
Heim >Technologie-Peripheriegeräte >KI >Was kann NLP sonst noch tun? Die Beihang University, die ETH, die Hong Kong University of Science and Technology, die Chinese Academy of Sciences und andere Institutionen haben gemeinsam ein hundertseitiges Papier veröffentlicht, um die Post-ChatGPT-Technologiekette systematisch zu erklären
Was kann NLP sonst noch tun? Die Beihang University, die ETH, die Hong Kong University of Science and Technology, die Chinese Academy of Sciences und andere Institutionen haben gemeinsam ein hundertseitiges Papier veröffentlicht, um die Post-ChatGPT-Technologiekette systematisch zu erklären

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-05 18:10:181236Durchsuche
Alles beginnt mit der Entstehung von ChatGPT...
Die einst friedliche NLP-Community wurde von diesem plötzlichen „Monster“ erschreckt! Über Nacht hat der gesamte NLP-Kreis enorme Veränderungen durchgemacht, die Branche ist schnell gefolgt, das Kapital ist gestiegen, und die akademische Gemeinschaft geriet plötzlich in einen Zustand der Verwirrung ... Alle begannen langsam Ich glaube, dass „NLP gelöst ist!“ ist real geworden! Das Produkt nach systematischer und umfassender Recherche. Ein 110-seitiges Papier erläutert systematisch die Technologiekette in der Post-ChatGPT-Ära: Interaktion.
Papieradresse: https://arxiv.org/abs/2305.13246

Projektressourcen: https://github. com /InteractiveNLP-Team
- Anders als herkömmliche Interaktionsarten wie „Human in the Loop (HITL)“ und „Writing Assistant“ hat die in diesem Artikel besprochene Interaktion eine höhere und umfassendere Perspektive:
- Branche: Wenn große Modelle schwer zu lösende Probleme wie Sachlichkeit und Aktualität haben, kann ChatGPT+X diese lösen? Lassen Sie es, genau wie ChatGPT-Plugins, mit Tools interagieren, die uns dabei helfen, in einem Schritt Tickets zu buchen, Mahlzeiten zu bestellen und Bilder zu zeichnen! Mit anderen Worten: Wir können einige der Einschränkungen aktueller großer Modelle durch einige systematische technische Rahmenbedingungen mildern.
An die Wissenschaft: Was ist echte AGI? Tatsächlich beschrieb Yoshua Bengio, einer der drei Deep-Learning-Giganten und Gewinner des Turing Award, bereits 2020 einen Entwurf für ein interaktives Sprachmodell [1]: ein Sprachmodell, das mit der Umgebung und sogar sozial interagieren kann Nur so können wir die umfassendste semantische Darstellung der Sprache erreichen. Bis zu einem gewissen Grad entsteht durch die Interaktion mit der Umwelt und den Menschen die menschliche Intelligenz.
-
Daher kann die Interaktion von Sprachmodellen (LM) mit externen Entitäten und sich selbst nicht nur dazu beitragen, die inhärenten Mängel großer Modelle zu überbrücken, sondern kann auch ein wichtiger Meilenstein auf dem Weg zum ultimativen Ideal von AGI sein!
Was ist Interaktion? - Tatsächlich ist das Konzept der „Interaktion“ nicht das, was sich die Autoren vorgestellt haben. Seit der Einführung von ChatGPT wurden viele Artikel zu neuen Themen in der NLP-Welt veröffentlicht, wie zum Beispiel:
- Tool Learning with Foundation Models erklärt, wie man Sprachmodelle verwendet, um reale Operationen zu begründen oder durchzuführen [2];
- Foundation Models for Decision Making: Probleme, Methoden und Chancen erklärt, wie man Sprachmodelle zur Durchführung verwendet Entscheidungsaufgaben (Entscheidungsfindung)[3];
- ChatGPT für Robotik: Designprinzipien und Modellfähigkeiten erklärt, wie man ChatGPT verwendet, um Roboter zu stärken[4];
- Erweiterte Sprachmodelle: Eine Umfrage erklärt, wie das geht die Denkkette (Chain of Thought), den Werkzeuggebrauch (Tool-use) und andere erweiterte Sprachmodelle nutzen und darauf hinweisen, dass der Einsatz von Werkzeugen durch Sprachmodelle tatsächliche Auswirkungen auf die Außenwelt haben (d. h. handeln) kann [5] ;
- Funken künstlicher allgemeiner Intelligenz: Frühe Experimente mit GPT-4 veranschaulichen, wie GPT-4 zur Ausführung verschiedener Arten von Aufgaben verwendet werden kann, einschließlich Fällen der Interaktion mit Menschen, Umgebungen, Werkzeugen usw. [6].
Es ist ersichtlich, dass sich der Schwerpunkt der NLP-Akademikergemeinschaft allmählich von „Wie baut man ein Modell“ zu „Wie baut man ein Framework“ verlagert hat, was bedeutet, dass mehr Entitäten in den Prozess des Sprachmodelltrainings einbezogen werden müssen Argumentation. Das typischste Beispiel ist das bekannte Reinforcement Learning from Human Feedback (RLHF). Das Grundprinzip besteht darin, das Sprachmodell aus der Interaktion mit Menschen (Feedback) lernen zu lassen [7].
Man kann also sagen, dass die Funktion „Interaktion“ nach ChatGPT einer der gängigsten technischen Entwicklungspfade für NLP ist! Der Beitrag der Autoren definiert und dekonstruiert erstmals „interaktives NLP“ systematisch und diskutiert vor allem anhand der Dimension interaktiver Objekte möglichst umfassend die Vor- und Nachteile verschiedener technischer Lösungen und Anwendungsüberlegungen, darunter:

- LM interagiert mit Menschen, um Benutzerbedürfnisse besser zu verstehen und zu erfüllen, Antworten zu personalisieren, sich an menschlichen Werten auszurichten und das allgemeine Benutzererlebnis zu verbessern Wissenshintergrundrelevanz von Antworten und nutzt externe Informationen dynamisch, um genauere Antworten zu generieren;
- LM interagiert mit Modellen und Werkzeugen, um komplexe Argumentationsaufgaben effektiv zu zerlegen und zu lösen, wobei spezifisches Wissen genutzt wird, um spezifische Unteraufgaben zu bewältigen und die Entstehung zu fördern des sozialen Verhaltens von Agenten;
- LM interagiert mit der Umgebung, um die sprachbasierte Entitätsdarstellung zu erlernen (Spracherdung) und bewältigt effektiv spezifische Aufgaben im Zusammenhang mit der Umweltbeobachtung, wie z. B. verkörperte Aufgaben.
- Daher ist das Sprachmodell im Rahmen der Interaktion nicht mehr das Sprachmodell selbst, sondern ein Modell, das sprachbasierte Agenten „beobachten“, „handeln“ und „feedbacken“ kann.
Bei der Interaktion mit einem Objekt nennen die Autoren es „XXX-in-the-Loop“, was bedeutet, dass dieses Objekt am Prozess des Sprachmodelltrainings oder der Inferenz sowie an einer Kaskade, Schleife, Rückmeldung oder Teilnahme teilnimmt in iterativer Form.
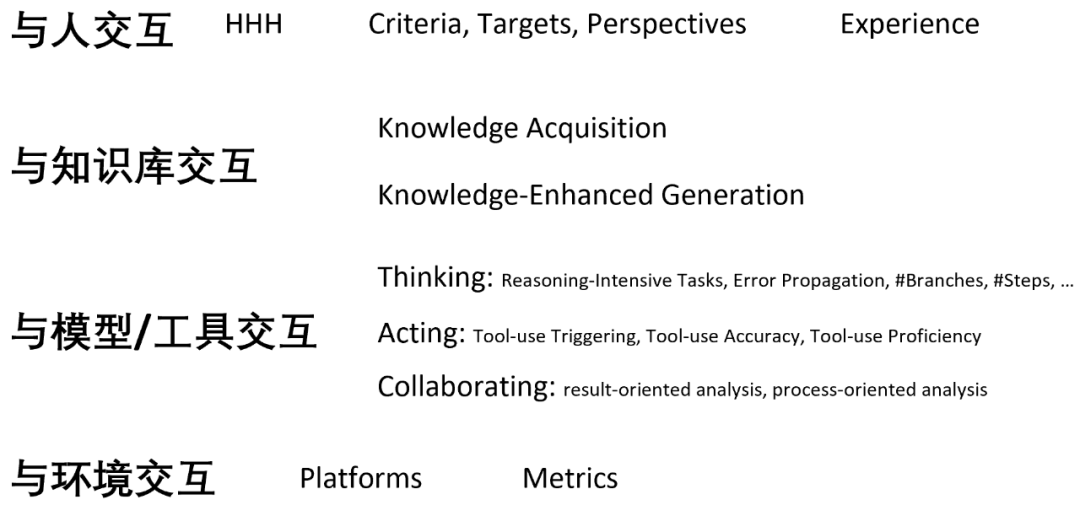
Mit Menschen interagieren
Es gibt drei Möglichkeiten, das Sprachmodell mit Menschen interagieren zu lassen: Verwenden Sie Aufforderungen zur Kommunikation e Feedback zum Lernen
- Mit Konfiguration anpassen
- Um eine skalierbare Bereitstellung sicherzustellen, werden außerdem häufig Modelle oder Programme verwendet, um menschliches Verhalten oder Vorlieben zu simulieren, also aus menschlichen Simulationen zu lernen.
- Im Allgemeinen ist das Kernproblem, das in der menschlichen Interaktion gelöst werden muss, die Ausrichtung, d. und kann Benutzern eine bessere Benutzererfahrung usw. ermöglichen.
„Mit Aufforderungen kommunizieren“ konzentriert sich hauptsächlich auf die Echtzeit- und Kontinuitätscharakteristik der Interaktion, das heißt, es betont den Kontinuitätscharakter mehrerer Dialogrunden. Dies steht im Einklang mit der Idee der Conversational AI [8]. Das heißt, der Benutzer kann in mehreren Dialogrunden weiterhin Fragen stellen, sodass sich die Antwort des Sprachmodells während des Dialogs langsam an die Präferenzen des Benutzers anpasst. Dieser Ansatz erfordert normalerweise keine Anpassung der Modellparameter während der Interaktion.
„Lernen mithilfe von Feedback“ ist derzeit die wichtigste Ausrichtungsmethode, die es Benutzern ermöglicht, Feedback zur Antwort des Sprachmodells zu geben. Dieses Feedback kann eine „Gut/Schlecht“-Anmerkung sein, die Präferenzen beschreibt, oder es kann natürlich sein Ausführlicheres Feedback in Sprachform. Das Modell muss trainiert werden, um diese Rückmeldungen so hoch wie möglich zu machen. Ein typisches Beispiel ist RLHF [7], das von InstructGPT verwendet wird. Es verwendet zunächst vom Benutzer beschriftete Präferenz-Feedback-Daten für Modellantworten, um ein Belohnungsmodell zu trainieren, und verwendet dieses Belohnungsmodell dann, um ein Sprachmodell mit einem bestimmten RL-Algorithmus zu trainieren, um die Belohnung zu maximieren (wie unten gezeigt) ).
Training von Sprachmodellen zur Befolgung von Anweisungen mit menschlichem Feedback [7]
„Mit Konfiguration anpassen“ ist eine spezielle interaktive Methode, die es Benutzern ermöglicht, die Superparameter des Sprachmodells (z. B B. Temperatur), oder die Kaskadenmethode von Sprachmodellen usw. Ein typisches Beispiel sind die KI-Ketten von Google [9]. Sprachmodelle mit verschiedenen voreingestellten Eingabeaufforderungen werden miteinander verbunden, um eine rationalisierte Aufgabenverarbeitung zu ermöglichen. Benutzer können die Knotenverbindungsmethode dieser Kette per Drag-and-Drop anpassen.
„Lernen aus menschlicher Simulation“ kann den groß angelegten Einsatz der oben genannten drei Methoden fördern, da der Einsatz realer Benutzer insbesondere im Trainingsprozess unrealistisch ist. Beispielsweise muss RLHF normalerweise ein Belohnungsmodell verwenden, um Benutzerpräferenzen zu simulieren. Ein weiteres Beispiel ist ITG [10] von Microsoft Research, das ein Oracle-Modell verwendet, um das Bearbeitungsverhalten von Benutzern zu simulieren.
Kürzlich haben Stanford-Professor Percy Liang und andere ein sehr systematisches Bewertungsschema für die Mensch-LM-Interaktion entwickelt: Evaluating Human-Language Model Interaction [11]. Interessierte Leser können sich auf dieses Papier oder den Originaltext beziehen. 🎞 Abruf
Wissen zur Verbesserung nutzen: Weitere Informationen finden Sie im Abschnitt „Interaction Message Fusion“. Ich werde es hier nicht vorstellen.
Im Allgemeinen kann die Interaktion mit der Wissensdatenbank das „Halluzinations“-Phänomen des Sprachmodells lindern, das heißt, die Faktizität und Genauigkeit seiner Ausgabe verbessern und auch dazu beitragen, die Aktualität des Sprachmodells zu verbessern. um die Wissensfähigkeiten des Sprachmodells zu ergänzen (wie unten gezeigt) usw.- MineDojo [16]: Wenn ein Sprachmodellagent auf eine Aufgabe stößt, die er nicht kennt, kann er in der Wissensdatenbank nach Lernmaterialien suchen und die Aufgabe dann mithilfe der Materialien abschließen .
- „Wissensquelle“ ist in zwei Typen unterteilt: Der eine ist geschlossenes Korpuswissen (Korpuswissen) wie WikiText usw. [15], der andere ist offenes Netzwerkwissen (Internetwissen) wie die Verwendung Suchwissen, das der Suchmaschine zur Verfügung steht [14].
„Knowledge Retrieval“ ist in vier Methoden unterteilt:
- Sprachbasierte spärliche Darstellung und spärlicher Abruf (sparse Retrieval) des lexikalischen Matchings: wie N-Gramm-Matching, BM25 usw.
- Dense Retrieval (Dense Retrieval) basierend auf sprachbasierter dichter Darstellung und semantischem Matching: z. B. Verwendung eines Single-Tower- oder Dual-Tower-Modells als Retriever usw.
- Basierend auf generativer Suche: Es handelt sich um eine relativ neue Methode. Das repräsentative Werk ist der Differentiable Search Index [12] von Google Tay Yi et al., der das Wissen in den Parametern des Sprachmodells speichert und direkt ausgibt nach Angabe der Dokument-ID oder des Dokumentinhalts, der dem Wissen entspricht. Denn das Sprachmodell ist die Wissensbasis.
- Basierend auf Reinforcement Learning: Es handelt sich ebenfalls um eine relativ hochmoderne Methode wie WebGPT von OpenAI [14], die menschliches Feedback nutzt, um das Modell so zu trainieren, dass es korrektes Wissen abruft.
Mit Modellen oder Werkzeugen interagieren
Der Hauptzweck der Interaktion von Sprachmodellen mit Modellen oder Werkzeugen besteht darin, komplexe Aufgaben zu zerlegen, beispielsweise komplexe Denkaufgaben in mehrere Unteraufgaben zu zerlegen, was ebenfalls eine Kette ist des Denkens [17]. Verschiedene Teilaufgaben können mithilfe von Modellen oder Werkzeugen mit unterschiedlichen Fähigkeiten gelöst werden. Beispielsweise können Rechenaufgaben mithilfe von Taschenrechnern und Retrieval-Aufgaben mithilfe von Retrieval-Modellen gelöst werden. Daher kann diese Art der Interaktion nicht nur die Argumentations-, Planungs- und Entscheidungsfähigkeiten des Sprachmodells verbessern, sondern auch die Einschränkungen des Sprachmodells wie „Halluzinationen“ und ungenaue Ausgaben lindern. Insbesondere wenn ein Tool zum Ausführen einer bestimmten Unteraufgabe verwendet wird, kann dies einen gewissen Einfluss auf die Außenwelt haben, z. B. die Verwendung der WeChat-API zum Posten eines Freundeskreises usw., was als „toolorientiert“ bezeichnet wird Lernen“ [ 2].
Darüber hinaus ist es manchmal schwierig, eine komplexe Aufgabe explizit zu zerlegen. In diesem Fall können Sie verschiedenen Sprachmodellen unterschiedliche Rollen oder Fähigkeiten zuweisen und diese Sprachmodelle dann miteinander zusammenarbeiten lassen . Während des Kommunikationsprozesses wird implizit und automatisch eine bestimmte Arbeitsteilung gebildet, um Aufgaben zu zerlegen. Diese Art der Interaktion kann nicht nur den Lösungsprozess komplexer Aufgaben vereinfachen, sondern auch die menschliche Gesellschaft simulieren und eine Art intelligente Agentengesellschaft aufbauen.
Die Autoren stellen Modelle und Tools zusammen, vor allem weil Modelle und Tools nicht unbedingt zwei separate Kategorien sind. Beispielsweise unterscheiden sich ein Suchmaschinen-Tool und ein Retriever-Modell nicht wesentlich. Diese Essenz wird von den Autoren definiert, indem sie „nach der Aufgabenzerlegung feststellen, welche Unteraufgaben von welchen Objekten ausgeführt werden“.
Wenn ein Sprachmodell mit einem Modell oder Werkzeug interagiert, gibt es drei Arten von Operationen:
- Denken: Das Modell interagiert mit sich selbst, um Aufgabenzerlegung und Argumentation durchzuführen;
- Handeln: Das Modell ruft auf andere Modelle oder externe Tools usw. helfen beim Denken oder haben tatsächliche Auswirkungen auf die Außenwelt.
- Zusammenarbeit: Mehrere Sprachmodellagenten kommunizieren und arbeiten miteinander zusammen, um bestimmte Aufgaben zu erledigen oder menschliches Sozialverhalten zu simulieren.
Hinweis: Beim Denken geht es hauptsächlich um die „mehrstufige Gedankenkette“, d. h. um unterschiedliche Argumentationsschritte, die unterschiedlichen Aufrufen des Sprachmodells entsprechen (mehrere Modellläufe), anstatt das Modell einmal auszuführen und Ausgabe von Gedanken + Antworten (einzelner Modelllauf) wie Vanilla CoT [17].
Dieser Teil erbt die Ausdrucksmethode von ReAct [18].
Zu den typischen Arbeiten zum Thema Denken gehören ReAct [18], Least-to-Most Prompting [19], Self-Ask [20] usw. Beispielsweise zerlegt Least-to-Most Prompting [19] zunächst ein komplexes Problem in mehrere einfache Modul-Unterprobleme und ruft dann iterativ das Sprachmodell auf, um sie einzeln zu lösen.
Typische Arbeiten zum Thema Schauspiel umfassen ReAct [18], HuggingGPT [21], Toolformer [22] usw. Toolformer [22] verarbeitet beispielsweise den vorab trainierten Korpus des Sprachmodells in ein Formular mit Eingabeaufforderung zur Werkzeugverwendung. Daher kann das trainierte Sprachmodell beim Generieren von Text automatisch die richtige Sprache aufrufen (z. B. Suchmaschinen, Übersetzungstools, Zeittools, Taschenrechner usw.) lösen bestimmte Teilprobleme.
Die Zusammenarbeit umfasst hauptsächlich:
- Interaktion mit geschlossenem Regelkreis: wie sokratische Modelle [23] usw., durch Interaktion mit geschlossenem Regelkreis zwischen großen Sprachmodellen, visuellen Sprachmodellen und Audio-Sprachmodellen bestimmte komplexe Qualitätssicherung, die speziell auf die Aufgabe der visuellen Umgebung zugeschnitten ist.
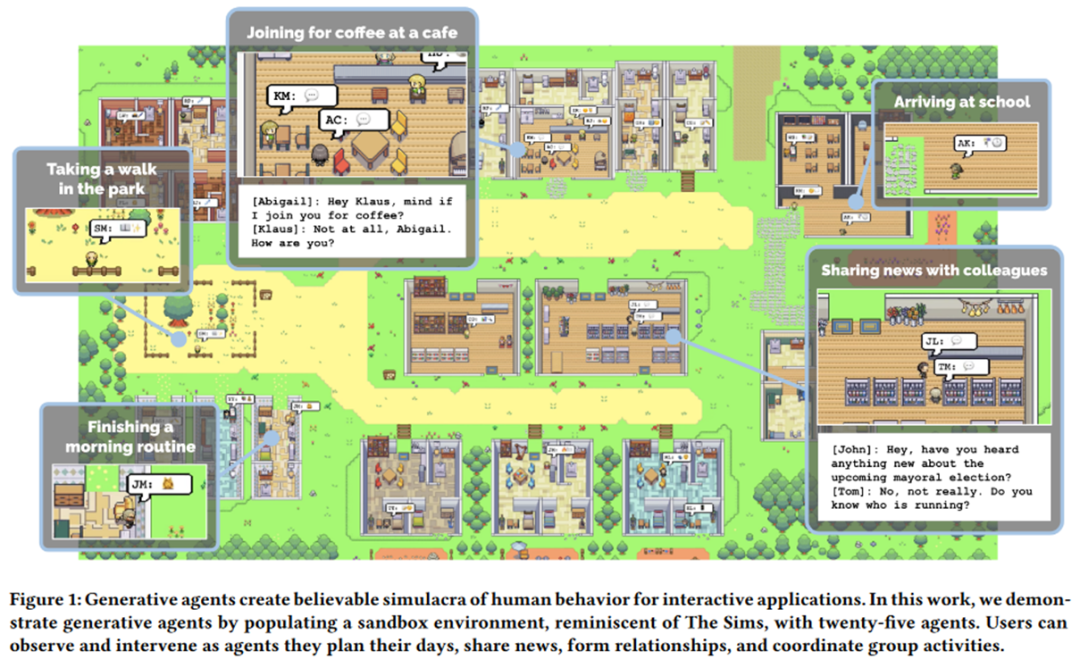
- Theory of Mind: Ziel ist es, einem Agenten zu ermöglichen, den Zustand eines anderen Agenten zu verstehen und vorherzusagen, um eine effiziente Interaktion untereinander zu fördern. Beispielsweise verleiht das Outstanding Paper von EMNLP 2021, MindCraft [24], zwei verschiedenen Sprachmodellen unterschiedliche, aber komplementäre Fähigkeiten, die es ihnen ermöglichen, während des Kommunikationsprozesses zusammenzuarbeiten, um bestimmte Aufgaben in der MineCraft-Welt zu erledigen. Der berühmte Professor Graham Neubig hat dieser Forschungsrichtung in letzter Zeit große Aufmerksamkeit gewidmet, beispielsweise [25]. Ziel ist es, mehreren Agenten die Kommunikation und Zusammenarbeit untereinander zu ermöglichen. Das typischste Beispiel sind Generative Agents [26] der Stanford University, die kürzlich die Welt schockierten: Durch den Aufbau einer Sandbox-Umgebung, in der sich viele intelligente Agenten, denen „Seelen“ aus großen Modellen injiziert wurden, darin frei bewegen können, können sie spontan etwas Menschenähnliches präsentieren Die sozialen Verhaltensweisen, wie z. B. Chatten und Hallo sagen, haben einen „westlichen“ Touch (wie unten gezeigt). Darüber hinaus ist das bekanntere Werk das neue Werk CAMEL [27] des Autors von DeepGCN, das es zwei durch große Modelle befähigten Agenten ermöglicht, Spiele zu entwickeln und dabei sogar Aktien zu kommunizieren, ohne dass allzu viel menschliches Eingreifen erforderlich ist . Intervention. Der Autor vertritt in dem Artikel deutlich das Konzept der „Large Model Society“ (LLM Society). ??
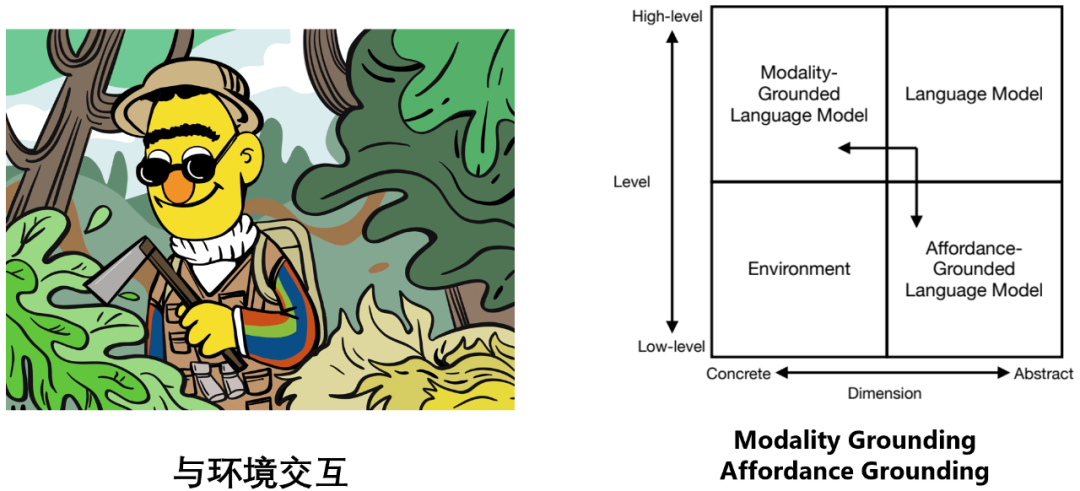
- Sprache Modell und Umgebung gehören zu zwei verschiedenen Quadranten: Das Sprachmodell basiert auf abstrakten Textsymbolen und eignet sich gut für logisches Denken, Planen, Entscheiden und andere Aufgaben, während die Umgebung auf spezifischen sensorischen Signalen (z. B. visuellen Informationen) basiert , auditive Informationen usw.), simulieren oder treten auf natürliche Weise einige Aufgaben auf niedriger Ebene auf, wie zum Beispiel die Bereitstellung von Beobachtung, Feedback, Zustandsübergängen usw. (Beispiel: Ein Apfel fällt in der realen Welt zu Boden, ein „Creeper“ erscheint in vor dir).
Um dem Sprachmodell eine effektive und effiziente Interaktion mit der Umgebung zu ermöglichen, umfasst es daher hauptsächlich zwei Aspekte der Bemühungen:
Modalitätserdung: Ermöglichen, dass das Sprachmodell multimodale Informationen wie Bilder und mehr verarbeitet Audio ;Affordance Grounding: Lassen Sie das Sprachmodell mögliche und angemessene Aktionen an möglichen und geeigneten Objekten im Maßstab der spezifischen Szene der Umgebung ausführen.
Das typischste für Modality Grounding ist das visuell-sprachliche Modell. Im Allgemeinen kann dies mit einem Einzelturmmodell wie OFA [28], einem Zweiturmmodell wie BridgeTower [29] oder der Interaktion von Sprachmodell und visuellem Modell wie BLIP-2 [30] durchgeführt werden. Auf weitere Details wird hier nicht näher eingegangen, Leser können für Einzelheiten auf dieses Dokument verweisen.
Es gibt zwei Hauptüberlegungen für Affordance Grounding, nämlich: wie (1) eine Wahrnehmung im Szenenmaßstab (Szenenmaßstabswahrnehmung) unter den Bedingungen einer bestimmten Aufgabe durchgeführt wird und (2) mögliche Aktionen (mögliche Aktion). Zum Beispiel:
In der obigen Szene müssen wir beispielsweise für die gegebene Aufgabe „Bitte schalten Sie das Licht im Wohnzimmer aus“ und „Wahrnehmung des Szenenmaßstabs“ alle Lichter mit roten Kästchen finden Auswahl der Lichter, die sich nicht im Wohnzimmer, sondern in der Küche befinden. Für die grün eingekreisten Lichter müssen wir bei den „möglichen Aktionen“ die möglichen Möglichkeiten zum Ausschalten der Lichter ermitteln „Aktion, und das Ein- und Ausschalten des Lichts erfordert eine „Kippschalter“-Aktion.
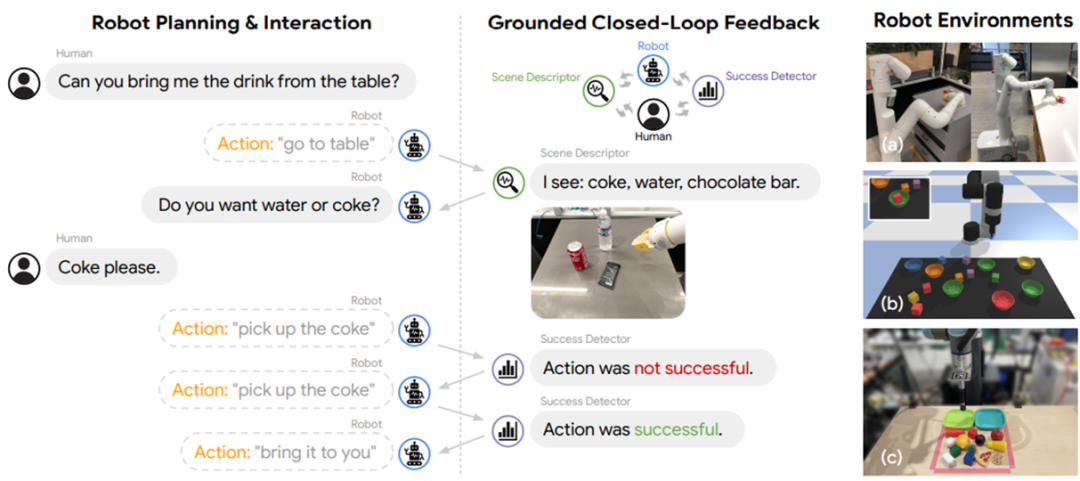
Im Allgemeinen kann Affordance Grounding mithilfe einer von der Umgebung abhängigen Wertfunktion wie SayCan [31] usw. oder eines speziellen Erdungsmodells wie gelöst werden als Grounded kann Decoding [32] usw. verwendet werden. Es kann sogar durch die Interaktion mit Menschen, Modellen, Werkzeugen usw. gelöst werden (wie unten gezeigt).
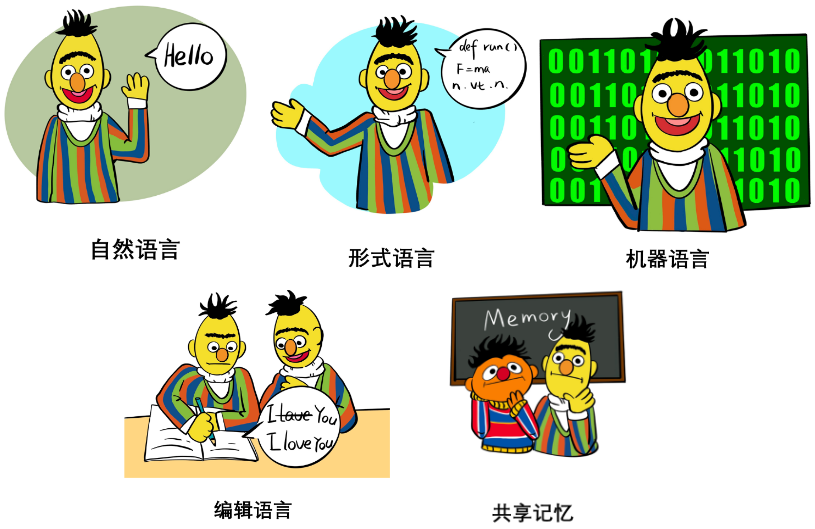
Innerer Monolog [33]# Was für die Interaktion verwendet werden sollte: Interaktive Schnittstelle Im Kapitel „Interaktionsschnittstelle“ des Papiers diskutierten die Autoren systematisch die Verwendung sowie die Vor- und Nachteile verschiedener Interaktionssprachen und Interaktionsmedien, darunter:
#🎜🎜 #Natürliche Sprache: wie z. B. wenige Beispiele, Aufgabenanweisungen, Rollenzuweisung oder sogar strukturierte natürliche Sprache usw. Seine Eigenschaften und Funktionen in der Generalisierung und Expressivität werden hauptsächlich diskutiert.
Formale Sprache: wie Code, Grammatik, mathematische Formeln usw. Seine Eigenschaften und Funktionen in Bezug auf Parsbarkeit und Argumentationsfähigkeit werden hauptsächlich diskutiert.Maschinensprache: wie Soft-Prompts, diskretisierte visuelle Token usw. Seine Eigenschaften und Funktionen in der Generalisierung, Informationsengpasstheorie, Interaktionseffizienz usw. werden hauptsächlich diskutiert.
- Bearbeiten: Es umfasst hauptsächlich Vorgänge wie Löschen, Einfügen, Ersetzen und Beibehalten von Text. Seine Prinzipien, Geschichte, Vorteile und aktuellen Einschränkungen werden diskutiert.
- Gemeinsamer Speicher: Der erstere zeichnet den historischen Status in einem Protokoll als Speicher auf, und der letztere verwendet einen lesbaren und beschreibbaren Speicher Module speichern Tensoren. Der Artikel erörtert die Eigenschaften, Funktionen und Grenzen der beiden.
- Interaktion: Interaktionsmethode
- 🎜🎜#In dem Artikel werden außerdem verschiedene Interaktionsmethoden umfassend, detailliert und systematisch erörtert, darunter hauptsächlich:
- Prompting: Keine Anpassung der Modellparameter, nur Aufruf des Sprachmodells durch Prompt Engineering, das In-Context-Lernen, Gedankenkette und Werkzeuge abdeckt. Verwendung von Prompts (Tool-Nutzung), Kaskade Argumentationsverkettung (Prompt Chaining) und andere Methoden werden die Prinzipien, Funktionen, verschiedenen Tricks und Einschränkungen verschiedener Eingabeaufforderungstechniken ausführlich besprochen, wie z. B. Überlegungen zur Steuerbarkeit und Robustheit.
- Feinabstimmung: Passen Sie die Modellparameter an, damit das Modell aus interaktiven Informationen lernen und sich aktualisieren kann. In diesem Abschnitt werden Methoden wie Supervised Instruction Tuning, Parameter-Efficient Fine-Tuning, Continual Learning und Semi-Supervised Fine-Tuning behandelt. Die Prinzipien, Funktionen, Vorteile, Überlegungen bei der spezifischen Verwendung und Einschränkungen dieser Methoden werden ausführlich besprochen. Es umfasst auch einen Teil der Wissensbearbeitung (dh die Bearbeitung von Wissen innerhalb des Modells).
- Aktives Lernen: Interaktives Algorithmus-Framework für aktives Lernen.
- Reinforcement Learning: Interaktives Framework für Verstärkungslernalgorithmen, diskutiert Online-Framework für Verstärkungslernen, Offline-Framework für Verstärkungslernen, Lernen aus menschlichem Feedback (RLHF) und Umgebung. Es gibt viele Methoden wie Lernen aus Feedback (RLEF) und Lernen aus KI-Feedback (RLAIF).
- Nachahmungslernen: Ein interaktives Nachahmungslernalgorithmus-Framework, in dem Online-Nachahmungslernen, Offline-Nachahmungslernen usw. diskutiert werden.
- Interaktionsnachrichtenfusion: Bietet einen einheitlichen Rahmen für alle oben genannten Interaktionsmethoden. Gleichzeitig wird er in diesem Rahmen nach außen erweitert, um unterschiedliche Wissens- und Informationsfusionen zu diskutieren . Schemata wie Cross-Attention-Fusion-Schema (Cross-Attention-Fusion-Schema), Constrained-Decoding-Fusion-Schema (Constrained-Decoding) usw.
Andere Diskussionen
Aus Platzgründen werden in diesem Artikel keine ausführlichen Diskussionen zu anderen Aspekten wie der Bewertung vorgestellt , Anwendung, Ethik, Sicherheit und zukünftige Entwicklungsrichtungen usw. Allerdings nehmen diese Inhalte im Originaltext der Arbeit immer noch 15 Seiten ein, daher wird den Lesern empfohlen, weitere Details im Originaltext anzusehen. Im Folgenden finden Sie eine Übersicht über diese Inhalte:
#🎜🎜 # Kommentare zur Interaktion
Die Bewertung in Das Papier Die Diskussion umfasst hauptsächlich die folgenden Schlüsselwörter:
Hauptanwendungen von Interactive NLP# 🎜🎜#
- Kontrollierbare Textgenerierung(Kontrollierbare Textgenerierung)
- # 🎜 🎜#Interaktion mit Menschen: RLHFs ideologisches Stempelphänomen usw.
- Interaktion mit Wissen: Wissensbewusste Feinabstimmung [34 ] usw.
- Interaktion mit Modellen und Werkzeugen: Klassifikatorgesteuertes CTG usw.
- Interaktion mit die Umgebung: Affordance Grounding usw ) #🎜 🎜#
- Inhaltsunterstützung: Art der Inhaltsunterstützung
Inhaltsprüfung und -politur: Art der Inhaltsprüfung und -politur# ?? ## 🎜🎜##🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#verkörperte Ai#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Beobachtung und Manipulation : Basic
- Navigation und Erkundung: Fortgeschritten (z. B. verkörperte Aufgaben mit langem Horizont)
- Multi - Rollenaufgaben: Fortgeschritten
- Spiel (Textspiel)
- Interaktive Spielplattform mit Text: Interaktive Textspielplattformen# Text abspielen -Nur Spiele Empowering-Spiele mit Textmedien: Powering Text-Aided Games
- Andere Anwendungen
- Felder, Aufgaben Spezialisierung: Zum Beispiel, wie man auf der Grundlage von Interaktion ein Sprachmodell-Framework speziell für den Finanzbereich, den medizinischen Bereich usw. erstellt.
- Personalisierung & Persönlichkeit: Zum Beispiel, wie man ein Sprachmodell speziell für den Benutzer oder mit einer bestimmten Persönlichkeit basierend auf Interaktion erstellt.
- Modellbasierte Evaluation
- Ethik und security
diskutiert die Auswirkungen interaktiver Sprachmodelle auf Bildung und geht auch auf soziale Vorurteile, Privatsphäre usw. ein. Ethische Sicherheitsfragen werden diskutiert .
Zukünftige Entwicklungsrichtung und Herausforderungen
# 🎜🎜#Ausrichtung: Das Ausrichtungsproblem von Sprachmodellen, wie kann die Ausgabe des Modells harmloser, konsistenter mit menschlichen Werten, vernünftiger usw. gestaltet werden? Soziale Verkörperung: Erdungsproblem des Sprachmodells, wie kann die Verkörperung und Sozialisierung des Sprachmodells weiter gefördert werden?
- Plastizität: Das Plastizitätsproblem von Sprachmodellen, wie man die kontinuierliche Aktualisierung des Modellwissens sicherstellt und das zuvor erworbene Wissen während des Aktualisierungsprozesses nicht vergisst.
- Geschwindigkeit und Effizienz: Themen wie die Inferenzgeschwindigkeit und Trainingseffizienz von Sprachmodellen, wie man die Inferenz beschleunigt, ohne die Leistung zu beeinträchtigen, und die Effizienz des beschleunigten Trainings.
- Kontextlänge: Die Kontextfenstergrößenbeschränkung des Sprachmodells. So erweitern Sie die Fenstergröße des Kontexts, damit längerer Text verarbeitet werden kann.
- Langtextgenerierung: Problem der Langtextgenerierung des Sprachmodells. So sorgen Sie dafür, dass das Sprachmodell in extrem langen Textgenerierungsszenarien eine hervorragende Leistung beibehält.
- Barrierefreiheit: Verfügbarkeitsproblem des Sprachmodells. Wie man Sprachmodelle von Closed Source zu Open Source macht und wie man die Bereitstellung von Sprachmodellen auf Edge-Geräten wie Fahrzeugsystemen und Laptops ohne übermäßige Leistungseinbußen ermöglicht.
- Analyse: Sprachmodellanalyse, Interpretierbarkeit und andere Probleme. Zum Beispiel, wie man die Leistung des Modells nach der Skalierung vorhersagt, um die Entwicklung großer Modelle zu leiten, wie man den internen Mechanismus großer Modelle erklärt usw.
- Kreativität: Kreative Probleme mit Sprachmodellen. Wie man Sprachmodelle kreativer macht, Metaphern, Metaphern usw. besser nutzen und neues Wissen schaffen kann usw.
- Bewertung: Wie man allgemeine große Modelle besser bewertet, wie man die interaktiven Eigenschaften von Sprachmodellen bewertet usw.

 Es gibt drei Möglichkeiten, das Sprachmodell mit Menschen interagieren zu lassen:
Es gibt drei Möglichkeiten, das Sprachmodell mit Menschen interagieren zu lassen: 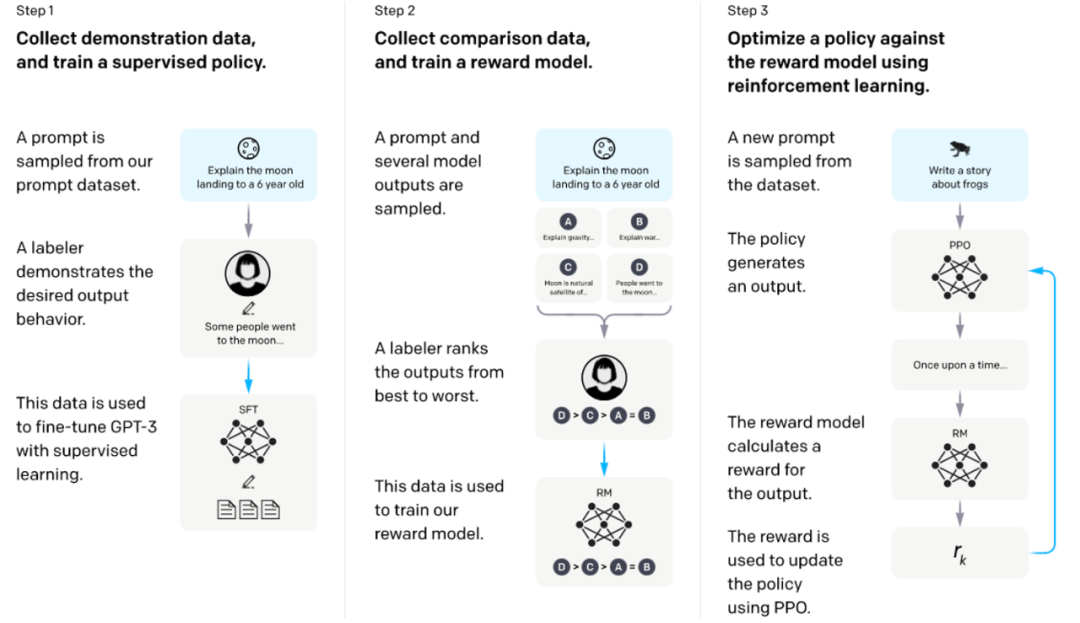


Das obige ist der detaillierte Inhalt vonWas kann NLP sonst noch tun? Die Beihang University, die ETH, die Hong Kong University of Science and Technology, die Chinese Academy of Sciences und andere Institutionen haben gemeinsam ein hundertseitiges Papier veröffentlicht, um die Post-ChatGPT-Technologiekette systematisch zu erklären. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr