
Heim >Technologie-Peripheriegeräte >KI >Das chinesische Wissenschaftsteam startet die „Thinking Chain Collection', um die komplexe Denkfähigkeit großer Modelle umfassend zu bewerten
Das chinesische Wissenschaftsteam startet die „Thinking Chain Collection', um die komplexe Denkfähigkeit großer Modelle umfassend zu bewerten

- 王林nach vorne
- 2023-06-05 13:22:29872Durchsuche
Große Modellfähigkeiten entstehen. Je größer der Parameterumfang, desto besser?
Allerdings behaupten immer mehr Forscher, dass auch Modelle kleiner als 10B eine vergleichbare Leistung wie GPT-3.5 erreichen können.
Ist das wirklich so?
Im Blog von OpenAI, der GPT-4 veröffentlicht, wurde Folgendes erwähnt:
In lockeren Gesprächen kann der Unterschied zwischen GPT-3.5 und GPT-4 sehr subtil sein. Unterschiede treten auf, wenn die Komplexität der Aufgabe einen ausreichenden Schwellenwert erreicht – GPT-4 ist zuverlässiger, kreativer und in der Lage, differenziertere Anweisungen zu verarbeiten als GPT-3.5.
Google-Entwickler machten auch ähnliche Beobachtungen zum PaLM-Modell. Sie stellten fest, dass die Denkketten-Fähigkeit des großen Modells deutlich stärker war als die des kleinen Modells.
Diese Beobachtungen zeigen alle, dass die Fähigkeit, komplexe Aufgaben auszuführen, der Schlüssel zur Verkörperung der Fähigkeiten großer Modelle ist.
Genau wie das alte Sprichwort gilt auch für Models und Programmierer: „Hör auf, Unsinn zu reden, zeig mir die Gründe.“

Forscher der University of Edinburgh, der University of Washington und des Allen AI Institute glauben, dass komplexe Denkfähigkeiten die Grundlage für die Weiterentwicklung großer Modelle zu intelligenteren Werkzeugen in der Zukunft sind.
Grundlegende Fähigkeit zur Textzusammenfassung, die Ausführung großer Modelle ist in der Tat ein „Hühnermord“.
Die Bewertung dieser Grundfähigkeiten scheint für die Untersuchung der zukünftigen Entwicklung großer Modelle etwas unprofessionell zu sein.
Papieradresse: https://arxiv.org/pdf/2305.17306.pdf
Welches Unternehmen verfügt über die besten Fähigkeiten zum Denken großer Modelle?
Aus diesem Grund haben Forscher eine komplexe Inferenzaufgabenliste, Chain-of-Thought Hub, zusammengestellt, um die Leistung des Modells bei anspruchsvollen Inferenzaufgaben zu messen.
Zu den Testaufgaben gehören Mathematik (GSM8K), Naturwissenschaften (MATH, Theorem QA), Symbole (BBH), Wissen (MMLU, C-Eval) und Codierung (HumanEval).
Diese Testprojekte oder Datensätze zielen alle auf die komplexen Argumentationsfunktionen großer Modelle ab. Es gibt keine einfache Aufgabe, die jeder genau beantworten kann.
Forscher verwenden immer noch die COT-Prompt-Methode, um die Argumentationsfähigkeit des Modells zu bewerten.
Für den Test der Denkfähigkeit verwenden Forscher nur die Leistung der endgültigen Antwort als einziges Messkriterium, und die Zwischenschritte des Denkens werden nicht als Grundlage für die Beurteilung herangezogen.
Wie in der folgenden Abbildung dargestellt, ist die Leistung aktueller Mainstream-Modelle bei verschiedenen Argumentationsaufgaben dargestellt.
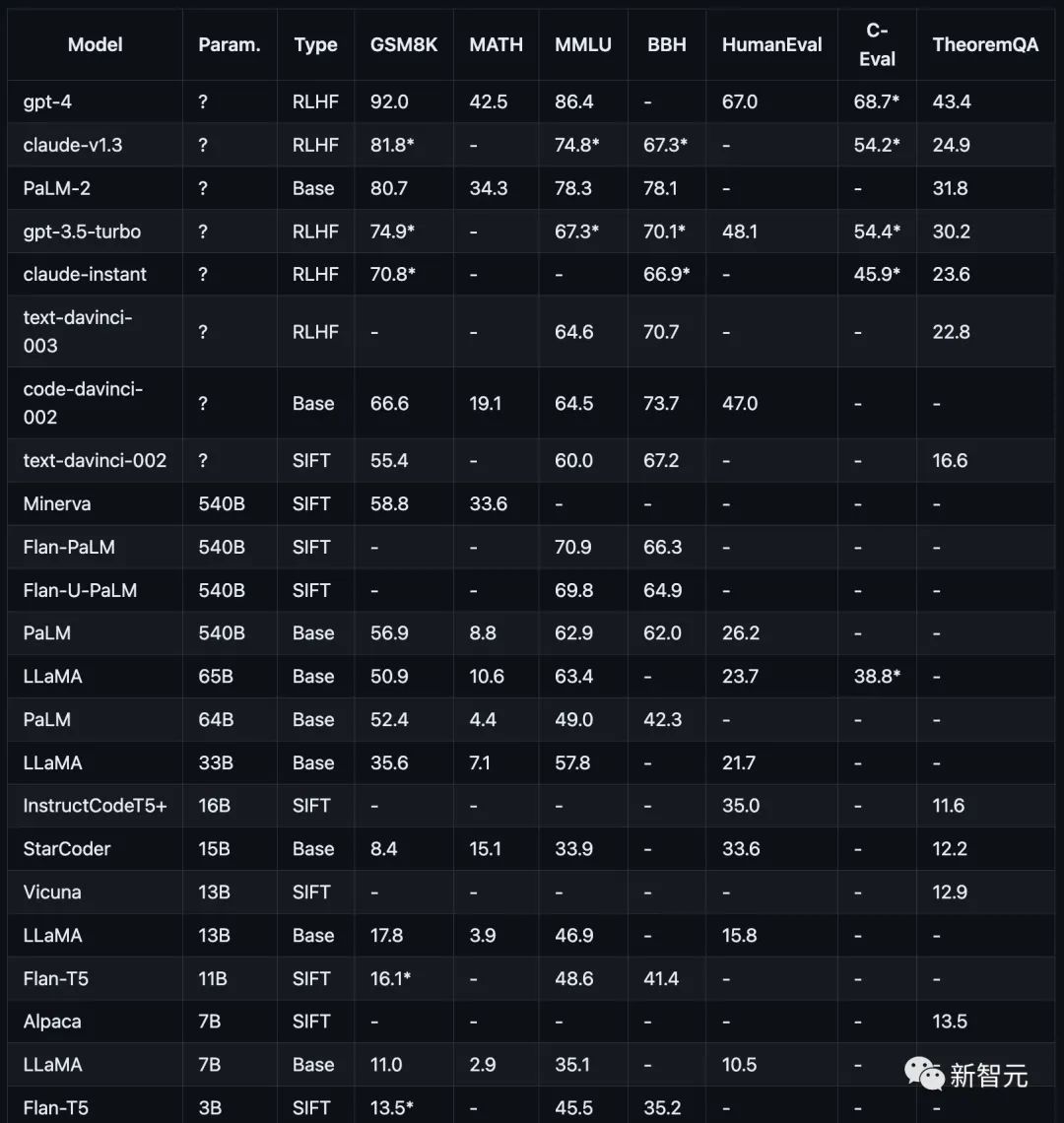
Testergebnisse: Je größer das Modell, desto stärker die Inferenzfähigkeit
Die Forschung der Forscher konzentriert sich auf derzeit beliebte Modelle, darunter GPT, Claude, PaLM, LLaMA und die T5-Modellfamilie, insbesondere:
OpenAI GPT umfasst GPT-4 (derzeit die stärkste), GPT3.5-Turbo (schneller, aber schwächer), text-davinci-003, text-davinci-002 und code-davinci-002 (vor Turbo wichtige Version) .

Anthropic Claude enthält claude-v1.3 (langsamer, aber leistungsfähiger) und claude-instant-v1.0 (schneller, aber weniger leistungsfähig).
Google PaLM, einschließlich PaLM, PaLM-2 und deren anweisungsangepasste Versionen (FLan-PaLM und Flan-UPaLM), starke Basis- und anweisungsangepasste Modelle.

Meta LLaMA, einschließlich der Varianten 7B, 13B, 33B und 65B, wichtiges Open-Source-Grundmodell.
GPT-4 übertrifft alle anderen Modelle auf GSM8K und MMLU deutlich, während Claude das einzige ist, das mit der GPT-Serie vergleichbar ist.
Kleinere Modelle wie FlanT5 11B und LLaMA 7B hinken weit hinterher.
Durch Experimente fanden Forscher heraus, dass die Modellleistung normalerweise mit der Skalierung zusammenhängt und einen ungefähr logarithmischen linearen Trend zeigt.
Modelle, die keine Parameterskalen offenlegen, schneiden im Allgemeinen besser ab als Modelle, die Skaleninformationen offenlegen.
Die Inferenzfähigkeit von LLaMA-65B kommt ChatGPT nahe
Darüber hinaus wiesen die Forscher darauf hin, dass die Open-Source-Community möglicherweise noch den „Graben“ in Bezug auf Skalierung und RLHF erkunden muss, um weitere Verbesserungen vorzunehmen.
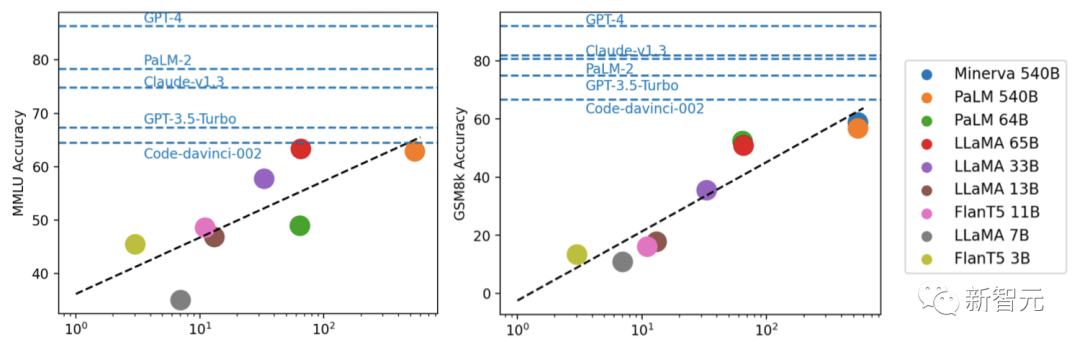
Fu Yao, der Erstautor des Artikels, kam zu dem Schluss:
1 Es gibt eine klare Lücke zwischen Open Source und Closed.
2. Die meisten der am besten bewerteten Mainstream-Modelle sind RLHF
3 und kommen dem Code-Davinci-002, dem Basismodell von GPT-3.5, sehr nahe die oben genannten, die meisten Die Richtung der Hoffnung besteht darin, „RLHF auf LLaMA 65B zu machen“.
Für dieses Projekt erklärt der Autor weitere Optimierungen in der Zukunft: 
In Zukunft werden weitere Argumentationsdatensätze, darunter auch sorgfältiger ausgewählte, hinzugefügt, insbesondere um das Denken mit gesundem Menschenverstand zu messen und mathematische Theoreme von Datensätzen.
und die Möglichkeit, externe APIs aufzurufen.
Wichtiger ist die Einbeziehung weiterer Sprachmodelle, beispielsweise auf LLaMA basierende Anleitungs-Feinabstimmungsmodelle wie Vicuna7 und andere Open-Source-Modelle.
Sie können auch über APIs wie Cohere 8 auf die Funktionen von Modellen wie PaLM-2 zugreifen.
Kurz gesagt, der Autor glaubt, dass dieses Projekt eine große Rolle als öffentliche Wohlfahrtseinrichtung zur Bewertung und Steuerung der Entwicklung großer Open-Source-Sprachmodelle spielen kann.
Das obige ist der detaillierte Inhalt vonDas chinesische Wissenschaftsteam startet die „Thinking Chain Collection', um die komplexe Denkfähigkeit großer Modelle umfassend zu bewerten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr