
Heim >Technologie-Peripheriegeräte >KI >Bei der Erkennung von „ChatGPT-Betrug' übertrifft der Effekt OpenAI: Die KI-generierten Detektoren der Peking-Universität und Huawei sind hier
Bei der Erkennung von „ChatGPT-Betrug' übertrifft der Effekt OpenAI: Die KI-generierten Detektoren der Peking-Universität und Huawei sind hier

- 王林nach vorne
- 2023-06-03 20:49:071334Durchsuche
Mit der kontinuierlichen Weiterentwicklung großer generativer Modelle nähert sich der von ihnen generierte Korpus allmählich dem des Menschen an. Obwohl große Models die Hände unzähliger Angestellter befreien, wurde ihre mächtige Fähigkeit, echte Dinge zu fälschen, auch von einigen Kriminellen genutzt, was zu einer Reihe sozialer Probleme führte:
# 🎜🎜# 


- Papieradresse: https://arxiv.org/abs/2305.18149
- Codeadresse (MindSpore): https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
- #🎜🎜 #Codeadresse (PyTorch): https://github.com/YuchuanTian/AIGC_text_detector
- Einführung
In Bezug auf die unterschiedlichen Erkennungseffekte von Korpus unterschiedlicher Länge stellte der Autor fest, dass es bei der Zuordnung kürzerer KI-generierter Texte zu einer gewissen „Unsicherheit“ kommen kann; Um es ganz klar auszudrücken: Da einige von der KI generierte kurze Sätze auch häufig von Menschen verwendet werden, ist es schwierig zu bestimmen, ob der von der KI generierte Kurztext von Menschen oder von der KI stammt. Hier sind mehrere Beispiele von Menschen und KI, die jeweils dieselbe Frage beantworten: Aus diesen Beispielen geht hervor, dass es schwierig ist, von der KI generierte kurze Antworten zu identifizieren: Der Unterschied zwischen dieser Art von Korpus und dem Menschen ist zu gering und es ist schwierig, seine wahren Eigenschaften genau zu beurteilen. Daher ist es unangemessen, kurze Texte einfach als Mensch/KI zu kommentieren und die Texterkennung gemäß herkömmlichen binären Klassifizierungsproblemen durchzuführen.
Als Reaktion auf dieses Problem wandelte diese Studie den Teil zur Erkennung binärer Klassifizierungen von Mensch und KI in ein partielles PU-Lernproblem (Positive-Unlabeled) um, das heißt, kürzer Sätze: Die menschliche Sprache ist die positive Klasse (Positive) und die Maschinensprache ist die unbeschriftete Klasse (Unlabeled), wodurch die Trainingsverlustfunktion verbessert wird. Diese Verbesserung verbessert die Klassifizierungsleistung des Detektors für verschiedene Korpora erheblich.
Algorithmusdetails

Unter diesen stellt 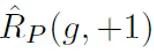 den durch positive Stichproben und positive Etiketten berechneten binären Klassifizierungsverlust dar; unter der Annahme positiver Proben als negative Etiketten. Der binäre Klassifizierungsverlust
den durch positive Stichproben und positive Etiketten berechneten binären Klassifizierungsverlust dar; unter der Annahme positiver Proben als negative Etiketten. Der binäre Klassifizierungsverlust 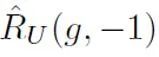 stellt die vorherige positive Probenwahrscheinlichkeit dar, d. h. den geschätzten Anteil positiver Proben an allen PU-Proben. Beim traditionellen PU-Lernen wird der Prior normalerweise auf einen festen Hyperparameter gesetzt. Im Texterkennungsszenario muss der Detektor jedoch verschiedene Texte unterschiedlicher Länge verarbeiten. Bei Texten unterschiedlicher Länge ist auch der geschätzte Anteil positiver Stichproben unter allen PU-Stichproben unterschiedlich. Daher verbessert diese Studie den PU-Verlust und schlägt eine längenabhängige mehrskalige PU-Verlustfunktion (MPU) vor.
stellt die vorherige positive Probenwahrscheinlichkeit dar, d. h. den geschätzten Anteil positiver Proben an allen PU-Proben. Beim traditionellen PU-Lernen wird der Prior normalerweise auf einen festen Hyperparameter gesetzt. Im Texterkennungsszenario muss der Detektor jedoch verschiedene Texte unterschiedlicher Länge verarbeiten. Bei Texten unterschiedlicher Länge ist auch der geschätzte Anteil positiver Stichproben unter allen PU-Stichproben unterschiedlich. Daher verbessert diese Studie den PU-Verlust und schlägt eine längenabhängige mehrskalige PU-Verlustfunktion (MPU) vor. 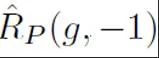
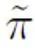 In dieser Studie wird insbesondere ein abstraktes wiederkehrendes Modell zur Modellierung der Erkennung kürzerer Texte vorgeschlagen. Wenn traditionelle NLP-Modelle Sequenzen verarbeiten, haben sie normalerweise eine Markov-Kettenstruktur wie RNN, LSTM usw. Der Prozess dieser Art von zyklischem Modell kann normalerweise als schrittweise iterativer Prozess verstanden werden, d. h. die Vorhersage jeder Token-Ausgabe wird durch Transformieren und Zusammenführen der Vorhersageergebnisse des vorherigen Tokens und der vorherigen Sequenz mit den Vorhersageergebnissen davon erhalten Token. Das heißt, der folgende Prozess:
In dieser Studie wird insbesondere ein abstraktes wiederkehrendes Modell zur Modellierung der Erkennung kürzerer Texte vorgeschlagen. Wenn traditionelle NLP-Modelle Sequenzen verarbeiten, haben sie normalerweise eine Markov-Kettenstruktur wie RNN, LSTM usw. Der Prozess dieser Art von zyklischem Modell kann normalerweise als schrittweise iterativer Prozess verstanden werden, d. h. die Vorhersage jeder Token-Ausgabe wird durch Transformieren und Zusammenführen der Vorhersageergebnisse des vorherigen Tokens und der vorherigen Sequenz mit den Vorhersageergebnissen davon erhalten Token. Das heißt, der folgende Prozess:
Um die A-priori-Wahrscheinlichkeit basierend auf diesem abstrakten Modell abzuschätzen, muss davon ausgegangen werden, dass die Ausgabe des Modells die Zuversicht ist, dass ein bestimmter Satz positiv ist Es wird davon ausgegangen, dass es von einer Person geäußert wird. Es wird davon ausgegangen, dass die Beitragsgröße jedes Tokens das umgekehrte Verhältnis zur Länge des Satztokens ist, positiv ist, dh unbeschriftet ist und die Wahrscheinlichkeit, unbeschriftet zu sein, viel größer ist als die Wahrscheinlichkeit, positiv zu sein. Denn wenn sich das Vokabular großer Modelle allmählich dem des Menschen annähert, werden die meisten Wörter sowohl in KI- als auch in menschlichen Korpora auftauchen. Basierend auf diesem vereinfachten Modell und der festgelegten positiven Token-Wahrscheinlichkeit wird die endgültige vorherige Schätzung erhalten, indem die Gesamterwartung der Modellausgabekonfidenz unter verschiedenen Eingabebedingungen ermittelt wird.
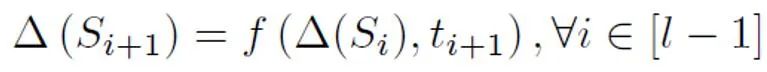
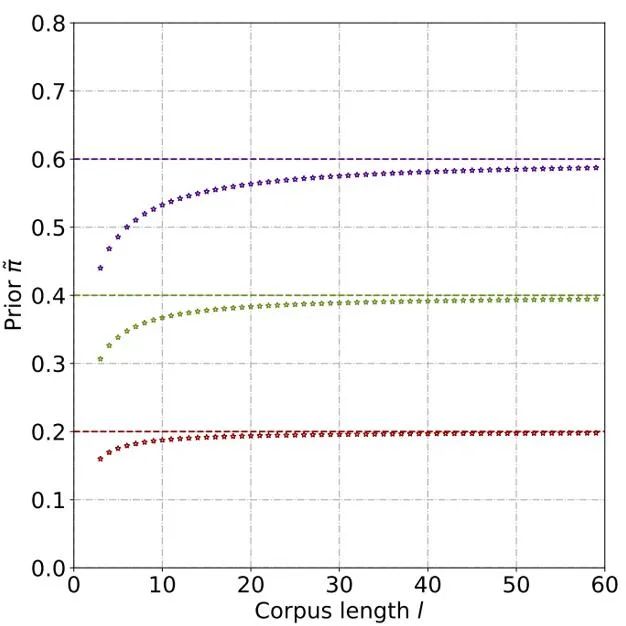
Durch theoretische Ableitung und Experimente wird geschätzt, dass die A-priori-Wahrscheinlichkeit mit zunehmender Textlänge zunimmt und sich schließlich stabilisiert. Auch dieses Phänomen entspricht den Erwartungen, denn je länger der Text wird, desto mehr Informationen kann der Detektor erfassen und die „Quellenunsicherheit“ des Textes nimmt allmählich ab:
Danach für jedes positive Ergebnis Für eine Stichprobe wird der PU-Verlust auf der Grundlage eines eindeutigen Priors berechnet, der aus der Stichprobenlänge abgeleitet wird. Da kürzere Texte schließlich nur eine gewisse „Unsicherheit“ aufweisen (das heißt, kürzere Texte enthalten auch Textmerkmale einiger Personen oder der KI), können der binäre Verlust und der MPU-Verlust gewichtet und als endgültiges Optimierungsziel hinzugefügt werden:
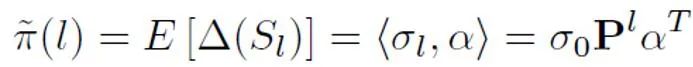
Darüber hinaus ist zu beachten, dass sich der MPU-Verlust an Trainingskörper unterschiedlicher Länge anpasst. Wenn die vorhandenen Trainingsdaten offensichtlich homogen sind und der Großteil des Korpus aus langen und langen Texten besteht, kann die MPU-Methode ihre Wirksamkeit nicht voll entfalten. Um die Länge des Trainingskorpus vielfältiger zu gestalten, wird in dieser Studie auch ein Multiskalierungsmodul auf Satzebene eingeführt. Dieses Modul deckt zufällig einige Sätze im Trainingskorpus ab und ordnet die übrigen Sätze unter Beibehaltung der ursprünglichen Reihenfolge neu. Nach dem mehrskaligen Betrieb des Trainingskorpus wurde die Länge des Trainingstextes erheblich erweitert, wodurch das PU-Lernen für das Training von KI-Textdetektoren voll ausgenutzt wird.
Experimentelle Ergebnisse

Wie in der obigen Tabelle gezeigt, testete der Autor zunächst die Auswirkung des MPU-Verlusts auf den kürzeren, von der KI generierten Korpusdatensatz Tweep-Fake. Der Korpus in diesem Datensatz besteht aus relativ kurzen Segmenten auf Twitter. Der Autor ersetzt auch den traditionellen Zwei-Kategorien-Verlust durch ein Optimierungsziel, das den MPU-Verlust auf der Grundlage der traditionellen Feinabstimmung des Sprachmodells enthält. Der verbesserte Sprachmodelldetektor ist effektiver und übertrifft andere Basisalgorithmen.
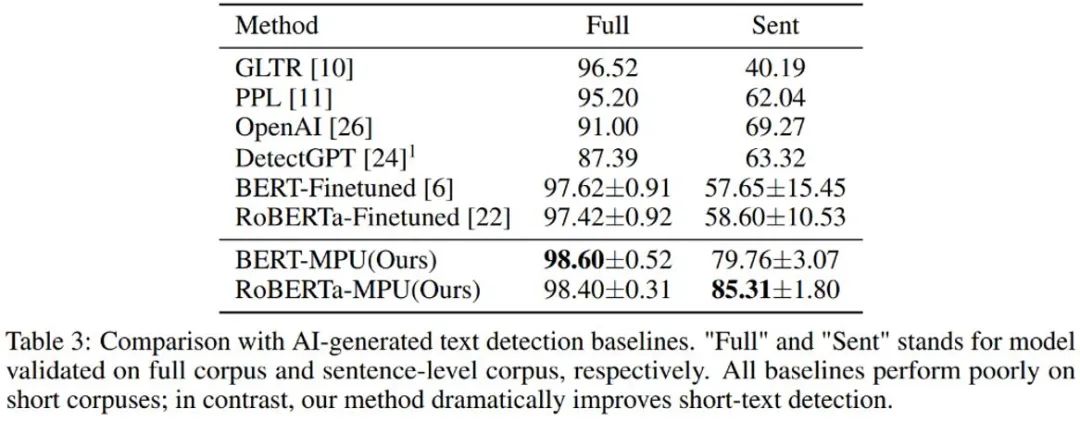
Der von chatGPT generierte Sprachmodelldetektor zeigte bei kurzen Sätzen eine schlechte Leistung; der unter denselben Bedingungen durch die MPU-Methode trainierte Detektor schnitt bei kurzen Sätzen besser ab Die Satzleistung ist gut und gleichzeitig kann eine erhebliche Wirkungsverbesserung auf den gesamten Korpus erzielt werden. Der F1-Score ist um 1 % gestiegen und übertrifft SOTA-Algorithmen wie OpenAI und DetectGPT.
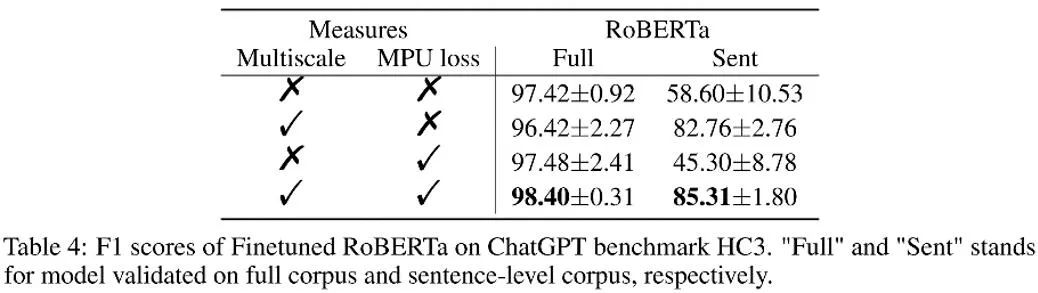
Wie in der Tabelle oben gezeigt, beobachtete der Autor die Wirkungssteigerung, die jeder Teil des Ablationsexperiments mit sich brachte. Der MPU-Verlust verstärkt den Klassifizierungseffekt von langen und kurzen Materialien.

Der Autor verglich auch traditionelles PU und Multiscale PU (MPU). Aus der obigen Tabelle ist ersichtlich, dass der MPU-Effekt besser ist und sich besser an die Aufgabe der KI-Texterkennung in mehreren Maßstäben anpassen kann.
Zusammenfassung
Der Autor hat das Problem der Kurzsatzerkennung durch Textdetektoren gelöst, indem er eine Lösung vorgeschlagen hat, die auf mehrskaligem PU-Lernen basiert. Mit der Verbreitung von AIGC-Generierungsmodellen wird die Erkennung dieser Art von Inhalten in Zukunft möglich sein wird immer wichtiger. Diese Forschung hat in der Frage der KI-Texterkennung einen deutlichen Schritt nach vorne gemacht. Es besteht die Hoffnung, dass es in Zukunft weitere ähnliche Forschungen geben wird, um AIGC-Inhalte besser zu kontrollieren und den Missbrauch von KI-generierten Inhalten zu verhindern.
Das obige ist der detaillierte Inhalt vonBei der Erkennung von „ChatGPT-Betrug' übertrifft der Effekt OpenAI: Die KI-generierten Detektoren der Peking-Universität und Huawei sind hier. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr