
Heim >Technologie-Peripheriegeräte >KI >Der Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen
Der Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen

- 王林nach vorne
- 2023-06-16 17:01:40886Durchsuche
Am 14. Juni wurde Tencent Robotics erheblich verbessert.
Roboterhunde so flexibel und stabil wie Menschen und Tiere zu machen, war ein langfristiges Ziel im Bereich der Robotikforschung. Die kontinuierliche Weiterentwicklung der Deep-Learning-Technologie ermöglicht es Maschinen, relevante Fähigkeiten durch „Lernen“ zu beherrschen und zu lernen, mit komplexen und komplexen Situationen umzugehen veränderliche Umgebungen werden machbar.
Einführung vor dem Training und Verstärkungslernen: Den Roboterhund agiler machen
Tencent Robotics Sie müssen nicht neu lernen, aber Sie können das bereits erlernte mehrstufige Wissen über Körperhaltung, Umweltwahrnehmung und strategische Planung wiederverwenden und aus einem Beispiel Rückschlüsse ziehen, um flexibel mit komplexen Umgebungen umzugehen


Diese Lernreihe ist in drei Phasen unterteilt:
In der ersten Phase sammelte der Forscher mithilfe des Bewegungserfassungssystems, das häufig in der Spieletechnologie verwendet wird, die Bewegungshaltungsdaten echter Hunde, einschließlich Gehen, Laufen, Springen, Stehen und anderer Aktionen, und nutzte diese Daten, um eine Nachahmungslernaufgabe zu erstellen im Simulator, und dann werden die Informationen in diesen Daten abstrahiert und in tiefe neuronale Netzwerkmodelle komprimiert. Diese Modelle können nicht nur die gesammelten Informationen zur Tierbewegungshaltung genau abdecken, sondern weisen auch eine hohe Interpretierbarkeit auf.
Tencent Robotics Diese Technologien und Daten spielen eine gewisse Hilfsrolle bei der auf physikalischen Simulationen basierenden Agentenschulung und der Umsetzung realer Roboterstrategien.
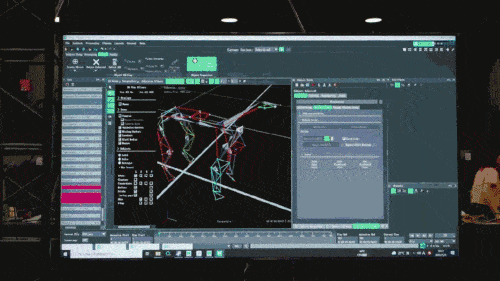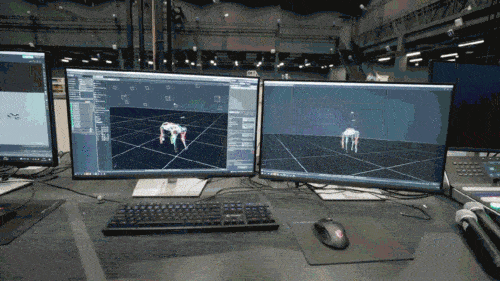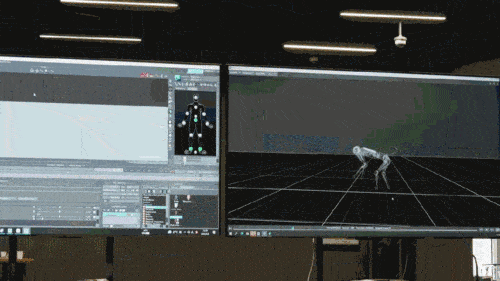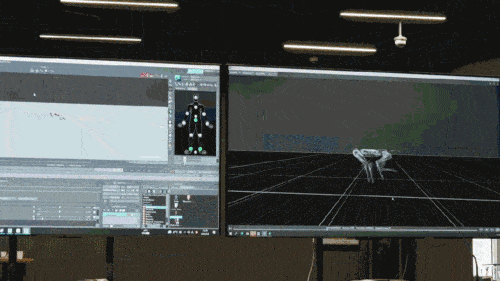

Das neuronale Netzwerkmodell akzeptiert nur die propriozeptiven Informationen des Roboterhundes (z. B. den motorischen Status) als Eingabe und wird auf eine imitierende Lernweise trainiert. Im nächsten Schritt bezieht das Modell sensorische Daten aus der Umgebung ein, beispielsweise durch die Verwendung anderer Sensoren zur Erkennung von Hindernissen unter den Füßen.
In der zweiten Stufe werden zusätzliche Netzwerkparameter verwendet, um die in der ersten Stufe erlernte intelligente Haltung des Roboterhundes mit der Außenwahrnehmung zu verbinden, sodass der Roboterhund durch die erlernte intelligente Haltung auf die äußere Umgebung reagieren kann. Wenn sich der Roboterhund an eine Vielzahl komplexer Umgebungen anpasst, wird auch das Wissen, das intelligente Körperhaltungen mit der Außenwahrnehmung verknüpft, gefestigt und in der neuronalen Netzwerkstruktur gespeichert.



In der dritten Stufe verfügt der Roboterhund unter Verwendung des in den beiden oben genannten Vortrainingsstufen erhaltenen neuronalen Netzwerks über die Voraussetzungen und die Möglichkeit, sich auf die Lösung des politischen Lernproblems der obersten Ebene zu konzentrieren, und verfügt schließlich über die Fähigkeit, komplexe Aufgaben zu lösen -zu Ende. In der dritten Phase werden weitere Netzwerke hinzugefügt, um Daten im Zusammenhang mit komplexen Aufgaben zu sammeln, beispielsweise um Informationen über Gegner und Flaggen im Spiel zu erhalten. Darüber hinaus lernt das für das Strategielernen verantwortliche neuronale Netzwerk durch eine umfassende Analyse aller Informationen übergeordnete Strategien für die Aufgabe, z. B. die Richtung, in die es laufen soll, das Vorhersagen des Verhaltens des Gegners, um zu entscheiden, ob die Verfolgung fortgesetzt werden soll usw.
Das in jeder der oben genannten Stufen erlernte Wissen kann ohne erneutes Lernen erweitert und angepasst werden, sodass es kontinuierlich angesammelt und kontinuierlich erlernt werden kann.
Robot Dog Obstacle Chase-Wettbewerb: Besitz autonomer Entscheidungs- und Kontrollfähigkeiten
Um diese von Max erworbenen neuen Fähigkeiten zu testen, ließ sich der Forscher vom Hindernisjagdspiel „World Chase Tag“ inspirieren und entwarf ein Hindernisjagdspiel für zwei Hunde. World Chase Tag ist eine 2014 im Vereinigten Königreich gegründete Wettbewerbsorganisation zur Hindernisjagd. Sie basiert auf beliebten Verfolgungsspielen für Kinder. Im Allgemeinen treten in jeder Runde des Hindernisjagd-Wettbewerbs zwei Athleten gegeneinander an. Einer ist der Verfolger (genannt Angreifer) und der andere ist der Ausweichmanöver (genannt Verteidiger). einen Punkt, wenn sie ihrem Gegner während der Verfolgungsrunde (d. h. 20 Sekunden) erfolgreich ausweichen (d. h. es kommt zu keinem Kontakt). Das Team, das in der vorgegebenen Anzahl an Verfolgungsrunden die meisten Punkte erzielt, gewinnt das Spiel.
Die Größe des Veranstaltungsortes für den Roboterhund-Hindernisjagd-Wettbewerb beträgt 4,5 x 4,5 Meter, wobei einige Hindernisse darauf verstreut sind. Zu Beginn des Spiels werden zwei MAX-Roboterhunde an zufälligen Orten auf dem Feld platziert, und einem Roboterhund wird zufällig die Rolle eines Verfolgers und dem anderen die eines Ausreißers zugewiesen. Gleichzeitig wird eine Flagge platziert an einer zufälligen Stelle im Feld.
Das Ziel des Dodgers ist es, so nah wie möglich an die Flagge heranzukommen, ohne vom Verfolger erwischt zu werden. Die Aufgabe des Verfolgers besteht darin, den Ausreißer zu fangen. Wenn es dem Dodger gelingt, die Flagge zu berühren, bevor er gefangen wird, wechseln die Rollen der beiden Roboterhunde sofort und die Flagge erscheint an einer anderen zufälligen Stelle wieder. Das Spiel endet, wenn der Ausweichmanöver vom aktuellen Verfolger gefangen wird und der Roboterhund, der die Rolle des Verfolgers spielt, gewinnt. In allen Spielen ist die durchschnittliche Vorwärtsgeschwindigkeit der beiden Roboterhunde auf 0,5 m/s begrenzt.
Aus diesem Spiel, das auf dem vorab trainierten Modell basiert, verfügt der Roboterhund durch tiefes Verstärkungslernen bereits über bestimmte Denk- und Entscheidungsfähigkeiten:
Wenn der Verfolger beispielsweise merkt, dass er den Ausweichmanöver nicht mehr einholen kann, bevor er die Flagge berührt, gibt er die Verfolgung auf und entfernt sich stattdessen vom Ausweichmanöver, um auf das nächste Zurücksetzen zu warten. Die Flagge erscheint .
Außerdem springt der Verfolger, wenn er im letzten Moment dabei ist, den Ausweichenden zu fangen, gerne auf und führt eine „Sprung“-Aktion auf den Ausweichenden aus, was dem Verhalten von Tieren beim Beutefang sehr ähnlich ist Wenn der Dodger dabei ist, die Flagge zu berühren, zeigt er das gleiche Verhalten. Dies alles sind proaktive Beschleunigungsmaßnahmen, die der Roboterhund ergreift, um seinen Sieg zu sichern.
Berichten zufolge handelt es sich bei allen Kontrollstrategien der Roboterhunde im Spiel um neuronale Netzwerkstrategien. Sie werden in Simulationen und durch Zero-Shot-Transfer (Zero-Adjustment-Transfer) erlernt, wodurch das neuronale Netzwerk menschliche Denkmethoden simulieren kann Entdecken Sie Dinge, die noch nie zuvor gesehen wurden, und wenden Sie dieses Wissen an echte Roboterhunde an. Wie in der folgenden Abbildung gezeigt, wird beispielsweise das Wissen über das Vermeiden von Hindernissen, das der Roboterhund im Vortrainingsmodell gelernt hat, im Spiel verwendet, auch wenn die Szenen mit Hindernissen nicht in der virtuellen Welt von Chase Tag Game trainiert werden ( (nur in der virtuellen Welt) Nach dem Training in Spielszenen auf ebenem Boden kann der Roboterhund die Aufgabe auch erfolgreich lösen.
Tencent Robotics Die Einführung im Roboterbereich verbessert die Steuerungsfähigkeiten von Robotern und macht sie flexibler. Dies schafft auch eine solide Grundlage dafür, dass Roboter in das wirkliche Leben eintreten und Menschen dienen können.
Das obige ist der detaillierte Inhalt vonDer Roboterhund von Tencent entwickelt sich weiter: Beherrschung autonomer Entscheidungsfähigkeiten durch tiefes Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr