
Heim >Technologie-Peripheriegeräte >KI >Neue Forschungsergebnisse von Yann LeCuns Team: Reverse Engineering des selbstüberwachten Lernens, es stellt sich heraus, dass Clustering auf diese Weise implementiert wird
Neue Forschungsergebnisse von Yann LeCuns Team: Reverse Engineering des selbstüberwachten Lernens, es stellt sich heraus, dass Clustering auf diese Weise implementiert wird

- 王林nach vorne
- 2023-06-15 11:27:541061Durchsuche
Selbstüberwachtes Lernen (SSL) hat in den letzten Jahren große Fortschritte gemacht und hat bei vielen nachgelagerten Aufgaben fast das Niveau überwachter Lernmethoden erreicht. Aufgrund der Komplexität des Modells und des Mangels an annotierten Trainingsdatensätzen war es jedoch schwierig, die erlernten Darstellungen und die ihnen zugrunde liegenden Arbeitsmechanismen zu verstehen. Darüber hinaus stehen Vorwandaufgaben, die beim selbstüberwachten Lernen verwendet werden, häufig nicht in direktem Zusammenhang mit bestimmten nachgelagerten Aufgaben, was die Komplexität der Interpretation der gelernten Darstellungen weiter erhöht. Bei der überwachten Klassifizierung ist die Struktur der erlernten Darstellung oft sehr einfach.
Im Vergleich zu herkömmlichen Klassifizierungsaufgaben (das Ziel besteht darin, Proben genau in bestimmte Kategorien zu klassifizieren) besteht das Ziel moderner SSL-Algorithmen normalerweise darin, eine Verlustfunktion zu minimieren, die zwei Hauptkomponenten enthält: Eine besteht darin, erweiterte Proben zu gruppieren (Invarianzbeschränkungen). , und die zweite besteht darin, den Zusammenbruch der Darstellung zu verhindern (Regularisierungsbeschränkungen). Beispielsweise besteht das Ziel der kontrastiven Lernmethode für dieselbe Probe nach unterschiedlichen Verbesserungen darin, die Klassifizierungsergebnisse dieser Proben gleich zu machen und gleichzeitig verschiedene Proben nach der Verbesserung unterscheiden zu können. Andererseits verwenden nicht-kontrastive Methoden Regularisierer, um einen Zusammenbruch der Darstellung zu vermeiden.
Selbstüberwachtes Lernen kann die unbeaufsichtigten Daten von Hilfsaufgaben (Vorwand) nutzen, um seine eigenen Überwachungsinformationen abzubauen und das Netzwerk anhand dieser konstruierten Überwachungsinformationen zu trainieren, sodass es wertvolle Darstellungen für nachgelagerte Aufgaben lernen kann. Kürzlich veröffentlichten mehrere Forscher, darunter der Turing-Preisträger Yann LeCun, eine Studie, in der sie behaupteten, selbstüberwachtes Lernen rückentwickelt zu haben, was es uns ermöglichte, das interne Verhalten seines Trainingsprozesses zu verstehen.
... Die Leute verstehen den Clustering-Prozess während des Trainings. Insbesondere zeigen wir, dass erweiterte Stichproben ein stark geclustertes Verhalten aufweisen, das Schwerpunkte um die Bedeutungseinbettungen erweiterter Stichproben bildet, die dasselbe Bild haben. Noch unerwarteter war, dass die Forscher beobachteten, dass sich Proben auf der Grundlage semantischer Bezeichnungen gruppierten, selbst wenn keine expliziten Informationen über die Zielaufgabe vorlagen. Dies zeigt die Fähigkeit von SSL, Stichproben basierend auf semantischer Ähnlichkeit zu gruppieren. 
ProblemstellungDa selbstüberwachtes Lernen (SSL) häufig für das Vortraining verwendet wird, um das Modell auf nachgelagerte Aufgaben vorzubereiten, wirft dies eine wichtige Frage auf: Welchen Einfluss hat SSL-Training auf die erlernten Darstellungen? Konkret: Wie funktioniert SSL während des Trainings unter der Haube und welche Kategorien können diese Darstellungsfunktionen lernen?
Um diese Probleme zu untersuchen, trainierten Forscher SSL-Netzwerke in mehreren Einstellungen und analysierten ihr Verhalten mit verschiedenen Techniken.
Daten und Augmentation: Alle in diesem Artikel erwähnten Experimente verwendeten den CIFAR100-Bildklassifizierungsdatensatz. Um das Modell zu trainieren, verwendeten die Forscher das in SimCLR vorgeschlagene Bildverbesserungsprotokoll. Jede SSL-Trainingssitzung wird für 1000 Epochen ausgeführt, wobei der SGD-Optimierer mit Dynamik verwendet wird.Backbone-Architektur: Bei allen Experimenten wurde die RES-L-H-Architektur als Backbone verwendet, gekoppelt mit zwei Schichten mehrschichtiger Perzeptron-Projektionsköpfe (MLP).
Lineare Sondierung: Um die Wirksamkeit des Extrahierens einer bestimmten diskreten Funktion (z. B. Kategorie) aus einer Darstellungsfunktion zu bewerten, wird hier die Methode der linearen Sondierung verwendet. Dies erfordert das Training eines linearen Klassifikators (auch lineare Sonde genannt) basierend auf dieser Darstellung, was einige Trainingsbeispiele erfordert.
Klassifizierung auf Probenebene: Um die Trennbarkeit auf Probenebene zu beurteilen, erstellten die Forscher einen speziellen neuen Datensatz.
Der Trainingsdatensatz enthält 500 zufällige Bilder aus dem CIFAR-100-Trainingssatz. Jedes Bild repräsentiert eine bestimmte Kategorie und wird auf 100 verschiedene Arten verbessert. Daher enthält der Trainingsdatensatz insgesamt 50.000 Stichproben aus 500 Kategorien. Der Testsatz verwendet immer noch diese 500 Bilder, verwendet jedoch 20 verschiedene Verbesserungen, alle aus derselben Distribution. Daher bestehen die Ergebnisse im Testsatz aus 10.000 Proben. Um die lineare oder NCC-Genauigkeit (Nearest Class Center/Nearest Class Center) einer bestimmten Darstellungsfunktion auf Stichprobenebene zu messen, besteht die hier verwendete Methode darin, zunächst die Trainingsdaten zur Berechnung eines relevanten Klassifikators zu verwenden und diesen dann zu berechnen Bewerten Sie die Genauigkeit des entsprechenden Testsatzes. Der Clustering-Prozess hat schon immer eine wichtige Rolle bei der Analyse von Deep-Learning-Modellen gespielt. Um das SSL-Training intuitiv zu verstehen, zeigt Abbildung 1 den Einbettungsraum der Trainingsbeispiele des Netzwerks durch UMAP-Visualisierung, der die Situation vor und nach dem Training umfasst und in verschiedene Ebenen unterteilt ist. Aufdeckung des Clustering-Prozesses des selbstüberwachten Lernens
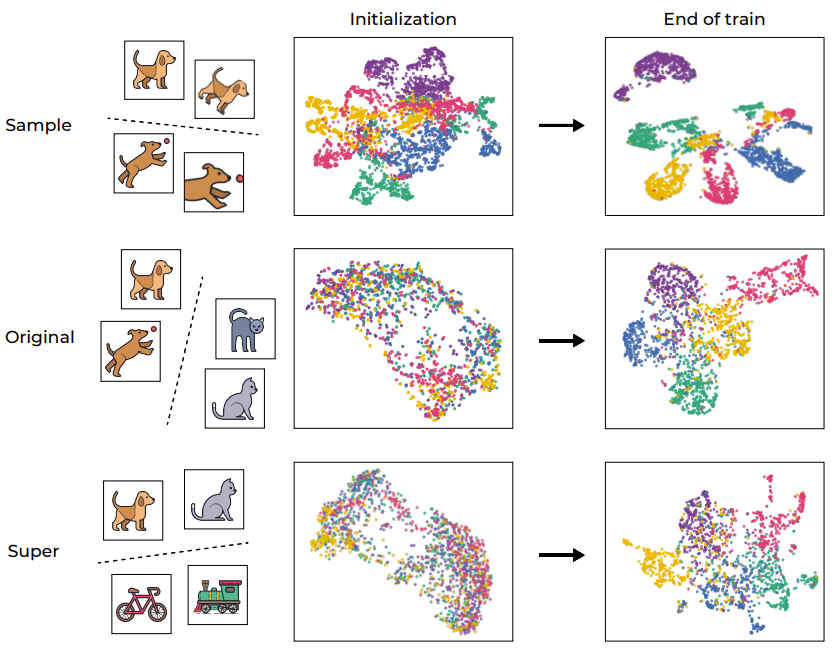
Abbildung 1: Durch SSL-Training induziertes semantisches Clustering
Wie erwartet hat der Trainingsprozess die Proben erfolgreich auf Probenebene geclustert und verschiedene Verbesserungen desselben Bildes abgebildet (wie in der ersten Zeile gezeigt). Dieses Ergebnis ist nicht unerwartet, da die Zielfunktion selbst dieses Verhalten fördert (über den Invarianzverlustterm). Bemerkenswerter ist jedoch, dass dieser Trainingsprozess auch Cluster basierend auf den ursprünglichen „semantischen Kategorien“ des Standard-CIFAR-100-Datensatzes erstellt, auch wenn es während des Trainingsprozesses an Beschriftungen mangelt. Interessanterweise können auch höhere Ebenen (Superkategorien) effizient geclustert werden. Dieses Beispiel zeigt, dass der Trainingsprozess zwar direkt die Clusterbildung auf Stichprobenebene fördert, die von SSL trainierten Datendarstellungen jedoch auch auf verschiedenen Ebenen nach semantischen Kategorien geclustert werden.
Um diesen Clusterprozess weiter zu quantifizieren, verwendeten die Forscher VICReg, um einen RES-10-250 zu trainieren. Die Forscher haben die NCC-Trainingsgenauigkeit gemessen, sowohl auf Stichprobenebene als auch basierend auf Originalkategorien. Es ist erwähnenswert, dass die SSL-trainierten Darstellungen auf Stichprobenebene einen neuronalen Kollaps aufweisen (NCC-Trainingsgenauigkeit liegt nahe bei 1,0), aber auch die Clusterbildung in Bezug auf semantische Kategorien ist signifikant (ungefähr 1,0 auf dem ursprünglichen Ziel) (0,41).
Wie im linken Bild von Abbildung 2 dargestellt, finden die meisten Clustering-Prozesse mit Erweiterung (auf denen das Netzwerk direkt trainiert wird) in den frühen Phasen des Trainingsprozesses statt und stagnieren dann, während die Clusterung in Bezug auf semantische Kategorien erfolgt (Das Trainingsziel (nicht angegeben) wird sich während des Trainings weiter verbessern.
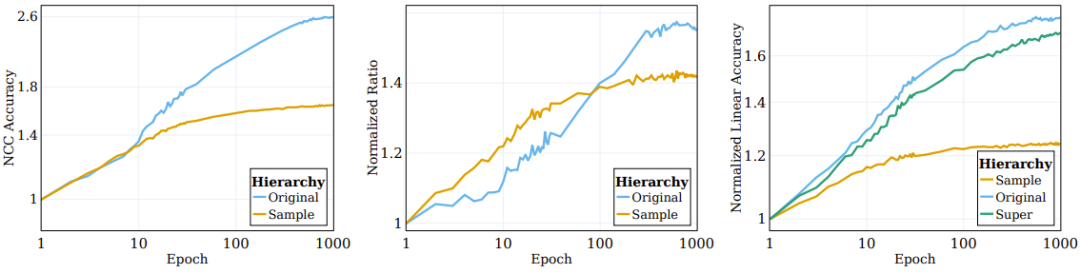
Abbildung 2: SSL-Algorithmus gruppiert Daten nach semantischen Zielpaaren
Frühere Forscher haben beobachtet, dass sich die Einbettung überwachter Trainingsmuster auf oberster Ebene allmählich in Richtung einer strukturellen Konvergenz des Klassenschwerpunkts bewegt . Um die Clustering-Natur von SSL-trainierten Darstellungsfunktionen besser zu verstehen, haben wir ähnliche Situationen während SSL untersucht. Sein NCC-Klassifikator ist ein linearer Klassifikator und weist keine bessere Leistung als der beste lineare Klassifikator auf. Die Datenclusterung kann auf verschiedenen Granularitätsebenen untersucht werden, indem die Genauigkeit des NCC-Klassifikators im Vergleich zu einem linearen Klassifikator bewertet wird, der auf denselben Daten trainiert wurde. Das mittlere Feld von Abbildung 2 zeigt die Entwicklung dieses Verhältnisses über Kategorien auf Stichprobenebene und ursprüngliche Zielkategorien hinweg, wobei die Werte auf die initialisierten Werte normalisiert sind. Mit fortschreitendem SSL-Training wird die Lücke zwischen NCC-Genauigkeit und linearer Genauigkeit kleiner, was darauf hindeutet, dass die erweiterten Stichproben den Clustering-Grad basierend auf ihren Stichprobenidentitäten und semantischen Eigenschaften allmählich verbessern.
Darüber hinaus zeigt die Abbildung auch, dass das Verhältnis auf Stichprobenebene anfänglich höher sein wird, was darauf hinweist, dass die erweiterten Stichproben entsprechend ihrer Identität geclustert werden, bis sie zum Schwerpunkt konvergieren (das Verhältnis zwischen NCC-Genauigkeit und linearer Genauigkeit liegt bei). ≥ 0,9 bei 100 Epochen). Mit fortschreitendem Training sättigen sich jedoch die Verhältnisse auf Stichprobenebene, während die Verhältnisse auf Klassenebene weiter ansteigen und sich etwa 0,75 annähern. Dies zeigt, dass die erweiterten Stichproben zunächst nach der Stichprobenidentität geclustert werden und nach der Implementierung nach semantischen Kategorien auf hoher Ebene geclustert werden.
Implizite Informationskomprimierung im SSL-Training
Wenn die Komprimierung effektiv durchgeführt werden kann, können vorteilhafte und nützliche Darstellungen erhalten werden. Ob eine solche Komprimierung jedoch während des SSL-Trainings auftritt, ist immer noch ein Thema, das nur wenige Menschen untersucht haben.
Um dies zu verstehen, verwendeten die Forscher Mutual Information Neural Estimation (MINE), eine Methode, die die gegenseitige Information zwischen der Eingabe und ihrer entsprechenden eingebetteten Darstellung während des Trainings schätzt. Diese Metrik kann verwendet werden, um den Komplexitätsgrad einer Darstellung effektiv zu messen, indem sie zeigt, wie viele Informationen (Anzahl der Bits) sie codiert.
Das mittlere Feld von Abbildung 3 zeigt die durchschnittliche gegenseitige Information, die für 5 verschiedene MINE-Initialisierungs-Seeds berechnet wurde. Wie in der Abbildung dargestellt, kommt es während des Trainingsprozesses zu einer erheblichen Komprimierung, was zu einer äußerst kompakten Trainingsdarstellung führt.
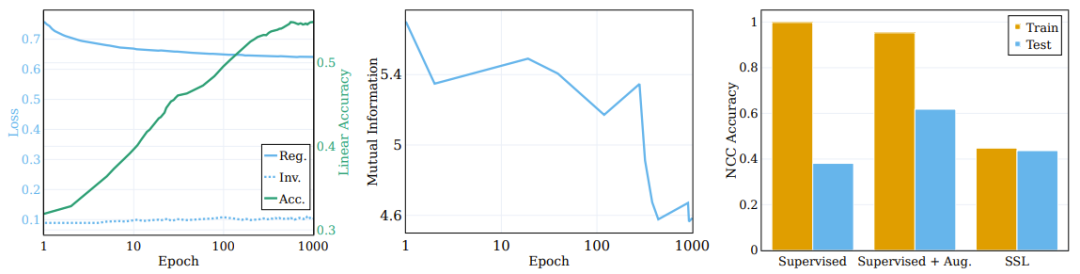
Das Diagramm auf der linken Seite zeigt die Änderungen der Regularisierung und des Invarianzverlusts während des Trainings des SSL-Trainingsmodells sowie die ursprüngliche Zielgenauigkeit des linearen Tests. (Mitte) Komprimierung gegenseitiger Informationen zwischen Eingabe und Darstellung während des Trainings. (Rechts) SSL-Training lernt Darstellungen von Clustern.
Die Rolle des Regularisierungsverlusts
Die Zielfunktion enthält zwei Elemente: Invarianz und Regularisierung. Die Hauptfunktion des Invarianzterms besteht darin, die Ähnlichkeit zwischen unterschiedlich verbesserten Darstellungen derselben Stichprobe zu verstärken. Das Ziel des Regularisierungsbegriffs besteht darin, einen Zusammenbruch der Repräsentation zu verhindern.
Um die Rolle dieser Komponenten im Clustering-Prozess zu untersuchen, zerlegten die Forscher die Zielfunktion in Invarianzterme und Regularisierungsterme und beobachteten deren Verhalten während des Trainingsprozesses. Die Vergleichsergebnisse sind im linken Bereich von Abbildung 3 dargestellt, wo die Entwicklung des Verlustterms auf dem ursprünglichen semantischen Ziel und die Genauigkeit des linearen Tests angegeben sind. Entgegen der landläufigen Meinung verbessert sich der Invarianzverlustterm während des Trainings nicht wesentlich. Stattdessen werden Verbesserungen des Verlusts (und der nachgelagerten semantischen Genauigkeit) durch die Reduzierung des Regularisierungsverlusts erreicht.
Es kann gefolgert werden, dass der größte Teil des SSL-Trainingsprozesses darin besteht, die semantische Genauigkeit und das Clustering gelernter Darstellungen zu verbessern, und nicht die Klassifizierungsgenauigkeit und Clustering auf Stichprobenebene.
Im Wesentlichen zeigen die Ergebnisse hier, dass, obwohl das direkte Ziel des selbstüberwachten Lernens die Klassifizierung auf Stichprobenebene ist, der Großteil der Trainingszeit tatsächlich für die Gruppierung von Daten basierend auf semantischen Kategorien auf verschiedenen Ebenen aufgewendet wird. Diese Beobachtung zeigt die Fähigkeit von SSL-Methoden, durch Clustering semantisch bedeutsame Darstellungen zu generieren, was uns auch ermöglicht, die zugrunde liegenden Mechanismen zu verstehen.
Vergleich von überwachtem Lernen und SSL-Clustering
Deep-Network-Klassifikatoren neigen dazu, Trainingsbeispiele basierend auf ihren Kategorien in verschiedene Schwerpunkte zu gruppieren. Damit die erlernte Funktion jedoch tatsächlich geclustert wird, muss diese Eigenschaft für das Testbeispiel weiterhin gültig sein. Dies ist der erwartete Effekt, der Effekt wird jedoch etwas schlechter sein.
Eine interessante Frage hier: Inwieweit kann SSL im Vergleich zum Clustering durch überwachtes Lernen ein Clustering basierend auf den semantischen Kategorien von Stichproben durchführen? Das rechte Feld von Abbildung 3 zeigt das NCC-Trainings- und Testgenauigkeitsverhältnis am Ende des Trainings für verschiedene Szenarien (mit und ohne verbessertes überwachtes Lernen und SSL).
Obwohl die NCC-Trainingsgenauigkeit des überwachten Klassifikators 1,0 beträgt, was deutlich höher ist als die NCC-Trainingsgenauigkeit des SSL-trainierten Modells, ist die NCC-Testgenauigkeit des SSL-Modells etwas höher als die NCC-Testgenauigkeit des betreutes Modell Spend. Dies zeigt, dass das Clustering-Verhalten der beiden Modelle nach semantischen Kategorien bis zu einem gewissen Grad ähnlich ist. Interessanterweise verringert die Verwendung erweiterter Stichproben zum Trainieren eines überwachten Modells die NCC-Trainingsgenauigkeit geringfügig, verbessert jedoch die NCC-Testgenauigkeit erheblich.
Untersuchung der Auswirkungen des Lernens semantischer Kategorien und der Zufälligkeit
Semantische Kategorien definieren die Beziehung zwischen Eingabe und Ziel basierend auf den intrinsischen Mustern der Eingabe. Wenn Sie andererseits Eingaben zufälligen Zielen zuordnen, werden Sie einen Mangel an erkennbaren Mustern feststellen, was dazu führt, dass die Verbindung zwischen Eingabe und Ziel willkürlich aussieht.
Die Forscher untersuchten auch den Einfluss der Zufälligkeit auf die Kompetenz des Ziels, die für das Modelllernen erforderlich ist. Dazu konstruierten sie eine Reihe von Zielsystemen mit unterschiedlichem Grad an Zufälligkeit und untersuchten anschließend die Auswirkung der Zufälligkeit auf die erlernten Darstellungen. Sie trainierten einen neuronalen Netzwerkklassifikator mit demselben Datensatz, der für die Klassifizierung verwendet wurde, und verwendeten dann dessen Zielvorhersagen aus verschiedenen Epochen als Ziele mit unterschiedlichem Grad an Zufälligkeit. In Epoche 0 ist das Netzwerk völlig zufällig und erhält deterministische, aber scheinbar willkürliche Bezeichnungen. Mit fortschreitendem Training nimmt die Zufälligkeit seiner Funktion ab, und schließlich wird ein Ziel erreicht, das mit dem Grundwahrheitsziel übereinstimmt (das als völlig nicht zufällig betrachtet werden kann). Der Grad der Zufälligkeit wird hier auf einen Bereich von 0 (überhaupt nicht zufällig, am Ende des Trainings) bis 1 (völlig zufällig, bei der Initialisierung) normalisiert.
Abbildung 4 Das linke Bild zeigt die lineare Testgenauigkeit für verschiedene Zufallsziele. Jede Zeile entspricht der Genauigkeit verschiedener SSL-Trainingsstufen mit unterschiedlichem Zufälligkeitsgrad. Es ist ersichtlich, dass das Modell während des Trainings Kategorien effizienter erfasst, die näher am „semantischen“ Ziel liegen (geringere Zufälligkeit), während es bei Zielen mit hoher Zufälligkeit keine signifikante Leistungsverbesserung zeigt.
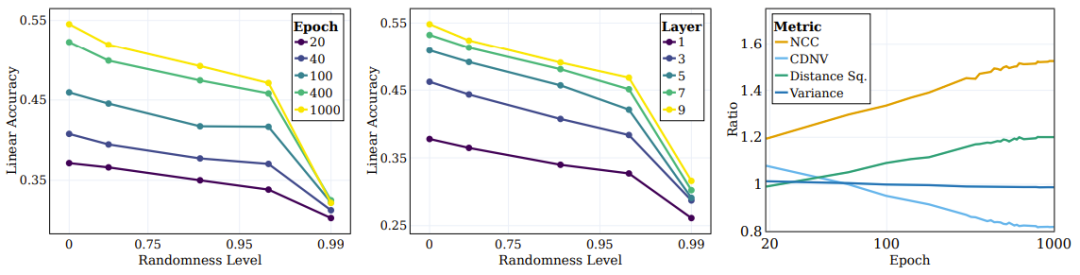
Abbildung 4: SSL lernt kontinuierlich semantische Ziele anstelle von Zufallszielen
Ein zentrales Problem beim Deep Learning ist das Verständnis der Rolle der Mittelschichten bei der Klassifizierung verschiedener Arten von Kategorien und Einfluss. Lernen verschiedene Ebenen beispielsweise unterschiedliche Arten von Kategorien? Forscher haben dieses Problem auch untersucht, indem sie die lineare Testgenauigkeit verschiedener Darstellungsebenen am Ende des Trainings auf unterschiedlichen Ebenen der Zielzufälligkeit bewertet haben. Wie im mittleren Bereich von Abbildung 4 dargestellt, verbessert sich die Genauigkeit linearer Tests mit abnehmender Zufälligkeit weiter, wobei tiefere Schichten über alle Kategorietypen hinweg eine bessere Leistung erbringen und die Leistungslücke bei Klassifizierungen in der Nähe semantischer Kategorien größer wird.
Die Forscher verwendeten auch einige andere Metriken, um die Qualität der Clusterbildung zu bewerten: NCC-Genauigkeit, CDNV, durchschnittliche Varianz pro Klasse und durchschnittlicher quadrierter Abstand zwischen Klassenmittelwerten. Um zu messen, wie sich Darstellungen durch Training verbessern, haben wir das Verhältnis dieser Metriken für semantische und zufällige Ziele berechnet. Das rechte Feld von Abbildung 4 veranschaulicht diese Verhältnisse, die zeigen, dass die Darstellung die Clusterung von Daten basierend auf semantischen Zielen statt auf zufälligen Zielen bevorzugt. Interessanterweise kann man sehen, dass CDNV (Varianz dividiert durch quadrierte Distanz) einfach durch die Verringerung der quadrierten Distanz abnimmt. Das Varianzverhältnis ist während des Trainings ziemlich stabil. Dies fördert größere Abstände zwischen Clustern, ein Phänomen, das nachweislich zu Leistungsverbesserungen führt.
Verstehen Sie die Kategoriehierarchie und die Zwischenschichten.
Frühere Untersuchungen haben gezeigt, dass Zwischenschichten beim überwachten Lernen nach und nach Merkmale auf verschiedenen Abstraktionsebenen erfassen. Erste Schichten tendieren zu Merkmalen auf niedriger Ebene, während tiefere Schichten abstraktere Merkmale erfassen. Als nächstes untersuchten die Forscher, ob SSL-Netzwerke hierarchische Attribute auf höheren Ebenen lernen können und welche Ebenen besser mit diesen Attributen korrelieren.
Im Experiment berechneten sie die lineare Testgenauigkeit auf drei Ebenen: Stichprobenebene, ursprüngliche 100 Kategorien und 20 Superkategorien. Das rechte Feld von Abbildung 2 zeigt die für diese drei verschiedenen Kategorien berechneten Mengen. Es ist zu beobachten, dass während des Trainingsprozesses die Leistungsverbesserung auf der Ebene der ursprünglichen Kategorie und der Superkategorie signifikanter ist als auf der Stichprobenebene.
Als nächstes geht es um das Verhalten der mittleren Schichten des SSL-trainierten Modells und ihre Fähigkeit, Ziele auf verschiedenen Ebenen zu erfassen. Die linken und mittleren Felder von Abbildung 5 geben die lineare Testgenauigkeit für alle Zwischenschichten in verschiedenen Trainingsstadien an, in denen das ursprüngliche Ziel und das Superziel gemessen werden. Das rechte Feld von Abbildung 5 zeigt das Verhältnis zwischen Superkategorien und Originalkategorien.
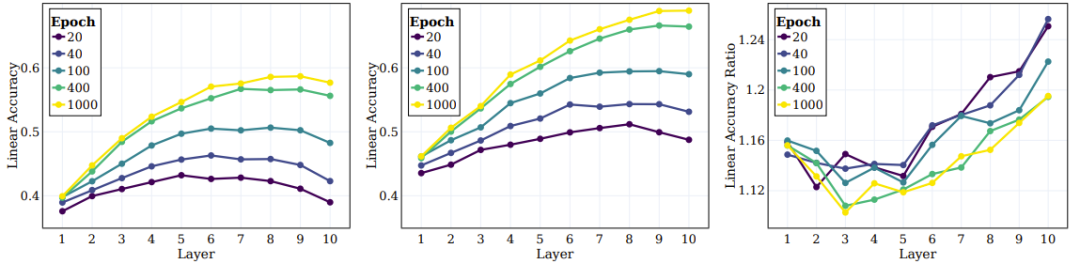
Abbildung 5: SSL kann semantische Kategorien in der gesamten Mittelschicht effektiv lernen
Die Forscher kamen aufgrund dieser Ergebnisse zu mehreren Schlussfolgerungen. Erstens ist zu beobachten, dass sich der Clustering-Effekt mit zunehmender Schichttiefe weiter verbessert. Darüber hinaus stellten die Forscher ähnlich wie beim überwachten Lernen fest, dass sich die lineare Genauigkeit jeder Schicht des Netzwerks während des SSL-Trainings verbesserte. Insbesondere stellten sie fest, dass die letzte Ebene nicht die optimale Ebene für die ursprüngliche Klasse war. Einige aktuelle SSL-Untersuchungen zeigen, dass nachgelagerte Aufgaben die Leistung verschiedener Algorithmen stark beeinträchtigen können. Unsere Arbeit erweitert diese Beobachtung und legt nahe, dass verschiedene Teile des Netzwerks für verschiedene nachgelagerte Aufgaben und Aufgabenebenen geeignet sein können. Aus dem rechten Bereich von Abbildung 5 ist ersichtlich, dass sich in tieferen Schichten des Netzwerks die Genauigkeit von Superkategorien stärker verbessert als die von Originalkategorien.
Das obige ist der detaillierte Inhalt vonNeue Forschungsergebnisse von Yann LeCuns Team: Reverse Engineering des selbstüberwachten Lernens, es stellt sich heraus, dass Clustering auf diese Weise implementiert wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr