
Heim >Technologie-Peripheriegeräte >KI >65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt
65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt

- 王林nach vorne
- 2023-06-20 15:57:581476Durchsuche
In Richtung großer Modelle trainieren Technologiegiganten größere Modelle, während die Wissenschaft über Möglichkeiten nachdenkt, diese zu optimieren. In letzter Zeit hat die Methode zur Optimierung der Rechenleistung ein neues Niveau erreicht.
Groß angelegte Sprachmodelle (LLM) haben den Bereich der Verarbeitung natürlicher Sprache (NLP) revolutioniert und außergewöhnliche Fähigkeiten wie Emergenz und Epiphanie demonstriert. Wenn Sie jedoch ein Modell mit bestimmten allgemeinen Fähigkeiten erstellen möchten, werden Milliarden von Parametern benötigt, was die Schwelle für die NLP-Forschung erheblich erhöht. Der LLM-Modelloptimierungsprozess erfordert in der Regel teure GPU-Ressourcen, beispielsweise ein 8×80-GB-GPU-Gerät, was es für kleine Labore und Unternehmen schwierig macht, sich an der Forschung in diesem Bereich zu beteiligen.
In letzter Zeit werden Techniken zur Parametereffizienten Feinabstimmung (PEFT) wie LoRA und Präfix-Tuning untersucht, die Lösungen für die Optimierung von LLM mit begrenzten Ressourcen bieten. Allerdings bieten diese Methoden keine praktischen Lösungen für die vollständige Parameter-Feinabstimmung, die als leistungsfähigere Methode als die Parameter-effiziente Feinabstimmung gilt.
In dem Artikel „Full Parameter Fine-tuning for Large Language Models with Limited Resources“, der letzte Woche vom Qiu
Durch die Integration von LOMO in bestehende Speicherspartechniken reduziert der neue Ansatz die Speichernutzung auf 10,8 % im Vergleich zum Standardansatz (DeepSpeed-Lösung). Dadurch ermöglicht der neue Ansatz die vollständige Parameter-Feinabstimmung eines 65B-Modells auf einer Maschine mit 8×RTX 3090s, jeweils mit 24 GB Speicher.

Link zum Papier: https://arxiv.org/abs/2306.09782
In dieser Arbeit analysierte der Autor vier Aspekte der Speichernutzung in LLM: Aktivierung, Optimierungszustand, Gradient Tensor und Parameter und optimierte den Trainingsprozess in drei Aspekten:
- überlegte die Funktion des Optimierers aus algorithmischer Sicht und stellte fest, dass SGD eine gute Möglichkeit ist, die gesamten Parameter von LLM Substitute zu optimieren. Dadurch können die Autoren ganze Teile des Optimiererzustands löschen, da SGD keinen Zwischenzustand speichert.
- Der neu vorgeschlagene Optimierer LOMO reduziert die Speichernutzung von Gradiententensoren auf O(1), was der Speichernutzung des größten Gradiententensors entspricht.
- Um das gemischte Präzisionstraining mit LOMO zu stabilisieren, integrieren die Autoren Gradientennormalisierung und Verlustskalierung und konvertieren bestimmte Berechnungen während des Trainings in volle Präzision.
Neue Technologie macht die Speichernutzung gleich der Parameternutzung plus Aktivierung und maximalen Gradiententensoren. Die Speichernutzung der vollständigen Parameter-Feinabstimmung wird auf das Äußerste getrieben, was nur der Verwendung von Inferenz entspricht. Dies liegt daran, dass der Speicherbedarf des Vorwärts- und Rückwärtsprozesses nicht geringer sein sollte als der des Vorwärtsprozesses allein. Es ist erwähnenswert, dass bei der Verwendung von LOMO zum Speichern von Speicher die neue Methode sicherstellt, dass der Feinabstimmungsprozess nicht beeinträchtigt wird, da der Parameteraktualisierungsprozess immer noch dem SGD entspricht.
Diese Studie bewertet die Speicher- und Durchsatzleistung von LOMO und zeigt, dass Forscher mit LOMO ein 65B-Parametermodell auf 8 RTX 3090-GPUs trainieren können. Um außerdem die Leistung von LOMO bei nachgelagerten Aufgaben zu überprüfen, wendeten sie LOMO an, um alle Parameter von LLM auf die SuperGLUE-Datensatzsammlung abzustimmen. Die Ergebnisse belegen die Wirksamkeit von LOMO zur Optimierung von LLMs mit Milliarden von Parametern.
Einführung in die Methode
Im Methodenabschnitt stellt dieser Artikel LOMO (LOW-MEMORY OPTIMIZATION) ausführlich vor. Im Allgemeinen stellt der Gradiententensor den Gradienten eines Parametertensors dar und seine Größe entspricht der der Parameter, was zu einem größeren Speicheraufwand führt. Bestehende Deep-Learning-Frameworks wie PyTorch speichern Gradiententensoren für alle Parameter. Derzeit gibt es zwei Gründe für die Speicherung von Gradiententensoren: die Berechnung des Optimiererzustands und die Normalisierung von Gradienten.
Da in dieser Studie SGD als Optimierer verwendet wird, gibt es keinen Gradienten-abhängigen Optimiererstatus und es gibt einige Alternativen zur Gradientennormalisierung.
Sie schlugen LOMO vor. Wie in Algorithmus 1 gezeigt, integriert LOMO die Gradientenberechnung und Parameteraktualisierung in einem Schritt und vermeidet so die Speicherung von Gradiententensoren.
Die folgende Abbildung zeigt den Vergleich zwischen SGD und LOMO in den Phasen Backpropagation und Parameteraktualisierung. Pi ist der Modellparameter und Gi ist der zu Pi entsprechende Gradient. LOMO integriert die Gradientenberechnung und Parameteraktualisierung in einem einzigen Schritt, um den Gradiententensor zu minimieren. Pseudocode des entsprechenden Algorithmus von LOMO: Zunächst ein zweidimensionaler Schrittprozess Berechnen Sie den Gradienten und aktualisieren Sie dann die Parameter. Die Fusionsversion ist
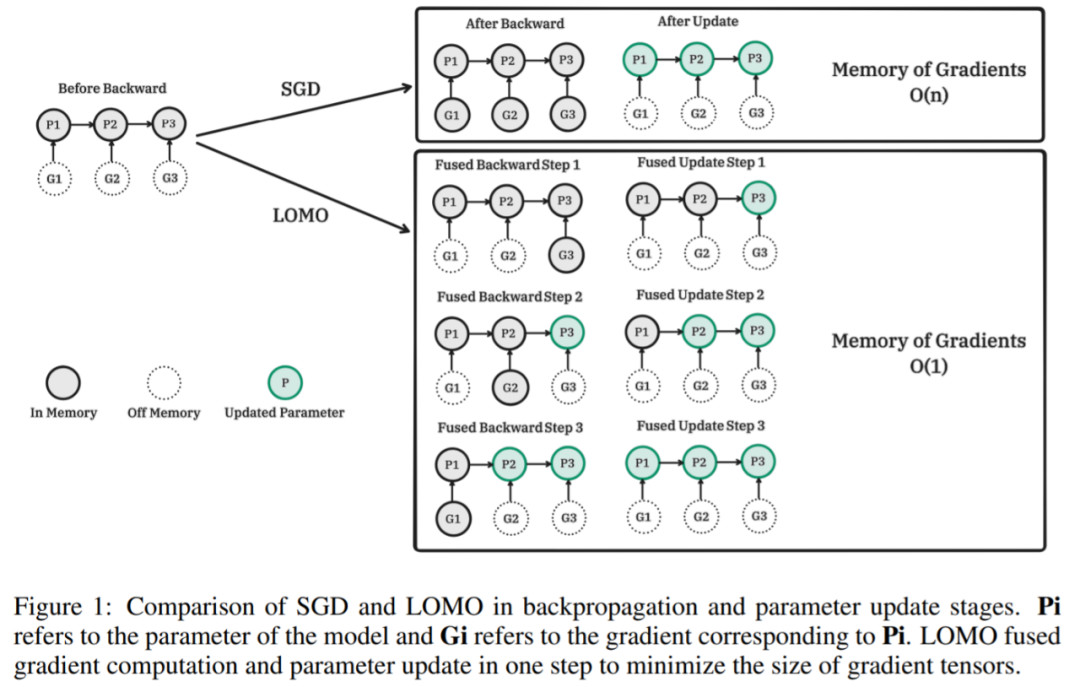
Der größte Teil der LOMO-Speichernutzung stimmt mit der Speichernutzung von Parameter-effizienten Feinabstimmungsmethoden überein, was darauf hinweist, dass die Kombination von LOMO mit diesen Methoden nur zu einer geringfügigen Erhöhung des vom Gradienten belegten Speichers führt. Dadurch können mehr Parameter für die PEFT-Methode abgestimmt werden.

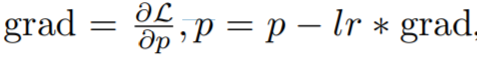
Speichernutzung
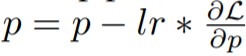 Die Forscher analysierten zunächst den Modellstatus und die aktivierte Speichernutzung während des Trainings unter verschiedenen Einstellungen. Wie in Tabelle 1 gezeigt, führt die Verwendung des LOMO-Optimierers zu einer deutlichen Reduzierung der Speichernutzung, von 102,20 GB auf 14,58 GB, während beim Training des LLaMA-7B-Modells die Speichernutzung sinkt von 51,99 GB auf 14,58 GB reduziert. Die deutliche Reduzierung der Speichernutzung ist hauptsächlich auf den geringeren Speicherbedarf für Farbverläufe und Optimiererzustände zurückzuführen. Daher wird der Speicher während des Trainingsprozesses hauptsächlich von Parametern belegt, was der Speichernutzung während der Inferenz entspricht.
Die Forscher analysierten zunächst den Modellstatus und die aktivierte Speichernutzung während des Trainings unter verschiedenen Einstellungen. Wie in Tabelle 1 gezeigt, führt die Verwendung des LOMO-Optimierers zu einer deutlichen Reduzierung der Speichernutzung, von 102,20 GB auf 14,58 GB, während beim Training des LLaMA-7B-Modells die Speichernutzung sinkt von 51,99 GB auf 14,58 GB reduziert. Die deutliche Reduzierung der Speichernutzung ist hauptsächlich auf den geringeren Speicherbedarf für Farbverläufe und Optimiererzustände zurückzuführen. Daher wird der Speicher während des Trainingsprozesses hauptsächlich von Parametern belegt, was der Speichernutzung während der Inferenz entspricht.
Wie in Abbildung 2 dargestellt, wird ein beträchtlicher Anteil des Speichers (73,7 %) dem Optimierungsstatus zugewiesen, wenn der AdamW-Optimierer für das LLaMA-7B-Training verwendet wird. Das Ersetzen des AdamW-Optimierers durch den SGD-Optimierer reduziert effektiv den Prozentsatz des vom Optimiererstatus belegten Speichers und verringert dadurch die GPU-Speichernutzung (von 102,20 GB auf 51,99 GB). Wenn LOMO verwendet wird, werden Parameteraktualisierungen und Rückwärtsvorgänge in einem einzigen Schritt zusammengeführt, wodurch der Speicherbedarf für den Optimiererstatus weiter entfällt.
Durchsatz
Die Forscher verglichen die Durchsatzleistung von LOMO, AdamW und SGD. Die Experimente wurden auf einem Server durchgeführt, der mit 8 RTX 3090-GPUs ausgestattet war.Für das 7B-Modell zeigt der Durchsatz von LOMO einen deutlichen Vorteil und übertrifft AdamW und SGD um etwa das Elffache. Diese deutliche Verbesserung ist auf die Fähigkeit von LOMO zurückzuführen, das 7B-Modell auf einer einzelnen GPU zu trainieren, was den Kommunikationsaufwand zwischen GPUs reduziert. Der etwas höhere Durchsatz von SGD im Vergleich zu AdamW ist darauf zurückzuführen, dass SGD die Berechnung von Impuls und Varianz ausschließt. Das 13B-Modell kann aufgrund von Speicherbeschränkungen nicht mit AdamW auf den vorhandenen 8 RTX 3090-GPUs trainiert werden. In diesem Fall ist Modellparallelität für LOMO erforderlich, das SGD hinsichtlich des Durchsatzes immer noch übertrifft. Dieser Vorteil wird auf die speichereffiziente Natur von LOMO und die Tatsache zurückgeführt, dass nur zwei GPUs erforderlich sind, um das Modell mit denselben Einstellungen zu trainieren, wodurch die Kommunikationskosten gesenkt und der Durchsatz verbessert werden. Darüber hinaus stieß SGD beim Training des 30B-Modells auf OOM-Probleme (Out-of-Memory) auf 8 RTX 3090-GPUs, während LOMO mit nur 4 GPUs eine gute Leistung erbrachte. Schließlich trainierte der Forscher das 65B-Modell erfolgreich mit 8 RTX 3090-GPUs und erreichte einen Durchsatz von 4,93 TGS. Mit dieser Serverkonfiguration und LOMO dauert der Trainingsprozess des Modells für 1000 Samples (jedes Sample enthält 512 Token) etwa 3,6 Stunden. Downstream-Leistung Um die Wirksamkeit von LOMO bei der Feinabstimmung großer Sprachmodelle zu bewerten, führten die Forscher eine umfangreiche Reihe von Experimenten durch. Sie verglichen LOMO mit zwei anderen Methoden: Die eine ist Zero-Shot, die keine Feinabstimmung erfordert, und die andere ist LoRA, eine beliebte Parameter-effiziente Feinabstimmungstechnik. 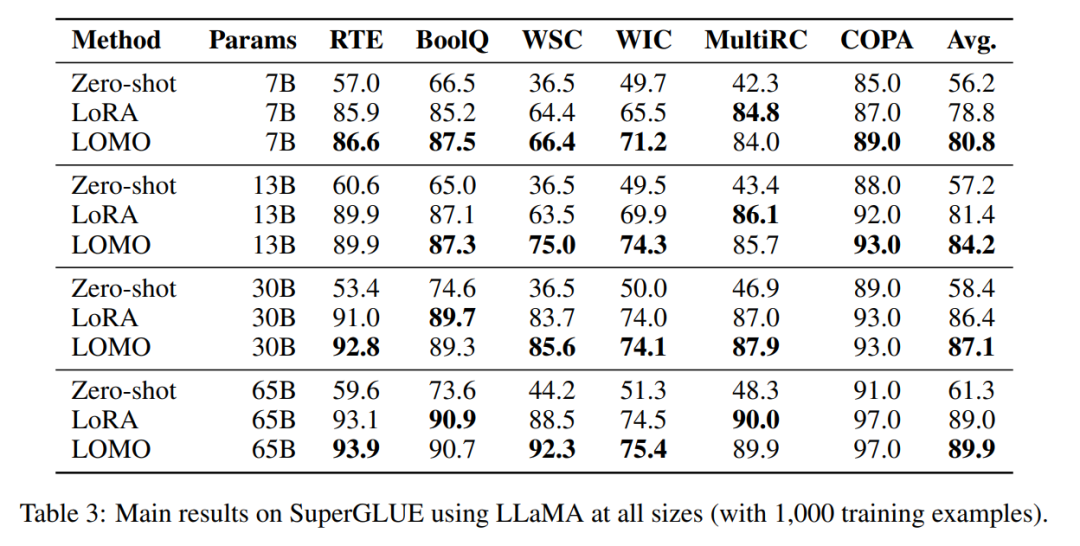
- LOMO schneidet deutlich besser ab als Zero-Shot;
- In den meisten Experimenten ist LOMO im Allgemeinen besser als LoRA; s skaliert auf 65 Milliarden Parameter.
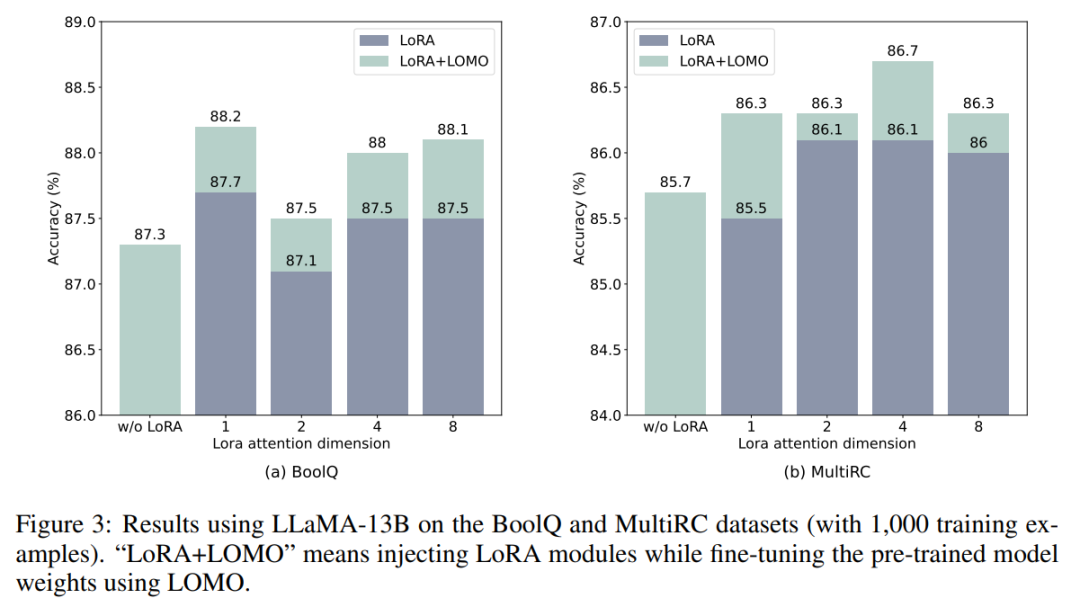
- LOMO und LoRA sind im Wesentlichen unabhängig voneinander. Um diese Aussage zu überprüfen, führten die Forscher Experimente mit BoolQ- und MultiRC-Datensätzen unter Verwendung von LLaMA-13B durch. Die Ergebnisse sind in Abbildung 3 dargestellt.
Sie fanden heraus, dass LOMO die Leistung von LoRA weiter steigerte, unabhängig davon, wie hoch die Ergebnisse waren, die LoRA erzielte. Dies zeigt, dass die verschiedenen Feinabstimmungsmethoden von LOMO und LoRA sich ergänzen. LOMO konzentriert sich insbesondere auf die Feinabstimmung der Gewichte des vorab trainierten Modells, während LoRA andere Module anpasst. Daher hat LOMO keinen Einfluss auf die Leistung von LoRA; stattdessen ermöglicht es eine bessere Modellabstimmung für nachgelagerte Aufgaben.
 Weitere Einzelheiten finden Sie im Originalpapier.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von65 Milliarden Parameter, 8 GPUs können alle Parameter feinabstimmen: Das Team von Qiu Xipeng hat den Schwellenwert für große Modelle gesenkt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr