
Heim >Technologie-Peripheriegeräte >KI >Meta-Open-Source-Text generiert ein großes Musikmodell. Wir haben es mit den Texten von „Qilixiang' versucht.
Meta-Open-Source-Text generiert ein großes Musikmodell. Wir haben es mit den Texten von „Qilixiang' versucht.

- 王林nach vorne
- 2023-06-13 21:16:172022Durchsuche
Bevor wir den Haupttext eingeben, hören wir uns zwei von MusicGen generierte Musikstücke an. Wir geben die Textbeschreibung „Ein Mann geht im Regen, stoßen auf ein schönes Mädchen und sie tanzen glücklich“
ein und versuchen dann, die ersten beiden Sätze in den Text von Jay Chous „Qili Xiang“ einzugeben: „Die Spatzen“. Draußen vor dem Fenster stehen sie gesprächig an den Telefonmasten. Du hast gesagt, dieser Satz lässt es sich wie im Sommer anfühlen Text zu Musik bezieht sich auf den Text im gegebenen Text. Die Aufgabe, eine musikalische Komposition in der beschriebenen Situation zu generieren, wie zum Beispiel „90er-Jahre-Gitarrenriff-Rocksong“. Beim Generieren von Musik ist das Modellieren langer Sequenzen eine anspruchsvolle Aufgabe. Im Gegensatz zu Sprache erfordert Musik die Nutzung des gesamten Spektrums, was bedeutet, dass das Signal mit einer höheren Rate abgetastet wird, d. h. die Standardabtastrate für Musikaufnahmen beträgt 44,1 kHz oder 48 kHz, während Sprache mit 16 kHz abgetastet wird.
Darüber hinaus enthält Musik die Harmonie und Melodie verschiedener Instrumente, was der Musik eine komplexe Struktur verleiht. Da menschliche Zuhörer jedoch sehr empfindlich auf Dissonanzen reagieren, haben sie keine große Toleranz gegenüber Melodien in generierter Musik. Natürlich ist die Fähigkeit, den Generierungsprozess auf vielfältige Weise zu steuern, für Musikschaffende unerlässlich, beispielsweise über Tonarten, Instrumente, Melodien, Genres usw.
Die jüngsten Fortschritte beim selbstüberwachten Lernen der Audiodarstellung, der Sequenzmodellierung und der Audiosynthese bieten die Voraussetzungen für die Entwicklung solcher Modelle. Um die Audiomodellierung zu vereinfachen, schlagen neuere Forschungsergebnisse vor, Audiosignale als einen Strom diskreter Token darzustellen, die „dasselbe Signal darstellen“. Dies ermöglicht eine hochwertige Audioerzeugung und eine effiziente Audiomodellierung. Dies erfordert jedoch die gemeinsame Modellierung mehrerer paralleler Abhängigkeitsflüsse.Kharitonov et al. [2022] und Kreuk et al. [2022] schlugen vor, eine Verzögerungsmethode zu verwenden, um mehrere Streams von Sprachtokens parallel zu modellieren, d. h. Offsets zwischen verschiedenen Streams einzuführen. Agostinelli et al. [2023] schlugen vor, mehrere diskrete Token-Sequenzen unterschiedlicher Granularität zu verwenden, um Musikfragmente darzustellen und diese mithilfe einer Hierarchie autoregressiver Modelle zu modellieren. Unterdessen verfolgten Donahue et al. [2023] einen ähnlichen Ansatz, konzentrierten sich jedoch auf die Aufgabe des Singens auf die Generierung von Begleitung. Kürzlich schlugen Wang et al. [2023] vor, dieses Problem in zwei Schritten zu lösen: die Modellierung auf den ersten Token-Stream zu beschränken. Anschließend wird ein Post-Netzwerk angewendet, um die verbleibenden Flüsse gemeinsam auf nicht-autoregressive Weise zu modellieren.
In diesem Artikel schlagen Forscher von Meta AI MUSICGEN vor, ein einfaches und kontrollierbares Musikgenerierungsmodell, das anhand einer Textbeschreibung hochwertige Musik generieren kann. Der Forscher schlägt eine Methode zur Modellierung mehrerer paralleler akustischer Token-Streams vor s Der General Das Framework dient als Zusammenfassung früherer Forschungsarbeiten (siehe Abbildung 1 unten). Um die Steuerbarkeit generierter Samples zu verbessern, werden in diesem Artikel auch unbeaufsichtigte Melodiebedingungen eingeführt, die es dem Modell ermöglichen, strukturell passende Musik basierend auf gegebener Harmonie und Melodie zu erzeugen. In diesem Artikel wird eine umfassende Evaluierung von MUSICGEN durchgeführt, und die vorgeschlagene Methode übertrifft die Bewertungsgrundlagen bei weitem: MUSICGEN erhält eine subjektive Bewertung von 84,8 von 100, verglichen mit 80,5 für die beste Basislinie. Darüber hinaus enthält dieser Artikel eine Ablationsstudie, die die Bedeutung jeder Komponente für die Gesamtleistung des Modells veranschaulicht.
Abschließend zeigt die menschliche Auswertung, dass MUSICGEN qualitativ hochwertige Samples produziert, die sowohl der Textbeschreibung entsprechen als auch melodisch besser auf die vorgegebene harmonische Struktur abgestimmt sind.
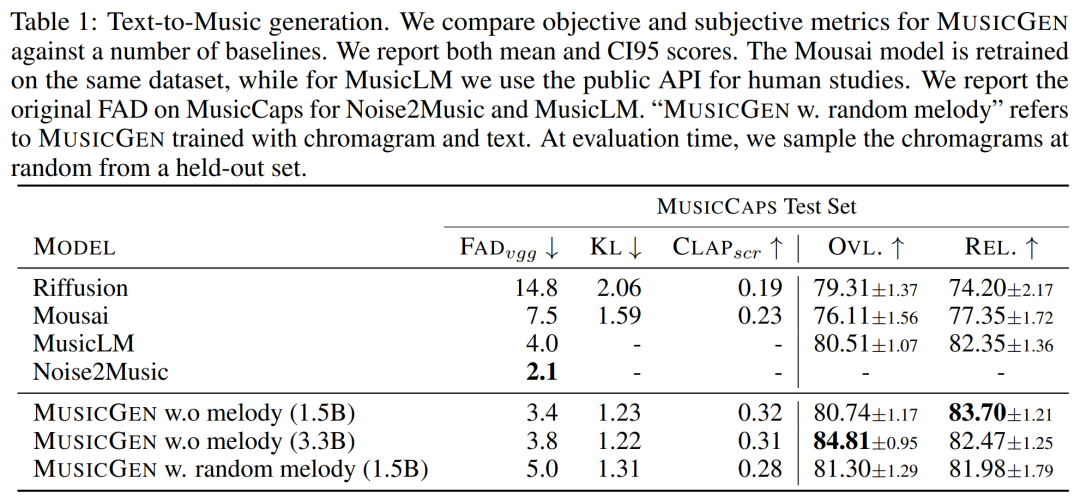
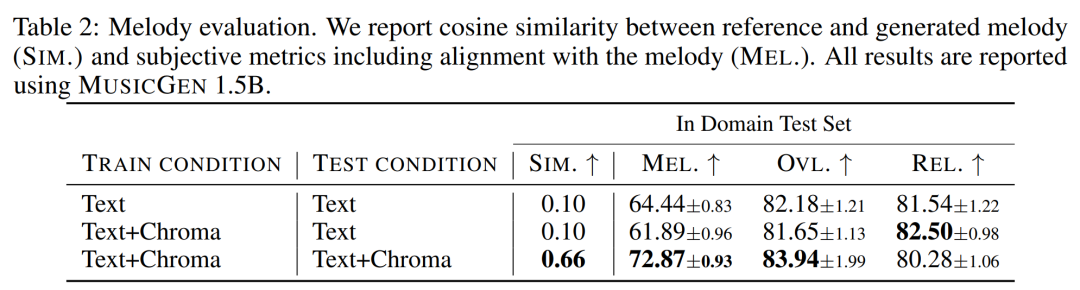
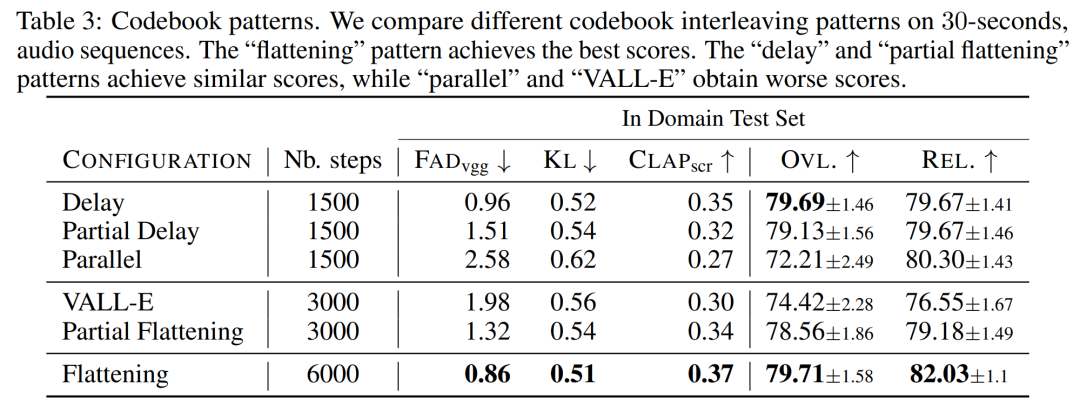
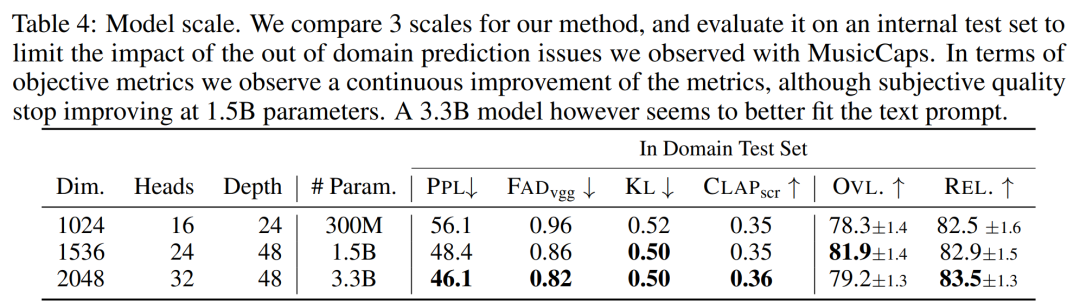
Die Hauptbeiträge dieses Artikels sind wie folgt: MUSICGEN enthält einen autoregressiven transformatorbasierten Decoder, der auf einer Text- oder Melodiedarstellung basiert. Das (Sprach-)Modell basiert auf der Quantisierungseinheit des EnCodec-Audio-Tokenizers, der eine High-Fidelity-Rekonstruktion aus diskreten Low-Frame-Darstellungen ermöglicht. Darüber hinaus erzeugen Komprimierungsmodelle mit Restvektorquantisierung (RVQ) mehrere parallele Streams. In dieser Einstellung besteht jeder Stream aus diskreten Token aus verschiedenen erlernten Codebüchern. In früheren Arbeiten wurden einige Modellierungsstrategien zur Lösung dieses Problems vorgeschlagen. Die Forscher schlugen einen neuartigen Modellierungsrahmen vor, der auf verschiedene Codebuch-Interleaving-Modi verallgemeinert werden kann. Es gibt auch mehrere Variationen dieses Frameworks. Basierend auf Mustern können sie die interne Struktur quantisierter Audio-Tokens nutzen. Schließlich unterstützt MUSICGEN die bedingte Generierung basierend auf Text oder Melodie. Audio-Tokenisierung Die Forscher verwendeten EnCodec, einen Faltungs-Autoencoder mit einem latenten Raum unter Verwendung von RVQ-Quantisierung und einem kontradiktorischen Rekonstruktionsverlust. Gegeben sei eine Referenz-Audio-Zufallsvariable X ∈ R^d·f_s, wobei d die Audiodauer und f_s die Abtastrate darstellt. EnCodec kodiert diese Variable in einen kontinuierlichen Tensor mit der Bildrate f_r ≪ f_s, und dann wird die Darstellung als Q ∈ {1 , N}^K×d・f_r quantisiert, wobei K das in RVQ Quantity verwendete Codebuch darstellt. N stellt die Codebuchgröße dar. Codebuch-Interleaved-Modus Exakte abgeflachte autoregressive Zerlegung. Das autoregressive Modell erfordert eine diskrete Zufallsfolge U ∈ {1, . Konventionell verwenden Forscher U_0 = 0, ein deterministisches Spezialtoken, das den Anfang der Sequenz darstellt. Anschließend können sie die Verteilung modellieren. Ungenaue autoregressive Zerlegung. Eine andere Möglichkeit besteht darin, die autoregressive Zerlegung in Betracht zu ziehen, wobei einige Codebücher parallele Vorhersagen erfordern. Definieren Sie beispielsweise eine andere Folge, V_0 = 0, und t∈ {1, . Wenn der Codebuchindex k entfernt wird (z. B. V_t), stellt dies die Verkettung aller Codebücher zum Zeitpunkt t dar. Beliebiger Codebuch-Interleaving-Modus. Um mit solchen Zerlegungen zu experimentieren und die Auswirkungen der Verwendung ungenauer Zerlegungen genau zu messen, führten die Forscher einen Codebuch-Interleaving-Modus ein. Betrachten Sie zunächst Ω = {(t, k) : {1, . f_r}, k ∈ {1, . Das Codebuchmuster ist die Folge P=(P_0, P_1, P_2, . . , P_S), wobei P_0 = ∅ und 0 Modellkonditionalisierung Textkonditionalisierung. Angenommen eine Textbeschreibung, die mit einem Eingabeaudio übereinstimmt Melodienkonditionierung. Während Text heute der vorherrschende Ansatz für bedingte generative Modelle ist, besteht ein natürlicherer Ansatz für Musik darin, eine melodische Struktur aus einer anderen Audiospur oder sogar Pfeifen oder Summen als Bedingung zu verwenden. Dieser Ansatz ermöglicht auch eine iterative Optimierung der Modellausgaben. Um dies zu unterstützen, haben wir versucht, die Melodiestruktur durch gemeinsame Modulation des Eingabechromatogramms und der Textbeschreibung zu steuern. In ersten Experimenten stellten sie fest, dass die Konditionierung am Originalchromatogramm häufig die Originalprobe rekonstruierte, was zu einer Überanpassung führte. Zu diesem Zweck wählen Forscher in jedem Zeitschritt große Zeit-Frequenz-Bins aus, um Informationsengpässe zu verursachen. Modellarchitektur Codebuchprojektion und Positionseinbettung. Bei einem gegebenen Codebuchmuster existieren in jedem Musterschritt P_s nur einige Codebücher. Der Forscher ruft den Wert von Q ab, der dem Index in P_s entspricht. Jedes Codebuch erscheint in P_s höchstens einmal oder überhaupt nicht. Transformator-Decoder. Der Eingang wird in einen Transformator mit L-Schichten und D-Dimensionen eingespeist, wobei jede Schicht aus einem kausalen Selbstaufmerksamkeitsblock besteht. Anschließend wird ein Queraufmerksamkeitsblock verwendet, der durch das Konditionierungssignal C bereitgestellt wird. Bei Verwendung der melodischen Konditionierung stellt der Forscher dem Transformatoreingang den konditionierten Tensor C voran. Logits-Vorhersage. Im Musterschritt P_s wird die Ausgabe des Transformatordecoders in Logits-Vorhersagen von Q-Werten umgewandelt. Jedes Codebuch erscheint höchstens einmal in P_s+1. Wenn das Codebuch vorhanden ist, wird eine codebuchspezifische lineare Schicht vom D-Kanal zum N-Kanal angewendet, um Logits-Vorhersagen zu erhalten. Audio-Tokenisierungsmodell. Die Studie verwendet ein nicht-kausales fünfschichtiges EnCodec-Modell für 32-kHz-Mono-Audio mit einem Schritt von 640, einer Bildrate von 50 Hz und einer anfänglichen versteckten Größe von 64, die in jeder der fünf Schichten des Modells verdoppelt wird . Transformer-Modell, untersuchte und trainierte autoregressive Transformer-Modelle unterschiedlicher Größe: 300M-, 1,5B-, 3,3B-Parameter. Trainingsdatensatz. Lernen Sie mit 20.000 Stunden lizenzierter Musik, um MUSICGEN zu trainieren. Im Detail verwendete die Studie einen internen Datensatz mit 10.000 hochwertigen Titeln sowie die Musikdatensätze ShutterStock und Pond5 mit 25.000 bzw. 365.000 reinen Instrumentaltiteln. Bewertungsdatensatz. Die Studie bewertet die vorgeschlagene Methode anhand des MusicCaps-Benchmarks und vergleicht sie mit früheren Arbeiten. MusicCaps bestehen aus 5,5.000 Samples (10 Sekunden lang), die von erfahrenen Musikern erstellt wurden, und 1.000 Teilmengen, die über verschiedene Genres verteilt sind. Tabelle 1 unten zeigt den Vergleich der vorgeschlagenen Methode mit Mousai, Riffusion, MusicLM und Noise2Music. Die Ergebnisse zeigen, dass MUSICGEN die von menschlichen Zuhörern bewerteten Basiswerte in Bezug auf Audioqualität und Konsistenz mit der bereitgestellten Textbeschreibung übertrifft. Noise2Music schneidet bei FAD auf MusicCaps am besten ab, gefolgt von MUSICGEN, das mit Textbedingungen trainiert wurde. Interessanterweise verschlechterte das Hinzufügen der Melodiebedingung die objektiven Messwerte, hatte jedoch keinen signifikanten Einfluss auf die menschlichen Bewertungen und war immer noch besser als die bewertete Basislinie. Die Forscher verwendeten objektive und subjektive Messungen des angegebenen Bewertungssatzes, um MUSICGEN unter den üblichen Bedingungen der Text- und Melodiedarstellung zu bewerten. Die Ergebnisse sind in Tabelle 2 unten aufgeführt. Die Ergebnisse zeigen, dass MUSICGEN, das mit Chromatogramm-Konditionalisierung trainiert wurde, erfolgreich Musik generiert, die einer bestimmten Melodie folgt, was eine bessere Kontrolle über die erzeugte Ausgabe ermöglicht. MUSICGEN ist robust gegenüber einem Abfall des Chromas zur Inferenzzeit unter Verwendung von OVL und REL. Die Auswirkungen des Codebuch-Interleaving-Modus. Wir haben verschiedene Codebuchmuster mithilfe des Frameworks in Abschnitt 2.2, K = 4, bewertet, das durch das Audio-Tokenisierungsmodell gegeben ist. In diesem Artikel werden objektive und subjektive Bewertungen in der folgenden Tabelle 3 aufgeführt. Obwohl das Flattening die Generierung verbessert, ist es rechenintensiv. Mit einfachen Verzögerungsmethoden kann eine ähnliche Leistung zu einem Bruchteil der Kosten erzielt werden. Der Effekt der Modellgröße. In der folgenden Tabelle 4 sind die Ergebnisse für verschiedene Modellgrößen aufgeführt, nämlich für die parametrischen Modelle 300M, 1,5B und 3,3B. Wie erwartet führt eine Vergrößerung der Modellgröße zu besseren Ergebnissen, allerdings nur auf Kosten längerer Trainings- und Inferenzzeiten. In Bezug auf die subjektive Bewertung ist die Gesamtqualität mit 1,5B optimal, größere Modelle können jedoch Textaufforderungen besser verstehen. 
Methodenübersicht
Experimentelle Ergebnisse
Das obige ist der detaillierte Inhalt vonMeta-Open-Source-Text generiert ein großes Musikmodell. Wir haben es mit den Texten von „Qilixiang' versucht.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr