
Heim >Technologie-Peripheriegeräte >KI >Mit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da
Mit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-13 10:34:271452Durchsuche
In letzter Zeit haben KI-Dialogassistenten erhebliche Fortschritte bei Sprachaufgaben gemacht. Diese signifikante Verbesserung basiert nicht nur auf der starken Generalisierungsfähigkeit von LLM, sondern ist auch auf die Optimierung der Anweisungen zurückzuführen. Dies beinhaltet die Feinabstimmung des LLM auf eine Reihe von Aufgaben durch vielfältigen und qualitativ hochwertigen Unterricht.
Ein möglicher Grund für das Erreichen einer Zero-Shot-Leistung mit der Befehlsoptimierung ist die Verinnerlichung des Kontexts. Dies ist insbesondere dann wichtig, wenn Benutzereingaben den gesunden Menschenverstandskontext überspringen. Durch die Einbeziehung der Befehlsoptimierung erhält LLM ein hohes Maß an Verständnis für die Absicht des Benutzers und weist bessere Zero-Shot-Fähigkeiten auf, selbst bei bisher unbekannten Aufgaben.
Ein idealer KI-Gesprächsassistent sollte jedoch in der Lage sein, Aufgaben mit mehreren Modalitäten zu lösen. Dies erfordert die Beschaffung eines vielfältigen und qualitativ hochwertigen multimodalen Datensatzes zur Befehlsverfolgung. Beispielsweise ist der LLaVAInstruct-150K-Datensatz (auch bekannt als LLaVA) ein häufig verwendeter visuell-verbaler Befehlsfolgedatensatz, der COCO-Bilder, Anweisungen und Antworten basierend auf Bildunterschriften und Zielbegrenzungsrahmen verwendet, die von GPT-4 Constructed erhalten wurden. Allerdings weist LLaVA-Instruct-150K drei Einschränkungen auf: begrenzte visuelle Vielfalt; Verwendung von Bildern als einzelne visuelle Daten und kontextbezogene Informationen, die nur die Sprachmorphologie enthalten.
Um KI-Dialogassistenten zu fördern, die diese Einschränkungen überwinden, haben Wissenschaftler der Nanyang Technological University in Singapur und Microsoft Research Redmond den multimodalen kontextbezogenen Befehlsoptimierungsdatensatz MIMIC-IT vorgeschlagen, der 2,8 Millionen multimodale kontextbezogene Elemente enthält Anweisungen – ein Datensatz entsprechender Paare, der eine Vielzahl realer Szenarien abdeckt.

Papieradresse: https://arxiv.org/pdf/2306.05425.pdf
Um effizient Befehls-Antwort-Paare zu generieren, führte der Forscher außerdem „Sythus“ ein ", eine Anweisung, die von der Self-Instruct-Methode inspiriert ist – einer automatisierten Pipeline, die auf Kommentare reagiert. Sythus verwendet Systeminformationen, visuelle Anmerkungen und Beispiele im Kontext, um ein Sprachmodell (GPT-4 oder ChatGPT) anzuleiten, um Befehls-Antwort-Paare basierend auf dem visuellen Kontext zu generieren und dabei auf die drei grundlegenden Fähigkeiten visueller Sprachmodelle abzuzielen: Wahrnehmung, Argumentation und Planung. Darüber hinaus werden englische Befehle und Antworten in sieben Sprachen übersetzt, um die mehrsprachige Nutzung zu unterstützen.
Besonders hervorzuheben ist, dass die Forscher das multimodale Modell „Otter“ auf Basis von OpenFlamingo auf MIMIC-IT trainiert haben. Die multimodalen Fähigkeiten von Otter wurden sowohl mit ChatGPT als auch mit Menschen evaluiert und übertreffen andere neuere visuelle Sprachmodelle.
In einer Reihe von Demos demonstrierten Forscher die multimodalen Frage- und Antwortfähigkeiten von Otter:
F: Welche Karte wird als nächstes gespielt?
A: Acht Röhren. Auf diese Weise können Sie Vierer und Fünfer auf eine Straße warten lassen.

F: Ich möchte landen, was soll ich tun?
A: Drücken Sie einmal die untere linke Taste, um nach links abzubiegen, und ziehen Sie die Handbremse rechts, wenn Sie landen möchten.

F: Was kommt als nächstes?
A: Passe den Ball in die Mitte, renne zum Tor und suche nach Torchancen.

Als nächstes schauen wir uns die Studiendetails an.
MIMIC-IT-Datensatz
Der MIMIC-IT-Datensatz umfasst 2,8 Millionen multimodale Befehls-Antwort-Paare, die grundlegende Fähigkeiten abdecken: Wahrnehmung, Argumentation und Planung. Jede Anweisung wird von einem multimodalen Konversationskontext begleitet, sodass auf MIMIC-IT geschulte VLM gute Kenntnisse in interaktiven Anweisungen nachweisen und eine Zero-Shot-Generalisierung durchführen können.
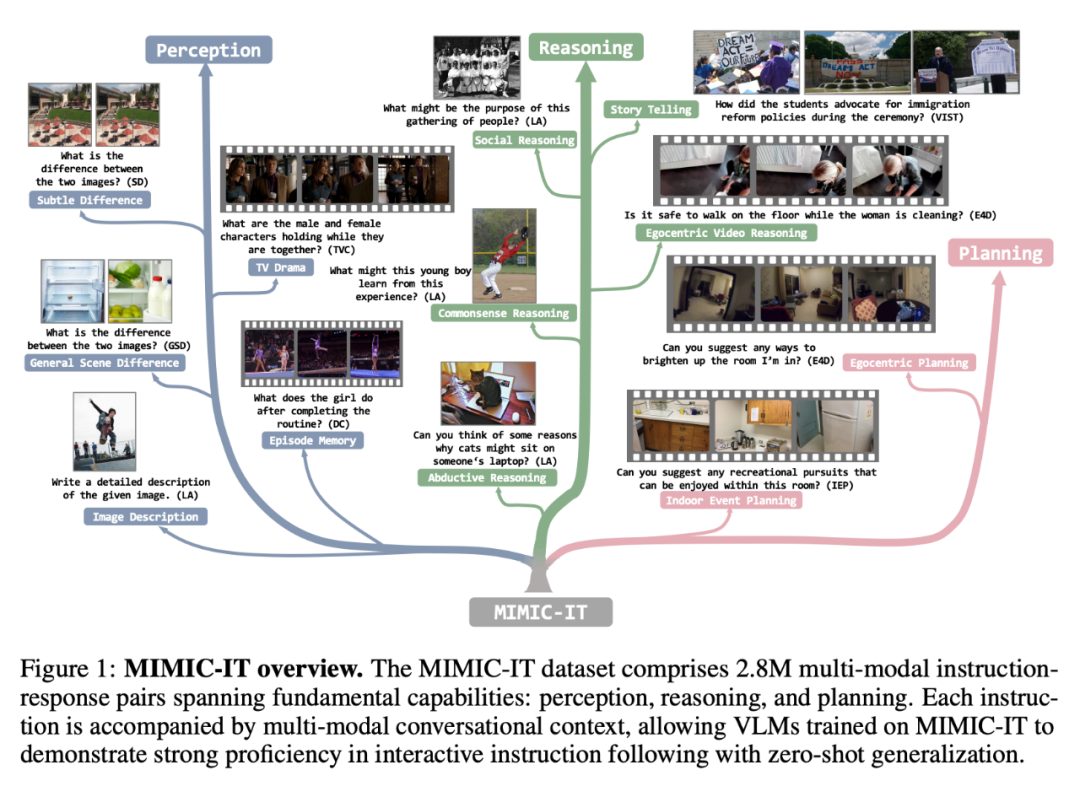
Im Vergleich zu LLaVA gehören zu den Funktionen von MIMIC-IT:
(1) Verschiedene visuelle Szenen, einschließlich allgemeiner Szenen, egozentrischer Perspektivenszenen und RGB-D-Innenbilder usw. Bilder und Videos aus verschiedenen Datensätzen;
(2) Mehrere Bilder (oder ein Video) als visuelle Daten
(3) Multimodale Kontextinformationen, einschließlich mehrerer Anweisungs-Antwort-Paare und mehrerer Bilder oder Videos;
(4) unterstützt acht Sprachen, darunter Englisch, Chinesisch, Spanisch, Japanisch, Französisch, Deutsch, Koreanisch und Arabisch.Die folgende Abbildung zeigt weiter den Befehl-Antwort-Vergleich der beiden (das gelbe Feld ist LLaVA):

Sythus: Automatisierte Pipeline zur Generierung von Befehls-Antwort-Paaren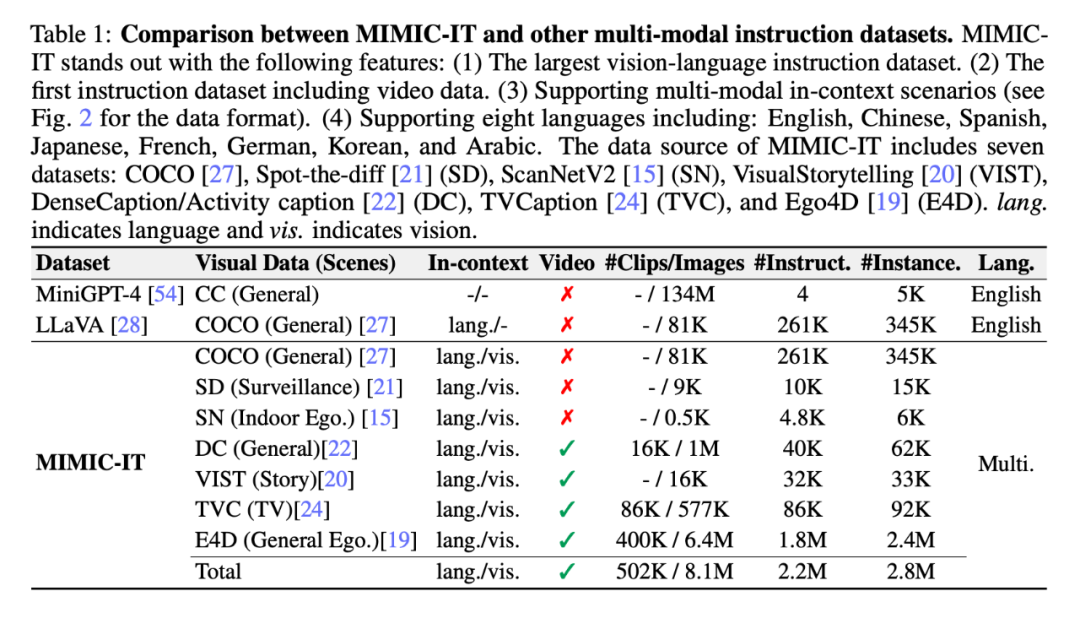
Da sich die Qualität des Kernsatzes auf den nachfolgenden Datenerfassungsprozess auswirkt, haben die Forscher eine Kaltstartstrategie angewendet, um die Stichproben vor groß angelegten Abfragen im Kontext zu verbessern. Während der Kaltstartphase wird ein heuristischer Ansatz angewendet, um ChatGPT dazu zu veranlassen, Proben nur im Kontext durch Systeminformationen und visuelle Anmerkungen zu sammeln. Diese Phase endet erst, nachdem die Proben in einem zufriedenstellenden Kontext identifiziert wurden. Im vierten Schritt werden die Befehls-Antwort-Paare von der Pipeline nach Erhalt in Chinesisch (zh), Japanisch (ja), Spanisch (es), Deutsch (de), Französisch (fr), Koreanisch (ko) und Arabisch erweitert (ar). Weitere Details finden Sie in Anhang C und spezifische Aufgabenaufforderungen finden Sie in Anhang D.
Abbildung 5 ist ein Beispiel für die Reaktion von Otter in verschiedenen Szenarien. Dank der Schulung am MIMIC-IT-Datensatz ist Otter in der Lage, situatives Verständnis und Argumentation, kontextbezogenes Beispiellernen und egozentrische visuelle Assistenten zu unterstützen. 
Abschließend führten die Forscher in einer Reihe von Benchmark-Tests eine vergleichende Analyse der Leistung von Otter und anderen VLMs durch.
ChatGPT-Bewertung
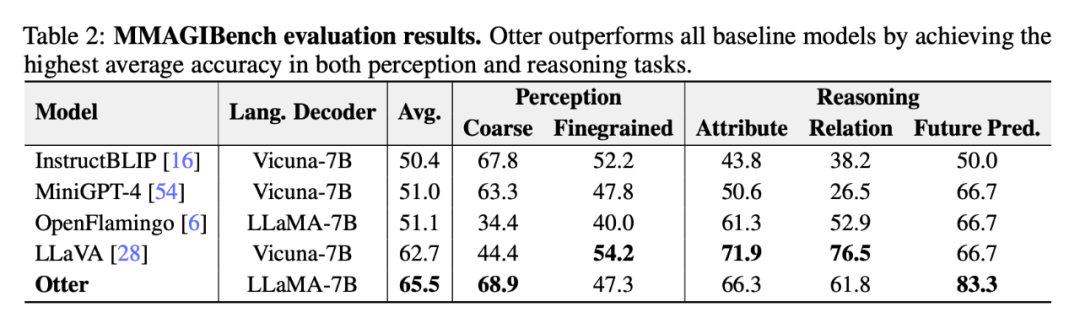
Tabelle 2 unten zeigt die umfassende Bewertung der Wahrnehmungs- und Argumentationsfähigkeiten visueller Sprachmodelle durch Forscher unter Verwendung des MMAGIBench-Frameworks [43].
Menschliche Bewertung
Multi-Modality Arena [32] verwendet das Elo-Bewertungssystem, um die Nützlichkeit und Konsistenz von VLM-Antworten zu bewerten. Abbildung 6(b) zeigt, dass Otter eine überlegene Praktikabilität und Konsistenz aufweist und die höchste Elo-Bewertung in den jüngsten VLMs erreicht.
Few-Shot-Benchmark-Bewertung für Kontextlernen
Otter ist auf OpenFlamingo abgestimmt, eine Architektur, die für multimodales Kontextlernen entwickelt wurde. Nach der Feinabstimmung mithilfe des MIMIC-IT-Datensatzes übertrifft Otter OpenFlamingo bei der COCO Captioning (CIDEr) [27]-Few-Shot-Bewertung deutlich (siehe Abbildung 6 (c)). Wie erwartet führt die Feinabstimmung auch zu geringfügigen Leistungssteigerungen bei der Nullstichprobenauswertung.

Abbildung 6: Auswertung des ChatGPT-Videoverständnisses.
Besprechen Sie
Mängel. Obwohl Forscher Systemnachrichten und Beispiele für Befehlsantworten schrittweise verbessert haben, ist ChatGPT anfällig für Sprachhalluzinationen und kann daher fehlerhafte Antworten generieren. Zuverlässigere Sprachmodelle erfordern häufig eine selbstinstruktive Datengenerierung.
Zukunft der Arbeit. In Zukunft planen die Forscher, spezifischere KI-Datensätze wie LanguageTable und SayCan zu unterstützen. Forscher erwägen auch die Verwendung vertrauenswürdigerer Sprachmodelle oder Generierungstechniken, um den Befehlssatz zu verbessern.
Das obige ist der detaillierte Inhalt vonMit 2,8 Millionen multimodalen Befehls-Antwort-Paaren, die in acht Sprachen üblich sind, ist der erste Befehlsdatensatz für Videoinhalte von MIMIC-IT da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr