
Heim >Technologie-Peripheriegeräte >KI >Der „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.
Der „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-12 23:40:01973Durchsuche
Vor einiger Zeit veröffentlichte Meta das KI-Modell „Segment Everything (SAM)“, das eine Maske für jedes Objekt in jedem Bild oder Video generieren kann, was Forscher im Bereich Computer Vision (CV) zum Ausruf veranlasste: „CV-Nr existiert nicht mehr.“ Danach gab es eine Welle der „sekundären Erstellung“ im Bereich CV. Einige Arbeiten kombinierten sukzessive Funktionen wie Zielerkennung und Bildgenerierung auf Basis der Segmentierung, die meisten Untersuchungen basierten jedoch auf statischen Bildern.
Jetzt schlägt eine neue Forschung mit dem Titel „Tracking Everything“ eine neue Methode zur Bewegungsschätzung in dynamischen Videos vor, mit der die Bewegungsbahn von Objekten genau und vollständig verfolgt werden kann.

Die Studie wurde von Forschern der Cornell University, Google Research und der UC Berkeley durchgeführt. Sie schlugen gemeinsam OmniMotion vor, eine vollständige und global konsistente Bewegungsdarstellung, und schlugen eine neue Methode zur Testzeitoptimierung vor, um eine genaue und vollständige Bewegungsschätzung für jedes Pixel im Video durchzuführen.

- Papieradresse: https://arxiv.org/abs/2306.05422
- Projekthomepage: https://omnimotion.github.io/
Einige Internetnutzer haben diese Studie auf Twitter weitergeleitet und sie erhielt an nur einem Tag mehr als 3.500 Likes. Der Forschungsinhalt wurde gut angenommen.

Der von der Studie veröffentlichten Demo nach zu urteilen, ist die Wirkung der Bewegungsverfolgung sehr gut, beispielsweise die Verfolgung der Bewegungsbahn eines springenden Kängurus:

Die Bewegungskurve eines Schaukel:

Sie können den Bewegungsverfolgungsstatus auch interaktiv anzeigen:

Die Bewegungsbahn kann auch dann verfolgt werden, wenn das Objekt blockiert ist, z. B. wenn ein Hund blockiert wird ein Baum beim Laufen:

Im Bereich Computer Vision gibt es zwei häufig verwendete Methoden zur Bewegungsschätzung: Spärliches Feature-Tracking und dichter optischer Fluss. Allerdings haben beide Methoden ihre eigenen Nachteile. Die Verfolgung von Sparse-Features kann nicht die Bewegung aller Pixel modellieren;
Das in dieser Forschung vorgeschlagene OmniMotion verwendet ein quasi-3D-kanonisches Volumen zur Darstellung des Videos und verfolgt jedes Pixel durch eine Bijektion zwischen lokalem Raum und kanonischem Raum. Diese Darstellung ermöglicht globale Konsistenz, ermöglicht Bewegungsverfolgung auch bei verdeckten Objekten und modelliert jede Kombination aus Kamera- und Objektbewegung. Diese Studie zeigt experimentell, dass die vorgeschlagene Methode bestehende SOTA-Methoden deutlich übertrifft.
Übersicht über die Methode
Diese Studie verwendet als Eingabe eine Sammlung von Bildern mit gepaarten Schätzungen verrauschter Bewegungen (z. B. optische Flussfelder), um eine vollständige, global konsistente Bewegungsdarstellung des gesamten Videos zu erstellen. Die Studie fügte dann einen Optimierungsprozess hinzu, der es ermöglichte, die Darstellung mit jedem Pixel in jedem Frame abzufragen, um im gesamten Video gleichmäßige, genaue Bewegungsbahnen zu erzeugen. Insbesondere kann diese Methode erkennen, wann Punkte im Rahmen verdeckt sind, und sogar Punkte durch Verdeckungen verfolgen.
OmniMotion-Charakterisierung
Herkömmliche Methoden zur Bewegungsschätzung (z. B. paarweiser optischer Fluss) verlieren die Verfolgung von Objekten, wenn sie verdeckt sind. Um auch unter Okklusion genaue und konsistente Bewegungstrajektorien bereitzustellen, schlägt diese Studie die globale Bewegungsdarstellung OmniMotion vor.
Diese Forschung versucht, reale Bewegungen ohne explizite dynamische 3D-Rekonstruktion genau zu verfolgen. Die OmniMotion-Darstellung stellt die Szene im Video als kanonisches 3D-Volumen dar, das in jedem Bild durch eine lokal-kanonische Bijektion auf ein lokales Volumen abgebildet wird. Lokale kanonische Bijektionen werden als neuronale Netze parametrisiert und erfassen Kamera- und Szenenbewegungen, ohne die beiden zu trennen. Basierend auf diesem Ansatz kann das Video als Rendering-Ergebnis aus dem lokalen Volumen einer festen statischen Kamera betrachtet werden.
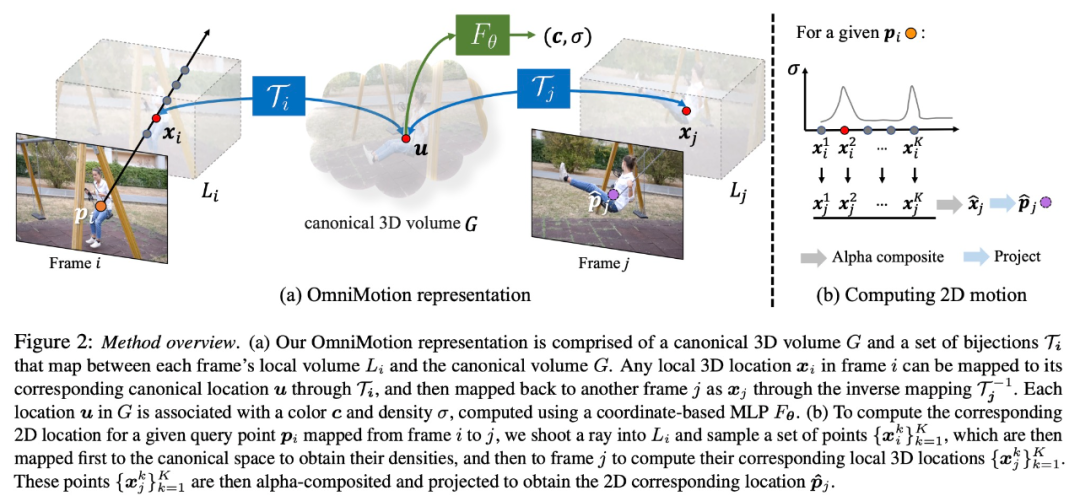
Da OmniMotion nicht klar zwischen Kamera- und Szenenbewegung unterscheidet, handelt es sich bei der erzeugten Darstellung nicht um eine physikalisch genaue 3D-Szenenrekonstruktion. Daher spricht die Studie von einer Quasi-3D-Charakterisierung.
OmniMotion speichert Informationen über alle auf jedes Pixel projizierten Szenenpunkte sowie deren relative Tiefenreihenfolge, sodass Punkte im Bild auch dann verfolgt werden können, wenn sie vorübergehend verdeckt sind.

Experimente und Ergebnisse
Quantitativer Vergleich
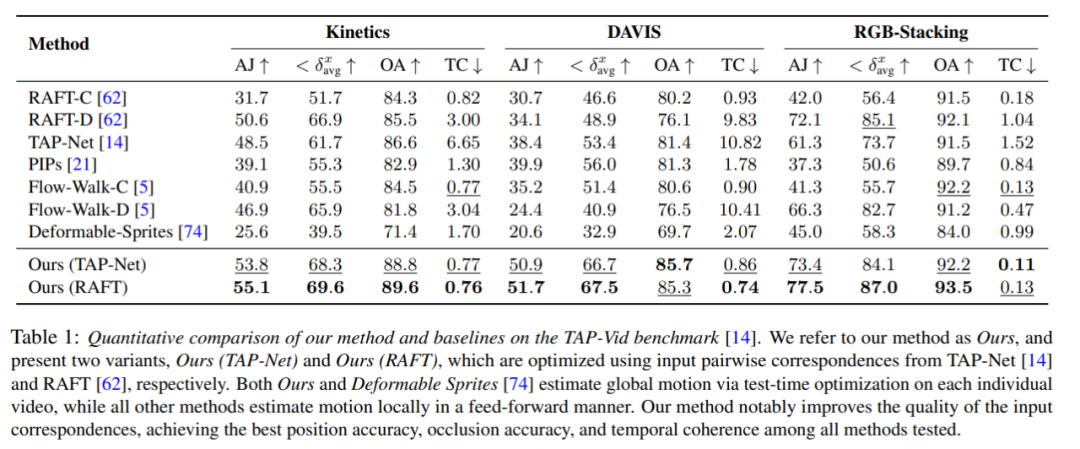
Die Forscher verglichen die vorgeschlagene Methode mit dem TAP-Vid-Benchmark und die Ergebnisse sind in Tabelle 1 dargestellt. Es ist ersichtlich, dass ihre Methode bei verschiedenen Datensätzen stets die beste Positionsgenauigkeit, Okklusionsgenauigkeit und Zeitkonsistenz erreicht. Ihre Methode verarbeitet die unterschiedlichen paarweisen Korrespondenzeingaben von RAFT und TAP-Net gut und bietet konsistente Verbesserungen gegenüber beiden Basismethoden.
Qualitativer Vergleich
Wie in Abbildung 3 dargestellt, führten die Forscher einen qualitativen Vergleich zwischen ihrer Methode und der Basismethode durch. Die neue Methode zeigt hervorragende Erkennungs- und Verfolgungsfähigkeiten bei (langen) Okklusionsereignissen, liefert gleichzeitig vernünftige Positionen für Punkte während Okklusionen und bewältigt große Kamerabewegungsparallaxen.

Ablationsexperimente und -analyse
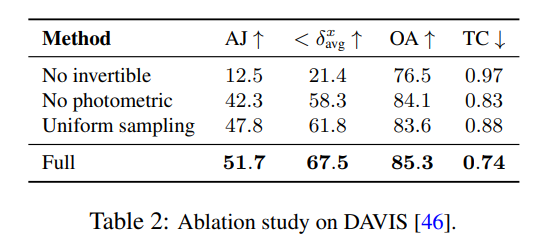
Die Forscher verwendeten Ablationsexperimente, um die Wirksamkeit ihrer Designentscheidungen zu überprüfen. Die Ergebnisse sind in Tabelle 2 aufgeführt.
In Abbildung 4 zeigen sie Pseudotiefenkarten, die von ihrem Modell generiert wurden, um die erlernte Tiefenrangfolge zu demonstrieren.

Es ist zu beachten, dass diese Zahlen nicht der physikalischen Tiefe entsprechen. Sie zeigen jedoch die Fähigkeit der neuen Methode, die relative Ordnung zwischen verschiedenen Oberflächen nur mithilfe photometrischer und optischer Flusssignale effektiv zu bestimmen, was für die Verfolgung von Verdeckungen von entscheidender Bedeutung ist. Weitere Ablationsexperimente und Analyseergebnisse finden Sie im Zusatzmaterial.
Das obige ist der detaillierte Inhalt vonDer „Track Everything'-Videoalgorithmus, der jedes Pixel jederzeit und überall verfolgt und keine Angst vor Hindernissen hat, ist da.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr