
Heim >Technologie-Peripheriegeräte >KI >DragGAN wurde in drei Tagen für 23.000 Stars als Open Source bereitgestellt, hier kommt eine weitere DragDiffusion
DragGAN wurde in drei Tagen für 23.000 Stars als Open Source bereitgestellt, hier kommt eine weitere DragDiffusion

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-28 15:28:171370Durchsuche
In der magischen Welt von AIGC können wir die gewünschten Bilder ändern und kombinieren, indem wir auf das Bild ziehen. Zum Beispiel einen Löwen dazu bringen, seinen Kopf zu drehen und sein Maul zu öffnen:
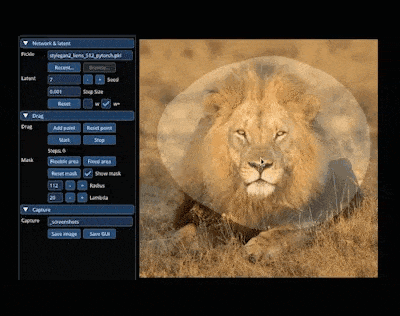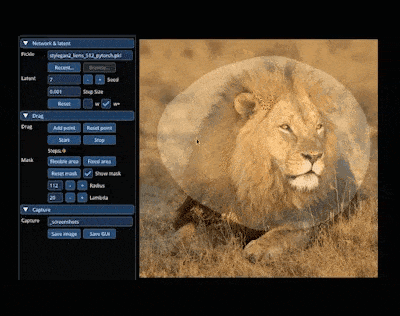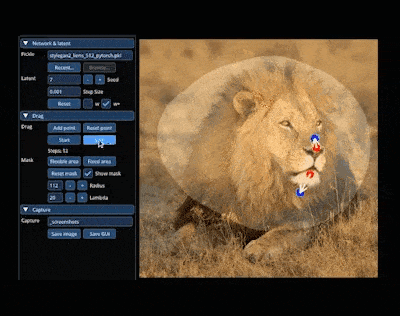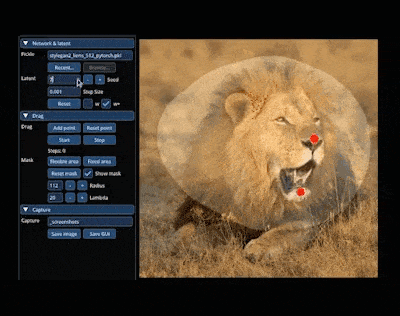
Die Forschung zur Erzielung dieses Effekts stammt aus dem von einem chinesischen Autor geleiteten Artikel „Drag Your GAN“, der letzten Monat veröffentlicht wurde und wurde akzeptiert von der SIGGRAPH 2023-Konferenz.
Mehr als ein Monat ist vergangen und das Forschungsteam hat kürzlich den offiziellen Code veröffentlicht. In nur drei Tagen hat die Anzahl der Stars 23.000 überschritten, was die Beliebtheit zeigt.
 Bilder
Bilder
GitHub-Adresse: https://github.com/XingangPan/DragGAN
Zufälligerweise ist heute eine weitere ähnliche Forschung – DragDiffusion – ins Blickfeld der Menschen geraten. Das vorherige DragGAN implementierte eine punktbasierte interaktive Bildbearbeitung und erzielte Präzisionsbearbeitungseffekte auf Pixelebene. Es gibt jedoch auch Mängel. DragGAN basiert auf einem generativen kontradiktorischen Netzwerk (GAN) und seine Vielseitigkeit ist durch die Kapazität des vorab trainierten GAN-Modells begrenzt.
In einer neuen Forschung haben mehrere Forscher der National University of Singapore und ByteDance diese Art von Bearbeitungsrahmen auf ein Diffusionsmodell erweitert und DragDiffusion vorgeschlagen. Sie nutzen umfangreiche vorab trainierte Diffusionsmodelle, um die Anwendbarkeit punktbasierter interaktiver Bearbeitung in realen Szenarien erheblich zu verbessern.
Während die meisten aktuellen diffusionsbasierten Bildbearbeitungsmethoden für die Texteinbettung geeignet sind, optimiert DragDiffusion die latente Diffusionsdarstellung, um eine präzise räumliche Kontrolle zu erreichen.
 Bilder
Bilder
- Papieradresse: https://arxiv.org/pdf/2306.14435.pdf
- Projektadresse: https://yujun-shi.github.io/projects /dragdiffusion.html
Die Forscher sagten, dass das Diffusionsmodell Bilder auf iterative Weise generiert und die „einstufige“ Optimierung der Darstellung des Diffusionspotentials ausreicht, um kohärente Ergebnisse zu generieren, sodass DragDiffusion effizient arbeiten kann Komplette hochwertige Bearbeitung.
Sie führten umfangreiche Experimente unter verschiedenen herausfordernden Szenarien (z. B. mehreren Objekten, verschiedenen Objektkategorien) durch, um die Plastizität und Vielseitigkeit von DragDiffusion zu überprüfen. Der entsprechende Code wird ebenfalls bald veröffentlicht.
Sehen wir uns an, wie DragDiffusion funktioniert.
Zuerst wollen wir den Kopf des Kätzchens im Bild unten anheben. Der Benutzer muss nur den roten Punkt zum blauen Punkt ziehen:

Als nächstes wollen wir das machen Berggipfel höher, kein Problem, ziehen Sie einfach den roten Schlüsselpunkt:
 Bild
Bild
 Wir möchten auch, dass der Avatar der Skulptur seinen Kopf dreht, ziehen Sie ihn einfach:
Wir möchten auch, dass der Avatar der Skulptur seinen Kopf dreht, ziehen Sie ihn einfach:
 Bilder
Bilder
 Lassen Sie die Blumen am Ufer in einem größeren Bereich blühen:
Lassen Sie die Blumen am Ufer in einem größeren Bereich blühen:

Einführung in die Methode
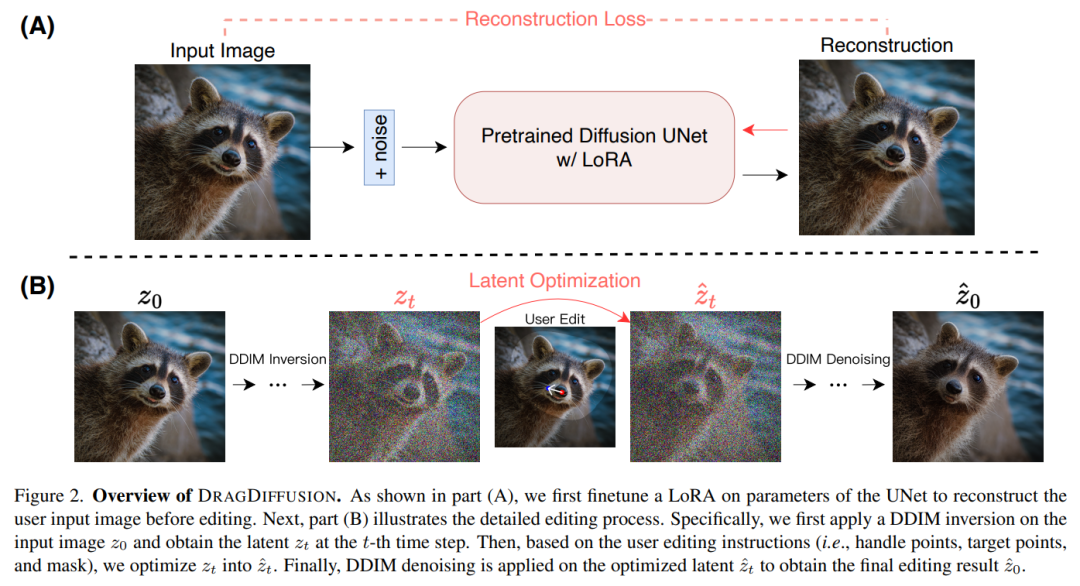
Die in diesem Artikel vorgeschlagene DRAGDIFFUSION zielt darauf ab, die Verbreitung latenter Variablen für interaktive, punktbasierte Zwecke gezielt zu optimieren Bildbearbeitung.
Um dieses Ziel zu erreichen, optimierte die Forschung zunächst LoRA basierend auf dem Diffusionsmodell, um das Benutzereingabebild zu rekonstruieren. Dadurch kann sichergestellt werden, dass der Stil der Eingabe- und Ausgabebilder konsistent bleibt.
Als nächstes verwendeten die Forscher die DDIM-Inversion (eine Methode zur Untersuchung der Umkehrtransformation und des latenten Raumbetriebs des Diffusionsmodells) für das Eingabebild, um die latente Diffusionsvariable in einem bestimmten Schritt zu erhalten.
Während des Bearbeitungsprozesses nutzte der Forscher wiederholt Bewegungsüberwachung und Punktverfolgung, um die zuvor erhaltene latente Diffusionsvariable in Schritt t zu optimieren und dadurch den Inhalt des Bearbeitungspunkts an den Zielort zu „ziehen“. Der Bearbeitungsprozess wendet außerdem einen Regularisierungsterm an, um sicherzustellen, dass die nicht maskierten Bereiche des Bildes unverändert bleiben.
Abschließend verwenden Sie DDIM, um die optimierten latenten Variablen in Schritt t zu entrauschen, um die bearbeiteten Ergebnisse zu erhalten. Die Gesamtübersicht sieht wie folgt aus:
 Bilder
Bilder
Experimentelle Ergebnisse
Bei einem Eingabebild „zieht“ DRAGDIFFUSION den Inhalt der Schlüsselpunkte (rot) zum entsprechenden Zielpunkt (blaue Farbe). . Drehen Sie zum Beispiel in Bild (1) den Kopf des Welpen um, in Bild (7) schließen Sie das Maul des Tigers usw.
 Bilder
Bilder
Hier sind weitere Beispieldemos. Machen Sie den Berggipfel höher, wie in Abbildung (4) gezeigt, vergrößern Sie in Abbildung (7) die Stiftspitze usw.
 Bilder
Bilder

Das obige ist der detaillierte Inhalt vonDragGAN wurde in drei Tagen für 23.000 Stars als Open Source bereitgestellt, hier kommt eine weitere DragDiffusion. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr