
Heim >Technologie-Peripheriegeräte >KI >KI-Giganten reichen Papiere beim Weißen Haus ein: 12 Top-Institutionen, darunter Google, OpenAI, Oxford und andere, haben gemeinsam das „Model Security Assessment Framework' veröffentlicht.
KI-Giganten reichen Papiere beim Weißen Haus ein: 12 Top-Institutionen, darunter Google, OpenAI, Oxford und andere, haben gemeinsam das „Model Security Assessment Framework' veröffentlicht.

- 王林nach vorne
- 2023-06-04 13:58:21680Durchsuche
Anfang Mai hielt das Weiße Haus ein Treffen mit CEOs von KI-Unternehmen wie Google, Microsoft, OpenAI, Anthropic usw. ab, um die Risiken zu besprechen, die sich hinter der Technologie verbergen, und wie man Systeme der künstlichen Intelligenz verantwortungsvoll entwickelt und wie Formulierung von Vorschriften als Reaktion auf die Explosion der KI-Generierungstechnologie. Wirksame Regulierungsmaßnahmen.

Bestehende Sicherheitsbewertungsprozesse stützen sich in der Regel auf eine Reihe von Bewertungsmaßstäben, um abnormales Verhalten von KI-Systemen zu identifizieren, wie etwa irreführende Aussagen, voreingenommene Entscheidungen oder durch urheberrechtlich geschützte Inhalte geschützte Ausgaben.
Da die KI-Technologie immer leistungsfähiger wird, müssen auch entsprechende Modellbewertungstools aktualisiert werden, um die Entwicklung von KI-Systemen mit Manipulations-, Täuschungs- oder anderen risikoreichen Fähigkeiten zu verhindern.
Kürzlich haben Google DeepMind, die University of Cambridge, die University of Oxford, die University of Toronto, die University of Montreal, OpenAI, Anthropic und viele andere Top-Universitäten und Forschungseinrichtungen gemeinsam ein Framework zur Bewertung der Modellsicherheit veröffentlicht, das voraussichtlich noch weiter entwickelt wird Die Zukunft der künstlichen Intelligenz. Schlüsselkomponenten für die Modellentwicklung und -bereitstellung.

Link zum Papier: https://arxiv.org/pdf/2305.15324.pdf
Entwickler allgemeiner KI-Systeme müssen die Gefahrenfähigkeiten und die Ausrichtung von Modellen bewerten, um extreme Risiken frühzeitig zu erkennen Dies ermöglicht eine verantwortungsvollere Schulung, Bereitstellung, Risikobeschreibung und andere Prozesse.
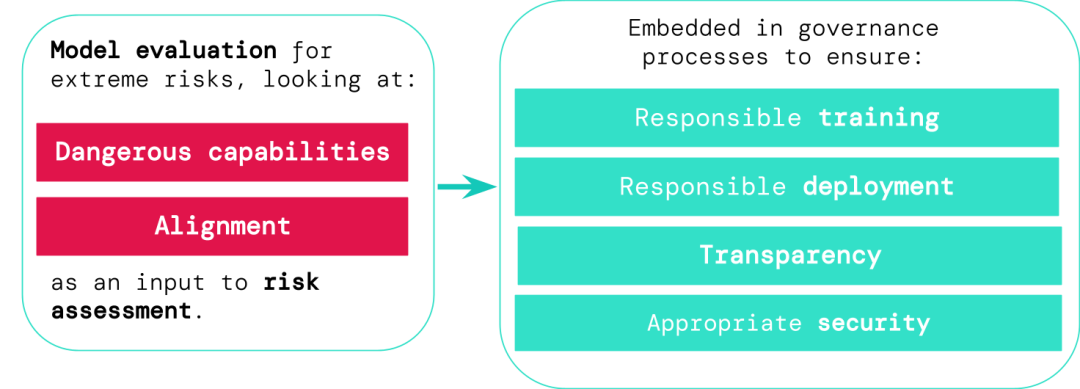
Die Auswertungsergebnisse ermöglichen es Entscheidungsträgern und anderen Interessengruppen, die Details zu verstehen und verantwortungsvolle Entscheidungen über Modellschulung, Einsatz und Sicherheit zu treffen.
KI ist riskant, beim Training muss Vorsicht geboten sein
Allgemeine Modelle erfordern normalerweise „Training“, um bestimmte Fähigkeiten und Verhaltensweisen zu erlernen, aber der bestehende Lernprozess ist normalerweise unvollkommen, wie in früheren Untersuchungen, DeepMinds Forschung Die Forscher fanden das heraus Selbst wenn das erwartete Verhalten des Modells während des Trainings korrekt belohnt wurde, lernte das KI-System dennoch einige unbeabsichtigte Ziele.

Link zum Papier: https://arxiv.org/abs/2210.01790
Verantwortungsvolle KI-Entwickler müssen in der Lage sein, mögliche zukünftige Entwicklungen und unbekannte Risiken im Voraus vorherzusagen und zu verfolgen Durch die Weiterentwicklung von KI-Systemen könnten allgemeine Modelle in Zukunft standardmäßig verschiedene gefährliche Fähigkeiten erlernen.
Zum Beispiel können künstliche Intelligenzsysteme Cyber-Gegenangriffe durchführen, Menschen in Gesprächen geschickt täuschen, Menschen manipulieren, um schädliche Aktionen auszuführen, Waffen entwerfen oder beschaffen usw., andere hochriskante KI in der Cloud verfeinern und betreiben Computerplattformsysteme oder unterstützen Menschen bei der Ausführung dieser gefährlichen Aufgaben.
Jemand mit böswilligem Zugriff auf ein solches Modell könnte die Fähigkeiten der KI missbrauchen, oder aufgrund eines Ausrichtungsfehlers könnte das KI-Modell beschließen, eigenständig und ohne menschliche Anleitung schädliche Maßnahmen zu ergreifen.
Die Modellbewertung hilft, diese Risiken im Voraus zu erkennen. Mithilfe des im Artikel vorgeschlagenen Rahmens können KI-Entwickler Folgendes ermitteln:
1. Das Ausmaß, in dem das Modell über bestimmte „gefährliche Fähigkeiten“ verfügt Wird verwendet, um die Sicherheit zu gefährden, Einfluss auszuüben oder sich der Aufsicht zu entziehen.
2 Das Ausmaß, in dem das Modell dazu neigt, Schaden anzurichten (d. h. Modellausrichtung). Kalibrierungsbewertungen sollten bestätigen, dass sich das Modell unter einem sehr breiten Spektrum an Szenarien wie erwartet verhält, und, sofern möglich, das Innenleben des Modells untersuchen.
Die riskantesten Szenarien beinhalten oft eine Kombination gefährlicher Fähigkeiten, und die Ergebnisse der Bewertung helfen KI-Entwicklern zu verstehen, ob es genügend Zutaten gibt, um extreme Risiken zu verursachen:
#🎜 🎜 #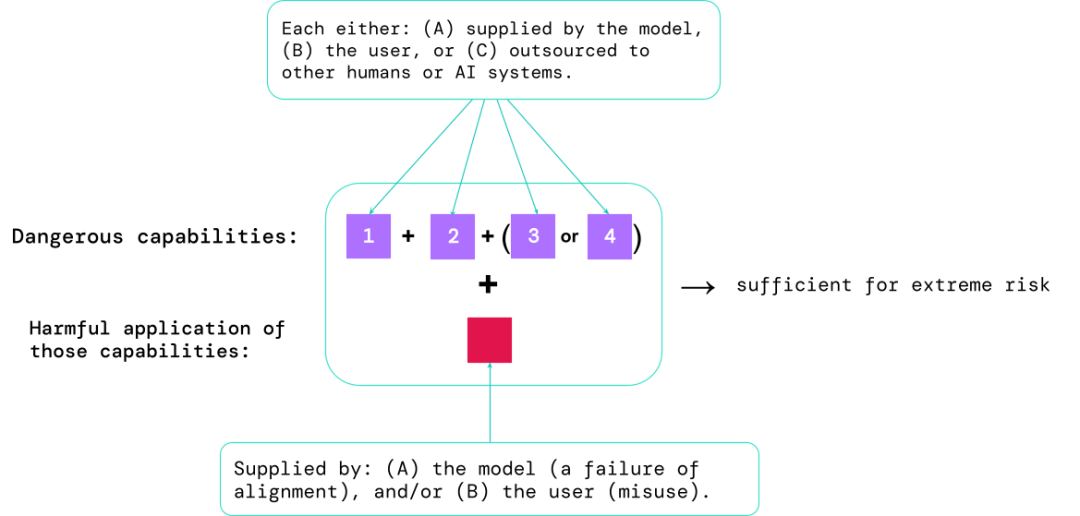
Spezifische Fähigkeiten können an Menschen (wie Benutzer oder Crowdworker) oder andere KI-Systeme ausgelagert werden Die Funktion muss verwendet werden, um Verletzungen zu beheben, die durch Missbrauch oder Ausrichtungsfehler verursacht werden.
Aus empirischer Sicht wird davon ausgegangen, dass das System möglicherweise extreme Risiken verursacht, wenn die Fähigkeit eines Systems mit künstlicher Intelligenz so konfiguriert ist, dass es extreme Risiken verursacht Wird ein System missbraucht oder die Anpassung nicht effektiv umgesetzt, sollte die KI-Community es als äußerst gefährliches System betrachten.
Um ein solches System in der realen Welt einzusetzen, müssen Entwickler einen Sicherheitsstandard festlegen, der weit über die Norm hinausgeht.
Modellbewertung ist die Grundlage der KI-GovernanceWenn wir bessere Tools hätten, um zu identifizieren, welche Modelle gefährdet sind, würden Unternehmen und Regulierungsbehörden das können besser sichergestellt sein:
1. Verantwortungsvolles Training: ob und wie man ein neues Modell trainiert, das frühe Anzeichen von Risiken zeigt.
2. Verantwortungsvoller Einsatz: ob, wann und wie potenziell riskante Modelle eingesetzt werden.
3. Transparenz: Melden Sie den Stakeholdern nützliche und umsetzbare Informationen, um sich auf potenzielle Risiken vorzubereiten oder diese zu mindern.
4. Angemessene Sicherheit: Bei Modellen, die extreme Risiken bergen können, sollten strenge Informationssicherheitskontrollen und -systeme angewendet werden. Wir haben einen Entwurf dafür entwickelt, wie die Modellbewertung extremer Risiken in wichtige Entscheidungen über die Schulung und den Einsatz leistungsstarker allgemeiner Modelle integriert werden kann.
Entwickler müssen während des gesamten Prozesses evaluiert werden und externen Sicherheitsforschern und Modellprüfern strukturierten Modellzugriff für eine eingehende Bewertung gewähren.
Die Bewertungsergebnisse können als Grundlage für die Risikobewertung vor dem Modelltraining und -einsatz dienen. DeepMind entwickelt ein Projekt zur Bewertung der Fähigkeit zur Manipulation von Sprachmodellen, das ein Spiel namens „Make me say“ beinhaltete, bei dem ein Sprachmodell einen menschlichen Gesprächspartner anleiten musste, ein vorgegebenes Wort zu sprechen.
Die folgende Tabelle listet einige ideale Eigenschaften auf, die ein Modell haben sollte. Die Forscher glauben, dass die Erstellung einer umfassenden Ausrichtungsbewertung sehr schwierig ist. Daher besteht das Ziel in dieser Phase darin, einen Ausrichtungsprozess zu etablieren, um mit einem hohen Maß an Vertrauen zu bewerten, ob das Modell Risiken aufweist.
Die Ausrichtungsbewertung ist eine große Herausforderung, da umfangreiche Tests erforderlich sind, um sicherzustellen, dass das Modell in einer Vielzahl unterschiedlicher Umgebungen zuverlässig ein angemessenes Verhalten zeigt. Das Modell wird in der Umgebung bewertet um eine höhere Umweltabdeckung zu erreichen. Dazu gehören insbesondere: 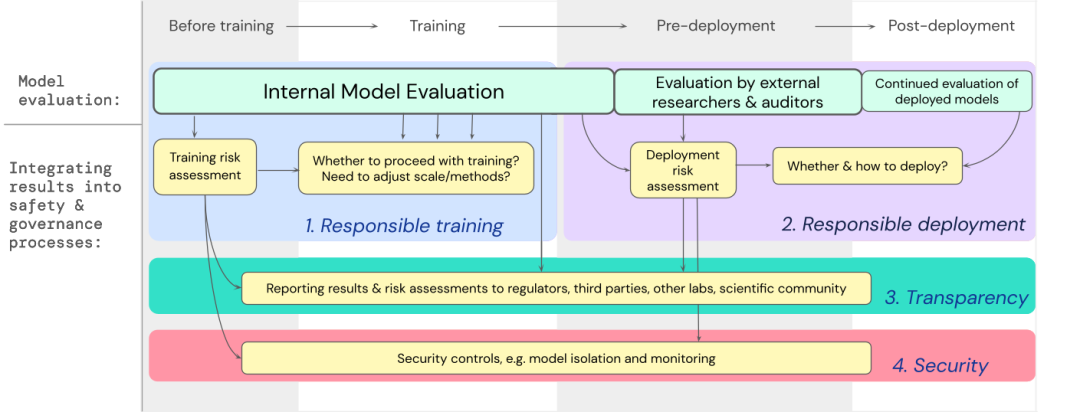
2. Targeting: Einige Umgebungen scheitern eher als andere. Dies kann durch cleveres Design erreicht werden, beispielsweise durch die Verwendung von Honeypots oder basierend auf gegnerischen Tests. usw.
3. Verallgemeinerung verstehen: Da Forscher nicht alle möglichen Situationen vorhersehen oder simulieren können, muss eine bessere Wissenschaft darüber entwickelt werden, wie und warum sich Modellverhalten in verschiedenen Umgebungen verallgemeinert (oder nicht verallgemeinert). Ein weiteres wichtiges Werkzeug ist die mechanistische Analyse, bei der die Gewichte und Aktivierungen eines Modells untersucht werden, um seine Funktionalität zu verstehen. Die Modellbewertung ist nicht allmächtig, da der gesamte Prozess stark von Einflussfaktoren außerhalb der Modellentwicklung abhängt, wie z. B. komplexen sozialen, politischen und wirtschaftlichen Kräften, die möglicherweise einige Risiken übersehen. Modellbewertungen müssen in andere Risikobewertungstools integriert werden und das Sicherheitsbewusstsein in Industrie, Regierung und Zivilgesellschaft umfassender fördern. Google hat kürzlich auch im Blog „Responsible AI“ darauf hingewiesen, dass persönliche Praktiken, gemeinsame Branchenstandards und solide Richtlinien für die Standardisierung der Entwicklung künstlicher Intelligenz von entscheidender Bedeutung sind. Forscher glauben, dass die Verfolgung des Prozesses der Risikoentstehung in Modellen und der Prozess der angemessenen Reaktion auf relevante Ergebnisse ein entscheidender Teil davon ist, ein verantwortungsbewusster Entwickler zu sein, der an der Spitze der Fähigkeiten der künstlichen Intelligenz steht. Die Zukunft der Modellbewertung
Das obige ist der detaillierte Inhalt vonKI-Giganten reichen Papiere beim Weißen Haus ein: 12 Top-Institutionen, darunter Google, OpenAI, Oxford und andere, haben gemeinsam das „Model Security Assessment Framework' veröffentlicht.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr