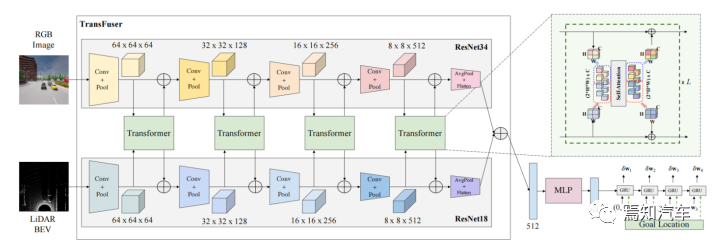
Zuerst wird der Merkmalsvektor durch MLP geleitet, um einen niedrigdimensionalen Vektor zu erhalten, der an das von GRU implementierte automatische Regressionspfadpunktnetzwerk übergeben und zum Initialisieren des verborgenen Zustands von GRU verwendet wird. Darüber hinaus werden auch die aktuelle Position und die Zielposition eingegeben, sodass sich das Netzwerk auf den relevanten Kontext des verborgenen Zustands konzentriert.
 Bild
Bild
Mit einer einschichtigen GRU und einer linearen Ebene zur Vorhersage des Pfadpunktversatzes 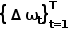 aus dem verborgenen Zustand erhalten wir den vorhergesagten Pfadpunkt
aus dem verborgenen Zustand erhalten wir den vorhergesagten Pfadpunkt 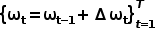 . Die Eingabe in die GRU ist der Ursprung.
. Die Eingabe in die GRU ist der Ursprung.
Der Controller verwendet zwei PID-Regler, um eine horizontale bzw. longitudinale Steuerung basierend auf den vorhergesagten Wegpunkten durchzuführen, um Lenk-, Brems- und Gaswerte zu erhalten. Führen Sie einen gewichteten Durchschnitt der Punktvektoren des kontinuierlichen Rahmenpfads durch, dann ist die Eingabe des Längsreglers seine Modullänge und die Eingabe des Querreglers seine Ausrichtung.
Berechnen Sie den L1-Verlust des Experten-Trajektorienpfadpunkts und des vorhergesagten Trajektorienpfadpunkts im aktuellen Fahrzeugkoordinatensystem, d. h.
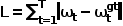
4 Verwenden Sie den gesammelten Datensatz. Trainieren Sie das Transformer-Modell. Während des Trainingsprozesses muss das Modell validiert werden, um seine Generalisierungsfähigkeit zu überprüfen. Zur Bewertung des Modells kann der Datensatz in Trainings-, Validierungs- und Testsätze unterteilt werden.
5. Generierung einer Fahrstrategie:
In tatsächlichen Anwendungen wird das vorab trainierte Transformer-Modell basierend auf dem aktuellen Fahrzeugstatus, Informationen zum Straßenzustand und Informationen zur Umgebung eingegeben. Basierend auf diesen Eingaben generiert das Modell Fahrstrategien wie Beschleunigung, Verzögerung, Lenkung usw.
6. Ausführung und Optimierung der Fahrstrategie:
Übergeben Sie die generierte Fahrstrategie an das autonome Fahrsystem, um das Fahrzeug zu steuern. Gleichzeitig werden Daten aus dem eigentlichen Ausführungsprozess zur weiteren Optimierung und Iteration des Modells gesammelt.
Durch die oben genannten Schritte kann eine auf dem Transformer-Modell basierende Methode verwendet werden, um in der Entscheidungsphase des autonomen Fahrens eine geeignete Fahrstrategie zu generieren. Dabei ist zu beachten, dass es aufgrund der hohen Sicherheitsanforderungen im Bereich des autonomen Fahrens erforderlich ist, die Leistungsfähigkeit und Sicherheit des Modells in verschiedenen Szenarien im realen Einsatz sicherzustellen.
03 Beispiele für Transformer+BEV-Technologie zur Lösung von Corner Cases
In diesem Abschnitt stellen wir detailliert drei Beispiele für BEV-Technologie zur Lösung von Corner Cases vor, bei denen es um komplexe Straßenverhältnisse, Unwetterbedingungen und die Vorhersage von abnormalem Verhalten geht. . Die folgende Abbildung zeigt einige Eckszenarien beim autonomen Fahren. Durch den Einsatz der Transformer+BEV-Technologie können die meisten derzeit erkennbaren Randszenen effektiv identifiziert und behandelt werden.
Bilder
 1. Umgang mit komplexen Straßenverhältnissen
1. Umgang mit komplexen Straßenverhältnissen
Bei komplexen Straßenverhältnissen wie Staus, komplexen Kreuzungen oder unregelmäßigen Straßenoberflächen kann die Transformer+BEV-Technologie eine umfassendere Umweltwahrnehmung ermöglichen. Durch die Integration von Bildern mehrerer Kameras rund um das Fahrzeug generiert BEV eine kontinuierliche Ansicht von oben, sodass das autonome Fahrsystem Spurlinien, Hindernisse, Fußgänger und andere Verkehrsteilnehmer klar identifizieren kann. An einer komplexen Kreuzung kann die BEV-Technologie beispielsweise dazu beitragen, dass das autonome Fahrsystem den Standort und die Fahrtrichtung jedes Verkehrsteilnehmers genau erkennt und so eine zuverlässige Grundlage für die Routenplanung und Entscheidungsfindung bietet.
2. Umgang mit Unwettern
Bei Unwettern wie Regen, Schnee, Nebel usw. können herkömmliche Kameras und Lidar beeinträchtigt sein, wodurch die Wahrnehmungsfähigkeit des autonomen Fahrsystems beeinträchtigt wird. Die Transformer+BEV-Technologie bietet in diesen Situationen immer noch gewisse Vorteile, da sie Bildinformationen aus verschiedenen Blickwinkeln zusammenführen kann, um die Wahrnehmung der Umgebung durch das System zu verbessern. Um die Leistung der Transformer+BEV-Technologie bei extremen Wetterbedingungen weiter zu verbessern, können Sie den Einsatz von Zusatzgeräten wie Infrarotkameras oder Wärmebildkameras in Betracht ziehen, um die Mängel von Kameras für sichtbares Licht in diesen Situationen zu ergänzen.
3. Sagen Sie abnormales Verhalten voraus
In tatsächlichen Straßenumgebungen können Fußgänger, Radfahrer und andere Verkehrsteilnehmer ungewöhnliche Verhaltensweisen zeigen, wie z. B. plötzliches Überqueren der Straße, Verstoß gegen Verkehrsregeln usw. BEV-Technologie kann autonomen Fahrsystemen dabei helfen, diese abnormalen Verhaltensweisen besser vorherzusagen. Mit der globalen Perspektive kann BEV vollständige Umweltinformationen bereitstellen, sodass das autonome Fahrsystem die Dynamik von Fußgängern und anderen Verkehrsteilnehmern genauer verfolgen und vorhersagen kann. Darüber hinaus kann die Transformer+BEV-Technologie durch die Kombination von maschinellem Lernen und Deep-Learning-Algorithmen die Vorhersagegenauigkeit abnormaler Verhaltensweisen weiter verbessern, sodass das autonome Fahrsystem in komplexen Szenarien vernünftigere Entscheidungen treffen kann.
4. Enge oder blockierte Straßen
In engen oder blockierten Straßenumgebungen können herkömmliche Kameras und Lidar Schwierigkeiten haben, genügend Informationen für eine effektive Umgebungswahrnehmung zu erhalten. In diesen Situationen kann jedoch die Transformer+BEV-Technologie ins Spiel kommen, da sie von mehreren Kameras aufgenommene Bilder integrieren kann, um eine umfassendere Ansicht zu erzeugen. Dadurch kann das autonome Fahrsystem die Umgebung um das Fahrzeug besser verstehen, Hindernisse in engen Passagen erkennen und diese Szenarien sicher navigieren.
5. Fahrzeuge zusammenführen und Verkehr zusammenführen
In Szenarien wie Autobahnen müssen autonome Fahrsysteme komplexe Aufgaben wie das Zusammenführen von Fahrzeugen und den Verkehr bewältigen. Diese Aufgaben stellen hohe Anforderungen an die Wahrnehmungsfähigkeit des autonomen Fahrsystems, da das System die Position und Geschwindigkeit umliegender Fahrzeuge in Echtzeit auswerten muss, um ein sicheres Einfädeln und Zusammenführen des Verkehrs zu gewährleisten. Mithilfe der Transformer+BEV-Technologie kann das autonome Fahrsystem eine globale Perspektive erhalten und die Verkehrsbedingungen rund um das Fahrzeug klar verstehen. Dies wird dem autonomen Fahrsystem dabei helfen, geeignete Zusammenführungsstrategien zu entwickeln, um sicherzustellen, dass sich Fahrzeuge sicher in den Verkehrsfluss integrieren können.
6. Notfallreaktion
In Notfallsituationen wie Verkehrsunfällen, Straßensperrungen oder Notfällen muss das autonome Fahrsystem schnelle Entscheidungen treffen, um die Fahrsicherheit zu gewährleisten. In diesen Fällen kann die Transformer+BEV-Technologie eine umfassende Echtzeitwahrnehmung der Umgebung für das autonome Fahrsystem bereitstellen und dem System dabei helfen, den aktuellen Straßenzustand schnell zu beurteilen. Durch die Kombination von Echtzeitdaten und fortschrittlichen Pfadplanungsalgorithmen können autonome Fahrsysteme geeignete Notfallstrategien entwickeln, um potenzielle Risiken zu vermeiden.
Anhand dieser Beispiele können wir sehen, dass die Transformer+BEV-Technologie großes Potenzial im Umgang mit Corner Case hat. Um jedoch die Vorteile der Transformer+BEV-Technologie voll ausschöpfen zu können, sind noch weitere Forschungs- und Entwicklungsarbeiten erforderlich, um die Leistung bei den Bildverarbeitungsfunktionen, der Sensorfusionstechnologie und der Vorhersage abnormalen Verhaltens zu verbessern.
04 Fazit
Dieser Artikel fasst die Prinzipien und Anwendungen der Transformer- und BEV-Technologie beim autonomen Fahren zusammen, insbesondere wie das Corner-Case-Problem gelöst werden kann. Durch die Bereitstellung einer globalen Perspektive und einer genauen Umgebungswahrnehmung soll die Transformer+BEV-Technologie die Zuverlässigkeit und Sicherheit autonomer Fahrsysteme in Extremsituationen verbessern. Allerdings weist die aktuelle Technologie immer noch bestimmte Einschränkungen auf, wie z. B. Leistungseinbußen bei widrigen Wetterbedingungen. Zukünftige Forschung sollte sich weiterhin auf die Verbesserung der BEV-Technologie und ihre Integration mit anderen Sensortechnologien konzentrieren, um ein höheres Maß an autonomer Fahrsicherheit zu erreichen.
Das obige ist der detaillierte Inhalt vonWie kann man Transformer BEV nutzen, um Extremsituationen des autonomen Fahrens zu meistern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr