
Analyse der Redis-Clusterinstanz

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-04 08:21:011757Durchsuche
1. Warum K8s
1. Der aktuelle Redis-Cluster wird auf einem physischen Maschinencluster bereitgestellt, um die Ressourcennutzung zu verbessern und Kosten zu sparen. Da es keine Isolation der CPU-Ressourcen gibt, kommt es häufig vor, dass die CPU-Auslastung eines Redis-Knotens zu hoch ist, was dazu führt, dass andere Redis-Clusterknoten um CPU-Ressourcen konkurrieren, was zu Verzögerungsjitter führt. Da verschiedene Cluster gemischt sind, ist diese Art von Problem schwer schnell zu lokalisieren und beeinträchtigt die Betriebs- und Wartungseffizienz. Die Container-Bereitstellung von K8 kann die CPU-Anforderung und das CPU-Limit festlegen, was die Ressourcennutzung verbessert und gleichzeitig Ressourcenkonflikte vermeidet.
2. Automatisierte Bereitstellung
Der aktuelle Bereitstellungsprozess von Redis Cluster auf physischen Maschinen ist sehr umständlich. Sie müssen die Metainformationsdatenbank überprüfen, um Maschinen mit freien Ressourcen zu finden, viele Konfigurationsdateien manuell ändern und dann einen Knoten bereitstellen um eins und verwenden Sie schließlich das Tool redis_trib, um einen Cluster zu erstellen. Die Initialisierung eines neuen Clusters dauert oft ein oder zwei Stunden.
K8s stellt Redis-Cluster über StatefulSet bereit und verwendet configmap zur Verwaltung von Konfigurationsdateien. Die Bereitstellung eines neuen Clusters dauert nur wenige Minuten, was die Betriebs- und Wartungseffizienz erheblich verbessert.2. Wie K8s
Der Client wird über den VIP von LVS einheitlich angesprochen und leitet Serviceanfragen über den Redis-Proxy an den Redis-Cluster-Cluster weiter. Hier stellen wir Redis Proxy zur Weiterleitung von Anfragen vor.
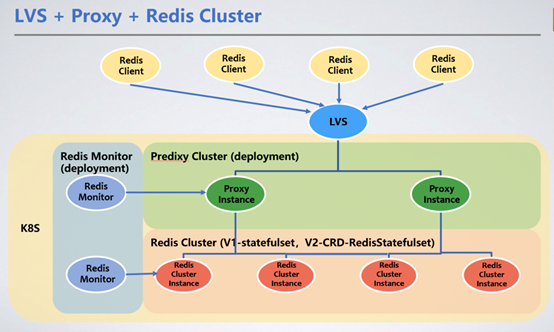 1. Redis-Cluster-Bereitstellungsmethode
1. Redis-Cluster-Bereitstellungsmethode
Redis wird als StatefulSet bereitgestellt, es ist am sinnvollsten, StatefulSet zu wählen, das die RDB/AOF des Knotens im verteilten Speicher beibehalten kann. Wenn der Knoten neu startet und zu anderen Maschinen wechselt, kann die ursprüngliche RDB/AOF über den bereitgestellten PVC (PersistentVolumeClaim) abgerufen werden, um Daten zu synchronisieren.
Ceph-Blockdienst ist das von uns gewählte persistente Speicher-PV (PersistentVolume). Die Lese- und Schreibleistung von Ceph ist schlechter als die lokaler Festplatten, wodurch sich die Lese- und Schreibverzögerungen um 100 bis 200 Millisekunden erhöhen. Die Lese- und Schreiblatenz des verteilten Speichers hat keine Auswirkungen auf den Dienst, da das RDB/AOF-Schreiben von Redis asynchron erfolgt. 2. Auswahl des Proxys werden nicht mehr berücksichtigt. redis-cluster-proxy ist ein von Redis offiziell in der Version 6.0 eingeführter Proxy, der das Redis-Cluster-Protokoll unterstützt. Allerdings gibt es derzeit keine stabile Version und er kann vorerst nicht in großem Umfang eingesetzt werden. Die einzigen Alternativen sind Cerberus und Predixy. Im Folgenden sind die Leistungstestergebnisse von Cerberus und Predixy aufgeführt, die wir in der K8s-Umgebung durchgeführt haben:Testumgebung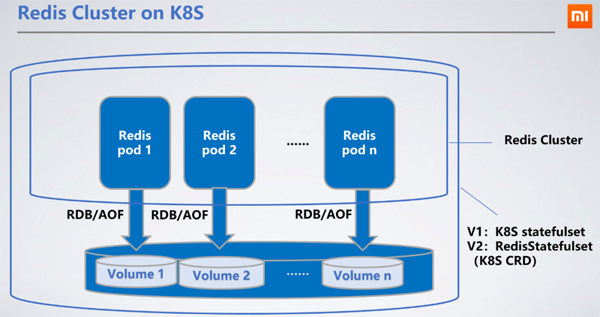
Testtool: redis-benchmarkProxy-CPU: 2 Kerne
Client-CPU: 2 Kerne
Redis-Cluster : 3 Master-Knoten, 1 CPU pro Knoten
Testergebnisse
Predixy ist in der Lage, bei gleicher Arbeitslast und Konfiguration höhere QPS zu erreichen, und seine Latenz kommt auch Cerberus ziemlich nahe. Insgesamt ist die Leistung von Predixy 33 bis 60 % höher als die von Cerberus. Je größer der Schlüssel/Wert der Daten ist, desto offensichtlicher ist der Vorteil von Predixy. Daher haben wir uns am Ende für Predixy entschieden.
Um uns an die Geschäfts- und K8s-Umgebung anzupassen, haben wir viele Änderungen an Predixy vorgenommen, bevor wir online gingen, und viele neue Funktionen hinzugefügt, wie z. B. dynamisches Umschalten des Back-End-Redis-Clusters, schwarze und weiße Listen, Überwachung abnormaler Vorgänge, usw.
3. Proxy-Bereitstellungsmethode
Aufgrund seiner zustandslosen und leichten Bereitstellungseigenschaften kann durch die Verwendung von Proxy als Bereitstellungsmethode und die Bereitstellung von Diensten durch Lastausgleich (LB) leicht eine dynamische Erweiterung und Kontraktion erreicht werden. Gleichzeitig haben wir die Funktion zum dynamischen Umschalten des Back-End-Redis-Clusters für den Proxy entwickelt, mit der Redis-Cluster online hinzugefügt und umgeschaltet werden können. 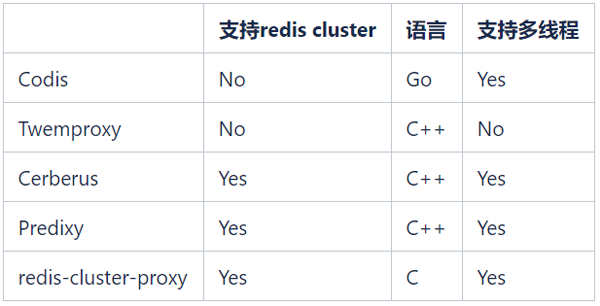
4. Automatische Proxy-Erweiterungs- und Kontraktionsmethode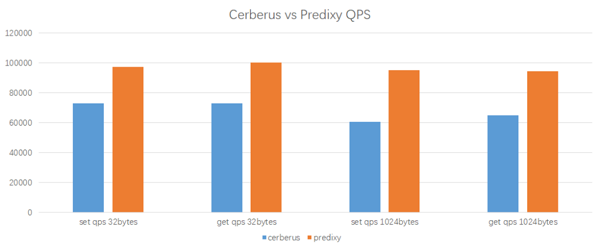
Wir verwenden K8s nativen HPA (Horizontal Pod Autoscaler), um eine dynamische Erweiterung und Kontraktion von Proxy zu erreichen. Wenn die durchschnittliche CPU-Auslastung aller Proxy-Pods einen bestimmten Schwellenwert überschreitet, wird die Erweiterung automatisch ausgelöst und die Replikatnummer des Proxys um 1 erhöht. Danach erkennt LVS den neuen Proxy-Pod und schneidet einen Teil des Datenverkehrs ab. Wenn die CPU-Auslastung den angegebenen Schwellenwert überschreitet, wird die Kapazität erweitert. Wenn sie immer noch nicht den Anforderungen entspricht, wird die Erweiterungslogik weiterhin ausgelöst. Allerdings wird die Verkleinerungslogik innerhalb von 5 Minuten nach erfolgreicher Erweiterung nicht ausgelöst, egal wie stark die CPU-Auslastung sinkt, wodurch die Auswirkungen häufiger Erweiterungen und Verkleinerungen auf die Clusterstabilität vermieden werden.
HPA kann die minimale (MINPODS) und maximale (MAXPODS) Anzahl von Pods im Cluster konfigurieren. Unabhängig davon, wie niedrig die Clusterlast ist, wird sie nicht auf die Anzahl der Pods unter MINPODS herunterskaliert. Es wird empfohlen, dass Kunden ihre tatsächlichen Geschäftsbedingungen beurteilen, um den Wert von MINPODS und MAXPODS zu ermitteln.
3. Warum Proxy
1. Ein Neustart des Redis-Pods kann zu IP-Änderungen führen
Redis-Clients, die Redis-Cluster verwenden, müssen einige IP-Adressen und Ports des Clusters konfigurieren, um den Eingang zum Redis-Cluster zu finden, wenn der Client neu startet. Bei Redis-Knoten, die in physischen Maschinenclustern bereitgestellt werden, können IP und Port unverändert bleiben, selbst wenn die Instanz oder die Maschine neu gestartet wird, und der Client kann weiterhin die Topologie des Redis-Clusters finden. Bei Redis-Clustern, die auf K8s bereitgestellt werden, kann jedoch nicht garantiert werden, dass die IP unverändert bleibt, wenn der Pod neu gestartet wird (selbst wenn er auf dem ursprünglichen K8s-Knoten neu gestartet wird), sodass der Client beim Neustart möglicherweise nicht in der Lage ist, die IP zu finden Eingang zum Redis-Cluster.
Durch das Hinzufügen eines Proxys zwischen dem Client und dem Redis-Cluster werden die Redis-Cluster-Informationen vom Client abgeschirmt. Der Proxy kann die Topologieänderungen des Redis-Clusters dynamisch erkennen. Der Client muss nur den IP-Port von LVS verwenden Punkt auf Anforderung Durch Weiterleitung an den Proxy können Sie den Redis-Cluster genauso verwenden wie die eigenständige Version von Redis, ohne dass ein Redis-Smart-Client erforderlich ist.
2. Redis bewältigt eine hohe Verbindungslast
Vor Version 6.0 verarbeitete Redis die meisten Aufgaben in einem einzigen Thread. Wenn die Verbindungen zu Redis-Knoten hoch sind, muss Redis viele CPU-Ressourcen verbrauchen, um diese Verbindungen zu verarbeiten, was zu einer erhöhten Latenz führt. Mit dem Proxy erfolgt eine große Anzahl von Verbindungen auf dem Proxy und es werden nur wenige Verbindungen zwischen dem Proxy und der Redis-Instanz aufrechterhalten. Dies verringert die Belastung von Redis und vermeidet die durch die Zunahme der Verbindungen verursachte Erhöhung der Redis-Latenz.
3. Clustermigration und -wechsel erfordern einen Neustart der Anwendung.
Während der Nutzung steigt das Datenvolumen des Redis-Clusters weiter an, wenn das Datenvolumen jedes Knotens zu hoch ist erheblich erhöht werden, wodurch die Clusterverfügbarkeit verringert wird. Gleichzeitig führt die Erhöhung der QPS auch zu einer Erhöhung der CPU-Auslastung jedes Knotens. Dies muss durch Hinzufügen eines Erweiterungsclusters gelöst werden. Derzeit ist die horizontale Skalierbarkeit des Redis-Clusters nicht sehr gut und die Migrationslösung für native Slots ist sehr ineffizient. Nach dem Hinzufügen eines neuen Knotens können einige Clients wie Lettuce den neuen Knoten aufgrund des Sicherheitsmechanismus nicht erkennen. Darüber hinaus ist die Migrationszeit völlig unvorhersehbar und es gibt keine Möglichkeit, ein Rollback durchzuführen, wenn während des Migrationsprozesses Probleme auftreten.
Der aktuelle Erweiterungsplan für physische Maschinencluster ist:
Erstellen Sie bei Bedarf neue Cluster.
Verwenden Sie Synchronisierungstools, um Daten vom alten Cluster mit dem neuen Cluster zu synchronisieren korrekt ist, kommunizieren Sie mit dem Unternehmen, starten Sie den Dienst neu und wechseln Sie zum neuen Cluster.
Der gesamte Prozess ist umständlich und riskant und das Unternehmen muss neu gestartet werden.
Mit der Proxy-Schicht kann die Erstellung, Synchronisierung und Umschaltung von Clustern im Backend vom Client abgeschirmt werden. Nachdem die Synchronisierung des neuen und des alten Clusters abgeschlossen ist, können Sie einen Befehl an den Proxy senden, um die Verbindung zum neuen Cluster umzuschalten, wodurch eine Clustererweiterung und -kontraktion erreicht werden kann, die der Client überhaupt nicht bemerkt.
Redis implementiert Authentifizierungsvorgänge über AUTH. Der Client ist direkt mit Redis verbunden und das Passwort muss weiterhin auf dem Client gespeichert werden. Bei Verwendung eines Proxys muss der Client nur über das Kennwort des Proxys auf Redis zugreifen und muss das Redis-Kennwort nicht kennen. Proxy schränkt auch Vorgänge wie FLUSHDB und CONFIG SET ein und verhindert so, dass Kunden versehentlich Daten löschen oder die Redis-Konfiguration ändern, was die Systemsicherheit erheblich verbessert. Gleichzeitig bietet Redis keine Auditing-Funktionen. Wir haben eine Protokollierungsfunktion für Vorgänge mit hohem Risiko auf dem Proxyserver hinzugefügt, die Prüffunktionen bietet, ohne die Gesamtleistung zu beeinträchtigen.
4. Durch Proxy verursachte Probleme
1. Die Verzögerung, die durch einen weiteren Hop verursacht wird
Wenn der Client auf Redis-Daten zugreift, muss er zuerst auf den Proxy zugreifen und dann auf den Redis-Knoten zugreifen, führt ein weiterer Hop zu einer erhöhten Verzögerung. Den Testergebnissen zufolge erhöht das Hinzufügen eines Hops die Verzögerung um 0,2 bis 0,3 ms, was für Unternehmen jedoch normalerweise akzeptabel ist.
2. Pod-Drift verursacht IP-ÄnderungenAuf K8s wird der Proxy durch Bereitstellung implementiert, daher besteht auch das Problem, dass Knotenneustarts IP-Änderungen verursachen. Unsere K8s LB-Lösung kann die IP-Änderungen des Proxys erkennen und den LVS-Verkehr dynamisch auf den neu gestarteten Proxy umleiten.
3. Durch LVS verursachte LatenzIn den in der Tabelle unten gezeigten Tests beträgt die durch Get/Set-Vorgänge unterschiedlicher Datenlänge verursachte LVS-Latenz weniger als 0,1 ms. 5. Vorteile von K8s
2. Lösen Sie das PortverwaltungsproblemDerzeit werden die auf physischen Maschinen bereitgestellten Redis-Instanzen durch Ports unterschieden, und Offline-Ports können nicht wiederverwendet werden, was bedeutet, dass jede Redis-Instanz im gesamten Unternehmen eine eindeutige Portnummer hat . Derzeit sind mehr als 40.000 der 65.535 Häfen genutzt. Nach der aktuellen Geschäftsentwicklung werden die Hafenressourcen innerhalb von zwei Jahren erschöpft sein. Durch die K8s-Bereitstellung verfügt der K8s-Pod, der jeder Redis-Instanz entspricht, über eine unabhängige IP, und es gibt kein Problem der Portauslastung und komplexer Verwaltungsprobleme. 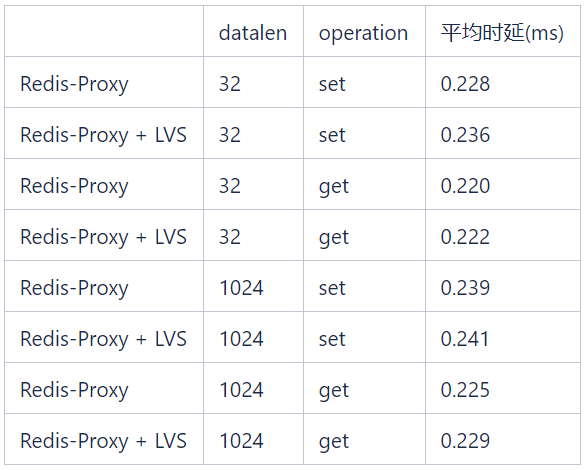
3. Senken Sie die Schwelle zur Kundennutzung Für Anwendungen müssen Sie nur die Standalone-Version des nicht-intelligenten Clients verwenden, um eine Verbindung zu VIP herzustellen, was die Nutzungsschwelle senkt und umständliche und komplizierte Parametereinstellungen vermeidet. Anwendungen müssen die Topologie des Redis-Clusters nicht selbst verwalten, da VIPs und Ports statisch festgelegt sind. 4. Verbessern Sie die Client-Leistung Die Verwendung nicht-intelligenter Clients kann auch die Belastung des Clients verringern, da der Smart-Client den Schlüssel auf dem Client hashen muss, um zu bestimmen, an welchen Redis-Knoten die Anfrage gesendet werden soll QPS ist relativ hoch. In diesem Fall werden die CPU-Ressourcen des Client-Computers verbraucht. Um die Migration von Client-Anwendungen zu vereinfachen, haben wir Proxy natürlich auch dafür gesorgt, dass es das Smart-Client-Protokoll unterstützt. 5. Dynamisches Upgrade und Kapazitätserweiterung Proxy unterstützt die Funktion des dynamischen Hinzufügens und Wechselns von Redis-Clustern, sodass der Cluster-Upgrade- und Kapazitätserweiterungs- und -wechselprozess von Redis Cluster vom Geschäftsende völlig unabhängig sein kann. Auf der Geschäftsseite wird beispielsweise ein Redis-Cluster mit 30 Knoten verwendet. Aufgrund des gestiegenen Geschäftsvolumens sind das Datenvolumen und die QPS schnell gestiegen, und die Clustergröße muss verdoppelt werden. Wenn die Kapazität auf der ursprünglichen physischen Maschine erweitert wird, ist der folgende Prozess erforderlich: Koordinieren Sie Ressourcen und stellen Sie einen neuen Cluster mit 60 Knoten bereit. Konfigurieren Sie das Migrationstool manuell, um die Daten des aktuellen Clusters zu migrieren der neue Cluster; Nachdem Sie überprüft haben, ob die Daten korrekt sind, benachrichtigen Sie die Geschäftspartei, die Topologie des Redis-Cluster-Verbindungspools zu ändern und den Dienst neu zu starten. Obwohl Redis Cluster die Online-Erweiterung unterstützt, wirkt sich die Verschiebung von Slots während des Erweiterungsprozesses auf das Online-Geschäft aus und die Migrationszeit ist unkontrollierbar, sodass diese Methode in dieser Phase selten und nur gelegentlich verwendet wird wenn die Ressourcen ernsthaft nicht ausreichen. Unter der neuen K8s-Architektur ist der Migrationsprozess wie folgt: Erstellen Sie mit einem Klick über die API-Schnittstelle einen neuen Cluster mit 60 Knoten. Erstellen Sie außerdem mit einem Klick über die API ein Cluster-Synchronisierungstool Schnittstelle zum Migrieren von Daten zum neuen Cluster; Nachdem Sie überprüft haben, ob die Daten korrekt sind, senden Sie einen Befehl an den Proxy, um neue Clusterinformationen hinzuzufügen und den Wechsel abzuschließen. Der gesamte Prozess ist sich des geschäftlichen Endes überhaupt nicht bewusst. Cluster-Upgrade ist auch sehr praktisch: Wenn das Unternehmen einen bestimmten Verzögerungsfehler akzeptieren kann, kann dies durch ein fortlaufendes StatefulSet-Upgrade außerhalb der Hauptverkehrszeiten erreicht werden. Wenn das Unternehmen Verzögerungsanforderungen hat, kann dies durch die Erstellung eines neuen erreicht werden Cluster und Migration von Daten. 6. Verbessern Sie die Dienststabilität und Ressourcennutzung. Verwenden Sie die Ressourcenisolationsfunktion von K8s, um eine gemischte Bereitstellung verschiedener Arten von Anwendungen zu ermöglichen. Dies verbessert nicht nur die Ressourcenauslastung, sondern gewährleistet auch die Servicestabilität. 6. Aufgetretene Probleme erkannt und der Pod wird neu gestartet. Wenn Redis auf dem Pod ein Slave ist, hat dies keine Auswirkungen. Wenn Redis jedoch der Master ist und kein AOF vorhanden ist, werden nach dem Neustart alle ursprünglichen Speicherdaten gelöscht. Redis lädt die zuvor gespeicherte RDB-Datei neu, die RDB-Datei ist jedoch keine Echtzeitdaten. Später synchronisiert der Slave auch seine eigenen Daten mit dem Datenspiegel in der vorherigen RDB-Datei, was zu einem gewissen Datenverlust führt. Bei der Bereitstellung eines StatefulSets folgt der Pod-Name einem bestimmten Namensformat und enthält eine feste Nummer, sodass es sich beim StatefulSet um einen zustandsbehafteten Dienst handelt. Wenn wir den Redis-Cluster initialisieren, stellen wir benachbarte nummerierte Pods auf eine Master-Slave-Beziehung ein. Wenn Sie einen Pod neu starten, ermitteln Sie seinen Slave anhand des Pod-Namens. Senden Sie vor dem Neustart des Pods den Cluster-Failover-Befehl an den Slave-Knoten, um zu erzwingen, dass der überlebende Slave-Knoten zum Master wird. Auf diese Weise wird der Knoten nach dem Neustart automatisch als Slave-Knoten dem Cluster beitreten. Die Lastverteilung der Proxy-Pods erfolgt über LVS. Es kommt zu einer gewissen Verzögerung bei der Wirksamkeit der LVS-Zuordnung des Proxy-Knotens. Um die Auswirkungen des Proxy-Betriebs und der Proxy-Wartung auf das Unternehmen zu minimieren, haben wir der Proxy-Bereitstellungsvorlage die folgenden Optionen hinzugefügt:
LVS-Zuordnungsverzögerunglifecycle: preStop: exec: command: - sleep - "171"
2. K8s StatefulSet kann die Bereitstellungsanforderungen des Redis-Clusters nicht erfüllen.
K8s natives StatefulSet kann die Anforderungen der Redis-Cluster-Bereitstellung nicht vollständig erfüllen:
Im Redis-Cluster können Knoten mit einer Master-Standby-Beziehung nicht auf demselben bereitgestellt werden Maschine. Dies ist leicht zu verstehen, wenn die Maschine ausfällt, ist der Daten-Shard nicht mehr verfügbar. 2) Der Redis-Cluster lässt nicht zu, dass mehr als die Hälfte der Masterknoten im Cluster ausfallen, denn wenn mehr als die Hälfte der Masterknoten ausfallen, gibt es nicht genügend Knotenstimmen, um die Anforderungen des Klatschprotokolls zu erfüllen. Da der Master und das Backup des Redis-Clusters jederzeit gewechselt werden können, können wir die Situation nicht vermeiden, dass alle Knoten auf derselben Maschine Masterknoten sind. Daher können wir während der Bereitstellung nicht zulassen, dass mehr als 1/4 der Knoten im Cluster dies tun auf derselben Maschine bereitgestellt werden.Um die oben genannten Anforderungen zu erfüllen, kann das native StatefulSet die Anti-Affinitätsfunktion verwenden, um sicherzustellen, dass derselbe Cluster nur einen Knoten auf derselben Maschine bereitstellt, die Maschinenauslastung ist jedoch sehr gering.
Also haben wir ein CRD basierend auf StatefulSet entwickelt: RedisStatefulSet, das verschiedene Strategien zur Bereitstellung von Redis-Knoten verwendet. Einige Funktionen zum Verwalten von Redis in RedisStatefulSet hinzugefügt. Wir werden diese in anderen Artikeln weiterhin ausführlich besprechen.
7. Zusammenfassung
Dutzende Redis-Cluster wurden seit mehr als sechs Monaten auf K8s bereitgestellt und ausgeführt, und an diesen Clustern sind mehrere Unternehmen innerhalb der Gruppe beteiligt. Dank der schnellen Bereitstellungs- und Fehlermigrationsfunktionen von K8s ist der Betriebs- und Wartungsaufwand dieser Cluster viel geringer als der von Redis-Clustern auf physischen Maschinen, und ihre Stabilität wurde vollständig überprüft.
Außerdem sind wir während des Betriebs- und Wartungsprozesses auf viele Probleme gestoßen. Viele der im Artikel genannten Funktionen wurden basierend auf den tatsächlichen Anforderungen verfeinert. Im folgenden Prozess müssen noch viele Probleme schrittweise gelöst werden, um die Effizienz der Ressourcennutzung und die Servicequalität zu verbessern.
1. Gemischte Bereitstellung vs. unabhängige Bereitstellung
Die Redis-Instanzen der physischen Maschine werden unabhängig voneinander bereitgestellt, was für die Verwaltung von Vorteil ist, die Ressourcenauslastung jedoch nicht hoch ist . Redis-Instanzen nutzen CPU, Speicher und Netzwerk-E/A, aber Speicherplatz wird grundsätzlich verschwendet. Wenn eine Redis-Instanz auf K8s bereitgestellt wird, kann auf der Maschine, auf der sie sich befindet, jede andere Art von Dienst bereitgestellt werden. Dies kann jedoch die Auslastung der Maschine verbessern, wenn Dienste wie Redis hohe Verfügbarkeits- und Latenzanforderungen haben weil die Maschine nicht über genügend Speicher verfügt, ist inakzeptabel. Dies erfordert, dass das Betriebs- und Wartungspersonal den Speicher aller Maschinen überwacht, auf denen Redis-Instanzen bereitgestellt werden. Sobald der Speicher nicht ausreicht, werden die Master- und Migrationsknoten abgeschaltet, was jedoch die Arbeitsbelastung für Betrieb und Wartung erhöht.
Wenn in der Hybridbereitstellung andere Anwendungen mit hohem Netzwerkdurchsatz vorhanden sind, kann dies auch negative Auswirkungen auf den Redis-Dienst haben. Obwohl die Anti-Affinitätsfunktion von K8s Redis-Instanzen selektiv auf Maschinen bereitstellen kann, die nicht über solche Anwendungen verfügen, lässt sich diese Situation nicht vermeiden, wenn die Maschinenressourcen knapp sind.
2. Redis-Cluster-Verwaltung
Redis-Cluster ist eine P2P-Cluster-Architektur ohne zentralen Knoten. Sie basiert auf dem Gossip-Protokoll, um den Status des Clusters automatisch zu verbreiten und zu reparieren, was zu Netzwerkproblemen führen kann Es treten Probleme mit dem Knotenstatus des Redis-Clusters auf, z. B. Knoten im Fehler- oder Handshake-Status in der Cluster-Topologie oder sogar Split-Brain. Für diesen abnormalen Zustand können wir Redis CRD weitere Funktionen hinzufügen, um ihn schrittweise zu lösen und die Betriebs- und Wartungseffizienz weiter zu verbessern.
3. Audit und Sicherheit
Redis bietet nur eine Auth-Passwort-Authentifizierungsschutzfunktion und keine Berechtigungsverwaltung, daher ist die Sicherheit relativ gering. Durch Proxy können wir Clienttypen anhand von Passwörtern unterscheiden. Administratoren und normale Benutzer verwenden unterschiedliche Passwörter zum Anmelden, und auch die Berechtigungen für ausführbare Vorgänge sind unterschiedlich, sodass Funktionen wie Berechtigungsverwaltung und Betriebsüberwachung realisiert werden können.
4. Unterstützung mehrerer Redis-Cluster
Aufgrund der Einschränkungen des Gossip-Protokolls verfügt ein einzelner Redis-Cluster über begrenzte horizontale Erweiterungsmöglichkeiten. Wenn die Clustergröße 300 Knoten beträgt, ist die Effizienz von Topologieänderungen wie der Knotenmasterauswahl geringer deutlich reduziert. Da gleichzeitig die Kapazität einer einzelnen Redis-Instanz nicht zu hoch sein sollte, ist es für einen einzelnen Redis-Cluster schwierig, eine Datenskala von mehr als TB zu unterstützen. Über Proxy können wir Schlüssel logisch teilen, sodass ein einzelner Proxy mit mehreren Redis-Clustern verbunden werden kann. Aus Sicht des Kunden entspricht dies einer Verbindung zu einem Redis-Cluster, der größere Datenskalen unterstützen kann.
Das obige ist der detaillierte Inhalt vonAnalyse der Redis-Clusterinstanz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!