
So lösen Sie Redis-bezogene Probleme

- PHPznach vorne
- 2023-06-04 08:33:021178Durchsuche
Redis-Persistenzmechanismus
Redis ist eine In-Memory-Datenbank, die Persistenz unterstützt. Sie synchronisiert Daten im Speicher über den Persistenzmechanismus mit Festplattendateien, um die Datenpersistenz sicherzustellen. Bei einem Neustart von Redis können die Daten wiederhergestellt werden, indem die Festplattendateien erneut in den Speicher geladen werden.
Implementierung: Erstellen Sie separat einen untergeordneten fork()-Prozess, kopieren Sie die Datenbankdaten des aktuellen übergeordneten Prozesses in den Speicher des untergeordneten Prozesses und schreiben Sie sie dann durch den untergeordneten Prozess in eine temporäre Datei es mit dieser temporären Datei, dann wird der untergeordnete Prozess beendet und der Speicher freigegeben.
RDB ist die Standardpersistenzmethode von Redis. Gemäß einer bestimmten Zeitperiodenstrategie werden die Speicherdaten in Form eines Snapshots in der Binärdatei der Festplatte gespeichert. Das heißt, Snapshot-Snapshot-Speicherung, die entsprechende generierte Datendatei ist dump.rdb, und der Snapshot-Zyklus wird über den Speicherparameter in der Konfigurationsdatei definiert. (Ein Snapshot kann eine Kopie der Daten sein, die er darstellt, oder eine Kopie der Daten.)
AOF: Redis hängt jeden empfangenen Schreibbefehl über die Write-Funktion an das Ende der Datei an, ähnlich wie MySQL-Binlog. Beim Neustart von Redis wird der Inhalt der gesamten Datenbank im Speicher neu aufgebaut, indem die in der Datei gespeicherten Schreibbefehle erneut ausgeführt werden.
Wenn beide Methoden gleichzeitig aktiviert sind, räumt Redis bei der Datenwiederherstellung der AOF-Wiederherstellung Vorrang ein.
Cache-Lawine, Cache-Penetration, Cache-Vorwärmung, Cache-Aktualisierung, Cache-Downgrade und andere Probleme
Cache-LawineWir können es einfach so verstehen: Aufgrund der Ungültigmachung des ursprünglichen Caches ist der neue Cache noch nicht abgelaufen (z Beispiel: Wir legen die gleiche Ablaufzeit für das Caching fest, und ein großer Bereich des Caches läuft gleichzeitig ab. Alle Anfragen, die ursprünglich auf den Cache zugreifen sollten, werden an die Datenbank abgefragt, was einen enormen Druck auf die Datenbank ausübt Die Belastung der Datenbank-CPU und des Speichers kann zu ernsthaften Ausfallzeiten der Datenbank führen. Dadurch kommt es zu einer Reihe von Kettenreaktionen, die zum Zusammenbruch des gesamten Systems führen.
Lösung: Die meisten Systemdesigner erwägen die Verwendung von Sperren (die häufigste Lösung) oder einer Warteschlange, um sicherzustellen, dass nicht viele Threads gleichzeitig in die Datenbank lesen und schreiben, wodurch eine große Anzahl von Parallelität vermieden wird Im Falle eines Fehlers wird die Anforderung an das zugrunde liegende Speichersystem weitergeleitet. Eine weitere einfache Lösung besteht darin, die Cache-Ablaufzeit zu verteilen.
Cache-Penetration Cache-Penetration bezieht sich auf Benutzerabfragedaten, die nicht in der Datenbank und natürlich auch nicht im Cache gefunden werden. Dies führt dazu, dass der Benutzer es bei der Abfrage nicht im Cache findet und jedes Mal erneut zur Abfrage in die Datenbank gehen und dann leer zurückkehren muss (entspricht zwei nutzlosen Abfragen). Auf diese Weise umgeht die Anfrage den Cache und überprüft direkt die Datenbank. Dies ist auch ein häufig auftretendes Problem mit der Cache-Trefferquote.
Lösung; Die gebräuchlichste Lösung besteht darin, den
Bloom-Filter zu verwenden, um alle möglichen Daten in eine ausreichend große Bitmap zu hashen. Daten, die definitiv nicht vorhanden sind, werden von dieser Bitmap abgefangen, wodurch der Abfragedruck auf den zugrunde liegenden Speicher vermieden wird System. Es gibt auch eine
einfachere und grobere Methode Wenn die von einer Abfrage zurückgegebenen Daten leer sind (unabhängig davon, ob die Daten nicht vorhanden sind oder das System ausfällt), werden wir das leere Ergebnis trotzdem zwischenspeichern, aber die Ablaufzeit ist sehr lang kurz, nicht länger als fünf Minuten. Der direkt festgelegte Standardwert wird im Cache gespeichert, sodass der Wert beim zweiten Mal im Cache abgerufen wird, ohne dass weiterhin auf die Datenbank zugegriffen werden muss. Diese Methode ist die einfachste und gröbste. Die 5-TB-Festplatte ist voller Daten. Bitte schreiben Sie einen Algorithmus, um die Daten zu deduplizieren. Wie kann dieses Problem gelöst werden, wenn die Daten eine Größe von 32 Bit haben? Was ist, wenn es 64bit ist?
Bitmap: Die typische Methode ist die Hash-Tabelle.
Der Nachteil besteht darin, dass Bitmap nur 1 Bit an Informationen für jedes Element aufzeichnen kann. Wenn Sie zusätzliche Funktionen ausführen möchten, können Sie dies leider nur tun, indem Sie mehr Platz und Zeit opfern.
Bloom-Filter (empfohlen)
besteht darin, k(k>1)k(k>1) unabhängige Hash-Funktionen einzuführen, um sicherzustellen, dass in einem bestimmten Element der Prozess abgeschlossen wird Gewichtsbeurteilung unter der Raum- und Fehleinschätzungsrate.
Sein Vorteil besteht darin, dass die Speicherplatzeffizienz und die Abfragezeit weitaus höher sind als bei herkömmlichen Algorithmen. Der Nachteil besteht darin, dass es eine gewisse Fehlerkennungsrate und Schwierigkeiten beim Löschen gibt.
Die Kernidee des Bloom-Filter-Algorithmus besteht darin, mehrere verschiedene Hash-Funktionen zu verwenden, um „Konflikte“ aufzulösen.
Es liegt ein Konfliktproblem (Kollisionsproblem) mit Hash vor. Die Werte zweier URLs, die durch Verwendung desselben Hashs erhalten werden, können gleich sein. Um Konflikte zu reduzieren, können wir mehrere weitere Hashes einführen. Wenn wir anhand eines der Hashwerte schließen, dass ein Element nicht in der Menge ist, dann ist das Element definitiv nicht in der Menge. Nur wenn alle Hash-Funktionen uns mitteilen, dass das Element in der Menge vorhanden ist, können wir sicher sein, dass das Element in der Menge vorhanden ist. Dies ist die Grundidee von Bloom-Filter.
Bloom-Filter wird im Allgemeinen verwendet, um festzustellen, ob ein Element in einem großen Datensatz vorhanden ist.
Durch Erinnerung hinzugefügt: Der Unterschied zwischen Cache-Penetration und Cache-Aufschlüsselung
Cache-Aufschlüsselung : bezieht sich auf einen Schlüssel, der sehr heiß und konzentriert ist Große Parallelität Wenn beim Zugriff auf diesen Schlüssel der Schlüssel abläuft, durchbricht der fortgesetzte große gleichzeitige Zugriff den Cache und fordert direkt die Datenbank an.
Lösung; Bevor Sie auf den Schlüssel zugreifen, verwenden Sie SETNX (festlegen, falls nicht vorhanden), um einen anderen Kurzzeitschlüssel festzulegen, um den Zugriff auf den aktuellen Schlüssel zu sperren, und löschen Sie dann den Kurzzeitschlüssel nach dem Zugriff.
3. Cache-Vorwärmung
Cache-Vorwärmung sollte ein relativ verbreitetes Konzept sein, das Vorheizen bedeutet, dass relevante Cache-Daten direkt geladen werden das Cache-System, nachdem das System online geht. Auf diese Weise können Sie das Problem vermeiden, zuerst die Datenbank abzufragen und dann die Daten zwischenzuspeichern, wenn der Benutzer sie anfordert! Benutzer fragen direkt zwischengespeicherte Daten ab, die vorgewärmt wurden!
Lösung:
1. Schreiben Sie direkt eine Cache-Aktualisierungsseite und führen Sie diese manuell aus, wenn Sie online gehen.
2. Die Datenmenge ist nicht groß und kann beim Start des Projekts automatisch geladen werden. 🎜🎜 # 3. Aktualisieren Sie den Cache regelmäßig;
Cache-Update Zusätzlich zur Cache-Invalidierungsstrategie, die mit dem Cache-Server geliefert wird (Redis hat Standardmäßig sind 6 Strategien verfügbar. Wir können auch eine individuelle Cache-Entfernung entsprechend den spezifischen Geschäftsanforderungen durchführen. Es gibt zwei gängige Strategien:
(1) Bereinigen abgelaufener Caches regelmäßig
(2) Wann Wenn ein Benutzer eine Anfrage stellt, wird beurteilt, ob der in der Anfrage verwendete Cache abgelaufen ist. Wenn er abgelaufen ist, wird er zum zugrunde liegenden System weitergeleitet, um neue Daten abzurufen und den Cache zu aktualisieren.
Beide haben ihre eigenen Vor- und Nachteile. Der Nachteil des ersten besteht darin, dass es schwieriger ist, eine große Anzahl zwischengespeicherter Schlüssel zu verwalten. Der Nachteil des zweiten besteht darin, dass der Cache jedes Mal gelöscht wird muss als ungültig beurteilt werden, und die Logik ist relativ kompliziert! Welche Lösung konkret zum Einsatz kommt, kann anhand der eigenen Anwendungsszenarien abgewogen werden.
5.
Cache-Downgrade Wenn die Anzahl der Besuche stark ansteigt, treten Dienstprobleme auf (z. B. langsame Reaktionszeit oder keine Antwort) oder nicht zum Kerngeschäft gehörende Dienste beeinträchtigen die Leistung des Kernprozesses muss weiterhin sichergestellt werden, dass der Dienst auch bei einem Dienstausfall weiterhin verfügbar ist. Das System kann basierend auf einigen Schlüsseldaten automatisch ein Downgrade durchführen oder Switches konfigurieren, um ein manuelles Downgrade durchzuführen.
Das ultimative Ziel des Downgrades besteht darin, sicherzustellen, dass Kerndienste verfügbar sind, auch wenn sie verlustbehaftet sind. Und einige Dienste können nicht herabgestuft werden (z. B. Hinzufügen zum Warenkorb, Bezahlen).
Legen Sie den Plan unter Bezugnahme auf die Protokollebene fest:
(1) Allgemein: Beispielsweise kommt es bei einigen Diensten aufgrund von Netzwerk-Jitter gelegentlich zu Zeitüberschreitungen oder der Dienst geht online und kann automatisch herabgestuft werden 🎜# (2) Warnung: Einige Dienste sind inaktiv. Wenn die Erfolgsquote innerhalb eines bestimmten Zeitraums schwankt (z. B. zwischen 95 und 100 %), können Sie ein automatisches Downgrade oder ein manuelles Downgrade durchführen und einen Alarm senden ) Fehler: Beispielsweise liegt die Verfügbarkeitsrate unter 90 % oder der Datenbankverbindungspool ist überlastet oder die Anzahl der Besuche steigt plötzlich auf den maximalen Schwellenwert, den das System ertragen kann. Zu diesem Zeitpunkt kann es automatisch herabgestuft werden oder je nach Situation manuell heruntergestuft werden;
(4) Schwerwiegender Fehler: Beispielsweise sind die Daten aus besonderen Gründen falsch. Dieses manuelle Downgrade ist erforderlich.
Der Zweck des Dienst-Downgrades besteht darin, einen Ausfall des Redis-Dienstes zu vermeiden, der wiederum Datenbanklawinenprobleme verursacht. Daher kann für unwichtige zwischengespeicherte Daten eine Service-Downgrade-Strategie angewendet werden. Ein gängiger Ansatz besteht beispielsweise darin, dass bei einem Problem mit Redis die Datenbank nicht abgefragt wird, sondern direkt der Standardwert an den Benutzer zurückgegeben wird.
Was sind heiße Daten und kalte Daten?
Heiße Daten, Cache ist wertvoll
Bei kalten Daten wurden die meisten Daten möglicherweise aus dem Speicher verdrängt, bevor erneut darauf zugegriffen werden konnte, was nicht nur Speicher beansprucht, sondern auch wenig Speicher hat Wert. Bei Daten, die häufig geändert werden, sollten Sie je nach Situation die Verwendung eines Caches in Betracht ziehen. In den beiden oben genannten Beispielen weisen sowohl die Langlebigkeitsliste als auch die Navigationsinformationen eine Eigenschaft auf, nämlich dass die Häufigkeit der Informationsänderung nicht hoch ist und die Leserate normalerweise hoch ist sehr hoch.
Bei wichtigen Daten wie einem unserer IM-Produkte, dem Geburtstagsgrußmodul und der Geburtstagsliste des Tages kann der Cache Hunderttausende Male gelesen werden. Ein weiteres Beispiel: In einem Navigationsprodukt speichern wir Navigationsinformationen zwischen und lesen sie möglicherweise in Zukunft millionenfach.
**Cache macht nur Sinn, wenn die Daten vor der Aktualisierung mindestens zweimal gelesen werden. Dies ist die grundlegendste Strategie, wenn der Cache ausfällt, bevor er wirksam wird.
Was ist mit dem Szenario, in dem der Cache nicht vorhanden ist und die Änderungshäufigkeit sehr hoch ist, aber Caching in Betracht gezogen werden muss? haben! Diese Leseschnittstelle übt beispielsweise großen Druck auf die Datenbank aus, es handelt sich jedoch auch um heiße Daten. Zu diesem Zeitpunkt müssen Caching-Methoden in Betracht gezogen werden, um den Druck auf die Datenbank zu verringern, z. B. die Anzahl der Likes, Sammlungen usw Anteile eines unserer Assistentenprodukte sind sehr typische Hot-Daten, die sich jedoch ständig ändern. Zu diesem Zeitpunkt müssen die Daten synchron im Redis-Cache gespeichert werden, um den Druck auf die Datenbank zu verringern.
2). von Datenstrukturen wie Zset und Hash
3). Die zugrunde liegenden Modelle sind unterschiedlich, die zugrunde liegenden Implementierungsmethoden und die Anwendungsprotokolle für die Kommunikation mit dem Client sind unterschiedlich. Redis hat direkt einen eigenen VM-Mechanismus erstellt, denn wenn das allgemeine System Systemfunktionen aufruft, verschwendet es eine gewisse Zeit für das Verschieben und Anfordern.
4) Die Wertgrößen sind unterschiedlich: Redis kann maximal 512 MB erreichen;
5) Die Geschwindigkeit von Redis ist viel schneller als die von Memcached
6) Redis unterstützt Datensicherung, also Datensicherung im Master-Slave-Modus.
(1) String
Dazu gibt es eigentlich nichts zu sagen. Die häufigste Set/Get-Operation, der Wert kann ein String oder ein sein Nummer. Im Allgemeinen werden einige komplexe Zählfunktionen zwischengespeichert.
(2) Hash
(3) Liste
Mit der Datenstruktur von List können Sie einfache Nachrichtenwarteschlangenfunktionen ausführen. Eine andere Sache ist, dass Sie den Befehl lrange verwenden können, um eine Redis-basierte Paging-Funktion zu implementieren, die eine hervorragende Leistung und eine gute Benutzererfahrung bietet. Ich verwende auch ein Szenario, das sehr gut geeignet ist: die Beschaffung von Marktinformationen. Es ist auch eine Szene von Produzenten und Konsumenten. LIST kann das Warteschlangen- und First-In-First-Out-Prinzip sehr gut vervollständigen. (4) set
Denn set ist eine Sammlung eindeutiger Werte. Daher kann die globale Deduplizierungsfunktion implementiert werden. Warum nicht das mit der JVM gelieferte Set für die Deduplizierung verwenden? Da unsere Systeme im Allgemeinen in Clustern bereitgestellt werden, ist es mühsam, das mit der JVM gelieferte Set zu verwenden. Ist es zu mühsam, einen öffentlichen Dienst nur für die globale Deduplizierung einzurichten?
Darüber hinaus können Sie durch die Verwendung von Operationen wie Schnittmenge, Vereinigung und Differenz allgemeine Präferenzen, alle Präferenzen, Ihre eigenen einzigartigen Präferenzen usw. berechnen.
(5) sortierter Satz
Der sortierte Satz verfügt über eine zusätzliche Gewichtsparameterbewertung, und die Elemente im Satz können entsprechend der Bewertung angeordnet werden. Sie können einen Ranking-Antrag stellen und TOP N-Operationen durchführen.
Redis interne Struktur
dict dient im Wesentlichen der Lösung des Suchproblems im Algorithmus (Suchen). Dabei handelt es sich um eine Datenstruktur, die zur Aufrechterhaltung der Zuordnungsbeziehung zwischen Schlüssel und Wert verwendet wird, ähnlich wie bei Map oder Dictionary in vielen Sprachen. Im Wesentlichen dient es dazu, das Suchproblem (Suchen) im Algorithmus zu lösen.
Redis‘ Ablaufstrategie und Speicherbeseitigungsmechanismus
Redis übernimmt die Regelmäßige Löschung + Lazy-Deletion-Strategie.
Warum nicht eine geplante Löschstrategie verwenden?
Beim geplanten Löschen wird der Schlüssel mithilfe eines Timers überwacht und er wird automatisch gelöscht, wenn er abläuft. Obwohl der Speicher rechtzeitig freigegeben wird, verbraucht er viele CPU-Ressourcen. Bei großen gleichzeitigen Anforderungen muss die CPU Zeit aufwenden, um die Anforderung zu verarbeiten, anstatt den Schlüssel zu löschen. Daher wird diese Strategie nicht übernommen ob ein abgelaufener Schlüssel vorhanden ist, und löschen Sie ihn, wenn ein abgelaufener Schlüssel vorhanden ist. Es ist zu beachten, dass Redis nicht alle 100 ms alle Schlüssel überprüft, sondern sie zufällig zur Überprüfung auswählt (wenn alle Schlüssel alle 100 ms überprüft werden, bleibt Redis dann nicht hängen)? Wenn Sie daher nur eine reguläre Löschstrategie anwenden, werden viele Schlüssel mit der Zeit nicht gelöscht.
Daher ist Lazy Deletion praktisch. Das heißt, wenn Sie einen Schlüssel erhalten, prüft Redis, ob der Schlüssel abgelaufen ist. Wenn eine Ablaufzeit festgelegt ist? Wenn es abläuft, wird es zu diesem Zeitpunkt gelöscht. Gibt es keine weiteren Probleme, wenn Sie das reguläre Löschen + das verzögerte Löschen übernehmen? Nein, wenn der Schlüssel nicht gelöscht wird, wenn Sie ihn regelmäßig löschen. Dann haben Sie den Schlüssel nicht sofort angefordert, was bedeutet, dass die verzögerte Löschung nicht wirksam wurde. Auf diese Weise wird die Erinnerung an Redis immer höher. Dann sollte der Speicherbeseitigungsmechanismus übernommen werden.
Es gibt eine Konfigurationszeile in redis.conf die festgelegte Ablaufzeit (Wählen Sie die zuletzt verwendeten Daten aus server.db[i].expires aus) und entfernen Sie sie. .expires) mit einer Ablaufzeit eingestellt, um es zu beseitigen
volatile-random
: Wählen Sie zufällig Daten aus, die aus dem Datensatz entfernt werden sollen (server.db[i].expires) mit festgelegter Ablaufzeit
: Aus dem Datensatz (server.db[i].dict) Wählen Sie die zuletzt verwendeten Daten zur Eliminierung aus
allkeys-random: Wählen Sie willkürlich Daten aus dem Datensatz (server.db[i].dict) zur Eliminierung aus
nein- enviction (Räumung): Deaktivieren Sie die Räumung von Daten und neue Schreibvorgänge. Es wird ein Fehler gemeldet ps: Wenn der Ablaufschlüssel nicht gesetzt ist und die Voraussetzungen nicht erfüllt sind, dann ist das Verhalten von volatile-lru, volatile-random und volatile-; TTL-Strategien sind im Grunde dasselbe wie Noeviction (nicht gelöscht).
Warum ist Redis Single-Threaded?
Da es sich bei Redis um einen speicherbasierten Vorgang handelt, ist die CPU nicht der Engpass von Redis. Der Engpass von Redis ist höchstwahrscheinlich die Größe des Maschinenspeichers oder des Netzwerks Bandbreite. Da Single-Threading einfach zu implementieren ist und die CPU nicht zu einem Engpass wird, ist es logisch, eine Single-Thread-Lösung zu übernehmen (schließlich verursacht die Verwendung von Multi-Threading viele Probleme!). Redis verwendet die Warteschlangentechnologie, um sich zu drehen gleichzeitiger Zugriff in seriellen Zugriff 1) Absolut Die meisten Anfragen sind reine Speicheroperationen (sehr schnell) 2) Single-Threaded, Vermeidung unnötiger Kontextwechsel und Race Conditions 3) Nicht blockierende IO-Vorteile:
1. Schnell, weil die Daten gespeichert werden Im Speicher besteht der Vorteil von HashMap, ähnlich wie bei HashMap, darin, dass die zeitliche Komplexität von Suche und Betrieb O(1) beträgt 2. Unterstützt umfangreiche Datentypen, unterstützt Zeichenfolge, Liste, Menge, sortierte Menge, Hash 3. Unterstützt Transaktionen Operationen sind atomar. Die sogenannte Atomizität bedeutet, dass alle Änderungen an den Daten entweder ausgeführt oder gar nicht ausgeführt werden
4. Umfangreiche Funktionen: können zum Caching, Versenden von Nachrichten und zum Festlegen der Ablaufzeit per Schlüssel verwendet werden. Sie werden automatisch gelöscht nach Ablauf. So lösen Sie das Problem der gleichzeitigen Schlüsselkonkurrenz in Redis Es gibt mehrere Subsysteme, um einen Schlüssel gleichzeitig festzulegen. Worauf sollten wir zu diesem Zeitpunkt achten? Es wird nicht empfohlen, den Transaktionsmechanismus von Redis zu verwenden. Da unsere Produktionsumgebung im Grunde eine Redis-Cluster-Umgebung ist, werden Daten-Sharding-Vorgänge durchgeführt. Wenn an einer Transaktion mehrere Schlüsselvorgänge beteiligt sind, werden diese mehreren Schlüssel nicht unbedingt auf demselben Redis-Server gespeichert. Daher ist der Transaktionsmechanismus von Redis sehr nutzlos.
(1) Wenn Sie mit diesem Schlüssel arbeiten, ist der Befehl nicht erforderlich: Bereiten Sie ein verteiltes Schloss vor, jeder greift nach dem Schloss und führt nach dem Ergreifen des Schlosses einfach die festgelegte Operation aus.
(3) Die Verwendung von Warteschlangen zur Umwandlung der Set-Methode in seriellen Zugriff kann auch dazu beitragen, dass Redis eine hohe Parallelität erreicht, wenn die Konsistenz des Lesens und Schreibens von Schlüsseln gewährleistet ist.
Alle Vorgänge auf Redis sind atomar und threadsicher Um Parallelitätsprobleme zu berücksichtigen, hat Redis bereits intern Parallelitätsprobleme für Sie gelöst.Was ist mit der Redis-Clusterlösung zu tun? Was sind die Pläne?
1.twemproxy, das allgemeine Konzept ist, dass es einer Proxy-Methode ähnelt. Bei Verwendung wird der Ort, an dem Redis verbunden werden muss, in twemproxy geändert und verwendet einen konsistenten Hash-Algorithmus Übertragen Sie die Anfrage. Empfangen Sie die spezifischen Redis und geben Sie das Ergebnis an twemproxy zurück.
Nachteile: Aufgrund des Drucks der twemproxy-eigenen Single-Port-Instanz ändert sich der berechnete Wert nach Verwendung von konsistentem Hashing, wenn sich die Anzahl der Redis-Knoten ändert, und die Daten können nicht automatisch auf den neuen Knoten verschoben werden.
2.codis, die derzeit am häufigsten verwendete Cluster-Lösung, hat grundsätzlich den gleichen Effekt wie twemproxy, unterstützt jedoch die Wiederherstellung alter Knotendaten auf neue Hash-Knoten, wenn sich die Anzahl der Knoten ändert.
3.redis wird mit Cluster3 geliefert .0 Das Merkmal des Clusters besteht darin, dass sein verteilter Algorithmus kein konsistentes Hashing ist, sondern das Konzept von Hash-Slots und seine eigene Unterstützung für die Knoteneinstellung von Slave-Knoten. Einzelheiten finden Sie in der offiziellen Dokumentation.
Haben Sie versucht, Redis auf mehreren Maschinen bereitzustellen? Wie kann die Datenkonsistenz sichergestellt werden?
Master-Slave-Replikation, Trennung von Lesen und Schreiben
Eine davon ist die Master-Datenbank (Master) und die andere ist die Slave-Datenbank (Slave). Bei einem Schreibvorgang können die Daten ausgeführt werden wird automatisch mit der Slave-Datenbank synchronisiert. Die Slave-Datenbank ist im Allgemeinen schreibgeschützt und empfängt synchronisierte Daten von der Master-Datenbank. Eine Master-Datenbank kann mehrere Slave-Datenbanken haben, während eine Slave-Datenbank nur eine Master-Datenbank haben kann.
So gehen Sie mit einer großen Anzahl von Anfragen um
Redis ist ein Single-Threaded-Programm, was bedeutet, dass es nur eine Client-Anfrage gleichzeitig verarbeiten kann.
Redis verwendet IO-Multiplexing (select, epoll, kqueue, je nachdem). die Plattformen, die unterschiedliche Implementierungen übernehmen), um mehrere Kundenanfragen zu bearbeiten
Redis häufige Leistungsprobleme und Lösungen?
(1) Der Master führt am besten keine Persistenzarbeiten wie RDB-Speicher-Snapshots und AOF-Protokolldateien aus.
(2) Wenn die Daten wichtig sind, aktiviert ein Slave die AOF-Sicherungsdaten und die Richtlinie ist so eingestellt, dass sie einmal pro Jahr synchronisiert Zweitens
(3) Für die Geschwindigkeit der Master-Slave-Replikation und die Stabilität der Verbindung ist es am besten, wenn sich Master und Slave im selben LAN befinden.
(4) Vermeiden Sie das Hinzufügen von Slave-Bibliotheken zur darunter liegenden Master-Bibliothek großer Druck
(5) Verwenden Sie keine Bilder für die Master-Slave-Replikationsstruktur. Es ist stabiler, eine einseitig verknüpfte Listenstruktur zu verwenden, das heißt: Master Slave3. .
Erklären Sie das Redis-Thread-Modell
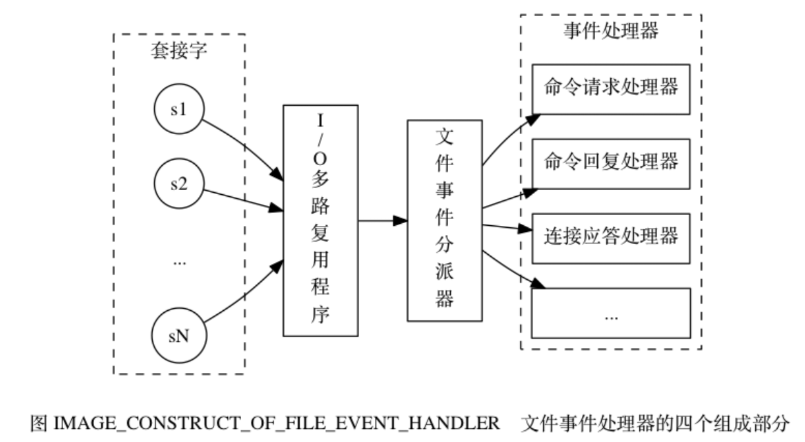
Der Dateiereignisprozessor umfasst Socket, E/A-Multiplexer, Dateiereignis-Dispatcher (Dispatcher) und Ereignishandler . Verwenden Sie einen E/A-Multiplexer, um mehrere Sockets gleichzeitig abzuhören und den Sockets basierend auf der gerade ausgeführten Aufgabe unterschiedliche Ereignishandler zuzuordnen. Wenn der überwachte Socket bereit ist, Vorgänge wie Verbindungsantworten (Akzeptieren), Lesen (Lesen), Schreiben (Schreiben), Schließen (Schließen) usw. auszuführen, wird das dem Vorgang entsprechende Dateiereignis generiert. Die Datei Der Ereignishandler ruft den zuvor dem Socket zugeordneten Ereignishandler auf, um diese Ereignisse zu verarbeiten.
Der E/A-Multiplexer ist dafür verantwortlich, mehrere Sockets abzuhören und die Sockets, die Ereignisse generiert haben, an den Dateiereignis-Dispatcher zu übermitteln.
Funktionsprinzip:
1) Der I/O-Multiplexer ist dafür verantwortlich, mehrere Sockets abzuhören und die Sockets, die Ereignisse generiert haben, an den Dateiereignis-Dispatcher zu übertragen.
Obwohl mehrere Dateiereignisse gleichzeitig auftreten können, stellt der E/A-Multiplexer immer alle ereignisgenerierenden Sockets in eine Warteschlange und durchläuft diese Warteschlange dann der Reihe nach (sequentiell), synchron, wobei er Sockets an den Dateiereignis-Dispatcher eines Sockets überträgt zu einem Zeitpunkt: wenn das vom vorherigen Socket generierte Ereignis verarbeitet wird (der Socket ist der dem Ereignis zugeordnete Ereignishandler). Der E/A-Multiplexer übergibt den nächsten Socket weiterhin an den Dateiereignis-Dispatcher, bis der E/A-Multiplexer dies getan hat Ausführung abgeschlossen). Wenn ein Socket sowohl lesbar als auch beschreibbar ist, liest der Server zuerst den Socket und schreibt ihn dann.
Warum sind Redis-Operationen atomar und wie kann die Atomizität sichergestellt werden?
Für Redis bedeutet die Atomizität eines Befehls, dass eine Operation nicht unterteilt werden kann und die Operation entweder ausgeführt wird oder nicht.
Der Grund, warum Redis-Operationen atomar sind, liegt darin, dass Redis Single-Threaded ist.
Alle von Redis selbst bereitgestellten APIs sind atomare Operationen. Transaktionen in Redis stellen tatsächlich die Atomizität von Batch-Operationen sicher.
Sind mehrere Befehle gleichzeitig atomar?
Nicht unbedingt, ändern Sie get und set auf Einzelbefehlsoperationen, Incr. Verwenden Sie Redis-Transaktionen oder verwenden Sie Redis+Lua== zur Implementierung.
Redis-Transaktion
Redis-Transaktionsfunktion wird durch die vier Grundelemente MULTI, EXEC, DISCARD und WATCH implementiert.
Redis serialisiert alle Befehle in einer Transaktion und führt sie dann der Reihe nach aus.
1. Redis unterstützt kein Rollback „Redis führt kein Rollback durch, wenn eine Transaktion fehlschlägt, sondern führt die verbleibenden Befehle weiterhin aus“, sodass die Interna von Redis einfach und schnell bleiben können.
2. Wenn in einer Transaktion ein Fehler im Befehl auftritt, werden alle Befehle nicht ausgeführt
3. Wenn in einer Transaktion ein Ausführungsfehler auftritt, wird der korrekte Befehl ausgeführt.
Hinweis: Das Verwerfen von Redis beendet nur diese Transaktion und die Auswirkungen des richtigen Befehls bleiben bestehen
1) Der MULTI-Befehl wird zum Starten einer Transaktion verwendet und gibt immer OK zurück. Nachdem MULTI ausgeführt wurde, kann der Client weiterhin beliebig viele Befehle an den Server senden. Diese Befehle werden nicht sofort ausgeführt, sondern in eine Warteschlange gestellt. Beim Aufruf des EXEC-Befehls werden alle Befehle in der Warteschlange ausgeführt .
2) EXEC: Befehle innerhalb aller Transaktionsblöcke ausführen. Gibt die Rückgabewerte aller Befehle innerhalb des Transaktionsblocks zurück, geordnet in der Reihenfolge der Befehlsausführung. Wenn der Vorgang unterbrochen wird, wird der leere Wert Null zurückgegeben.
3) Durch Aufrufen von DISCARD kann der Client die Transaktionswarteschlange leeren und die Ausführung der Transaktion aufgeben, und der Client verlässt den Transaktionsstatus.
4) Der WATCH-Befehl kann Check-and-Set (CAS)-Verhalten für Redis-Transaktionen bereitstellen. Ein oder mehrere Schlüssel können überwacht werden. Sobald einer der Schlüssel geändert (oder gelöscht) wird, werden nachfolgende Transaktionen nicht ausgeführt und die Überwachung wird bis zum EXEC-Befehl fortgesetzt.
Redis implementiert verteilte Sperren
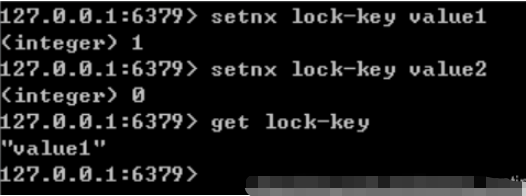
Redis ist ein Einzelprozess-Single-Thread-Modus. Es verwendet den Warteschlangenmodus, um den gleichzeitigen Zugriff in seriellen Zugriff umzuwandeln, und es gibt keine Konkurrenz zwischen den Verbindungen mehrerer Clients zu Redis. Sie können den SETNX-Befehl verwenden Um eine Verteilung im Redis-Stil zu erreichen, sperren.
Setzen Sie den Wert von Schlüssel genau dann auf Wert, wenn der Schlüssel nicht vorhanden ist. Wenn der angegebene Schlüssel bereits vorhanden ist, ergreift SETNX keine Aktion.
Entsperren: Verwenden Sie den Befehl del key, um die Sperre aufzuheben.
Lösen Sie den Deadlock:
1) Legen Sie die maximale Haltezeit für die Sperre über Expire() in Redis fest , wenn es überschritten wird, hilft uns Redis, die Sperre aufzuheben.
2) Dies kann durch die Befehlskombination aus setnx-Taste „aktuelle Systemzeit + Sperrhaltezeit“ und getset-Taste „aktuelle Systemzeit + Sperrhaltezeit“ erreicht werden.
Das obige ist der detaillierte Inhalt vonSo lösen Sie Redis-bezogene Probleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!