
Heim >Technologie-Peripheriegeräte >KI >5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT
5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT

- 王林nach vorne
- 2023-06-10 10:42:301168Durchsuche
Schlechtes Gedächtnis ist das Hauptproblem aktueller Mainstream-Sprachmodelle. ChatGPT kann beispielsweise nur 4096 Token (ungefähr 3000 Wörter) eingeben, und das reicht nicht einmal aus Lesen Sie eine Kurzgeschichte von.
Das kurze Eingabefenster schränkt auch die Anwendungsszenarien des Sprachmodells ein. Wenn Sie beispielsweise eine wissenschaftliche Arbeit (ca. 10.000 Wörter) zusammenfassen, müssen Sie den Artikel manuell segmentieren und ihn dann in verschiedene Kapitel in das Modell eingeben. Die zugehörigen Informationen gehen verloren.
Obwohl GPT-4 bis zu 32.000 Token unterstützt und der aktualisierte Claude bis zu 100.000 Token unterstützt, können sie das Problem der unzureichenden Gehirnkapazität nur lindern.
Kürzlich gab das Unternehmerteam Magic bekannt, dass es bald das LTM-1-Modell herausbringen wird, das bis zu 5 Millionen Token unterstützt, was etwa 500.000 Codezeilen oder 5000 Dateien entspricht, also 50 Mal höher als Claude. Es ist im Grunde in Ordnung. Es deckt die meisten Speicheranforderungen ab, das macht wirklich einen Unterschied in Quantität und Qualität!
Das Hauptanwendungsszenario von LTM-1 ist die Codevervollständigung, mit der beispielsweise längere und komplexere Codevorschläge generiert werden können.Sie können Informationen auch über mehrere Dateien hinweg wiederverwenden und synthetisieren.
Die schlechte Nachricht ist, dass Magic, der Entwickler von LTM-1, die spezifischen technischen Prinzipien nicht veröffentlicht hat, sondern nur gesagt hat, dass es eine brandneue Methode entwickelt hat, das Long-Term Memory Network (LTM Net).
Aber es gibt auch gute Nachrichten: Im September 2021 haben Forscher von DeepMind und anderen Institutionen ein Modell namens ∞-former vorgeschlagen, das einen Langzeitgedächtnismechanismus (LTM) enthält. Die Theorie kann das Transformer-Modell unendlich machen Speicher, aber es ist nicht klar, ob es sich bei beiden um die gleiche Technologie oder eine verbesserte Version handelt.

Link zum Papier: https://arxiv.org/pdf/2109.00301.pdf
Das Entwicklungsteam gab an, dass LTM-Netze zwar mehr Kontext sehen können als GPT, LTM-Netzwerke jedoch mehr Kontext sehen können als GPT Die Parameter des -1-Modells sind viel kleiner als die des aktuellen Sota-Modells, daher ist auch der Intelligenzgrad geringer. Eine weitere Vergrößerung der Modellgröße dürfte jedoch die Leistung von LTM-Netzen verbessern.Derzeit hat LTM-1 Alpha-Testanwendungen geöffnet.

Anwendungslink: https://www.php.cn/link/bbfb937a66597d9646ad992009aee405
LTM-1-Entwickler Magic wurde 2022 gegründet und entwickelt hauptsächlich ähnliche GitHub Copilot’s Das Produkt kann Softwareentwicklern beim Schreiben, Überprüfen, Debuggen und Ändern von Code helfen. Das Ziel besteht darin, einen KI-Kollegen für Programmierer zu schaffen. Sein Hauptwettbewerbsvorteil besteht darin, dass das Modell längeren Code lesen kann.Magic ist dem Gemeinwohl verpflichtet und seine Mission besteht darin, AGI-Systeme zu entwickeln und sicher einzusetzen, die die menschlichen Fähigkeiten übertreffen. Derzeit ist das Unternehmen ein Startup-Unternehmen mit nur 10 Mitarbeitern.

Eric Steinberger, CEO und Mitbegründer von Magic, hat einen Bachelor-Abschluss in Informatik von der Universität Cambridge und hat bei FAIR maschinelles Lernen geforscht.

Vor der Gründung von Magic gründete Steinberger auch ClimateScience, um Kindern auf der ganzen Welt dabei zu helfen, etwas über die Auswirkungen des Klimawandels zu lernen.
Infinite Memory Transformer
Das Design des Aufmerksamkeitsmechanismus im Transformer, der Kernkomponente des Sprachmodells, führt dazu, dass die Zeitkomplexität jedes Mal quadratisch zunimmt, wenn die Länge der Eingabesequenz erhöht wird.
Obwohl es bereits einige Varianten des Aufmerksamkeitsmechanismus gibt, wie z. B. spärliche Aufmerksamkeit usw., um die Komplexität des Algorithmus zu reduzieren, hängt seine Komplexität immer noch von der Eingabelänge ab und kann nicht unendlich erweitert werden.
∞-former Der Schlüssel zum Transformer-Modell des Langzeitgedächtnisses (LTM), das die Eingabesequenz auf unbegrenzt erweitern kann, ist ein kontinuierliches räumliches Aufmerksamkeitsgerüst, das die Anzahl der Gedächtnisinformationseinheiten (basierend auf der Funktion) erhöht.
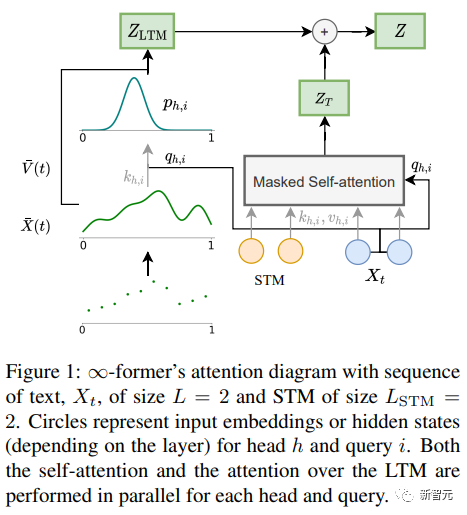
Im Framework wird die Eingabesequenz als „kontinuierliches Signal“ dargestellt, das eine lineare Kombination von N radialen Basisfunktionen (RBF) darstellt. Auf diese Weise beträgt die Aufmerksamkeitskomplexität von ∞-former Es wird auf O(L^2 + L × N) reduziert, während die Aufmerksamkeitskomplexität des ursprünglichen Transformers O(L×(L+L_LTM)) beträgt, wobei L und L_LTM der Transformer-Eingabegröße und dem Langzeitgedächtnis entsprechen Länge bzw.
Diese Darstellungsmethode hat zwei Hauptvorteile:
1 Der Kontext kann durch eine Basisfunktion N dargestellt werden, die kleiner ist als die Anzahl der Token, was den Rechenaufwand für die Aufmerksamkeit reduziert;
2 kann festgelegt werden und ist somit in der Lage, einen unbegrenzten Kontext im Gedächtnis darzustellen, ohne die Komplexität des Aufmerksamkeitsmechanismus zu erhöhen.

Natürlich gibt es kein kostenloses Mittagessen auf der Welt, und der Preis ist die Verringerung der Auflösung: Die Verwendung einer geringeren Anzahl von Basisfunktionen führt zu einer Verringerung der Genauigkeit bei der Darstellung der Eingabesequenz als ein Dauersignal.
Um das Problem der Auflösungsreduzierung zu lindern, führten Forscher das Konzept der „Sticky Memories“ ein, das den größeren Platz im LTM-Signal auf häufiger aufgerufene Speicherbereiche zurückführte und so ein „Sticky Memory“ im LTM schuf Das Konzept der „Permanenz“ ermöglicht es dem Modell, den langfristigen Kontext besser zu erfassen, ohne relevante Informationen zu verlieren, und ist außerdem vom langfristigen Potenzial und der Plastizität des Gehirns inspiriert.
Experimenteller Teil
Um zu überprüfen, ob ∞-former lange Kontexte modellieren kann, führten die Forscher zunächst Experimente zu einer synthetischen Aufgabe durch, d. h. zum Sortieren von Token nach Häufigkeit in einer langen Sequenz mit Sprachmodellierung und dokumentbasierter Dialoggenerierung durch Feinabstimmung vorab trainierter Sprachmodelle.
Sortierung
Die Eingabe umfasst eine Sequenz von Token, die gemäß einer Wahrscheinlichkeitsverteilung (dem System unbekannt) abgetastet werden, und das Ziel besteht darin, Token in der Reihenfolge abnehmender Häufigkeit in der Sequenz zu generieren
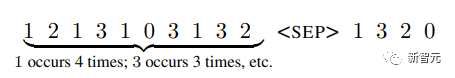
Um langfristig zu untersuchen, ob der Speicher effizient genutzt wird und ob der Transformer einfach durch Modellierung der neuesten Tags sortiert, haben die Forscher die Tag-Wahrscheinlichkeitsverteilung so entworfen, dass sie sich im Laufe der Zeit ändert.
Es gibt 20 Token im Vokabular, und zum Vergleich werden Experimente mit Sequenzen der Längen 4.000, 8.000 und 16.000 durchgeführt.
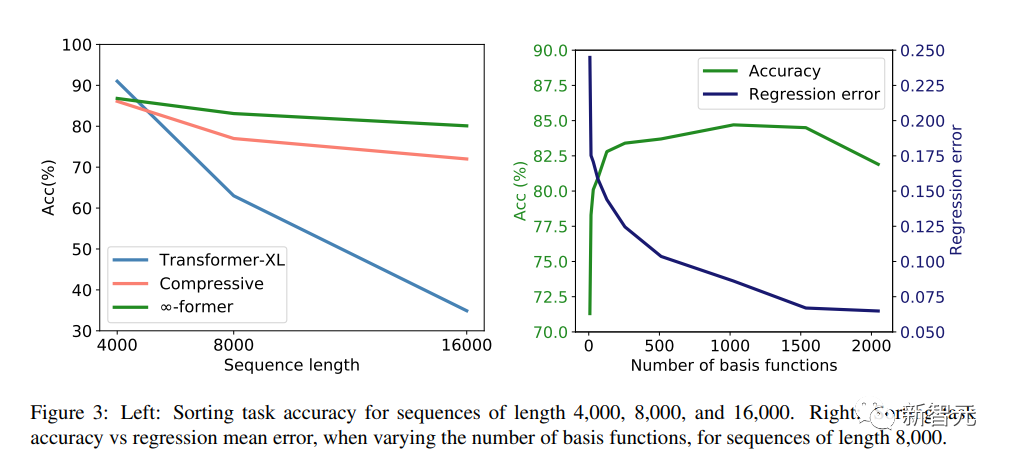
Die experimentellen Ergebnisse zeigen, dass Transformer-XL bei einer kurzen Sequenzlänge (4.000) eine etwas höhere Genauigkeit als andere Modelle erreicht. Mit zunehmender Sequenzlänge nimmt die Genauigkeit jedoch ebenfalls schnell ab, jedoch für ∞-former For Dieser Rückgang ist nicht offensichtlich, was darauf hindeutet, dass er bei der Modellierung langer Sequenzen mehr Vorteile bietet.
Sprachmodellierung
Um zu verstehen, ob das Langzeitgedächtnis zur Erweiterung vorab trainierter Sprachmodelle verwendet werden kann, führten die Forscher GPT-2 Small an einer Teilmenge von Wikitext103 und PG-19 Fine- durch. abgestimmt, darunter rund 200 Millionen Token.
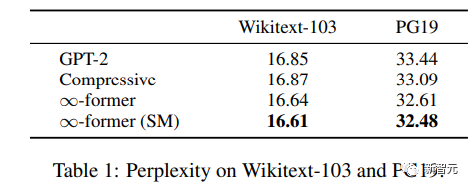
Die experimentellen Ergebnisse zeigen, dass ∞-Former die Verwirrung von Wikitext-103 und PG19 verringern kann und ∞-Former eine größere Verbesserung gegenüber dem PG19-Datensatz erzielt, da Bücher stärker davon abhängig sind als Wikipedia-Artikel Langzeitgedächtnis.
Dokumentbasierter Dialog
Bei der dokumentbasierten Dialoggenerierung kann das Modell neben dem Dialogverlauf auch Dokumente zum Gesprächsthema abrufen.
Im CMU Document Grounded Conversation-Datensatz (CMU-DoG) handelt es sich bei der Konversation um einen Film, und eine Zusammenfassung des Films wird als Hilfsdokument angegeben; die Konversation enthält mehrere verschiedene fortlaufende Diskurse, die Hilfsdokumente sind in mehrere Teile unterteilt.
Um den Nutzen des Langzeitgedächtnisses zu beurteilen, gewährten die Forscher dem Modell erst vor Beginn des Gesprächs Zugriff auf die Datei, was die Aufgabe schwieriger machte.
Nach der Feinabstimmung von GPT-2 wird GPT-2 mithilfe eines kontinuierlichen LTM (∞-Former) mit N=512 Basisfunktionen erweitert, damit das Modell das gesamte Dokument im Speicher behalten kann.
Um den Modelleffekt zu bewerten, verwenden Sie Ratlosigkeit, F1-Score, Rouge-1 und Rouge-L sowie Meteor-Indikatoren.
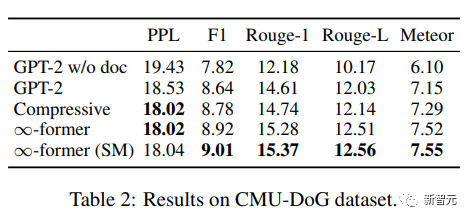
Den Ergebnissen nach zu urteilen, können ∞-Former und Komprimierungstransformator einen besseren Korpus erzeugen. Obwohl die Verwirrung der beiden im Grunde die gleiche ist, erzielt ∞-Former bessere Ergebnisse.
Das obige ist der detaillierte Inhalt von5-Millionen-Token-Monster, lesen Sie den gesamten „Harry Potter' auf einmal! Mehr als 1000-mal länger als ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr