
Heim >Technologie-Peripheriegeräte >KI >Augapfelreflexion erschließt die 3D-Welt und macht Black Mirror Wirklichkeit! Das neue Werk von Maryland Chinese begeistert Science-Fiction-Fans
Augapfelreflexion erschließt die 3D-Welt und macht Black Mirror Wirklichkeit! Das neue Werk von Maryland Chinese begeistert Science-Fiction-Fans

- PHPznach vorne
- 2023-06-19 14:43:181030Durchsuche
„Die einzig wahre Entdeckungsreise besteht nicht darin, ein fremdes Land zu besuchen, sondern das Universum mit den Augen anderer zu beobachten.“ – Marcel Proust
Sehen Sie die Welt mit den Augen anderer, dieser Science-Fiction-Film. Die poetische (und erschreckende) Idee ist wahr geworden!

„Black Mirror“ Staffel 1 „The Entire History of You“
Jetzt können wir das Objekt, das die Person beobachtet, einfach anhand der Spiegelung des Auges dreidimensional rekonstruieren .
Ja, das ist sehr Black Mirror.


Kürzlich hat ein Team der University of Maryland eine brandneue Methode vorgeschlagen – durch die Verwendung von Porträts, die Augenreflexionen enthalten, um Szenen einzufangen, die nicht von der Kamera. Führen Sie eine dreidimensionale Rekonstruktion durch.

Papieradresse: https://arxiv.org/abs/2306.09348
Projektadresse: https://world-from-eyes.github.io/
Sind alle Szenen der klassischen Science-Fiction wahr geworden?
Augenreflexion nutzen, um eine Strahlungsfeldrekonstruktion zu erzeugen? Diese Idee mag verrückt erscheinen, aber sie hat tatsächlich genügend theoretische Grundlage.
Der Autor sagte, dass es möglich ist, die 3D-Szene, die Menschen beobachten, nur anhand der Reflexion der Augen zu rekonstruieren und darzustellen, da das menschliche Auge stark reflektiert.

Angesichts der Tatsache, dass dieses Konzept sehr „Black Mirror“ ist und eine neue Staffel von „Black Mirror“ nur wenige Stunden nach Veröffentlichung dieser Zeitung angekündigt wurde, lässt dieser Zufall die Leute einfach daran zweifeln, dass „Black Mirror“ „Hat der Regisseur dieses Papier auch bemerkt? (Dog Head)

Black Mirror Staffel 6 startet heute
Sobald diese Studie herauskam, drehten die Internetnutzer durch.
Wir sind also fast da?

Ist das nicht die Szene aus „Ghost in the Shell“ aus den 2000ern? All diese Fiktionen sind Wirklichkeit geworden!


100 % Blade Runner, gib mir jetzt ein Exemplar.


Jules Vernes „Bruder Kip“ wird wahr!

Einige Leute äußerten sich natürlich entsetzt darüber: Diese Technologie sollte niemals für Dinge wie Ermittlungen und Beweiserhebung eingesetzt werden.

Heute verfügen wir bereits über Varjo-Eye-Tracking-Kameras, Apples VisionPro und andere Headsets. In Kombination mit dieser neuen Technologie können unzählige neue Science-Fiction-Filme erfasst werden Die Szene könnte bald wahr werden ...

Durch die Ausnutzung der winzigen Lichtreflexionen auf dem menschlichen Auge hat das Forschungsteam eine Methode entwickelt, mit der Bilder verwendet werden können, die an einer festen Kameraposition aufgenommen wurden Bildsequenzen werden verwendet, um die vom Menschen beobachtete (nicht direkt betrachtete) Szene zu rekonstruieren.
Allerdings reicht es aus mehreren Gründen nicht aus, das Strahlungsfeld einfach auf die beobachteten Reflexionen zu trainieren: 1) das inhärente Rauschen bei der Hornhautpositionierung, 2) die Komplexität der Iristextur, 3) die in jedem Bild erfasste Strahlungsmenge Reflexionen mit niedriger Auflösung.
Um diese Herausforderungen zu lösen, führte das Team während des Trainingsprozesses eine Optimierung der Hornhauthaltung und eine Zerlegung der Iristextur ein, mithilfe eines radialen Texturregulierungsverlusts basierend auf der menschlichen Iris.
Im Gegensatz zu herkömmlichen neuronalen Feldtrainingsmethoden, bei denen die Kamera bewegt werden muss, wird die Kamera bei dieser Methode an einem festen Blickwinkel positioniert und basiert vollständig auf der Bewegung des Benutzers.
Verwendung von Reflexionen des menschlichen Auges zur Szenenrekonstruktion
Diese Aufgabe ist eine Herausforderung, da es schwierig ist, die Augenhaltung genau abzuschätzen, und die miteinander verflochtenen Texturen zwischen der Iris und den Szenenreflexionen.
Um dieses Problem zu lösen, optimierte der Autor gemeinsam die Augenhaltung, das die Szene beschreibende Strahlungsfeld und die Textur der Augeniris des Betrachters.

Pecifical sind die Hauptbeiträge drei Punkte:
1. das frühere Grundlagenarbeiten mit jüngsten Fortschritten im neuronalen Rendering kombiniert.
2. Radialer Prior der Iris
Der radiale Prior der Iris-Texturzerlegung wird eingeführt, was die Qualität des rekonstruierten Strahlungsfeldes erheblich verbessert.
3. Optimierung der Hornhauthaltung
Ein Prozess zur Optimierung der Hornhauthaltung wurde entwickelt, um das Rauschen bei der Schätzung der Augenhaltung zu mildern und die einzigartigen Herausforderungen beim Extrahieren von Merkmalen aus dem menschlichen Auge zu bewältigen.
Die Ergebnisse zeigen, dass wir mit dieser neuen Methode aus der Spiegelung der Augen durch Verschieben des Bildes mehrere Perspektiven der Szene erhalten und schließlich eine vollständige Szenenrekonstruktion erreichen können.

Was noch erstaunlicher ist, ist, dass das Team auch versucht hat, die MVs von Miley Cyrus und Lady Gaga zu verwenden, um die Szenen in ihren Augen nachzubilden.
Die Autoren gaben an, dass es ihnen gelungen sei, die Objekte zu rekonstruieren, die in Mileys Augen erschienen, und dass der Oberkörper einer Person durch Lady Gagas Augen gesehen zu werden schien.
Da jedoch die Qualität dieser Videos nicht hoch genug ist, kann nicht auf die Genauigkeit der Rekonstruktionsergebnisse geschlossen werden.

Lady Gaga

Miley Cyrus
Wie geht das?
Es ist bekannt, dass die Hornhautgeometrie gesunder Erwachsener nahezu gleich ist.
Durch einfaches Berechnen der Pixelgröße der Hornhaut einer Person im Bild kann deren Augenposition genau berechnet werden.
Als nächstes trainieren die Autoren das vom Auge reflektierte Strahlungsfeld, indem sie Strahlen von der Kamera aufnehmen und reflektieren, um die Augengeometrie anzunähern.
Um zu vermeiden, dass die Iris des menschlichen Auges in der Rekonstruktion erscheint, trainierte der Autor auch eine zweidimensionale Texturzuordnung, die die Iristextur lernte, um eine Texturzerlegung durchzuführen.




Experimentelle Auswertung
Synthetische Datenauswertung
Zuerst der Autor bestanden Das menschliche Augenmodell wurde in der Blender-Szene platziert und anhand synthetischer Daten ausgewertet.
Das Bild unten zeigt eine Szene, die nur mithilfe von Augenreflexionen rekonstruiert wurde.
Da die Hornhaut im wirklichen Leben nicht perfekt geschätzt werden kann, haben die Autoren die Robustheit der Hornhauthaltungsoptimierung gegenüber dem geschätzten Hornhautradiusrauschen bewertet.
Um Tiefenschätzungsfehler zu simulieren, die in realen Daten auftreten können, verfälschen die Autoren den beobachteten Hornhautradius r_img, indem sie ihn in jedem Bild mit unterschiedlichen Rauschpegeln skalieren.

Die folgende Abbildung zeigt die Leistungsänderungen bei unterschiedlichen Geräuschpegeln.
Es ist erwähnenswert, dass mit zunehmendem Rauschen die von den Autoren vorgeschlagene posenoptimierte Rekonstruktion im Hinblick auf die rekonstruierte Geometrie und Farbe robuster ist als die Rekonstruktion ohne Posenoptimierung.
Dies beweist, dass die Posenoptimierung für reale Szenarien von entscheidender Bedeutung ist, da die Passung von der projizierten Hornhaut zur anfänglichen Ellipse im Bild nicht perfekt ist.

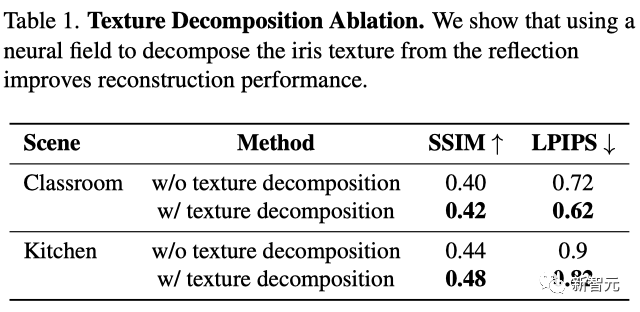
Darüber hinaus zeigen quantitative Vergleiche mit und ohne Texturzerlegung, dass die Methode der Autoren mit Texturzerlegung in Bezug auf SSIM und LPIPS besser abschneidet.
Es ist erwähnenswert, dass der Autor das PSNR nicht berechnet hat, da im Setup der Unterschied in der Beleuchtung zwischen Reflexionen und der Szene selbst sehr groß ist.
Real World Evaluation
Um den Realismus des Sichtfelds sicherzustellen, wählte der Autor eine Sony RX IV-Kamera für die Aufnahme und verwendete Adobe Lightroom, um das Bild nachzubearbeiten und zu verkleinern Hornhautreflexionen. Gleichzeitig fügte der Autor auf beiden Seiten der Figur Lichtquellen hinzu, um das Zielobjekt zu beleuchten.
Während des Vorgangs muss sich die zu fotografierende Person im Sichtfeld der Kamera bewegen, damit das Team in jeder Szene 5–15 Einzelbilder aufnehmen kann.
Aufgrund des großen Dynamikbereichs der Szenenbeleuchtung verwenden die Autoren in allen Experimenten 16-Bit-Bilder, um Informationsverluste in den beobachteten Reflexionen zu vermeiden.
Im Durchschnitt bedeckt die Hornhaut in jedem Bild nur etwa 0,1 % der Fläche, während das Zielobjekt, verschachtelt mit der Iristextur, etwa 20x20 Pixel einnimmt.

Datenverarbeitung
Der Autor erhält zunächst die anfängliche Positionsschätzung der Hornhaut, indem er die Hornhautmitte und den Radius des Bildes schätzt.
Anschließend wird die dreidimensionale Position der Hornhaut mithilfe einer direkten Näherung der durchschnittlichen Tiefe und der Brennweite der Kamera berechnet und ihre Oberflächennormale berechnet.
Um diesen Prozess zu automatisieren, verwendet der Autor Grounding Dino, um den Begrenzungsrahmen des Auges zu lokalisieren, und verwendet ELLSeg, um eine Ellipsenanpassung an der Iris durchzuführen.
Obwohl die Hornhaut normalerweise verschlossen ist, benötigen wir nur den nicht verschlossenen Bereich, sodass wir Segment Anything verwenden können, um eine Segmentierungsmaske für die Iris zu erhalten.

Echte Ergebnisse
Wie aus den in der Abbildung unten gezeigten Ergebnissen ersichtlich ist, ist die Methode des Autors in der Lage, 3D-Szenen aus realen Porträtbildern zu rekonstruieren, trotz der Anwesenheit von Hornhautposition und geometrische Schätzung der Ungenauigkeit.

Aufgrund der Unschärfe des Hornhautrandes ist eine genaue Positionierung im Bild sehr schwierig.
Außerdem ist die 3D-Rekonstruktion bei bestimmten Augenfarben wie Grün und Blau schwieriger, da die Iristextur heller ist.

Wenn außerdem keine explizite Modellierungstextur vorhanden ist, werden im rekonstruierten Bild mehr „schwebende Objekte“ angezeigt.
Um diese Probleme zu lösen, kann die Qualität der Rekonstruktion durch Erhöhen des Grads der radialen Regularisierung verbessert werden.

Diese Methode weist jedoch noch zwei wesentliche Einschränkungen auf.
Zuallererst basieren die aktuellen realen Ergebnisse auf „Laboreinstellungen“, wie z. B. dem Heranzoomen von Gesichtern, der Verwendung zusätzlicher Lichtquellen zur Beleuchtung der Szene usw. In einer freieren Umgebung müssen Sie sich größeren Herausforderungen wie einer geringeren Sensorauflösung, einem kleineren Dynamikbereich und Bewegungsunschärfe stellen.
Zweitens sind aktuelle Annahmen über die Iristextur (z. B. konstante Textur, radial konstante Farbe) möglicherweise zu stark vereinfacht, sodass die Methode möglicherweise fehlschlägt, wenn sich das Auge erheblich dreht.
Vorstellung des Autors
Co-Autor Kevin Zhang ist derzeit Doktorand an der University of Maryland.

Brandon Y. Feng promovierte in Informatik an der University of Maryland. Seine Forschungsinteressen konzentrieren sich auf Computational Imaging, Mid-Level Vision und Computational Photography. Er hat maschinelle Lernalgorithmen für die Bild- und 3D-Datenverarbeitung entwickelt, deren Anwendungen von Mixed Reality bis hin zu Naturwissenschaften reichen.

Jia-Bin Huang ist außerordentlicher Professor an der University of Maryland und hat zuvor an der UIUC promoviert. Die Forschungsinteressen konzentrieren sich auf die Schnittstelle zwischen Computer Vision, Computergrafik und maschinellem Lernen.

Das obige ist der detaillierte Inhalt vonAugapfelreflexion erschließt die 3D-Welt und macht Black Mirror Wirklichkeit! Das neue Werk von Maryland Chinese begeistert Science-Fiction-Fans. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr