
Heim >Technologie-Peripheriegeräte >KI >GPT-4 brachte DeepMind in Verlegenheit: Sie haben den Sortieroptimierungsalgorithmus von Nature übernommen und ich habe es in zwei Absätzen herausgefunden
GPT-4 brachte DeepMind in Verlegenheit: Sie haben den Sortieroptimierungsalgorithmus von Nature übernommen und ich habe es in zwei Absätzen herausgefunden

- PHPznach vorne
- 2023-06-10 10:23:071077Durchsuche
DeepMinds neue KI ist erst seit einem Tag auf Nature und GPT-4 ist bereits da, um mitzuhalten!
Mit nur zwei Absätzen mit Eingabeaufforderungen bietet GPT-4 die gleiche Methode zur Optimierung des Sortieralgorithmus wie AlphaDev.
DeepMind nennt AlphaDev „die Wiederherstellung der Magie von AlphaGo“, weil es eine Methode entdeckt hat, die den Sortieralgorithmus um bis zu 70 % beschleunigen kann.
Oh, AlphaDev ist jetzt noch verlegener.
Lassen Sie GPT-4 den Bruder, der die gleiche Operation durchgeführt hat, direkt „entdecken“:
Kein verstärkendes Lernen ist überhaupt nicht erforderlich. Kann ich diese Entdeckung in Nature veröffentlichen?
Musk „hat es gesehen, als er vorbeiging“ und auch einen Kommentar „wegen der Explosion“ hinterlassen.

Wie macht GPT-4 das?
Nur 2 Absätze mit Aufforderungen
Die Person, die diese neue Entdeckung brachte, ist ein außerordentlicher Professor der University of Wisconsin-Madison namens Dimitris Papailiopoulos (im Folgenden als Professor D bezeichnet).
Die Schritte, mit denen er GPT-4 diesen Vorgang ausführen ließ, waren sehr einfach und er gab insgesamt nur zwei Eingabeaufforderungen ein.
Zuerst sagte er zu GPT-4:
Dies ist ein Sortieralgorithmus, und ich denke, er kann weiter optimiert werden. Welcher Satz muss umgeschrieben werden? . Erklären Sie Schritt für Schritt, warum, gehen Sie dann noch einmal zurück und überprüfen Sie, ob es richtig ist.

Im ersten Schritt betonte er außerdem, dass man bei neuen Entdeckungen nicht zuerst Änderungen vornehmen, sondern nur „zuschauen“ und einige schriftliche Verbesserungsvorschläge aufschreiben sollte.
Seien Sie sehr detailliert und sehr vorsichtig.
Dann liefert GPT-4 eine detaillierte Erklärung des angegebenen Codes.

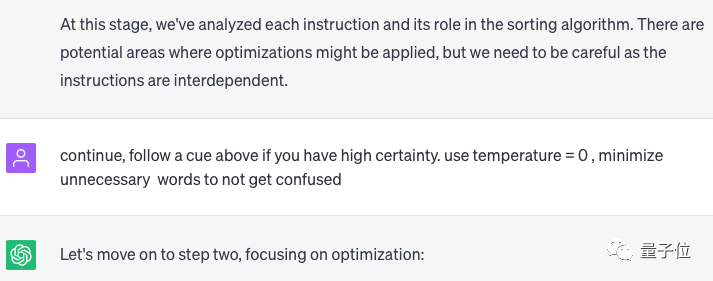
Dann gab Professor D den zweiten Tipp:
Weitermachen. Wenn Sie sehr sicher sind, befolgen Sie die oben genannten Tipps. Stellen Sie die Temperatur auf 0 ein, um sicherzustellen, dass die generierten Ergebnisse deterministisch und konsistent sind und um Verwirrung zu vermeiden.
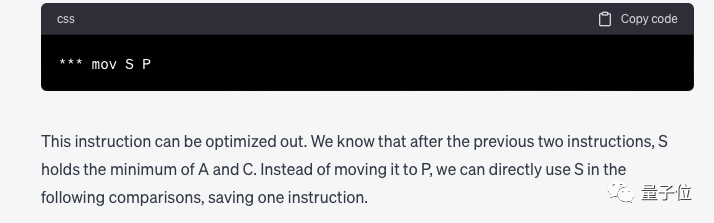
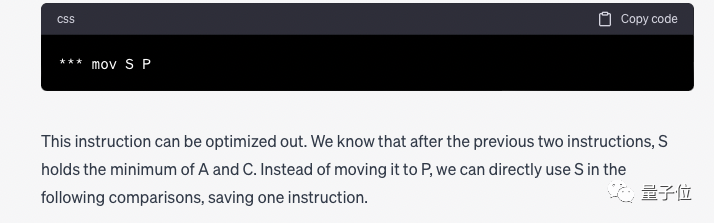
Dann gab GPT-4 detaillierte Schritte und kam schließlich zu dem Schluss:
Wir haben festgestellt, dass die Anweisung „mov S P“ überflüssig ist und entfernt werden kann und andere Anweisungen erforderlich sind. Aber nach dem Löschen sollte P durch S ersetzt werden.
Wenn man die Überlegungen von DeepMinds neuem Werk AlphaDev zum Umgang mit demselben Problem vergleicht, kann man nicht sagen, dass es nichts damit zu tun hat, wir können nur sagen, dass es genau dasselbe ist:
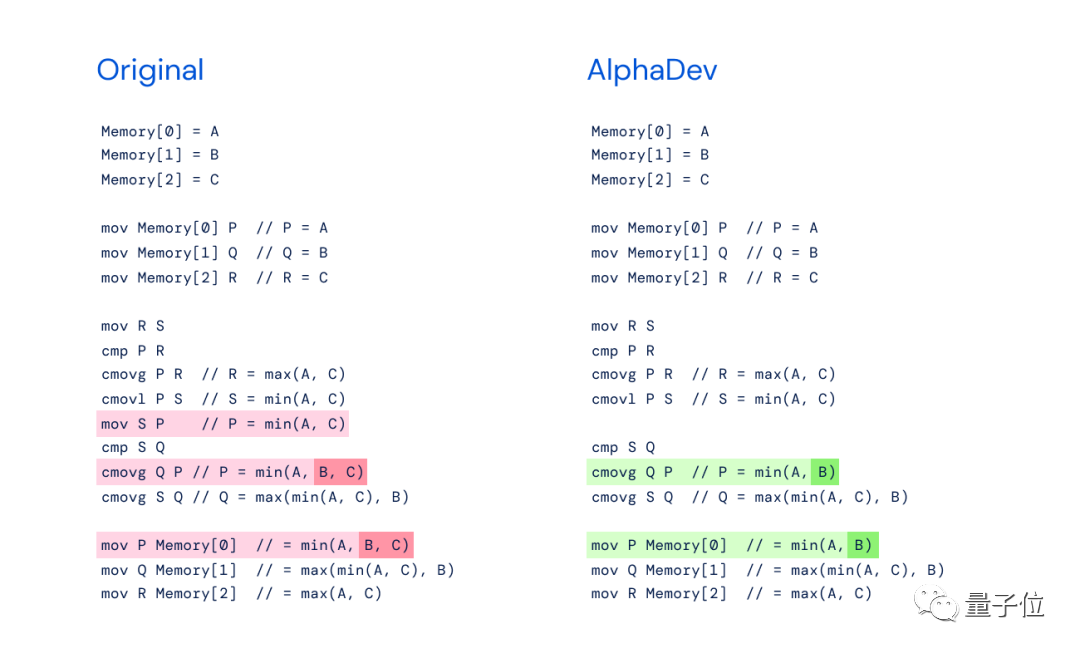
DeepMinds Funktionsweise von AlphaDev erinnert an AlphaGos „Move 37“ – ein kontraintuitiver Zug, der den legendären Go-Spieler Lee Sedol direkt besiegte, was das Publikum schockierte.
In ähnlicher Weise überspringt AlphaDev einen Schritt, indem es Züge austauscht und kopiert und so das Ziel auf eine Weise erreicht, die falsch erscheint, in Wirklichkeit aber eine Abkürzung ist.
Berichten zufolge handelt es sich bei AlphaDev um einen Verstärkungslernalgorithmus, der auf AlphaZero basiert. Seine Entdeckung basiert nicht auf vorhandenen Algorithmen, sondern beginnt mit den Montageanweisungen der untersten Ebene.
Seine Innovation liegt hauptsächlich in zwei Befehlssequenzen:
(1) AlphaDev Swap Move (Swap Move)
(2) AlphaDev Copy Move (Copy Move)
Im Prinzip haben DeepMind-Forscher eine Einzelspieler-„Assembly“ entworfen. Spiel:
Solange Sie die entsprechenden Anweisungen suchen und auswählen können (Prozess A in der Abbildung unten) und die Daten korrekt und schnell anordnen können (Prozess B in der Abbildung unten), können Sie Belohnungen erhalten.
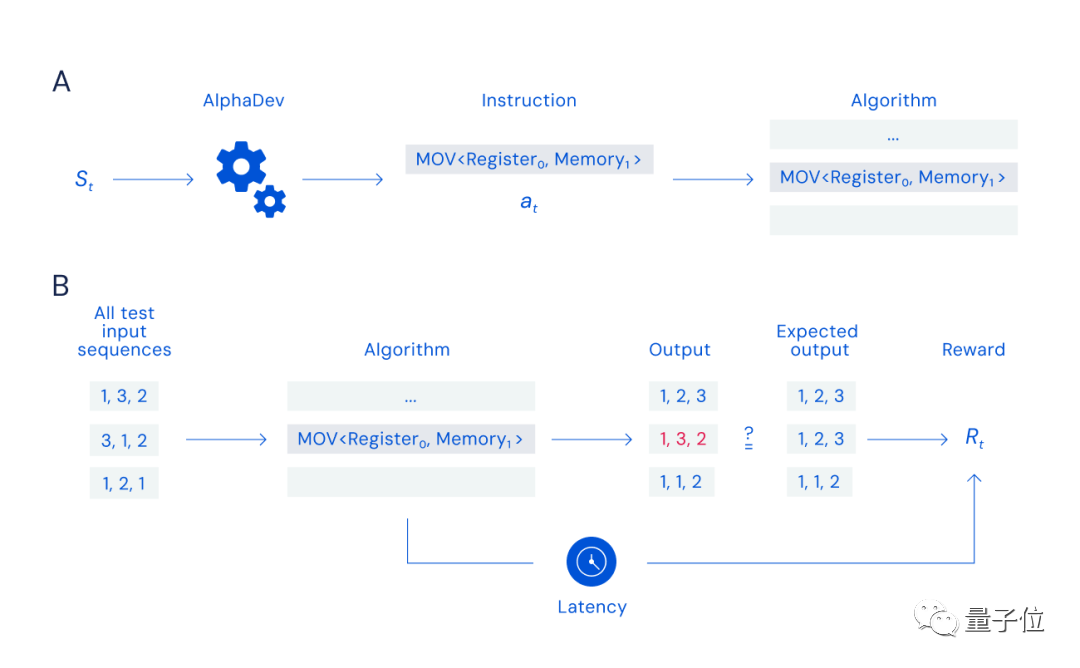
Aber die Herausforderung dieses Spiels liegt nicht nur in der Größe des Suchraums (die Anzahl der kombinierbaren Anweisungen entspricht der Anzahl der Teilchen im Universum), sondern auch in der Art der Belohnung Funktion, da eine falsche Anweisung den gesamten Algorithmus zum Scheitern bringen kann. Ungültig.
Netizen: Wir unterschätzen immer die Fähigkeiten von GPT-4
In Bezug auf die „sexy Bedienung“ von GPT-4 sagten einige Leute: „Selbst erfahrene Entwickler unterschätzen GPT-4.“

Einige Leute beklagten, dass die Operation von Professor D weiter bestätigte, dass GPT-4 immer noch viele Dinge tun kann, solange man Geduld hat und die schnelle Technik versteht.

Einige Leute haben auch gefragt, ob GPT-4 dies kann, weil seine Trainingsdaten einige Optimierungsmethoden für Sortieralgorithmen enthalten?

Aber ein großer Teil des Grundes, warum diese Angelegenheit so viel Aufmerksamkeit und Diskussion erregt hat, ist, dass die Aufnahme von AlphaDev in Nature umstritten ist.
Viele Menschen sind der Meinung, dass dies keine bahnbrechende Forschung ist und DeepMind übertreibt.

Professor D sagte nicht nur: „Kann ich auch in der Natur sein?“, Es gab auch Internetnutzer, die sagten, dass sie als Teenager das schnelle Sortieren optimiert hätten und auch Artikel veröffentlichen sollten.
Natürlich glauben einige Leute, dass die Innovation von AlphaDev selbst darin besteht, dass es Verstärkungslernen nutzt, um neue Algorithmen zu entdecken.

Was meint ihr?
Referenzlinks: [1]https://chat.openai.com/share/95693df4-36cd-4241-9cae-2173e8fb760c[2]https://twitter.com/DimitrisPapail/status/1666843952824168465
Das obige ist der detaillierte Inhalt vonGPT-4 brachte DeepMind in Verlegenheit: Sie haben den Sortieroptimierungsalgorithmus von Nature übernommen und ich habe es in zwei Absätzen herausgefunden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr