
Heim >Technologie-Peripheriegeräte >KI >DeepMind schreibt den Sortieralgorithmus mit KI neu; 33 B große Modelle werden in einer einzigen Verbraucher-GPU untergebracht
DeepMind schreibt den Sortieralgorithmus mit KI neu; 33 B große Modelle werden in einer einzigen Verbraucher-GPU untergebracht

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-12 18:49:571520Durchsuche
Inhaltsverzeichnis:
- Schnellere Sortieralgorithmen mithilfe von Deep Reinforcement Learning entdeckt
- Video-LLaMA: Ein auf Anweisungen abgestimmtes audiovisuelles Sprachmodell für Videos. Verstehen
- Patch- basierte 3D-Erzeugung natürlicher Szenen aus einem einzigen Beispiel
- Räumlich-zeitliche Diffusionspunktprozesse
- SpQR: Eine dünnquantisierte Darstellung für nahezu verlustfreie LLM-Gewichtskomprimierung
- UniControl: Ein einheitliches Diffusionsmodell für kontrollierbare visuelle Darstellung Generation In the Wild
- FrugalGPT: Wie man große Sprachmodelle nutzt und gleichzeitig die Kosten senkt und die Leistung verbessert
Aufsatz 1: Schnellere Sortieralgorithmen entdeckt mit Deep Reinforcement Learning
- Autor: Daniel J . Mankowitz Wait
- Papieradresse: https://www.nature.com/articles/s41586-023-06004-9
Zusammenfassung: "Durch das Vertauschen und Kopieren von Zügen überspringt AlphaDev Ein Schritt, der Projekte auf eine Weise verbindet, die falsch erscheint, in Wirklichkeit aber eine Abkürzung ist. Dieser beispiellose und kontraintuitive Gedanke erinnert die Menschen an den Frühling 2016.
Vor sieben Jahren besiegte AlphaGo den menschlichen Weltmeister im Go, und jetzt hat uns die KI eine weitere Lektion in Sachen Programmierung erteilt. Zwei Sätze von Hassabis, CEO von Google DeepMind, läuten den Computerbereich ein: „AlphaDev hat einen neuen und schnelleren Sortieralgorithmus entdeckt, und wir haben ihn als Open-Source-Lösung in die C++-Hauptbibliothek für Entwickler bereitgestellt. Das ist nur KI, die die Codeeffizienz verbessert. Der Anfang.“ des Fortschritts 2: Video-LLaMA: Ein auf Anweisungen abgestimmtes audiovisuelles Sprachmodell für das Videoverständnis
Papieradresse: https://arxiv.org/abs/ 2306.02858
- Zusammenfassung:
- In letzter Zeit haben große Sprachmodelle beeindruckende Fähigkeiten unter Beweis gestellt. Können wir große Models mit „Augen“ und „Ohren“ ausstatten, damit sie Videos verstehen und mit Nutzern interagieren können? Ausgehend von diesem Problem schlugen Forscher der DAMO Academy Video-LLaMA vor, ein großes Modell mit umfassenden audiovisuellen Funktionen. Video-LLaMA kann Video- und Audiosignale in Videos wahrnehmen und verstehen und kann Benutzereingabeanweisungen verstehen, um eine Reihe komplexer Aufgaben basierend auf Audio und Video zu erledigen, wie z. B. Audio-/Videobeschreibung, Schreiben, Fragen und Antworten usw. Derzeit sind alle Artikel, Codes und interaktive Demos geöffnet. Darüber hinaus stellt das Forschungsteam auf der Homepage des Video-LLaMA-Projekts auch eine chinesische Version des Modells bereit, um die Erfahrung chinesischer Benutzer reibungsloser zu gestalten.
- Die folgenden beiden Beispiele demonstrieren die umfassenden audiovisuellen Wahrnehmungsfähigkeiten von Video-LLaMA. Das Gespräch im Beispiel dreht sich um Audiovideos.
Empfohlen: Fügen Sie umfassende audiovisuelle Funktionen zu großen Sprachmodellen hinzu, DAMO Academy Open Source Video-LLaMA.
Papier 3: Patch-basierte 3D-Naturszenengenerierung anhand eines einzelnen Beispiels
- Autor: Weiyu Li et al Ich habe an der Shandong-Universität studiert und Tencent AI Lab-Forscher haben die erste Methode vorgeschlagen, um verschiedene hochwertige 3D-Szenen ohne Training basierend auf Einzelbeispielszenen zu generieren.
- Empfohlen: CVPR 2023 | 3D-Szenengenerierung: Generieren Sie vielfältige Ergebnisse aus einer einzigen Probe ohne neuronales Netzwerktraining.
Papier 4: Raum-zeitliche Diffusionspunktprozesse

Autor: Yuan Yuan et al
Papieradresse: https://arxiv.org/abs/2305.12403.
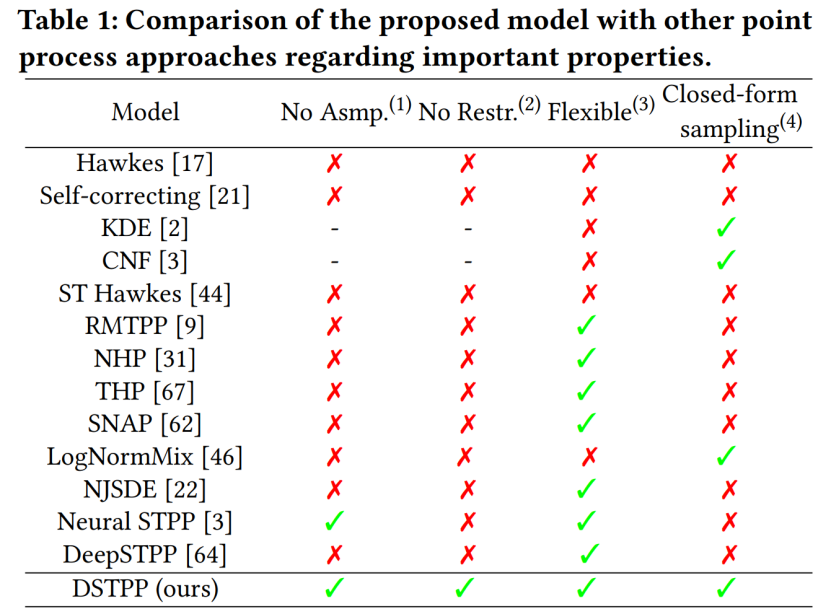
- Zusammenfassung: Das Urban Science and Computing Research Center der Abteilung für Elektrotechnik der Tsinghua-Universität hat kürzlich den raumzeitlichen Diffusionspunktprozess vorgeschlagen, der die Einschränkungen bestehender Methoden wie eingeschränkte Wahrscheinlichkeitsformen und hohe Stichprobenkosten für die Modellierung durchbricht räumlich-zeitliche Punktprozesse und erreicht eine flexible, effiziente und Das einfach zu berechnende räumlich-zeitliche Punktprozessmodell kann in großem Umfang bei der Modellierung und Vorhersage räumlich-zeitlicher Ereignisse wie städtischer Naturkatastrophen, Notfälle und Bewohneraktivitäten verwendet werden fördert die intelligente Entwicklung der Stadtplanung und des Stadtplanungswesens. Die folgende Tabelle zeigt die Vorteile von DSTPP gegenüber bestehenden Punktprozesslösungen.
- Empfohlen: Können Diffusionsmodelle Erdbeben und Verbrechen vorhersagen? Die neueste Forschung des Tsinghua-Teams schlägt einen Raum-Zeit-Diffusionspunktprozess vor.
Artikel 5: SpQR: Eine spärlich quantisierte Darstellung für nahezu verlustfreie LLM-Gewichtskomprimierung
Autor: Tim Dettmers et al.
Papieradresse: https://arxiv . org /pdf/2306.03078.pdf
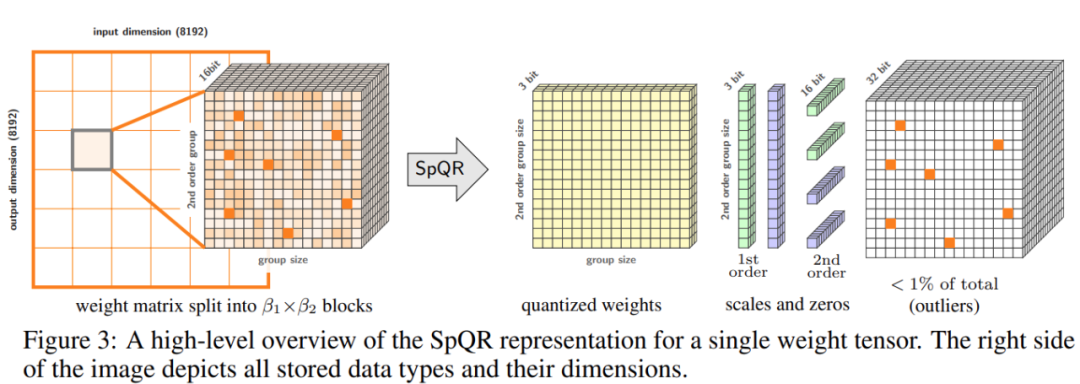
- Zusammenfassung:Um das Genauigkeitsproblem zu lösen, schlugen Forscher der University of Washington, der ETH Zürich und anderer Institutionen ein neues Komprimierungsformat und eine Quantisierungstechnologie SpQR (Sparse-Quantitative) vor Darstellung) erreicht erstmals eine nahezu verlustfreie Komprimierung von LLM über Modellskalen hinweg und erreicht gleichzeitig ähnliche Komprimierungsniveaus wie frühere Methoden.
- SpQR identifiziert und isoliert abnormale Gewichte, die besonders große Quantisierungsfehler verursachen, speichert sie mit höherer Präzision, während alle anderen Gewichte auf 3-4 Bits komprimiert werden. In LLaMA wird ein relativer Genauigkeitsverlust von weniger als 1 % erreicht und Falcon LLMs. Führen Sie ein 33-B-Parameter-LLM auf einer einzelnen 24-GB-Consumer-GPU ohne Leistungseinbußen und gleichzeitig 15 % schneller aus. Abbildung 3 unten zeigt die Gesamtarchitektur von SpQR.
Empfehlung: Setzen Sie ein großes Modell mit 33 Milliarden Parametern in eine einzige Verbraucher-GPU ein und steigern Sie die Geschwindigkeit um 15 %, ohne die Leistung zu beeinträchtigen.
Aufsatz 6: UniControl: Ein einheitliches Diffusionsmodell für die kontrollierbare visuelle Erzeugung in freier Wildbahn
- Autor: Can Qin et al Universität, Stanford University Die Forscher schlugen einen MOE-ähnlichen Adapter und ein aufgabenbewusstes HyperNet vor, um die Fähigkeit zur multimodalen Bedingungsgenerierung in UniControl zu realisieren. UniControl ist für neun verschiedene C2I-Aufgaben geschult und demonstriert starke visuelle Generierungsfähigkeiten und Zero-Shot-Generalisierungsfähigkeiten. Das UniControl-Modell besteht aus mehreren Pre-Training-Aufgaben und Zero-Shot-Aufgaben.
- Empfohlen: Das einheitliche Modell für die multimodale steuerbare Bilderzeugung ist da, und die Modellparameter und der Inferenzcode sind alle Open Source.
Papier 7: FrugalGPT: Wie man große Sprachmodelle nutzt und gleichzeitig die Kosten senkt und die Leistung verbessert

Autor: Lingjiao Chen et al
Papieradresse: https://arxiv. org /pdf/2305.05176.pdf
- Zusammenfassung: Das Gleichgewicht zwischen Kosten und Genauigkeit ist ein Schlüsselfaktor bei der Entscheidungsfindung, insbesondere bei der Einführung neuer Technologien. Die effektive und effiziente Nutzung von LLM ist eine zentrale Herausforderung für Praktiker: Wenn die Aufgabe relativ einfach ist, kann durch die Aggregation mehrerer Antworten aus GPT-J (das 30-mal kleiner als GPT-3 ist) eine ähnliche Leistung wie GPT-3 erzielt werden einen Kosten- und Umweltkompromiss zu erzielen. Bei schwierigeren Aufgaben kann sich die Leistung von GPT-J jedoch erheblich verschlechtern. Daher sind neue Ansätze erforderlich, um LLM kosteneffizient einzusetzen.
- Eine aktuelle Studie hat versucht, eine Lösung für dieses Kostenproblem vorzuschlagen. Die Forscher haben experimentell gezeigt, dass FrugalGPT mit der Leistung des besten einzelnen LLM (wie GPT-4) mit einer Kostenreduzierung von bis zu 98 % konkurrieren kann. , oder Verbesserung der Genauigkeit des besten einzelnen LLM um 4 % bei gleichen Kosten. In dieser Studie werden drei Strategien zur Kostensenkung erörtert, nämlich sofortige Anpassung, LLM-Annäherung und LLM-Kaskadierung.
Empfohlen: GPT-4 API-Ersatz? Die Leistung ist vergleichbar und die Kosten werden um 98 % gesenkt. Stanford schlug FrugalGPT vor, aber die Forschung war umstritten.
Das obige ist der detaillierte Inhalt vonDeepMind schreibt den Sortieralgorithmus mit KI neu; 33 B große Modelle werden in einer einzigen Verbraucher-GPU untergebracht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr