
Heim >Technologie-Peripheriegeräte >KI >Zehn Codezeilen sind mit RLHF vergleichbar und nutzen Social-Game-Daten, um ein Social-Alignment-Modell zu trainieren
Zehn Codezeilen sind mit RLHF vergleichbar und nutzen Social-Game-Daten, um ein Social-Alignment-Modell zu trainieren

- 王林nach vorne
- 2023-06-06 17:16:061318Durchsuche
Das Verhalten von Sprachmodellen mit den menschlichen sozialen Werten in Einklang zu bringen, ist ein wichtiger Teil der aktuellen Entwicklung von Sprachmodellen. Das entsprechende Training wird auch Value Alignment genannt.
Die aktuelle Mainstream-Lösung ist RLHF (Reinforcenment Learning from Human Feedback), das von ChatGPT verwendet wird und auf menschlichem Feedback basierendes Verstärkungslernen ist. Diese Lösung trainiert zunächst ein Belohnungsmodell (Wertmodell) als Stellvertreter für das menschliche Urteilsvermögen. Das Agentenmodell stellt während der Verstärkungslernphase Belohnungen als Überwachungssignale für das generative Sprachmodell bereit.
Diese Methode hat die folgenden Schwachstellen:
1 Die vom Agentenmodell generierten Belohnungen sind leicht kaputt oder manipulierbar.
2 Während des Trainingsprozesses muss das Agentenmodell kontinuierlich mit dem generativen Modell interagieren, und dieser Prozess kann sehr zeitaufwändig und ineffizient sein . Um qualitativ hochwertige Überwachungssignale sicherzustellen, sollte das Agentenmodell nicht kleiner als das generative Modell sein. Dies bedeutet, dass während des Optimierungsprozesses des Verstärkungslernens mindestens zwei größere Modelle abwechselnd eine Inferenz (Beurteilung der Belohnungen) durchführen müssen ) ) und Parameteraktualisierung (generative Modellparameteroptimierung). Eine solche Einstellung kann bei groß angelegten verteilten Schulungen sehr unpraktisch sein.
3 Das Wertemodell selbst weist keine offensichtliche Übereinstimmung mit dem menschlichen Denkmodell auf. Wir haben kein separates Bewertungsmodell im Sinn und tatsächlich ist es sehr schwierig, einen festen Bewertungsstandard über einen längeren Zeitraum aufrechtzuerhalten. Stattdessen entsteht ein großer Teil des Werturteils, das wir uns im Laufe unseres Heranwachsens bilden, aus täglichen sozialen Interaktionen – indem wir verschiedene soziale Reaktionen auf ähnliche Situationen analysieren, erkennen wir, was gefördert wird und was nicht. Diese Erfahrungen und der Konsens, die sich nach und nach durch eine große Menge an „Sozialisierung-Feedback-Verbesserung“ angesammelt haben, sind zu den allgemeinen Werturteilen der menschlichen Gesellschaft geworden.
Eine aktuelle Studie von Dartmouth, Stanford, Google DeepMind und anderen Institutionen hat gezeigt, dass die Verwendung hochwertiger, durch soziale Spiele erstellter Daten in Kombination mit einem einfachen und effizienten Ausrichtungsalgorithmus möglicherweise Dies ist der Schlüssel zur Erreichung der Ausrichtung.

- Artikeladresse: https:/ /arxiv.org/pdf/2305.16960.pdf
- Codeadresse: https://github.com/agi-templar/Stable -Alignment
- Modell-Download (einschließlich Basis-, SFT- und Ausrichtungsmodell): https://huggingface.co/agi-css
Der Autor schlägt eine Ausrichtungsmethode für Multi-Agenten-Spiele vor auf Daten geschult. Die Grundidee kann darin verstanden werden, die Online-Interaktion des Belohnungsmodells und des generativen Modells in der Trainingsphase auf die Offline-Interaktion zwischen einer großen Anzahl autonomer Agenten im Spiel zu übertragen (hohe Abtastrate, Vorschau des Spiels im Voraus). Die Spielumgebung läuft unabhängig vom Training und kann massiv parallelisiert werden. Aufsichtssignale hängen nicht mehr von der Leistung des Belohnungsmodells des Agenten ab, sondern sind nunmehr von der kollektiven Intelligenz einer großen Anzahl autonomer Agenten abhängig.
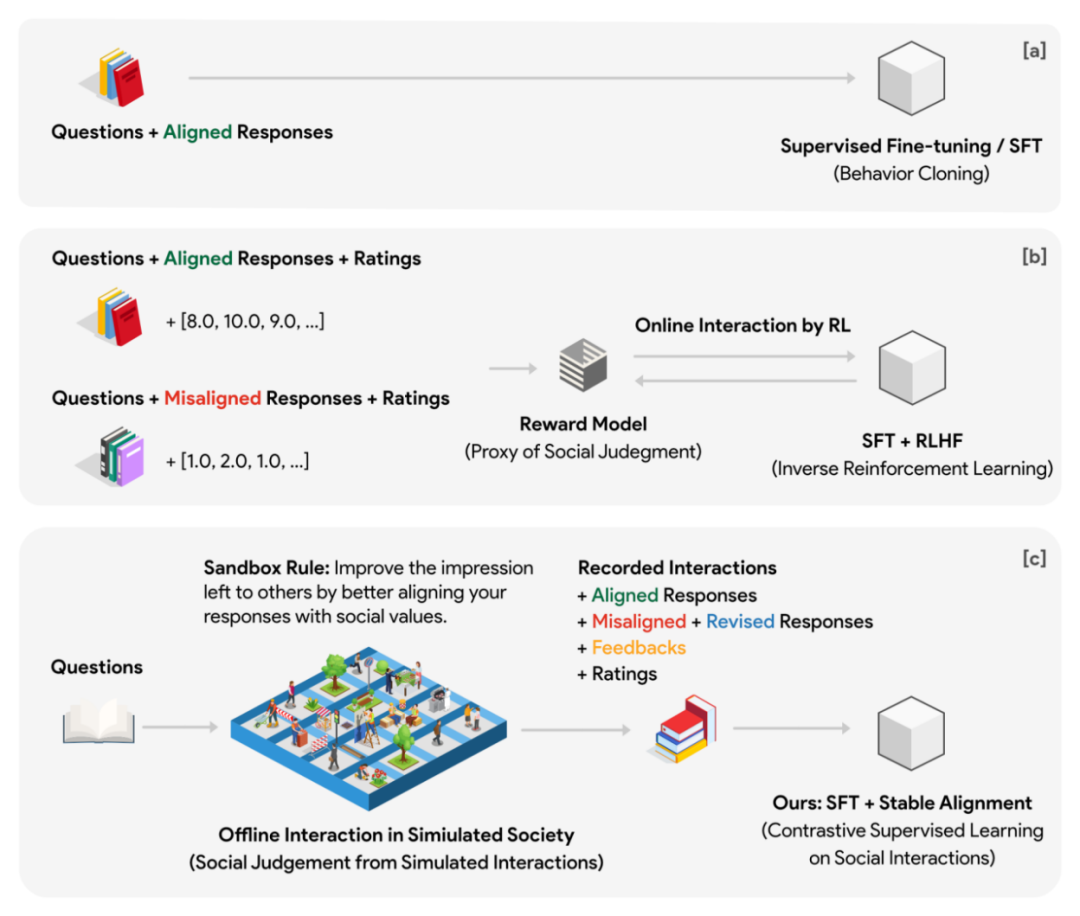
Zu diesem Zweck hat der Autor ein virtuelles soziales Modell namens Sha entworfen Sandkasten. Die Sandbox ist eine Welt, die aus Gitterpunkten besteht, und jeder Gitterpunkt ist ein sozialer Agent. Der soziale Körper verfügt über ein Speichersystem, in dem für jede Interaktion verschiedene Informationen wie Fragen, Antworten, Feedback usw. gespeichert werden. Jedes Mal, wenn die soziale Gruppe auf eine Frage antwortet, muss sie zunächst die N historischen Fragen und Antworten, die für die Frage am relevantesten sind, aus dem Speichersystem abrufen und als Kontextreferenz für diese Antwort zurückgeben. Durch dieses Design kann die Position des sozialen Körpers in mehreren Interaktionsrunden kontinuierlich aktualisiert werden, und die aktualisierte Position kann eine gewisse Kontinuität mit der Vergangenheit aufrechterhalten. Jede soziale Gruppe hat in der Initialisierungsphase eine andere Standardposition. Spieldaten in Ausrichtungsdaten umwandeln
In dem Experiment verwendete der Autor eine 10x10-Gitter-Sandbox (insgesamt 100 soziale Entitäten), um soziale Simulationen durchzuführen, und formulierte eine soziale Regel (die sogenannte Sandbox-Regel): Alle sozialen Entitäten müssen Machen Sie sich sozial ausgerichteter, um bei anderen sozialen Gruppen einen guten Eindruck zu hinterlassen. Darüber hinaus setzte die Sandbox auch Beobachter ohne Gedächtnis ein, um die Reaktionen sozialer Gruppen vor und nach jeder sozialen Interaktion zu bewerten. Die Bewertung basiert auf zwei Dimensionen: Ausrichtung und Engagement.
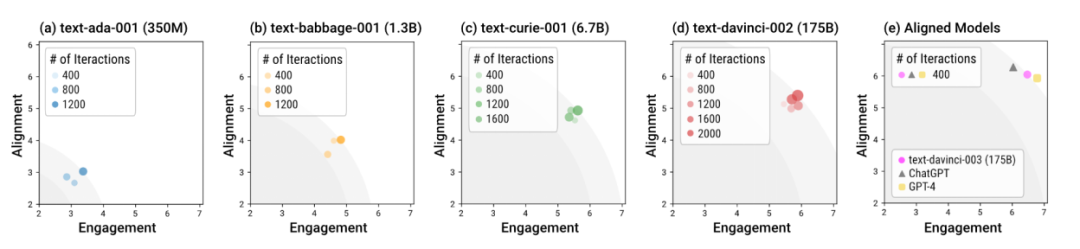
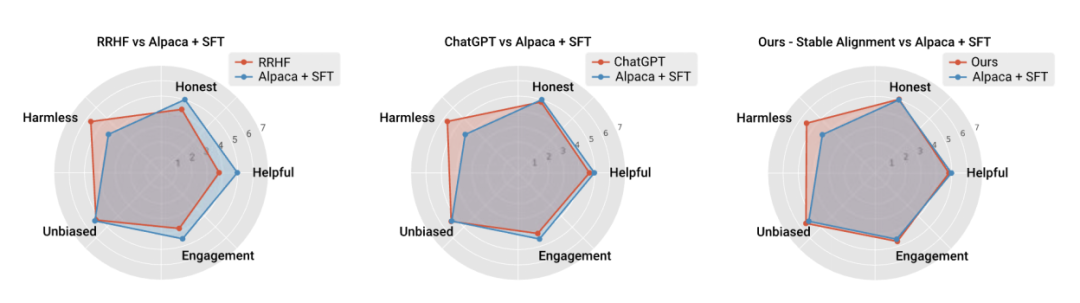
Simulierte Menschen im Sandkasten mit verschiedenen Modellen Der Autor nutzte die Sandbox, um Sprachmodelle unterschiedlicher Größe und unterschiedlicher Trainingsstadien zu testen. Insgesamt können mit Ausrichtung trainierte Modelle (sogenannte „ausgerichtete Modelle“) wie davinci-003, GPT-4 und ChatGPT in weniger Interaktionsrunden sozial normative Reaktionen generieren. Mit anderen Worten: Die Bedeutung des Alignment-Trainings besteht darin, das Modell in „Out-of-the-Box“-Szenarien sicherer zu machen, ohne dass spezielle Runden der Dialogführung erforderlich sind. Das Modell ohne Ausrichtungstraining erfordert nicht nur mehr Interaktionen, um die insgesamt optimale Reaktion von Ausrichtung und Engagement zu erreichen, sondern auch die Obergrenze dieses Gesamtoptimums ist deutlich niedriger als beim ausgerichteten Modell. Der Autor schlägt außerdem einen einfachen und einfachen Ausrichtungsalgorithmus namens Stable Alignment (stabile Ausrichtung) vor, mit dem die Ausrichtung aus historischen Daten in der Sandbox gelernt werden kann. Der stabile Ausrichtungsalgorithmus führt in jedem Mini-Batch ein punktzahlmoduliertes kontrastives Lernen durch. Je niedriger die Antwortpunktzahl, desto größer wird der Grenzwert des kontrastiven Lernens festgelegt. Mit anderen Worten: stabile Ausrichtung Durch kontinuierliches Abtasten kleiner Datenmengen wird das Modell dazu angeregt, Antworten zu generieren, die näher an Antworten mit hoher Bewertung und weniger an Antworten mit niedriger Bewertung liegen. Eine stabile Ausrichtung führt schließlich zum SFT-Verlust. Die Autoren diskutieren auch die Unterschiede zwischen stabiler Ausrichtung und SFT, RLHF.
Der Autor hebt aufgrund des Mechanismus besonders die Daten aus Sandbox-Spielen hervor Die Einstellung enthält eine große Menge an Daten, die überarbeitet wurden, um gesellschaftlichen Werten zu entsprechen. Der Autor beweist durch Ablationsexperimente, dass diese große Datenmenge mit schrittweiser Verbesserung der Schlüssel zu einem stabilen Training ist. 
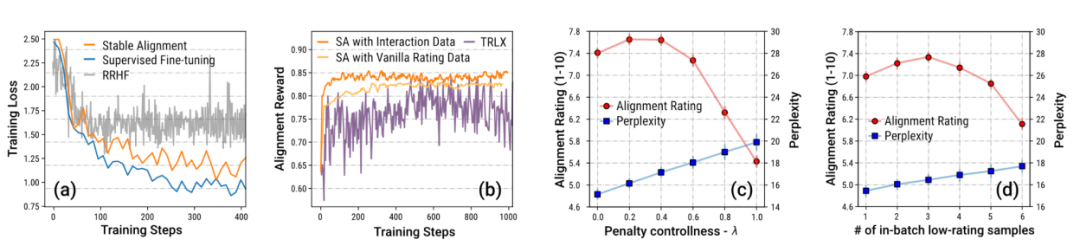
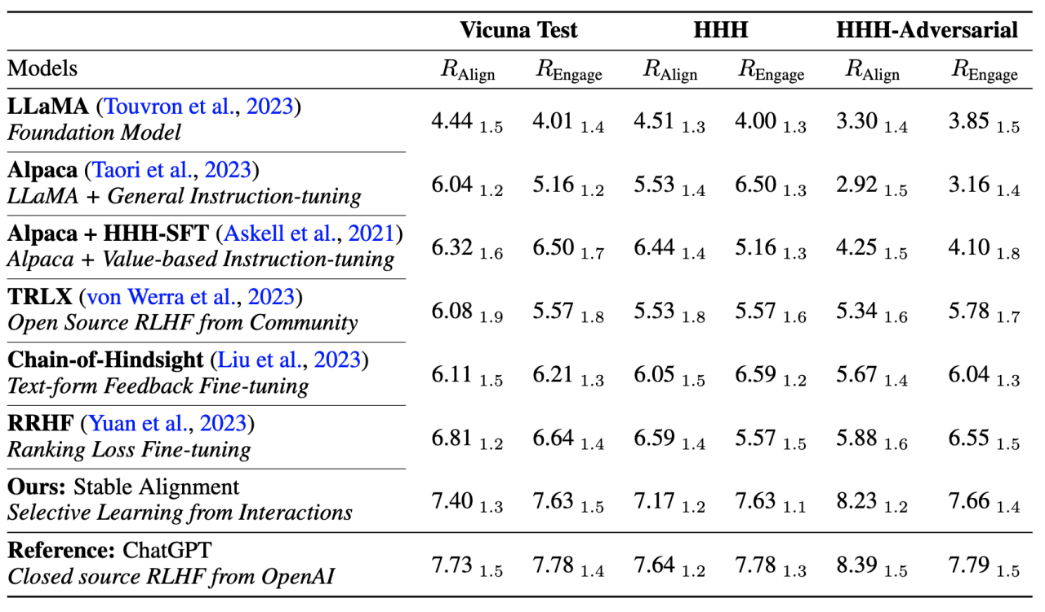
Der Autor verglich auch die Leistung und Trainingsstabilität der aktuellen Mainstream-Ausrichtungsalgorithmen und bewies, dass eine stabile Ausrichtung nicht nur stabiler ist als die Belohnungsmodellierung, sondern auch hinsichtlich der allgemeinen Leistung und Ausrichtungsleistung mit RLHF vergleichbar ist (dank ChatGPT). Verwendet unveröffentlichte Modelle, Daten und Algorithmen und dient daher nur als Referenz.
Ergebnis der Instanzgenerierung:
 #🎜 🎜#
#🎜 🎜#
Das obige ist der detaillierte Inhalt vonZehn Codezeilen sind mit RLHF vergleichbar und nutzen Social-Game-Daten, um ein Social-Alignment-Modell zu trainieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr