
Heim >Technologie-Peripheriegeräte >KI >Ein großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet
Ein großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet

- PHPznach vorne
- 2023-06-07 22:33:211404Durchsuche
Die Leistung vorab trainierter großer Sprachmodelle (LLM) bei bestimmten Aufgaben verbessert sich anschließend, wenn die prompten Anweisungen angemessen sind. Viele Menschen führen dieses Phänomen auf die Zunahme zurück Beim Trainieren von Daten und Parametern zeigen aktuelle Trends, dass Forscher sich mehr auf kleinere Modelle konzentrieren, diese Modelle jedoch auf mehr Daten trainiert werden und daher bei der Inferenz einfacher zu verwenden sind.
Zum Beispiel wurde LLaMA mit einer Parametergröße von 7B auf 1T-Tokens trainiert. Obwohl die durchschnittliche Leistung etwas niedriger ist als bei GPT-3, beträgt die Parametergröße 1/25 davon. Darüber hinaus können aktuelle Komprimierungstechnologien diese Modelle weiter komprimieren, wodurch der Speicherbedarf bei gleichbleibender Leistung deutlich reduziert wird. Mit solchen Verbesserungen können leistungsstarke Modelle auf Endbenutzergeräten wie Laptops bereitgestellt werden.
Allerdings steht dies vor einer weiteren Herausforderung: Wie können diese Modelle unter Berücksichtigung der Generierungsqualität auf eine ausreichend kleine Größe komprimiert werden, um in diese Geräte zu passen? Untersuchungen zeigen, dass komprimierte Modelle zwar Antworten mit akzeptabler Genauigkeit generieren, bestehende 3-4-Bit-Quantisierungstechniken jedoch immer noch die Genauigkeit verschlechtern. Da die LLM-Generierung sequentiell erfolgt und auf zuvor generierten Token basiert, häufen sich kleine relative Fehler und führen zu schwerwiegenden Ausgabefehlern. Um eine zuverlässige Qualität sicherzustellen, ist es wichtig, Quantisierungsmethoden mit geringer Bitbreite zu entwickeln, die die Vorhersageleistung im Vergleich zu 16-Bit-Modellen nicht beeinträchtigen.
Allerdings führt die Quantisierung jedes Parameters auf 3–4 Bit häufig zu moderaten oder sogar hohen Genauigkeitsverlusten, insbesondere bei kleineren Modellen im Parameterbereich 1–10B, die sich ideal für den Edge-Einsatz eignen.
Um das Genauigkeitsproblem zu lösen, schlugen Forscher der University of Washington, der ETH Zürich und anderer Institutionen ein neues Komprimierungsformat und eine Quantisierungstechnologie SpQR (Sparse-Quantized Representation, spärlich quantisierte Darstellung) vor, die für die implementiert wurde Zum ersten Mal bietet LLM eine nahezu verlustfreie Komprimierung über Modellskalen hinweg und erreicht dabei ähnliche Komprimierungsniveaus wie frühere Methoden.
SpQR identifiziert und isoliert anomale Gewichte, die besonders große Quantisierungsfehler verursachen, speichert sie mit höherer Präzision, während alle anderen Gewichte in LLaMA auf 3-4 Bits komprimiert werden, und erreicht in Perplexity einen relativen Genauigkeitsverlust von weniger als 1 % Falcon-LLMs. Dadurch kann ein 33-B-Parameter-LLM auf einer einzelnen 24-GB-Consumer-GPU ohne Leistungseinbußen ausgeführt werden und ist gleichzeitig 15 % schneller.
Der SpQR-Algorithmus ist effizient und kann die Gewichte sowohl in andere Formate kodieren als auch zur Laufzeit effizient dekodieren. Konkret stellt diese Forschung SpQR einen effizienten GPU-Inferenzalgorithmus zur Verfügung, der eine schnellere Inferenz als 16-Bit-Basismodelle ermöglicht und gleichzeitig eine über 4-fache Steigerung der Speicherkomprimierung erzielt.

- Papieradresse: https://arxiv.org/pdf/2306.03078.pdf
- Projektadresse: https://github.com/Vahe1994/SpQR
Methode
Diese Studie schlägt ein neues Format für die hybride Sparse-Quantisierung vor – Sparse Quantization Representation (SpQR), das präzise vorab trainierte LLM auf 3–4 Bits pro Parameter komprimieren kann und dabei nahezu verlustfrei bleibt.
Konkret unterteilte die Studie den gesamten Prozess in zwei Schritte. Der erste Schritt ist die Erkennung von Ausreißern: Die Studie isoliert zunächst die Ausreißergewichte und zeigt, dass ihre Quantisierung zu hohen Fehlern führt: Ausreißergewichte bleiben mit hoher Präzision erhalten, während andere Gewichte mit geringer Präzision gespeichert werden (z. B. in einem 3-Bit-Format). Die Studie implementiert dann eine Variante der gruppierten Quantisierung mit sehr kleinen Gruppengrößen und zeigt, dass die Quantisierungsskala selbst in eine 3-Bit-Darstellung quantisiert werden kann.
SpQR reduziert den Speicherbedarf von LLM erheblich, ohne die Genauigkeit zu beeinträchtigen, und produziert LLM im Vergleich zur 16-Bit-Inferenz um 20–30 % schneller.
Darüber hinaus ergab die Studie, dass die Positionen sensibler Gewichte in der Gewichtsmatrix nicht zufällig sind, sondern eine bestimmte Struktur haben. Um seine Struktur während der Quantifizierung hervorzuheben, berechnete die Studie die Empfindlichkeit jedes Gewichts und visualisierte diese Gewichtsempfindlichkeiten für das LLaMA-65B-Modell. Abbildung 2 unten zeigt die Ausgabeprojektion der letzten Selbstaufmerksamkeitsschicht von LLaMA-65B.
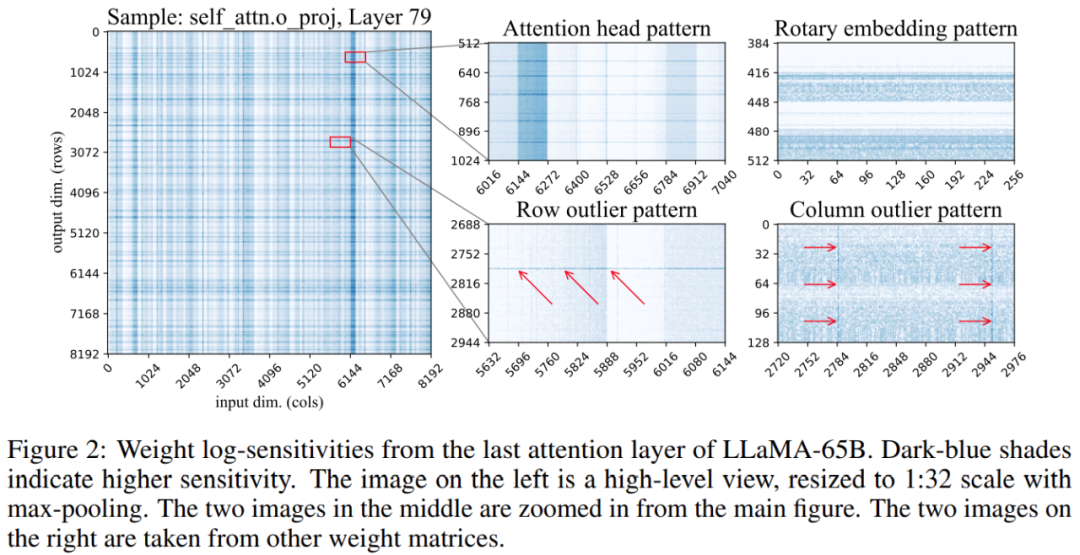
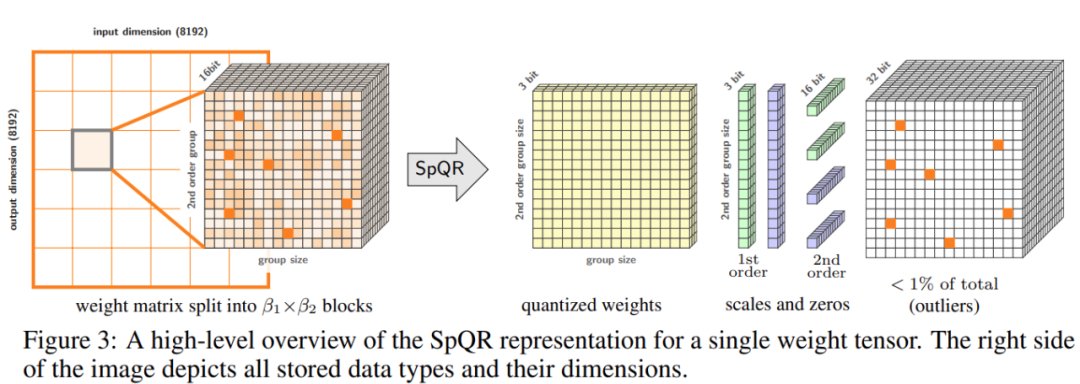
Diese Studie nimmt zwei Änderungen am Quantifizierungsprozess vor: eine zur Erfassung kleiner empfindlicher Gewichtsgruppen und die andere zur Erfassung einzelner Ausreißer. Abbildung 3 unten zeigt die Gesamtarchitektur von SpQR:
Die folgende Tabelle zeigt den SpQR-Quantisierungsalgorithmus. Das Codefragment auf der linken Seite beschreibt den gesamten Prozess, und das Codefragment auf der rechten Seite enthält Unterprogramme für die Sekundärseite Quantisierung und Finden von Ausreißern. :

Die Studie verglich SpQR mit zwei anderen Quantisierungsschemata: GPTQ, RTN (Aufrunden auf den nächsten Wert) und verwendete zwei Metriken, um die Leistung des Quantisierungsmodells zu bewerten. Die erste ist die Messung der Perplexität unter Verwendung von Datensätzen wie WikiText2, Penn Treebank und C4; die zweite ist die Null-Stichproben-Genauigkeit bei fünf Aufgaben: WinoGrande, PiQA, HellaSwag, ARC-easy, ARC-challenge.
Hauptergebnisse. Die Ergebnisse aus Abbildung 1 zeigen, dass SpQR bei ähnlichen Modellgrößen deutlich besser abschneidet als GPTQ (und das entsprechende RTN), insbesondere bei kleineren Modellen. Diese Verbesserung ist darauf zurückzuführen, dass SpQR eine stärkere Komprimierung erzielt und gleichzeitig die Verlustverschlechterung reduziert.
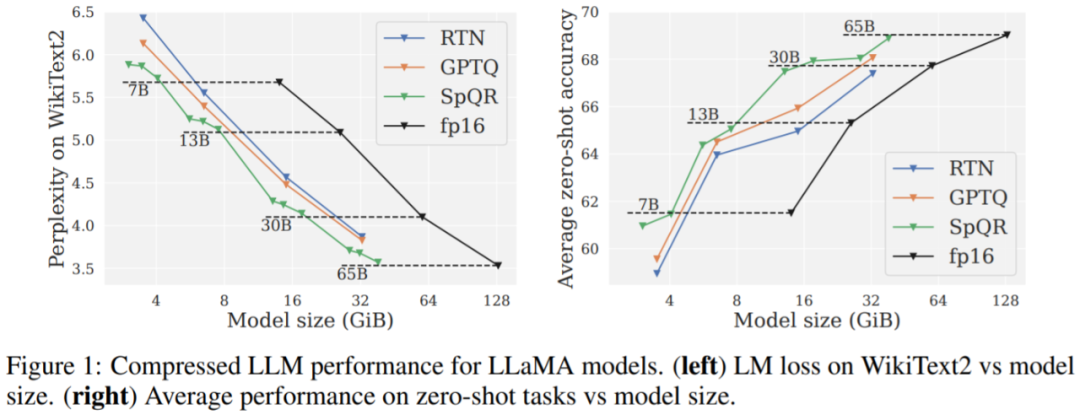
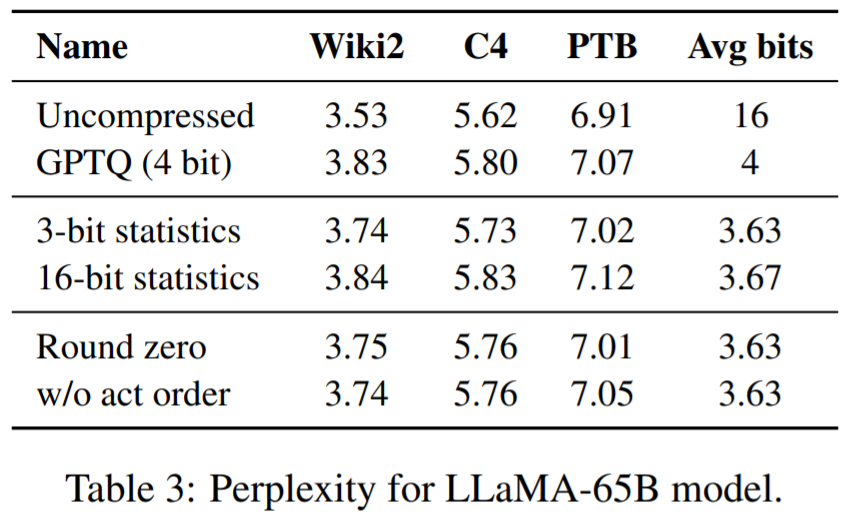
Tabelle 1, Tabelle 2 Die Ergebnisse zeigen, dass bei der 4-Bit-Quantisierung der Fehler von SpQR relativ zur 16-Bit-Basislinie im Vergleich zu GPTQ halbiert ist.
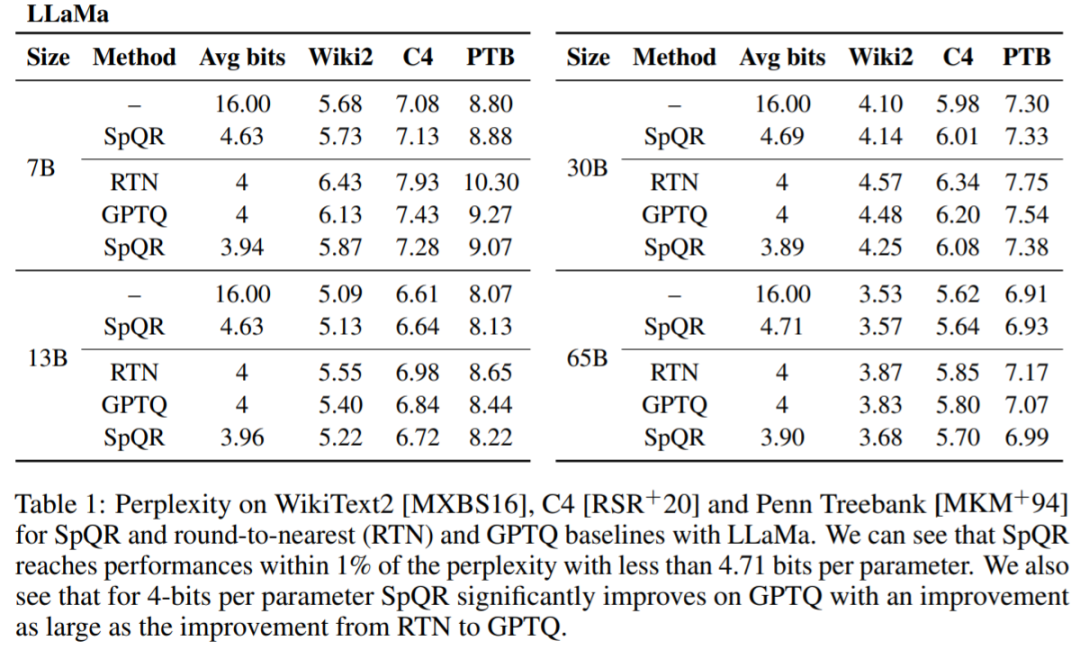
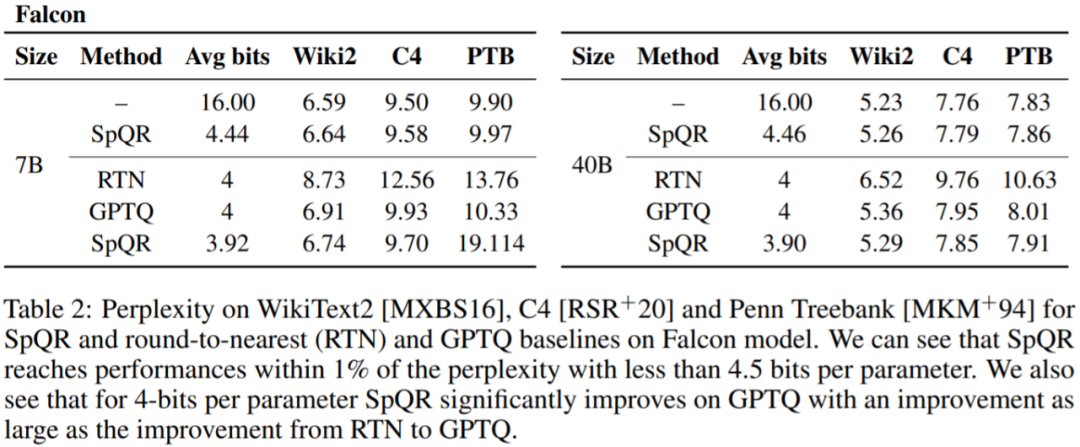
Tabelle 3 zeigt die Verwirrungsergebnisse des LLaMA-65B-Modells für verschiedene Datensätze.
Abschließend bewertet die Studie die SpQR-Inferenzgeschwindigkeit. In dieser Studie wird ein speziell entwickelter Sparse-Matrix-Multiplikationsalgorithmus mit dem in PyTorch (cuSPARSE) implementierten Algorithmus verglichen. Die Ergebnisse sind in Tabelle 4 aufgeführt. Wie Sie sehen können, ist die standardmäßige Sparse-Matrix-Multiplikation in PyTorch zwar nicht schneller als die 16-Bit-Inferenz, der in diesem Artikel speziell entwickelte Sparse-Matrix-Multiplikationsalgorithmus kann die Geschwindigkeit jedoch um etwa 20–30 % verbessern.

Das obige ist der detaillierte Inhalt vonEin großes 33-Milliarden-Parameter-Modell in eine einzige Verbraucher-GPU „packen', was eine Geschwindigkeitssteigerung von 15 % ohne Leistungseinbußen bedeutet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr