
Heim >Datenbank >MySQL-Tutorial >So beheben Sie einen MySQL-Indexfehler
So beheben Sie einen MySQL-Indexfehler

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-04 09:24:393037Durchsuche
1. Vorwort
Beim Durchführen einer Indexabfrage für eine SQL-Anweisung wird ein Indexfehler auftreten, der einen entscheidenden Einfluss auf die Durchführbarkeit und Leistungseffizienz der Anweisung hat. In diesem Artikel wird analysiert, warum der Index fehlschlägt. code>, welche Situationen zu einem Indexfehler führen und Optimierungslösungen für einen Indexfehler, die sich auf das Linkste-Präfix-Matching-Prinzip konzentrieren, Logische Architektur und Optimierer von MySQL, Indexfehlerszenarien und warum sie fehlschlagen. 索引为何失效,有哪些情况会导致索引失效以及对于索引失效时的优化解决方案,其中着重介绍最左前缀匹配原则、MySQL逻辑架构和优化器、索引失效场景以及为何会失效。
二、最左前缀匹配原则
之前有写了一篇关于MySQL添加索引特点及优化问题方面的文章,下面将介绍索引失效的相关内容。
首先引入在之后的索引失效原因中会使用到的一个原则:最左前缀匹配原则。
最左前缀底层原理:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
什么是最左前缀匹配原则呢?要想理解联合索引的最左匹配原则,先来理解下索引的底层原理:索引的底层是一颗B+树,那么联合索引的底层也就是一颗B+树,只不过联合索引的B+树节点中存储的是键值。数据库需要依赖联合索引中最左边的字段来构建,因为B+树只能根据一个值来确定索引关系。
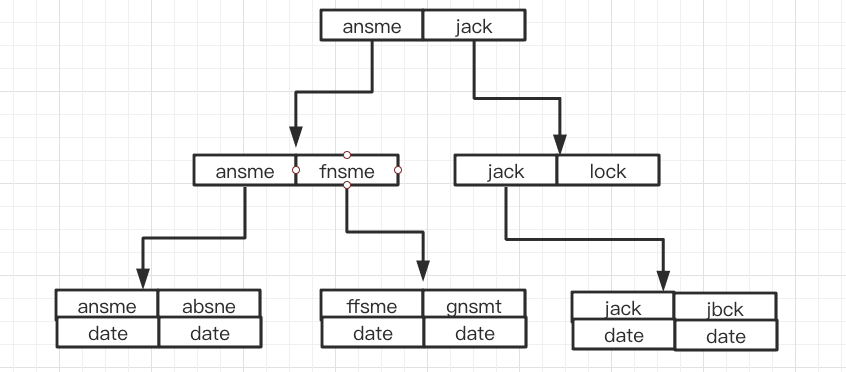
举例:创建一个(a,b)的联合索引,那么它的索引树就是下图的样子。
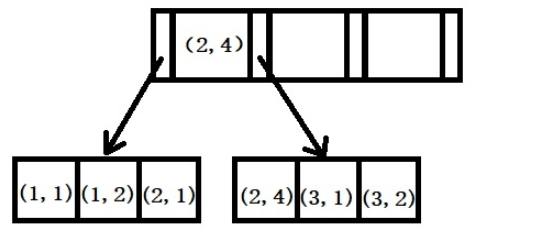
a的值有序,出现的顺序为1,1,2,2,3,3。b的值无序,出现的数字为1,2,1,4,1,2。在a的值相等的情况下,我们可以观察到b的值按照一定顺序排列,但要注意这个顺序是相对的。这是因为MySQL创建联合索引的规则是首先会对联合索引的最左边第一个字段排序,在第一个字段的排序基础上,然后在对第二个字段进行排序。所以b=2这种查询条件没有办法利用索引。
由于整个过程是基于explain结果分析的,那接下来在了解下explain中的type字段和key_lef字段。
1.type:联接类型。
system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计
const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。因为只需匹配一行数据,所有很快。将主键放在WHERE条件中,MySQL会将该查询转换为一个const查询。
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。注意:ALL全表扫描的表记录最少的表如t1表
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。-
2. Prinzip des Präfixabgleichs ganz linksindex - Ich habe zuvor einen Artikel über die Merkmale und Optimierungsprobleme beim Hinzufügen von Indizes zu MySQL geschrieben. Im Folgenden wird der relevante Inhalt von Indexfehlern vorgestellt. Führen Sie zunächst ein Prinzip ein, das in den folgenden Gründen für Indexfehler verwendet wird:
Das Prinzip der Übereinstimmung des Präfixes ganz links.
Was ist das Prinzip des Präfixabgleichs ganz links? Um das am weitesten links stehende Matching-Prinzip des gemeinsamen Index zu verstehen, verstehen Sie zunächst das zugrunde liegende Prinzip des Index: Die unterste Ebene des Index ist ein B + -Baum, und dann ist die untere Ebene des gemeinsamen Index ebenfalls ein B + -Baum, jedoch im B + -Baum Knoten des gemeinsamen Index Schlüsselwerte werden gespeichert. Die Datenbank muss auf der Grundlage des Felds ganz links im gemeinsamen Index erstellt werden, da der B+-Baum die Indexbeziehung nur auf der Grundlage eines Werts bestimmen kann.
Beispiel: Erstellen Sie einen gemeinsamen Index von (a, b), dann sieht sein Indexbaum wie im Bild unten aus.
- a-Werte sind in der Reihenfolge: Die Reihenfolge des Auftretens ist 1, 1, 2, 2, 3, 3. Die Werte von b sind ungeordnet und die angezeigten Zahlen sind 1, 2, 1, 4, 1, 2. Wenn die Werte von a gleich sind, können wir beobachten, dass die Werte von b in einer bestimmten Reihenfolge angeordnet sind. Es ist jedoch zu beachten, dass diese Reihenfolge relativ ist. Dies liegt daran, dass die MySQL-Regel zum Erstellen eines gemeinsamen Index darin besteht, zuerst das Feld ganz links im gemeinsamen Index basierend auf der Sortierung des ersten Felds und dann das zweite Feld zu sortieren. Daher gibt es keine Möglichkeit, den Index für Abfragebedingungen wie b=2 zu verwenden. Da der gesamte Prozess auf der EXPLAIN-Ergebnisanalyse basiert, lernen wir das Typfeld und das key_lef-Feld in EXPLAIN kennen.
- 1.
Typ: Verbindungstyp
. - system: Die Tabelle hat nur eine Zeile mit Datensätzen (entspricht der Systemtabelle). Sie erscheint normalerweise nicht und kann ignoriert werden Wird einmal über den Index gefunden, wird const zum Vergleichen des Primärschlüssels oder des eindeutigen Index verwendet. Da Sie nur eine Datenzeile abgleichen müssen, geht es sehr schnell. Setzen Sie den Primärschlüssel in die WHERE-Bedingung und MySQL konvertiert die Abfrage in eine konstante Abfrage.
ref: nicht eindeutiger Indexscan, geben alle Zeilen zurück, die einem einzelnen Wert entsprechen. Im Wesentlichen handelt es sich um einen Indexzugriff, der alle Zeilen zurückgibt, die einem einzelnen Wert entsprechen. Es können jedoch mehrere übereinstimmende Zeilen gefunden werden, daher sollte es sich um eine Mischung aus Suche und Scan handeln. -
range: Rufen Sie nur Zeilen in einem bestimmten Bereich ab und verwenden Sie einen Index, um Zeilen auszuwählen. Die Schlüsselspalte zeigt, welcher Index verwendet wird. Im Allgemeinen erscheinen Abfragen wie between, , in usw. in der where-Anweisung. Dieser Bereichsscan für Indexspalten ist besser als ein vollständiger Indexscan. Es muss nur an einem bestimmten Punkt beginnen und an einem anderen Punkt enden, ohne den gesamten Index zu scannen.
index: Vollständiger Index-Scan. Der Unterschied zwischen Index und ALL besteht darin, dass der Indextyp nur den Indexbaum durchläuft. Dies sind normalerweise ALLE Blöcke, da Indexdateien normalerweise kleiner sind als Datendateien. (Obwohl Index und ALL beide die gesamte Tabelle lesen, liest Index aus dem Index, während ALL von der Festplatte liest)🎜🎜🎜🎜ALL: Vollständiger Tabellenscan, durchläuft die gesamte Tabelle, um passende Zeilen zu finden🎜🎜🎜🎜 2.🎜 key_len🎜: Zeigt die Länge des Index an, den MySQL tatsächlich verwenden möchte. Wenn der Index NULL ist, ist die Länge NULL. Wenn nicht NULL, die Länge des verwendeten Index. Aus diesem Feld kann also abgeleitet werden, welcher Index verwendet wird. 🎜🎜🎜Berechnungsregeln: 🎜🎜🎜🎜🎜1. Feld mit fester Länge, int belegt 4 Bytes, Datum belegt 3 Bytes, char(n) belegt n Zeichen. 🎜🎜🎜🎜2. Das Feld variabler Länge varchar(n) nimmt n Zeichen + zwei Bytes ein. 🎜🎜🎜🎜3. Bei verschiedenen Zeichensätzen ist die Anzahl der von einem Zeichen belegten Bytes unterschiedlich. Bei der Latin1-Codierung belegt ein Zeichen ein Byte, bei der GDK-Codierung belegt ein Zeichen zwei Bytes und bei der UTF-8-Codierung belegt ein Zeichen drei Bytes. 🎜🎜🎜🎜 (Da meine Datenbank das Codierungsformat Latin1 verwendet, wird in den nachfolgenden Berechnungen ein Zeichen als ein Byte gezählt) 🎜🎜🎜🎜4. Wenn alle Indexfelder auf NULL gesetzt sind, ist 1 Byte erforderlich. 🎜🎜🎜🎜Nachdem wir das Prinzip des Präfixabgleichs ganz links verstanden haben, werfen wir einen Blick auf das Indexfehlerszenario und analysieren, warum es fehlschlägt. 🎜3. Logische MySQL-Architektur und -Optimierer
Logische MySQL-Architektur: MySQL逻辑架构:
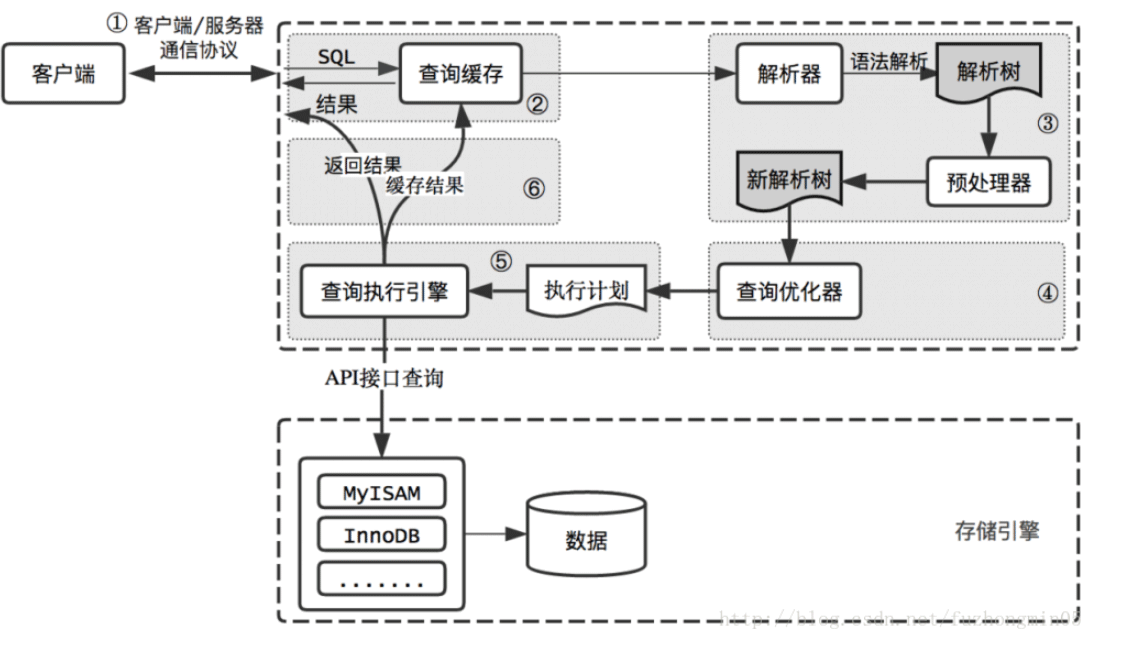
mysql架构可分为大概的4层,分别是:
1.客户端:各种语言都提供了连接mysql数据库的方法,比如jdbc、php、go等,可根据选择 的后端开发语言选择相应的方法或框架连接mysql
2.server层:包括连接器、查询缓存、分析器、优化器、执行器等,涵盖mysql的大多数核心服务功能,以及所有的内置函数(例如日期、世家、数 学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
3.存储引擎层:负责数据的存储和提取,是真正与底层物理文件打交道的组件。 数据本质是存储在磁盘上的,通过特定的存储引擎对数据进行有组织的存放并根据业务需要对数据进行提取。存储引擎的架构模式是插件式的,支持Innodb,MyIASM、Memory等多个存储引擎。现在最常用的存储引擎是Innodb,它从mysql5.5.5版本开始成为了默认存储引擎。
4.物理文件层:存储数据库真正的表数据、日志等。物理文件包括:redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等。
server层重要组件介绍:
1.连接器
连接器负责来自客户端的连接、获取用户权限、维持和管理连接。
一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建连接才会使用新的权限设置。
2.查询缓存
mysql拿到一个查询请求后,会先到查询缓存查看之前是否执行过这条语句。之前运行的语句及其输出结果可能直接存储在内存中,以键值对的形式缓存。key是查询的语句,value是查询的结果。当SQL查询的关键字(key)能够直接在查询缓存中匹配时,查询结果(value)就会被直接返回给客户端。
其实大多数情况下建议不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。只要涉及到一个表的更新操作,所有和该表相关的查询缓存都很容易失效并被清空。因此很有可能经过费力将结果存储之后,还未来得及使用就被新的更新操作全部清空了。对于更新操作多的数据库来说,查询缓存的命中率会非常低。除非业务需要的是一张静态表,很长时间才会更新一次。比如,一个系统配置表,那么这张表的查询才适合使用查询缓存。
3.分析器
词法分析(识别关键字,操作,表名,列名)
语法分析 (判断是否符合语法)
4.优化器
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
5.执行器
开始执行的时候,要先判断一下用户对这个表 T 有没有执行查询的权限。如果没有,就会返回没有权限的错误。如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去调用这个引擎提供的接口。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的。
MySQL优化器
MySQL-Architektur kann in ungefähr 4 Schichten unterteilt werden bzw.:
-
1.
Client: Methoden werden in verschiedenen Sprachen bereitgestellt Stellen Sie eine Verbindung zu einer MySQL-Datenbank wie JDBC, PHP, Go usw. her. Sie können die entsprechende Methode oder das entsprechende Framework auswählen, um eine Verbindung zu MySQL entsprechend der ausgewählten Back-End-Entwicklungssprache herzustellen
- #🎜 🎜#2.#🎜🎜 #Serverschicht: Einschließlich Konnektoren, Abfrage-Cache, Analysatoren, Optimierer, Executoren usw., die die meisten Kerndienstfunktionen von MySQL sowie alle integrierten Funktionen (z. B. Datum) abdecken , Familien-, Mathematik- und Verschlüsselungsfunktionen usw. ), werden alle speicherübergreifenden Engine-Funktionen in dieser Schicht implementiert, wie z. B. gespeicherte Prozeduren, Trigger, Ansichten usw.
- #🎜🎜#3.#🎜🎜#Storage Engine Layer#🎜🎜#: Verantwortlich für die Speicherung und den Abruf von Daten. Es ist die Komponente, die sich tatsächlich mit den zugrunde liegenden physischen Dateien befasst . Die Essenz der Daten wird auf der Festplatte gespeichert. Die Daten werden über eine spezielle Speicher-Engine organisiert gespeichert und entsprechend den Geschäftsanforderungen extrahiert. Das Architekturmodell der Speicher-Engine ist ein Plug-In und unterstützt mehrere Speicher-Engines wie Innodb, MyIASM und Memory. Die derzeit am häufigsten verwendete Speicher-Engine ist Innodb, die seit MySQL5.5.5 zur Standard-Speicher-Engine geworden ist. #🎜🎜#
- #🎜🎜#4. #🎜🎜#Physische Dateischicht #🎜🎜#: Speichert die echten Tabellendaten, Protokolle usw. der Datenbank. Zu den physischen Dateien gehören: Redolog, Undolog, Binlog, Errorlog, Querylog, Slowlog, Daten, Index usw. #🎜🎜#
Syntaktische Analyse (Bestimmen Sie, ob es entspricht der Grammatik) #🎜🎜##🎜🎜##🎜🎜#4. Optimierer#🎜🎜##🎜🎜##🎜🎜#Der Optimierer entscheidet, welcher Index verwendet wird, wenn die Tabelle mehrere Indizes enthält Wenn eine Anweisung über mehrere Tabellenzuordnungen (Join) verfügt, bestimmen Sie die Verbindungsreihenfolge jeder Tabelle. Nachdem die Optimierungsphase abgeschlossen ist, wird der Ausführungsplan dieser Anweisung bestimmt und tritt dann in die Executor-Phase ein. #🎜🎜##🎜🎜##🎜🎜#5. Executor #🎜🎜##🎜🎜##🎜🎜#Beim Starten der Ausführung müssen Sie zunächst feststellen, ob der Benutzer berechtigt ist, Abfragen für diese Tabelle T auszuführen. Wenn nicht, wird der Fehler „Keine Berechtigung“ zurückgegeben. Wenn der Abfragecache erreicht wird, erfolgt die Berechtigungsüberprüfung, wenn der Abfragecache die Ergebnisse zurückgibt. Die Abfrage ruft außerdem eine Vorprüfung auf, um Berechtigungen vor dem Optimierer zu überprüfen. Wenn Sie die Berechtigung haben, öffnen Sie die Tabelle und fahren Sie mit der Ausführung fort. Wenn eine Tabelle geöffnet wird, ruft der Executor die von der Engine bereitgestellte Schnittstelle basierend auf der Engine-Definition der Tabelle auf. In einigen Szenarien wird der Executor einmal aufgerufen und mehrere Zeilen werden innerhalb der Engine gescannt, sodass die Anzahl der von der Engine gescannten Zeilen nicht genau mit rows_examined
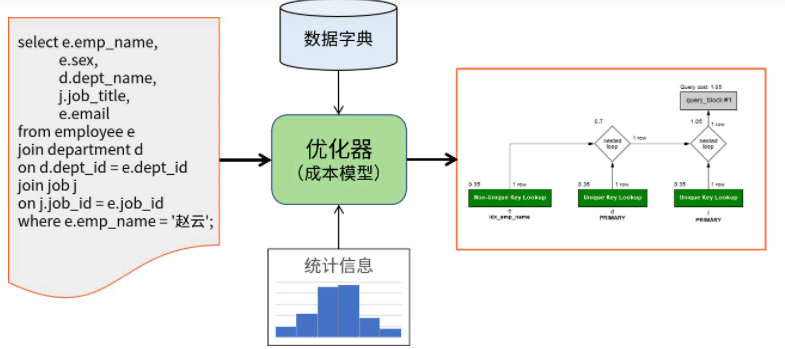
MySQL-Optimierer: #🎜🎜##🎜🎜#Der MySQL-Optimierer verwendet kostenbasierte Optimierung (kostenbasierte Optimierung), verwendet SQL-Anweisungen als Eingabe und verwendet das integrierte Im Kostenmodell und im Datenwörterbuch sowie in den statistischen Informationen der Speicher-Engine wird bestimmt, welche Schritte zur Implementierung der Abfrageanweisung, also des Abfrageplans, verwendet werden. #🎜🎜##🎜🎜##🎜🎜##🎜🎜##🎜🎜# Auf einer hohen Ebene ist der MySQL-Server in zwei Komponenten unterteilt: die Serverschicht und die Speicher-Engine-Schicht. Unter anderem arbeitet der Optimierer auf der Serverebene, die sich über der Speicher-Engine-API befindet. #🎜🎜##🎜🎜##🎜🎜#Der Arbeitsprozess des Optimierers kann semantisch in vier Phasen unterteilt werden: #🎜🎜##🎜🎜#1.Logische Transformation, einschließlich Negationsbeseitigung, Gleichwertübertragung und Konstantenübertragung, Auswertung konstanter Ausdrücke, Konvertierung von Außen-Joins in Innen-Joins, Konvertierung von Unterabfragen, Zusammenführen von Ansichten usw.;# 🎜 🎜#2.
Optimierungsvorbereitung, wie Indexreferenz- und Bereichszugriffsmethodenanalyse, Abfragebedingungs-Fanout-Wertanalyse (Fanout, Anzahl der Datensätze nach dem Filtern), konstante Tabellenerkennung; # 3.Basierend auf Kostenoptimierung
, einschließlich der Auswahl von Zugriffsmethoden und Verbindungssequenzen; 4.Verbesserung des Ausführungsplans
, z. Down, Zugriffsmethodenoptimierung, Sortiervermeidung und Indexbedingungs-Pushdown. 4. Indexfehlerszenarien und warum sie fehlschlagen werden
1.Like-Index beginnt mit Platzhalter % und schlägt fehl. Das Obige stellt das zugrunde liegende Prinzip des Präfixabgleichs ganz links vor. Wir wissen, dass die häufig verwendete Indexdatenstruktur ein B+-Baum ist und der Index geordnet ist. Wenn der Typ des Indexschlüsselworts Int type ist,
Der Index wird in der folgenden Reihenfolge sortiert: like以通配符%开头索引失效。上面介绍了最左前缀匹配底层原理,我们知道了通常用的索引数据结构是B+树,而索引是有序排列的。如果索引关键字的类型是Int 类型,索引的排列顺序如下:
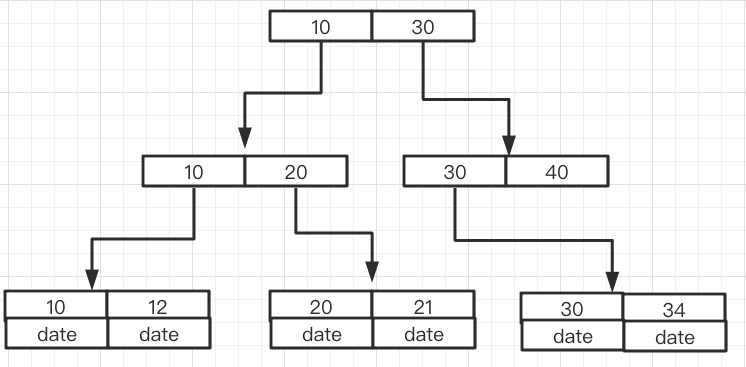
数据只存放在叶子节点,而且是有序的排放。
如果索引关键字的类型是String类型,排列顺序如下:
可以看出,索引的排列顺序是根据比较字符串的首字母排序的。
我们在进行模糊查询的时候,如果把 % 放在了前面,最左的 n 个字母便是模糊不定的,无法根据索引的有序性准确的定位到某一个索引,只能进行全表扫描,找出符合条件的数据。(最左前缀底层原理)
在使用联合索引时也是如此,如果违背了索引有序排列的规则,同样会造成索引失效,进行全表扫描。
例子:表example中有个组合索引为:(A,B,C)
SELECT * FROM example WHERE A=1 and B =1 and C=1; 可以走索引;
SELECT A FROM example WHERE C =1 and B=1 ORDER BY A; 可以走索引(使用了覆盖索引)
SELECT * FROM example WHERE C =1 and B=1 ORDER BY A; 不可以走索引
覆盖索引:索引包含所有满足查询需要的数据的索引,称为覆盖索引(Covering Index)
可以有两种方式优化:
一种是使用覆盖索引,第二种是把%放后面。
2.字段类型是字符串,where时没有用引号括起来。表中的字段为字符串类型,是B+树的普通索引,如果查询条件传了一个数字过去,它是不走索引的。
例子:表example中有个字段为pid是varchar类型。
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE pid = 1
//此时执行语句type为ref索引查询 explain SELECT * FROM example WHERE pid = '1'
为什么第一条语句未加单引号就不走索引了呢? 这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。
3.OR 前后只要存在非索引的列,都会导致索引失效。查询条件包含or,就有可能导致索引失效。
例子:表example中有字段为pid是int类型,score是int类型。
//此时执行语句type为ref索引查询 explain SELECT * FROM example WHERE pid = 1
//把or条件加没有索引的score,并不会走索引,为ALL全表查询 explain SELECT * FROM example WHERE pid = 1 OR score = 10
这里对于OR后面加上没有索引的score这种情况,假设它走了p_id的索引,但是走到score查询条件时,它还得全表扫描,也就是需要三步过程: 全表扫描+索引扫描+合并。
mysql是有优化器的,处于效率与成本,遇到OR条件,索引可能会失效也是合理的。
注意: 如果or条件的列都加了索引,索引可能会走的。
4.联合索引(组合索引),查询时的条件列不是联合索引中的第一个列,索引失效。在联合索引中,查询条件满足最左匹配原则时,索引是正常生效的。
当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则。
例子:有一个联合索引idx_pid_score,pid在前,score在后。
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1 OR score = 10
//此时执行语句type为ref索引查询,idx_pid_score索引 explain SELECT * FROM example WHERE pid = 1
//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score = 10
联合索引不满足最左原则,索引一般会失效,但是这个还跟Mysql优化器有关。
5.计算、函数、类型转换(自动或手动)导致索引失效,索引字段上使用(!= 或者 ,not in)时,可能会导致索引失效。
gespeichert Blattknoten und es handelt sich um eine geordnete Entladung.
Wenn der Typ des Indexschlüsselworts String type ist,
ersten Buchstaben der verglichenen Zeichenfolgen. #🎜🎜#Wenn wir eine Fuzzy-Abfrage durchführen, sind die n Buchstaben ganz links unscharf und unsicher. Wir können einen bestimmten Index nicht genau anhand der Indexreihenfolge lokalisieren. Wir können nur die gesamte Tabelle scannen um Daten zu finden, die die Bedingungen erfüllen. (Das zugrunde liegende Prinzip des Präfixes ganz links)#🎜🎜##🎜🎜#Das Gleiche gilt, wenn gemeinsamer Index verwendet wird führt außerdem dazu, dass der Index ungültig ist und ein Scan der vollständigen Tabelle durchgeführt wird. #🎜🎜#Beispiel: Es gibt einen kombinierten Index im Tabellenbeispiel: (A, B, C) #🎜🎜#SELECT * FROM example WHERE A=1 and B =1 and C=1; YesDen Index durchgehen; #🎜🎜#SELECT A FROM example WHERE C =1 and B=1 ORDER BY A; FROM example WHERE C =1 and B=1 ORDER BY A; Nicht möglich Indizierung #🎜🎜##🎜🎜##🎜🎜#Abgedeckter Index: #🎜🎜#Der Index enthält alle Elemente, die die Abfrageanforderungen erfüllen. Der Datenindex wird Covering Index genannt Verwenden Sie den Abdeckungsindex , der zweite besteht darin,% am Ende einzufügen. #🎜🎜##🎜🎜#2.Der Feldtyp ist eine Zeichenfolge und das Wo steht nicht in Anführungszeichen.Die Felder in der Tabelle sind vom Typ String und normale Indizes von B+-Bäumen. Wenn die Abfragebedingung eine Zahl übergibt, wird sie nicht indiziert. #🎜🎜#Beispiel: Im Tabellenbeispiel gibt es ein Feld, dessen PID vom Typ Varchar ist. #🎜🎜#//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE Date_ADD(birthtime,INTERVAL 1 DAY) = 6rrree#🎜🎜#Warum wird die erste Anweisung nicht ohne einfache Anführungszeichen indiziert? Dies liegt daran, dass der Vergleich zwischen Zeichenfolgen und Zahlen nicht erfolgt, wenn einfache Anführungszeichen hinzugefügt werden. MySQL führt keineimpliziteTypkonvertierung durch und konvertiert sie vor dem Vergleich in Gleitkommazahlen. #🎜🎜##🎜🎜#3.Solange vor und nach OR Nicht-Index-Spalten vorhanden sind, schlägt der Index fehl.Wenn die Abfragebedingung „oder“ enthält, kann dies zu einem Indexfehler führen. #🎜🎜#Beispiel: Es gibt Felder im Tabellenbeispiel, bei denen pid vom Typ int und score vom Typ int ist. #🎜🎜#//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score-1=5//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score != 2#🎜🎜# Hier gilt für den Fall, dass nach OR ein Score ohne Index hinzugefügt wird, vorausgesetzt, dass der Index von p_id verwendet wird, aber wenn es um die Score-Abfragebedingung geht, muss immer noch die gesamte Tabelle gescannt werden. Dies bedeutet, dass drei Schritte erforderlich sind:Vollständiger Tabellenscan + Indexscan + Zusammenführung.#🎜🎜#Mysql verfügt über einen Optimierer. Aus Effizienz- und Kostengründen ist es sinnvoll, dass der Index beim Auftreten von ODER-Bedingungen fehlschlägt. #🎜🎜##🎜🎜#Hinweis: Wenn die Spalten der ODER-Bedingung indiziert sind, kann der Index verloren gehen. #🎜🎜##🎜🎜#4.Gemeinsamer Index (kombinierter Index), die Bedingungsspalte in der Abfrage ist nicht die erste Spalte im gemeinsamen Index und der Index wird ungültig.Wenn im gemeinsamen Index die Abfragebedingungen das Übereinstimmungsprinzip ganz links erfüllen, wird der Index normal wirksam. #🎜🎜#Wenn wir einen gemeinsamen Index erstellen, z. B. (k1, k2, k3), entspricht dies der Erstellung von drei Indizes (k1), (k1, k2) und (k1, k2, k3). Left-Matching-Prinzip. #🎜🎜#Beispiel: Es gibt einen gemeinsamen Index idx_pid_score, mit pid an erster Stelle und Score an zweiter Stelle. #🎜🎜#//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score <> 3//此时执行语句type为range索引查询 explain SELECT * FROM example WHERE name is not null//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE name is not null OR card is not null#🎜🎜#Der gemeinsame Index erfüllt nicht das Prinzip ganz links, und der Index schlägt im Allgemeinen fehl, aber dies hängt auch mit dem MySQL-Optimierer zusammen. #🎜🎜##🎜🎜#5.Berechnung, Funktion, Typkonvertierung (automatisch oder manuell) führen zu Indexfehlern. Bei Verwendung von (!= oder , nicht in) im Indexfeld kann es zu Indexfehlern kommen Der Index ist ungültig.#🎜🎜#Birthtime ist indiziert, aber da es die in MySQL integrierte Funktion Date_ADD() verwendet, gibt es keinen Index. #🎜🎜#Beispiel: Im Tabellenbeispiel ist der Index idx_birth_time ein Geburtszeitfeld vom Typ datetime#🎜🎜#//此时执行语句example表会走type为index类型索引,example_two则为ALL全表搜索不走索引 explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name#🎜🎜#Es gibt auch Operationen für die Indexspalte (z. B. +, -, *, /), und der Index wird ungültig. #🎜🎜#Beispiel: Im Tabellenbeispiel gibt es einen Score-Feldindex vom Typ int, idx_score#🎜🎜#//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score-1=5还有不等于(!= 或者)导致索引失效。
例子:在表example中有int类型的score字段索引idx_score//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score != 2//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE score <> 3虽然score 加了索引,但是使用了!= 或者 ,not in这些时,索引如同虚设。
6.is null可以使用索引,is not null无法使用索引。
例子:在表example中有varchar类型的name字段索引idx_name,varchar类型的card字段索引idx_card。//此时执行语句type为range索引查询 explain SELECT * FROM example WHERE name is not null//此时执行语句type为ALL全表查询 explain SELECT * FROM example WHERE name is not null OR card is not null7.
左连接查询或者右连接查询查询关联的字段编码格式不一样。两张表相同字段外连接查询时字段编码格式不同则会不走索引查询。
例子:在表example中有varchar类型的name字段编码是utf8mb4,索引为idx_name
在表example_two中有varchar类型的name字段编码为utf8,索引为idx_name。
//此时执行语句example表会走type为index类型索引,example_two则为ALL全表搜索不走索引 explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name当把两表的字段类型改为一致时:
//此时执行语句example表会走type为index类型索引,example_two会走type为ref类型索引 explain SELECT e.name,et.name FROM example e LEFT JOIN example_two et on e.name = et.name所以字段类型也会导致索引失效
8.mysql估计使用全表扫描要比使用索引快,则不使用索引。当表的索引被查询,会使用最好的索引,除非优化器使用全表扫描更有效。优化器优化成全表扫描取决与使用最好索引查出来的数据是否超过表的30%的数据。建议:不要给’性别’等增加索引。如果某个数据列里包含了均是"0/1"或“Y/N”等值,即包含着许多重复的值,就算为它建立了索引,索引效果不会太好,还可能导致全表扫描。
Mysql出于效率与成本考虑,估算全表扫描与使用索引,哪个执行快,这跟它的优化器有关。
Das obige ist der detaillierte Inhalt vonSo beheben Sie einen MySQL-Indexfehler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!