
Heim >Technologie-Peripheriegeräte >KI >NVIDIA H100 dominiert den maßgeblichen KI-Leistungstest und schließt das Training großer Modelle auf Basis von GPT-3 in 11 Minuten ab
NVIDIA H100 dominiert den maßgeblichen KI-Leistungstest und schließt das Training großer Modelle auf Basis von GPT-3 in 11 Minuten ab

- 王林nach vorne
- 2023-06-28 20:00:20910Durchsuche
Am Dienstag Ortszeit veröffentlichte MLCommons, eine offene Branchenallianz im Bereich maschinelles Lernen und künstliche Intelligenz, die neuesten Daten von zwei MLPerf-Benchmark-Tests. Darunter stellte der NVIDIA H100-Chipsatz im Test einen neuen Rekord in allen Kategorien auf Die Rechenleistung der künstlichen Intelligenz war die einzige Hardwareplattform, die alle Tests ausführen konnte.
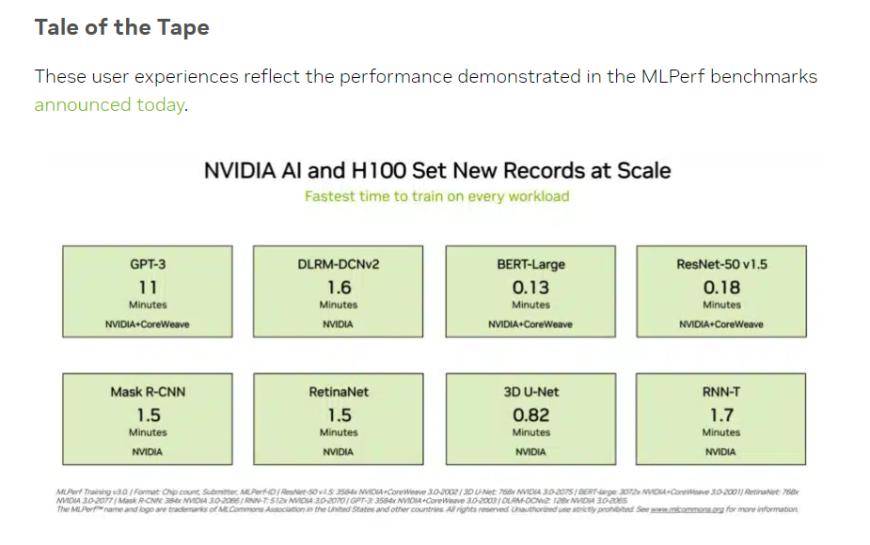
(Quelle: NVIDIA, MLCommons)
MLPerf ist eine Führungsallianz im Bereich der künstlichen Intelligenz, die sich aus Wissenschaft, Laboren und Industrie zusammensetzt. Es ist derzeit ein international anerkannter und maßgeblicher Maßstab für die Bewertung der KI-Leistung. Training v3.0 enthält 8 verschiedene Lasten, darunter Sehvermögen (Bildklassifizierung, biomedizinische Bildsegmentierung, Objekterkennung für zwei Lasten), Sprache (Spracherkennung, großes Sprachmodell, Verarbeitung natürlicher Sprache) und Empfehlungssystem. Mit anderen Worten: Verschiedene Gerätehersteller benötigen unterschiedlich viel Zeit, um die Benchmark-Aufgabe abzuschließen.
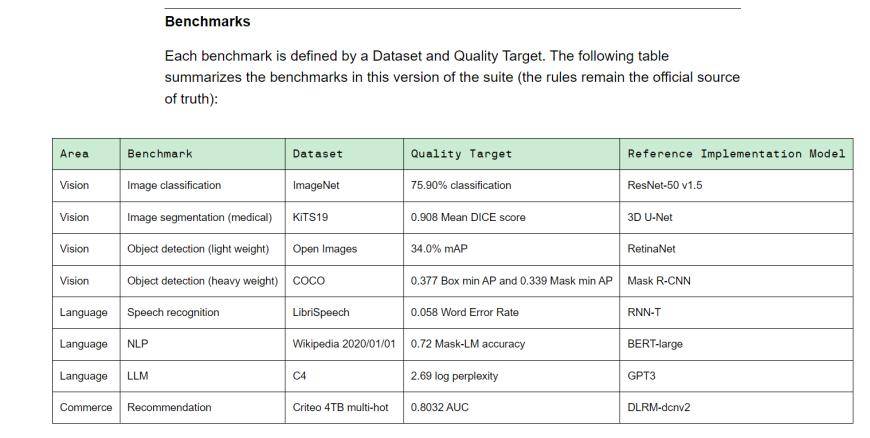
(Training v3.0 Trainings-Benchmark, Quelle: MLCommons)
In dem Trainingstest „Big Language Model“, dem Investoren große Aufmerksamkeit schenken, haben die von NVIDIA und der GPU-Cloud-Computing-Plattform CoreWeave übermittelten Daten einen grausamen Industriestandard für diesen Test gesetzt. Dank der konzertierten Anstrengungen von 896 Intel
Mit Ausnahme von Nvidia erhielt nur das Produktportfolio von Intel Bewertungsdaten zu diesem Projekt. In einem System mit 96 Xeon 8380-Prozessoren und 96 Habana Gaudi2 AI-Chips betrug die Zeit für die Durchführung desselben Tests 311,94 Minuten. Auf einer Plattform mit 768 H100-Chips dauert der horizontale Vergleichstest nur 45,6 Minuten.
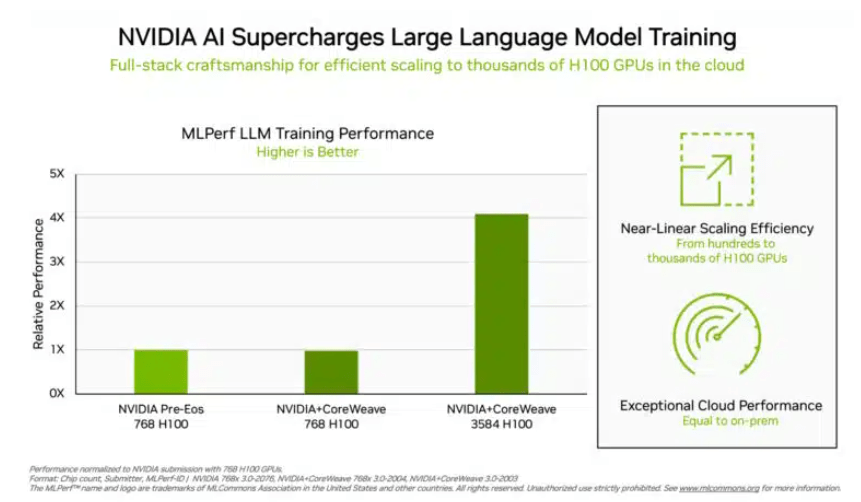
(Je mehr Chips, desto besser die Daten, Quelle: NVIDIA)
In Bezug auf dieses Ergebnis sagte Intel auch, dass es noch Raum für Verbesserungen gibt. Theoretisch sind die Berechnungsergebnisse natürlich schneller, solange mehr Chips gestapelt sind. Jordan Plawner, Senior Director für KI-Produkte bei Intel, sagte den Medien, dass die Rechenergebnisse von Habana um das 1,5- bis 2-fache verbessert werden. Plawner lehnte es ab, den konkreten Preis von Habana Gaudi2 bekannt zu geben, und sagte lediglich, dass die Branche einen zweiten Hersteller benötige, um KI-Trainingschips bereitzustellen, und MLPerf-Daten zeigen, dass Intel in der Lage sei, diese Nachfrage zu decken.
Beim BERT-Large-Modelltraining, das chinesischen Investoren bekannter ist, haben NVIDIA und CoreWeave die Daten auf extreme 0,13 Minuten erhöht. Bei 64 Karten erreichten die Testdaten ebenfalls 0,89 Minuten. Die aktuelle Infrastruktur der Mainstream-Großmodelle ist die Transformer-Struktur im BERT-Modell.
Quelle: Financial Associated Press
Das obige ist der detaillierte Inhalt vonNVIDIA H100 dominiert den maßgeblichen KI-Leistungstest und schließt das Training großer Modelle auf Basis von GPT-3 in 11 Minuten ab. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr