
Heim >Technologie-Peripheriegeräte >KI >Neue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt
Neue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt

- 王林nach vorne
- 2023-06-05 14:17:471437Durchsuche
Neurale Strahlungsfelder (NeRF) sind zu einer beliebten neuen Methode zur Synthese von Sichtweisen geworden. Obwohl sich NeRF schnell auf ein breiteres Spektrum von Anwendungen und Datensätzen verallgemeinert, bleibt die direkte Bearbeitung von NeRF-Modellierungsszenarien eine große Herausforderung. Eine wichtige Aufgabe besteht darin, unerwünschte Objekte aus einer 3D-Szene zu entfernen und die Konsistenz mit der umgebenden Szene aufrechtzuerhalten. Diese Aufgabe wird als 3D-Bild-Inpainting bezeichnet. In 3D müssen Lösungen über mehrere Ansichten hinweg konsistent und geometrisch gültig sein.
In diesem Artikel schlagen Forscher von Samsung, der University of Toronto und anderen Institutionen eine neue 3D-Inpainting-Methode vor, um diese Herausforderungen zu lösen. Zunächst wird ein kleiner Satz von Posenbildern und spärliche Anmerkungen in einem einzelnen Eingabebild vorgeschlagen Erhalten Sie schnell die dreidimensionale Segmentierungsmaske des Zielobjekts, verwenden Sie die Maske und führen Sie dann eine auf Wahrnehmungsoptimierung basierende Methode ein, die die gelernten zweidimensionalen Bilder verwendet, um sie zu reparieren, ihre Informationen in den dreidimensionalen Raum zu extrahieren und gleichzeitig sicherzustellen die Ansichtskonsistenz.
Diese Studie bringt auch einen neuen Maßstab für die Bewertung von 3D-In-Scene-Inpainting-Methoden durch das Training eines anspruchsvollen realen Szenendatensatzes. Insbesondere enthält dieser Datensatz Ansichten derselben Szene mit und ohne Zielobjekte, was ein prinzipielleres Benchmarking von Inpainting-Aufgaben im 3D-Raum ermöglicht.

- Papieradresse: https://arxiv.org/pdf/2211.12254.pdf
- Papierhomepage: https://spinnerf3d.github.io/.
Das Folgende ist eine Demonstration des Effekts, der immer noch mit der umgebenden Szene übereinstimmt:

Vergleich zwischen dieser Methode und anderen Methoden, während diese Methode offensichtliche Artefakte aufweist Nicht so offensichtlich:

Einführung in die Methode
Der Autor befasst sich mit verschiedenen Herausforderungen bei 3D-Szenenbearbeitungsaufgaben durch einen integrierten Ansatz, der Mehransichtsbilder der Szene erhält und 3D-Bilder mit Benutzereingabemaske extrahiert und anpasst Das Maskenbild wird mithilfe von NeRF trainiert, sodass das Zielobjekt durch ein angemessenes dreidimensionales Erscheinungsbild und eine angemessene Geometrie ersetzt wird. Bestehende interaktive 2D-Segmentierungsmethoden berücksichtigen den 3D-Aspekt nicht, und aktuelle NeRF-basierte Methoden können mit spärlichen Annotationen keine guten Ergebnisse erzielen und erreichen keine ausreichende Genauigkeit. Während einige aktuelle NeRF-basierte Algorithmen das Entfernen von Objekten ermöglichen, versuchen sie nicht, neu generierte Raumteile bereitzustellen. Dem aktuellen Forschungsfortschritt zufolge ist diese Arbeit die erste, die gleichzeitig die interaktive Multi-View-Segmentierung und die vollständige 3D-Bildwiederherstellung in einem einzigen Framework abwickelt.
Forscher nutzen handelsübliche, 3D-freie Modelle zur Segmentierung und Bildwiederherstellung und übertragen ihre Ergebnisse auf ansichtskonsistente Weise in den 3D-Raum. Aufbauend auf Arbeiten zur interaktiven 2D-Segmentierung beginnt das von den Autoren vorgeschlagene Modell mit einer kleinen Anzahl von durch den Benutzer mit der Maus kalibrierten Bildpunkten auf einem Zielobjekt. Daraufhin initialisiert ihr Algorithmus die Maske mit einem videobasierten Modell und trainiert sie in eine kohärente 3D-Segmentierung, indem er den NeRF einer semantischen Maske anpasst. Anschließend wird die vorab trainierte 2D-Bildwiederherstellung auf den Multi-View-Bildsatz angewendet. Der NeRF-Anpassungsprozess wird verwendet, um die 3D-Bildszene zu rekonstruieren, wobei Wahrnehmungsverlust verwendet wird, um die Inkonsistenz des 2D-Bilds und der Geometrie des Normalisierten einzuschränken Maske des Tiefenbildes. Insgesamt bieten wir einen vollständigen Ansatz, von der Objektauswahl bis zur neuen Ansichtssynthese eingebetteter Szenen, in einem einheitlichen Framework mit minimaler Belastung für den Benutzer, wie in der folgenden Abbildung dargestellt. 
Zusammenfassend sind die Beiträge dieser Arbeit wie folgt:
- Ein vollständiger 3D-Szenenbetriebsprozess, beginnend mit der Objektauswahl der Benutzerinteraktion und endend mit der 3D-reparierten NeRF-Szene; 🎜#Erweitern Sie das zweidimensionale Segmentierungsmodell auf Situationen mit mehreren Ansichten und stellen Sie dreidimensionale konsistente Masken aus spärlichen Anmerkungen wieder her Rationality, eine neue optimierungsbasierte 3D-Inpainting-Formulierung, die 2D-Bild-Inpainting nutzt;
- In der Studie wird zunächst insbesondere beschrieben, wie eine grobe 3D-Maske aus Einzelansichtsanmerkungen initialisiert wird. Bezeichnen Sie die kommentierte Quellcodeansicht als I_1. Geben Sie spärliche Informationen über Objekte und Quellansichten an ein interaktives Segmentierungsmodell weiter, um die anfängliche Quellobjektmaske
- zu schätzen. Die Trainingsansichten werden dann als Videosequenz behandelt, zusammen mit
- mit einem Videoinstanzsegmentierungsmodell V, um zu berechnen, wobei #🎜 🎜#
ist die erste Schätzung der Objektmaske von I_i. Die anfänglichen Masken sind in der Nähe von Grenzen häufig ungenau, da es sich bei den Trainingsansichten nicht um tatsächlich benachbarte Videobilder handelt und Videosegmentierungsmodelle häufig 3D-unbekannt sind. 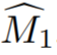
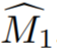
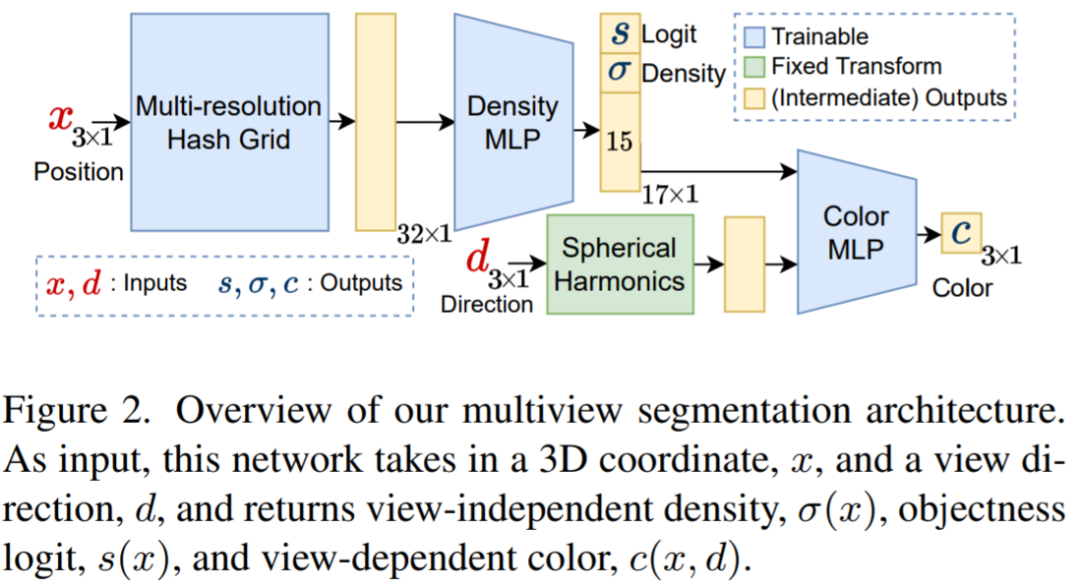
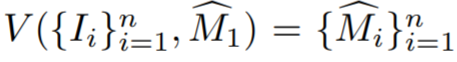 Das Multi-View-Segmentierungsmodul erhält das eingegebene RGB-Bild und das entsprechende Kamera-intrinsische und externe Parameter sowie anfängliche Masken zum Trainieren eines semantischen NeRF. Das obige Diagramm zeigt das im semantischen NeRF verwendete Netzwerk für einen Punkt x und ein Ansichtsverzeichnis d. Zusätzlich zur Dichte σ und der Farbe c gibt es einen Präsigmoid-Objekt-Logit s (x) zurück. Für die schnelle Konvergenz verwendeten die Forscher Instant-NGP als NeRF-Architektur. Die mit einem Strahl r verbundene gewünschte Objektivität erhält man, indem man in der Gleichung den Logarithmus der Punkte auf r und nicht ihre Farbe relativ zur Dichte darstellt: #
Das Multi-View-Segmentierungsmodul erhält das eingegebene RGB-Bild und das entsprechende Kamera-intrinsische und externe Parameter sowie anfängliche Masken zum Trainieren eines semantischen NeRF. Das obige Diagramm zeigt das im semantischen NeRF verwendete Netzwerk für einen Punkt x und ein Ansichtsverzeichnis d. Zusätzlich zur Dichte σ und der Farbe c gibt es einen Präsigmoid-Objekt-Logit s (x) zurück. Für die schnelle Konvergenz verwendeten die Forscher Instant-NGP als NeRF-Architektur. Die mit einem Strahl r verbundene gewünschte Objektivität erhält man, indem man in der Gleichung den Logarithmus der Punkte auf r und nicht ihre Farbe relativ zur Dichte darstellt: #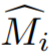 #🎜 🎜# Dann verwenden Sie den Klassifizierungsverlust zur Überwachung:
#🎜 🎜# Dann verwenden Sie den Klassifizierungsverlust zur Überwachung:
 #🎜 🎜#
#🎜 🎜#
Der verwendete Gesamtverlust Um das NeRF-basierte Multi-View-Segmentierungsmodell zu überwachen, lautet:
# 🎜🎜#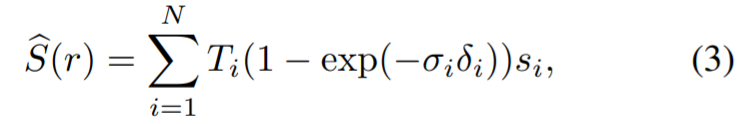
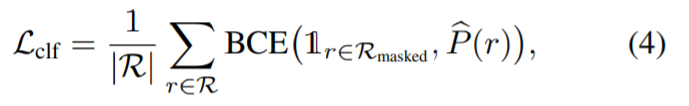 Das Bild oben zeigt eine Übersicht über die ansichtskonsistente Korrekturmethode. Da der Mangel an Daten ein direktes Training von 3D-modifizierten Inpainting-Modellen verhindert, nutzt diese Studie vorhandene 2D-Inpainting-Modelle, um Tiefen- und Erscheinungsbildprioritäten zu erhalten, und überwacht dann die Anpassung des NeRF-Renderings an die gesamte Szene. Dieses eingebettete NeRF wird mit dem folgenden Verlust trainiert:
Das Bild oben zeigt eine Übersicht über die ansichtskonsistente Korrekturmethode. Da der Mangel an Daten ein direktes Training von 3D-modifizierten Inpainting-Modellen verhindert, nutzt diese Studie vorhandene 2D-Inpainting-Modelle, um Tiefen- und Erscheinungsbildprioritäten zu erhalten, und überwacht dann die Anpassung des NeRF-Renderings an die gesamte Szene. Dieses eingebettete NeRF wird mit dem folgenden Verlust trainiert:
Diese Studie schlägt eine ansichtskonsistente Inpainting-Methode mit RGB-Eingabe vor. Zunächst überträgt die Studie Bild- und Maskenpaare an einen Image-Inpainter, um ein RGB-Bild zu erhalten. Da jede Ansicht unabhängig repariert wird, werden die reparierten Ansichten direkt zur Überwachung der Rekonstruktion von NeRF verwendet. Anstatt den mittleren quadratischen Fehler (MSE) als Verlust zum Generieren von Masken zu verwenden, schlagen die Forscher in diesem Artikel vor, den Wahrnehmungsverlust LPIPS zu verwenden, um den maskierten Teil des Bildes zu optimieren, während MSE weiterhin zur Optimierung des unmaskierten Teils verwendet wird. Dieser Verlust wird wie folgt berechnet:
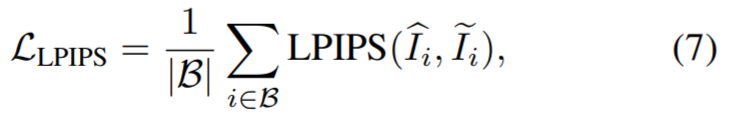
Reparieren Sie auch bei wahrgenommenem Verlust den Unterschiede zwischen ihnen können auch fälschlicherweise dazu führen, dass das Modell zu einer Geometrie mit geringerer Qualität konvergiert (z. B. können sich in der Nähe der Kamera „verschwommene“ Geometriemessungen bilden, um unterschiedliche Informationen aus jeder Ansicht zu berücksichtigen). Daher verwendeten die Forscher die generierte Tiefenkarte als zusätzliche Orientierungshilfe für das NeRF-Modell und trennten die Gewichte bei der Berechnung des Wahrnehmungsverlusts, wobei sie den Wahrnehmungsverlust nur zur Anpassung an die Farbe der Szene verwendeten. Zu diesem Zweck haben wir ein NeRF verwendet, das für Bilder mit unerwünschten Objekten optimiert ist, und gerenderte Tiefenkarten, die den Trainingsansichten entsprechen. Die Berechnungsmethode besteht darin, den Abstand zur Kamera anstelle der Farbe des Punktes zu verwenden:
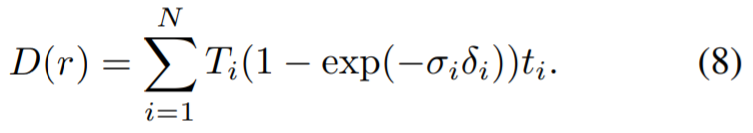
Dann wird die gerenderte Tiefe in das Fixer-Modell eingegeben, um die reparierte Tiefenkarte zu erhalten. Untersuchungen haben ergeben, dass die Verwendung von LaMa für Tiefenrendering, beispielsweise RGB, ausreichend hochwertige Ergebnisse liefern kann. Bei diesem NeRF kann es sich um dasselbe Modell handeln, das für die Segmentierung mit mehreren Ansichten verwendet wird. Wenn andere Quellen zum Erhalten der Masken verwendet werden, z. B. von Menschen kommentierte Masken, wird ein neues NeRF in der Szene installiert. Diese Tiefenkarten werden dann verwendet, um die Geometrie des eingefärbten NeRF zu überwachen, über das die gerenderte Tiefe dann in das Inpainter-Modell eingespeist wird, um die eingefärbte Tiefenkarte zu erhalten. Untersuchungen haben ergeben, dass die Verwendung von LaMa für Tiefenrendering, beispielsweise RGB, ausreichend hochwertige Ergebnisse liefern kann. Bei diesem NeRF kann es sich um dasselbe Modell handeln, das für die Segmentierung mit mehreren Ansichten verwendet wird. Wenn andere Quellen zum Erhalten der Masken verwendet werden, z. B. von Menschen kommentierte Masken, wird ein neues NeRF in der Szene installiert. Diese Tiefenkarten werden dann verwendet, um die Geometrie des eingefärbten NeRF zu überwachen, indem die Tiefe von der eingefärbten Tiefe zur eingefärbten Tiefe gerendert wird.  #🎜🎜 #
#🎜🎜 #
#🎜 🎜#
Multi-View-Segmentierung: Bewerten Sie zunächst das MVSeg-Modell ohne Bearbeitungskorrekturen. In diesem Experiment wird davon ausgegangen, dass spärlich besetzte Bildpunkte ein vorgefertigtes interaktives Segmentierungsmodell erhalten haben und Quellmasken verfügbar sind. Die Aufgabe besteht also darin, die Quellmaske in andere Ansichten zu übertragen. Die folgende Tabelle zeigt, dass das neue Modell die 2D- (3D-inkonsistent) und 3D-Basislinien übertrifft. Darüber hinaus trägt die von den Forschern vorgeschlagene zweistufige Optimierung dazu bei, die resultierende Maske weiter zu verbessern.
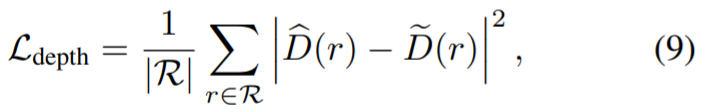
Zur qualitativen Analyse vergleicht die folgende Abbildung die Ergebnisse des Forschersegmentierungsmodells mit NVOS und Die Ergebnisse verschiedener Videosegmentierungsmethoden werden verglichen. Ihr Modell reduziert Rauschen und verbessert die Ansichtskonsistenz im Vergleich zu den dicken Kanten von 3D-Videosegmentierungsmodellen. Obwohl NVOS Scribbles anstelle der im neuen Modell der Forscher verwendeten spärlichen Punkte verwendet, ist das MVSeg des neuen Modells NVOS optisch überlegen. Da die NVOS-Codebasis nicht verfügbar ist, replizierten die Forscher veröffentlichte qualitative Ergebnisse zu NVOS (weitere Beispiele finden Sie im Zusatzdokument).
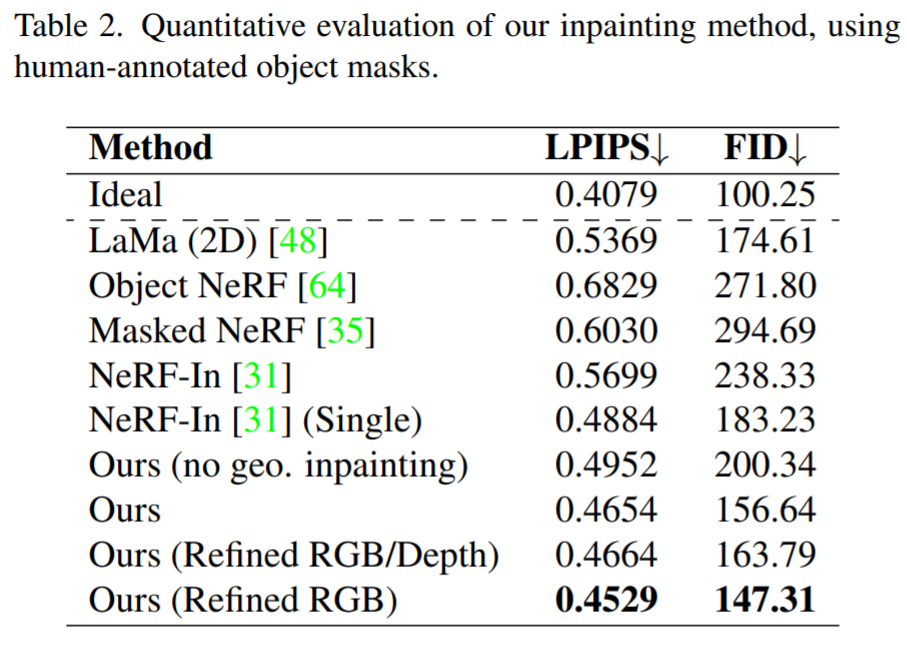
Die folgende Tabelle zeigt den Vergleich der MV-Methode mit der Basislinie. Insgesamt übertrifft die neu vorgeschlagene Methode andere 2D- und 3D-Reparaturmethoden deutlich. Die folgende Tabelle zeigt außerdem, dass das Entfernen der Führung aus geometrischen Strukturen die Qualität der reparierten Szene beeinträchtigt. Die qualitativen Ergebnisse sind in Abbildung 6 und Abbildung 7 dargestellt. Abbildung 6 zeigt, dass unsere Methode ansichtskonsistente Szenen mit detaillierten Texturen rekonstruieren kann, einschließlich kohärenter Ansichten von glänzenden und matten Oberflächen. Abbildung 7 zeigt, dass unser wahrnehmungsbezogener Ansatz die Einschränkungen bei der genauen Rekonstruktion von Maskenbereichen verringert und dadurch das Auftreten von Unschärfe bei Verwendung aller Bilder verhindert und gleichzeitig Artefakte vermeidet, die durch die Einzelansichtsüberwachung verursacht werden.
# 🎜 🎜#

Das obige ist der detaillierte Inhalt vonNeue Forschungsergebnisse von NeRF sind da: 3D-Szenen werden ohne Objekte spurlos und haargenau entfernt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr