
Heim >Technologie-Peripheriegeräte >KI >Anwendung in der KI-Branche: Datenweberei verhilft zu Durchbrüchen beim Training von KI-Anwendungen
Anwendung in der KI-Branche: Datenweberei verhilft zu Durchbrüchen beim Training von KI-Anwendungen

- PHPznach vorne
- 2023-06-08 11:38:451253Durchsuche
#Dieser Artikel wurde von „Everyone is a Product Manager’s „Original Incentive Plan“ erstellt.
Obwohl groß angelegte KI-Modelle mittlerweile sehr beliebt sind und jedes Unternehmen ein Stück davon haben möchte, sind die Algorithmen und Daten, die zur Realisierung dieses Prozesses erforderlich sind, nicht leicht zu verstehen. Unter ihnen ist die Datenübertragung und -verwaltung ein großes Problem. Dieser Artikel konzentriert sich auf den Engpass beim KI-Anwendungstraining, fasst die Schwierigkeiten des KI-Trainings zusammen und kombiniert sie mit IDC-Analyseberichten, um zu dem Schluss zu kommen, dass „Daten“ der größte Engpass sind, und erörtert Lösungen für dieses Problem.

1. Produkthintergrund
„In letzter Zeit gibt es wieder Stimmen, die über KI diskutieren. Anders als die abwartende Haltung gegenüber KI in den letzten zwei Jahren sagen viele Leute, dass mit der Anwendung von ChatGPT das KI-Zeitalter wirklich angekommen ist, und das Produkt.“ und Operationsstudenten sind damit beschäftigt, zu verstehen, was ChatGPT ist, was stabile Diffusion usw. ist, aber die Algorithmusingenieure haben verrückte Kopfschmerzen und beschweren sich wie verrückt. Die Leiter bitten sie, so schnell wie möglich ein großes Modell zu erstellen und die Algorithmusmodellindikatoren zu verbessern Als ich so schnell wie möglich am Algorithmus-Team vorbeikam, hörte ich das folgende Gespräch:
Gong Zhang: Bruder Hu, wie läuft deine Modelausbildung?
Gong Hu: Leider ist es schwierig, es in einem Satz zu erklären. Ich habe die Daten schließlich nicht an die Geschäftsabteilung übermittelt, oder die Daten, die sie gesammelt haben, waren alle unterschiedlich gebraucht?
Gong Zhang: Bei mir ist das nicht der Fall. Kürzlich summierten sich die Bilder und Videos des Kunden auf mehr als 10 T. Allein der Import der Daten hat unser Team lange gekostet.
Gong Hu sagte, wenn das Unternehmen eine Datenplattform aufbauen kann, die es uns ermöglicht, Daten schnell abzurufen und zu verwalten, wird es für uns bequemer sein, Daten in unserer täglichen Arbeit zu verwenden.
Nachdem ich das obige Gespräch gehört hatte, kam mir eine Idee, die ich kürzlich für Kunden entwickelt habe, die auf der Idee der Datenweberei basieren. Deshalb habe ich ihnen schnell eine detaillierte Produkteinführung gegeben und ihnen erklärt, wie das geht Verwenden Sie „Daten“. Das Designkonzept des „Webens“ wird verwendet, um eine Datenverwaltungsplattform aufzubauen, die Benutzern hilft, den Datenengpass beim KI-Anwendungstraining zu überwinden.
2. Schwierigkeiten bei der Anwendung des KI-Trainings
Mit Ausnahme der subjektiven Personalprobleme fassen wir die objektiven Schwierigkeiten des KI-Anwendungstrainings zusammen, die sich in den folgenden drei Punkten zusammenfassen lassen:

Hochwertige Daten: Um gute Ergebnisse beim Algorithmustraining zu erzielen, sind qualitativ hochwertige Daten die erste Voraussetzung. Es gibt jedoch folgende Schwierigkeiten:
- Datenvielfalt: Es gibt strukturierte/unstrukturierte Daten in vielen Formaten und den von verschiedenen Systemen bereitgestellten Daten fehlen einheitliche Standards.
- Datenverteilung: Viele Geschäftsdaten werden diskret gespeichert und es fehlt eine einheitliche Datenverwaltungsplattform. Es ist schwierig, Daten vor dem Anwendungstraining zu erhalten.
- Datenanmerkung: Daten können sofort abgerufen werden, aber eine große Menge an Geschäftsdaten muss vor der Anwendung mit Anmerkungen versehen werden, und die Annotation ist zeit- und arbeitsintensiv.
Effiziente Rechenleistung: Bezieht sich auf das Training eines Modells, das normalerweise viel Rechenleistung erfordert. Gleichzeitig ist es schwierig, die Rechenleistung effizient zu nutzen
- Da große Modelle jederzeit schrittweise gefördert werden, wird die Modellgröße immer größer und auch der Bedarf an Rechenleistung steigt rapide an.
- Wenn die Datenspeicherung diskret ist, verlangsamt sich der Zugriff auf Daten. Selbst bei Cluster-Rechenleistung wird die Rechenleistung nicht effizient genutzt, wenn Parallelität nicht möglich ist.
Ausgereiftes Framework: bezieht sich auf Algorithmusanwendungen, die ausgereifte, stabile und hoch skalierbare Algorithmus-Frameworks erfordern
- Anwendungsframework: Derzeit gibt es im In- und Ausland viele Deep-Learning-Algorithmus-Frameworks. Für die Algorithmenforschung (Pytorch) und die industrielle Anwendung (Tensorflow) müssen Sie unterschiedliche Frameworks auswählen.
- Datenkonvertierung: Aufgrund unterschiedlicher Frameworks und verwendeter Sprachen müssen qualitativ hochwertige Daten schnell an verschiedene Sprachen und Trainingsframeworks angepasst werden, auch wenn sie vorbereitet werden.
Zusammenfassung: Aus der Analyse der drei Schwierigkeiten beim KI-Anwendungstraining geht hervor, dass sie alle mit Daten zusammenhängen. Wenn das Datenproblem gelöst werden kann, kann es daher effektiv dabei helfen, den Engpass beim KI-Anwendungstraining zu überwinden.
3. Sind Daten der Flaschenhals von KI-Anwendungen?Obwohl das Zusammenfassen von Daten von der Anwendungsseite den Engpass beim Training von KI-Anwendungen darstellt, stellt sich die Frage, wie viele Benutzer das glauben? Zur Veranschaulichung ist ein Datenelement erforderlich.

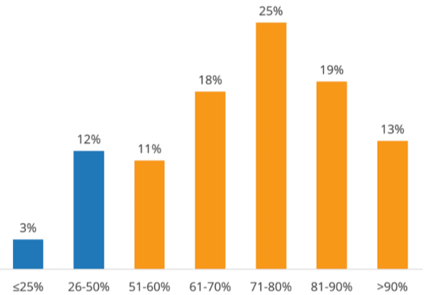
Die Daten stammen aus dem IDC-Statistikbericht Aus den Statistiken geht hervor, dass 29 % der Benutzer der Meinung sind, dass es bei Anwendungen für künstliche Intelligenz an Trainings- und Testdaten mangelt, und 85 % der Benutzer glauben, dass mindestens die Hälfte des Arbeitsaufwands für die Datenaufbereitung aufgewendet wird.
Zusammenfassung: Da Daten nachweislich tatsächlich der Flaschenhals von KI-Anwendungen sind, können Sie erwägen, einen Einstiegspunkt aus den Daten zu finden, um „einheitliche Standards und schnellen Zugriff auf große Mengen hochverfügbarer Datenquellen“ für die Produktausführung bereitzustellen Planung der Positionierung. 4. Produktdesign
Nachdem wir Daten als Einstiegspunkt gefunden haben, haben wir darüber nachgedacht, wie wir datenbasierte Produkte erstellen können. Basierend auf der obigen Analyse können wir feststellen, dass wir drei datenbasierte Probleme in unseren Produkten lösen müssen:
- Frage 1:
- Datenspeicherung: Versuchen Sie, den Speicherort der Quelldaten nicht zu ändern und die Kosten für die Datenspeicherung zu minimieren. Frage 2:
- Schneller Zugriff, am besten von der frühen Datenabfrage bis zur Datenbegründung, schnelle Suche nach den erforderlichen Daten. Frage 3:
- Standards vereinheitlichen, um komplexe Daten für eine einfache Anwendung zu standardisieren. Basierend auf der traditionellen Datenverwaltungsplattform übernehmen wir das Konzept „Datenweberei + Wissensgraph“, um ein revolutionäres Design zur Bewältigung der oben genannten Probleme durchzuführen. Die bahnbrechenden Punkte jeder Ausgabe sind wie folgt:
- Frage 1:
- Design basierend auf der Idee der Datenweberei Frage 2:
- Design basierend auf der Idee des Wissensgraphen Frage 3:
- Bereitstellung externer Dienste auf Basis einer einheitlichen Datenplattform Der nächste Schritt ist das detaillierte Design des Produkts, das anhand der Produktpositionierung, der Anwendungsarchitektur, der differenzierten Wettbewerbsfähigkeit und des Konstruktionspfads vorgestellt wird.
1. Produktarchitektur
1) ProduktpositionierungBereitstellung einer Datenverwaltungsplattform im Knowledge-Graph-Stil, die auf der Idee der Datenweberei basiert, um Kunden zu bedienen, die qualitativ hochwertige Daten benötigen.
Hinweis:Obwohl das Hauptziel darin besteht, den Datenengpass beim KI-Anwendungstraining zu lösen, haben wir aus Sicht der Produktplanung die Benutzerszenarien erweitert, und jeder, der Datendienste benötigt, ist der Zielbenutzer dieses Produkts.
2) ProduktanwendungsarchitekturVon der Datenschicht bis zur Produktanwendungsschicht entwerfen wir die folgende Produktarchitektur:
 Datenschicht: Unterstützt den Zugriff auf verschiedene Datentypen sowie auf strukturierte und unstrukturierte Daten. Es gibt viele Datentypen für das KI-Training, insbesondere multimodale Anwendungen, die mehrere Datentypen erfordern.
Datenschicht: Unterstützt den Zugriff auf verschiedene Datentypen sowie auf strukturierte und unstrukturierte Daten. Es gibt viele Datentypen für das KI-Training, insbesondere multimodale Anwendungen, die mehrere Datentypen erfordern.
Speicherschicht: Angesichts der diskreten Natur von Daten ist es notwendig, die Speicherung von Daten an verschiedenen Orten zu unterstützen und den Zugriff von Cloud-Daten auf lokale Daten zu unterstützen.
Datenverwaltungsplattform: Das Kernprodukt, das dieses Mal entworfen werden soll, besteht hauptsächlich aus vier Teilen:
Datenverwaltung: Ein gemeinsames Modul herkömmlicher Datenverwaltungsplattformen, das Funktionen wie Datenanalyse, Bereinigung und Regeldefinition bereitstellt.
- Datensicherheit: Es ist ebenfalls ein traditionelles Modul und bietet Funktionen im Zusammenhang mit der Datensicherheit, wie z. B. Datendesensibilisierung, sichere Datenübertragung usw.
- Datenvirtualisierungsspeicherung und verteilter Cache: Hier wird die Idee des Datenwebens verwendet, um Daten von verschiedenen Plattformen zu einer Datenansicht zu verweben. Gleichzeitig werden nur die logischen Informationen der gespeicherten Daten virtualisiert Durch Migration und Kopieren werden die Speicherkosten gesenkt. Um Daten schnell abzurufen, ist im Design ein verteilter Cache vorgesehen, um häufig aufgerufene Daten zwischenzuspeichern, die E/A-Geschwindigkeit und Parallelität von Daten für das Training von KI-Algorithmen zu verbessern und die Datenverarbeitung zu maximieren Leistung. Cluster-Effizienz erzwingen.
- Wissensdiagramm: Bereinigen Sie die Daten, definieren Sie Regeln, speichern Sie sie in Form von Wissensdiagramm-Tripeln und stellen Sie Abfragedienste in Form von Wissensdiagrammen bereit. Das Wissensdiagramm dient der Suchbegründung und kann durch eine Entität geleitet werden Wenn Sie beispielsweise Filmvideodaten abfragen, können Sie nach den Schauspielern „Wang Baoqiang“ und „Xu Zheng“ suchen Durch die Assoziationsinferenzabfrage können Sie Benutzern auf der Plattform helfen, die erforderlichen Daten schnell zu extrahieren.
- Datendienste: Nach der Gestaltung der Plattform ist es notwendig, einen Absatzmarkt für externe Dienste zu reservieren. Ausgehend von der Positionierung des Produkts ist es hauptsächlich auf toB-Kunden ausgerichtet, sodass sowohl visuelle Dienste als auch API-Dienste berücksichtigt werden müssen.
API/SDK-Dienst: Für Unternehmen oder Benutzer mit technischen Fähigkeiten, wie z. B. dem Engpass bei KI-Trainingsanwendungen, den dieser Artikel lösen möchte, können Sie die KI-Plattform direkt in den API-Dienst der Datenplattform integrieren, um die zu erhalten erforderliche Daten und verwenden Sie die bereinigten Daten für das Modelltraining.
- Hinweis:
- Im Allgemeinen erfordern KI-Trainingsplattformen annotierte Daten. Sie können also zuerst die Annotationsplattform verbinden und die Daten dann direkt an die KI-Trainingsplattform übertragen. Visuelle Abfrage: Neben der Berücksichtigung des Andockens auf technischer Ebene müssen wir natürlich auch das Verhalten von Geschäftsbenutzern berücksichtigen, z. B. beim Abfragen von Daten und beim Herunterladen von Daten auf der Plattform, auf die sich Produktmanager und Betriebsleiter verlassen müssen Die von der Plattform selbst bereitgestellte visuelle Abfrage importiert sie. Andere Geschäftsplattformen werden für die Verarbeitung und Produktion verwendet. Die visuelle Abfrage übernimmt eine Diagrammstruktur und verwendet den Tianyancha-Stil als Referenz Die zugehörigen Daten werden gleichzeitig angezeigt, um den Rückschluss und die Abfrage durch den Benutzer zu erleichtern.
Hinweis: Tianyancha-Screenshots dienen nur als Lernreferenz
2. Kommerzialisierung
Sobald das Produkt auf den Markt kommt, ist keine Kommerzialisierung möglich, daher muss die Kommerzialisierungsrichtung während der Produktplanungsphase klar berücksichtigt werden und die folgenden drei Schlüsselaspekte sollten berücksichtigt werden:
1) Inhalte verkaufen
Für B-End-Kunden bieten wir zwei Arten von Vertriebsinhalten an, darunter Standardprodukte „Datenverwaltungsplattform“ und „technische Lösungen“.
- Standardprodukte: Für Benutzer ohne Datenverwaltungsplattform müssen Benutzer nur unsere Standardprodukte kaufen, auf die Daten zugreifen und sie dann in ihrem Unternehmen anwenden, damit sie sofort verwendet werden können.
- Technische Lösungen: Nach den Auswirkungen des digitalen Transformationstrends werden viele B-seitige Unternehmenskunden mehr oder weniger über eigene Datenverwaltungsplattformen verfügen. Daher besteht ein weiteres Verkaufsargument von toB darin, ausgereifte technische Lösungen zu verkaufen, die die bestehenden Produkte des Unternehmens ergänzen können Um eine Transformation und ein Upgrade durchzuführen, müssen wir die Produkte des Kunden zu diesem Zeitpunkt auf der Grundlage der Designidee „Datenweberei + Wissensgraph“ von der untersten Ebene in die Serviceebene umwandeln.
2) Verkaufsmethode
Die beiden gängigen Vertriebsmodelle für B-End-Produkte sind „Channel-Kooperation“ und „Direktvertrieb“. Diese Methoden kommen auch bei diesem Produkt zum Einsatz.
- Kanalkooperation: Es werden zwei Arten der Kanalkooperation ausgewählt, die sie vor Ort fördern. Das andere ist das ISV-Modell, bei dem ein zentraler Agent mit technischen Fähigkeiten gefunden wird, der mit der Datenverwaltungsplattform zusammenarbeitet Wir können unsere Vorteile gegenseitig ergänzen und sie gemeinsam nach außen bekannt machen.
- Direktvertrieb: Direktvertrieb von Produkten durch Produkteinführungen, Werbeaktionen, Kundenbesuche usw.
3) Differenzierungsvorteile
Da es sich um eine Datenverwaltungsplattform handelt, die auf neuen Designideen basiert, muss sie während des Produktverkaufsprozesses ihre differenzierten Vorteile gegenüber herkömmlichen Datenverwaltungsplattformen widerspiegeln, um aufzuholen und Benutzer anzulocken. Wir können sie in den folgenden drei Vorteilen zusammenfassen :
- Datenweberei: Dieses Produkt übernimmt die Idee der Datenweberei für die Datenverwaltung und nutzt Datenvirtualisierungsspeicher, um die physischen Speicherkosten von Daten zu reduzieren. Gleichzeitig nutzt es Datencaching, um die Zugriffsverzögerung beim Abrufen von Daten während der KI zu reduzieren Bewerbungstraining.
- KI-Funktionen: Anders als bei der herkömmlichen Datenplattform-Abrufmethode wird dieses Produkt direkt in Form einer Wissensdiagrammansicht dargestellt. Der Benutzer kann nur eine einfache Bedingung eingeben, und das System kann die relevante Datenbeziehungstopologie zurückgeben und erkennen „Daten finden Menschen“.
- Ausgereifte Standardprodukte: Obwohl Sie technische Lösungen verkaufen können, ist es schwierig, Kunden ohne ausgereifte Standardprodukte zu beeindrucken. Daher verkaufen wir im Gegensatz zu traditionellen Herstellern, die große und umfassende Datenmanagementplattformen verkaufen, „kleine, aber anspruchsvolle“ Daten aus einer Hand Managementplattform.
Die Reife des Produkts erfordert auch einen kontinuierlichen Konstruktionsprozess. Während des Konstruktionsprozesses dieses Produkts basiert es auf „Projektpolierprodukten“ und wird in zwei Hauptphasen aufgebaut.
- Projektabwicklung, Technologiepräzipitation: Durch die Durchführung halbprivatisierter Datenprojekte werden die Ideen für die Datenwebung und den Aufbau von Wissensgraphen im Projekt umgesetzt und eine Technologiepräzipitation erreicht.
- Produktimplementierung und Markenwerbung: Produkte aus tatsächlichen Projekten abstrahieren und iterativ umsetzen. Nachdem Sie das Produkt erstellt haben, branden Sie es und bewerben Sie es nach außen.
Dieser Artikel konzentriert sich auf den Engpass beim KI-Anwendungstraining, fasst die Schwierigkeiten des KI-Trainings zusammen und kombiniert sie mit IDC-Analyseberichten, um zu dem Schluss zu kommen, dass „Daten“ der größte Engpass sind, und erörtert Lösungen für dieses Problem.
Führen Sie ein Produkttransformationsdesign basierend auf den Konzepten der Datenweberei und des Wissensgraphen durch und führen Sie eine intelligente Datenverwaltungsplattform für „Daten findende Personen“ aus den Perspektiven der Produktpositionierung, Produktarchitektur, Anwendungsszenarien usw. im Detail ein Außerdem können Werbeideen und Konstruktionspfade Kunden bei Datenanwendungsszenarien wie KI-Trainingsplattformen, Datenanmerkungsplattformen und sogar Kunden helfen, die herkömmliche Datenverwaltungsprodukte transformieren und aktualisieren müssen.
In Zukunft werden wir die Idee der Ausweitung der Datenverflechtung auf den eigentlichen Prozess des modellparallelen Trainings weiter untersuchen und nach einer besseren Durchführbarkeit der Dateneffizienz streben.
Kolumnist
Eric_d, der Produktmanager-Kolumnist für alle. Ich habe eine Leidenschaft für KI, Big Data und andere Bereiche. Ich verfüge über ausgezeichnete Fähigkeiten in den Bereichen Anforderungsanalyse, Produktprozess und Architekturdesign.
Dieser Artikel wurde von „Everyone is a Product Manager’s „Original Incentive Plan“ erstellt.
Das Titelbild stammt von Unsplash, basierend auf der CC0-Lizenz.
Das obige ist der detaillierte Inhalt vonAnwendung in der KI-Branche: Datenweberei verhilft zu Durchbrüchen beim Training von KI-Anwendungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr